基于哈希和PCA的时空索引建立方法与流程
本发明涉及数据索引建立领域,主要应用于数据库中,具体涉及对数据时空三维特征建立统一索引。
背景技术:
随着传感器技术的快速发展,基于物联网、云计算、移动计算的空间定位技术和通信技术的日益成熟,各应用场景中对象的活动与交互产生的大量具有时空信息的数据,得以被探测、传输与记录。面对大量涌现的时空数据,如何针对这些数据的时空特性进行存储,面临着巨大的挑战。
在进行大规模时空数据处理时,经常会遇到时空数据查询效率低的问题。大规模数据必须存储于数据库中,而数据库带来的好处很重要的一方面是查询效率的显著提升,但面对具有时空特性的数据,传统关系型数据库对数据时空特征建立的索引往往不能带来时空查询效率的显著提升,需要针对数据的时空特性采取针对性的方法建立索引,来应对日趋增长的时空查询需求。
传统关系型数据库对数据的时空三维特征字段建立索引的方法是:为每个特征单独建立一个索引。这样会导致在进行时空查询的时候,要根据三个索引执行三次数据查找操作,查询响应时间会很长,而对时空三维特征字段统一建立一个索引,可以在进行时空查询时,只根据时空索引执行一次查询操作,响应时间与关系型数据库对一个字段进行查询的响应时间相似。
技术实现要素:
本发明主要解决的技术问题是,针对数据时空三维特征的特点,建立专用的时空索引,加快时空查询的速率。对三维时空特征字段统一建立一个索引,使用哈希方法显著增加查询效率的同时,又使用pca算法辅助,减少建立哈希索引的存储空间开销。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于哈希和pca的时空索引建立方法,包括如下步骤:
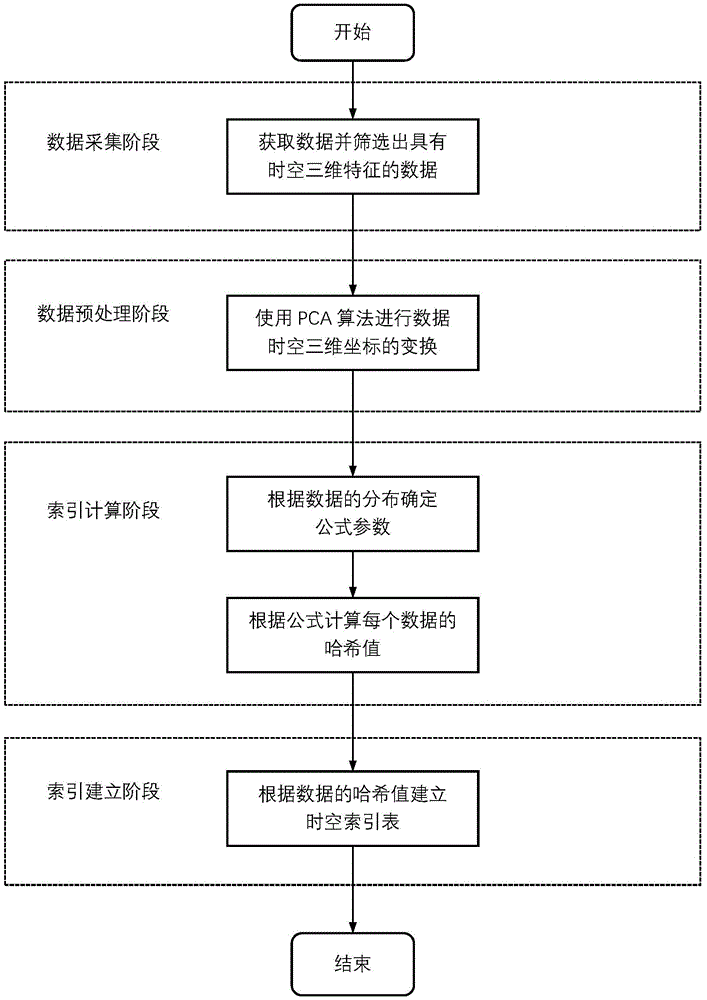
步骤1,数据采集,获取足够多的真实应用场景中的对象产生的具有经度、纬度、时间三个特征、称为时空三维特征的数据,这三个特征字段不能存在任何缺失;
步骤2,数据预处理,将所有时空三维特征的数据看作时空三维坐标系中的点,采用pca算法将该坐标系的坐标轴进行旋转,得到数据在新坐标系中的坐标;
步骤2方法如下:
步骤2a)采用pca算法的处理流程,对数据的时空三维坐标进行中心化处理,即将每一维特征值都减去所有数据该维特征字段的均值;
步骤2b)计算所有数据的协方差矩阵;
步骤2c)对协方差矩阵进行特征值分解,将特征值按照从大到小的顺序排列,相应的,将特征值对应的特征向量也按照相应的顺序排列,形成坐标转移矩阵;
步骤2d)将数据的原时空三维坐标乘以转移矩阵,得到数据在新坐标系中的坐标;
步骤2e)确定新坐标中每一维的最小值,并将所有新坐标减去最小值,得到最终坐标。
步骤3,索引计算,根据每个时空三维特征的数据的新坐标计算哈希值,并根据时空三维特征的数据分布情况调整哈希计算过程的参数;方法如下:
步骤3a)使用基于公式的计算方法,根据每个数据的最终坐标,从左到右,对坐标的每一维计算一个时空索引哈希值;
步骤3b)将三个哈希值按序连接,形成最终索引值。
步骤4,索引建立,为三级索引分别建立三张表,第三级索引的表存储指向时空三维特征的数据的指针,其余表存储指向下一级索引的指针,具体方法如下:
步骤4a)建立全局指针,代表时空索引,指向第一级索引表的表头;
步骤4b)第一级索引表是一个数组,每个数组元素为一个第二级索引表的表头,即第二级索引表个数与数组长度相等;数组的长度视索引第一块的可能取值的个数而定,由于进行了pca处理,原始数据在最终坐标第一维的方向上方差最大,在第二、三维方向上的方差指数级递减。方差大(例如数百数千)意味着数据在该方向分布得分散,方差小(例如小于1)就意味着数据在该方向聚集在一个很小的范围内,即该维度的可能取值很少,也就是说,数据最终坐标的第一维的取值范围非常大,而二、三维的取值范围指数递减,也就是说,如果第一维的数量级为100,那么第二、三维的数量级可能是10、1;
步骤4c)第二级索引表是一个数组,每个数组元素为一个第三级索引表的表头,数组的长度视索引第二块的可能取值的个数而定,如步骤4b的论述,这个数组的长度将比一级索引的数组长度小得多;
步骤4d)第三级索引表是一个数组,每个数组元素为指向一个链表的指针,该链表存储了所有具有相同最终索引值的数据,数组的长度视索引第二块的可能取值的个数而定,如步骤4b的论述,该数组的长度将比二级索引的数组长度小得多。
优选的,所述步骤3中的索引值具有块结构,第一块代表最终坐标第一维的哈希值,以此类推。
优选的,为了节省索引存储空间,所述步骤3中公式的参数根据实际步骤1采集到的数据的分布调整,调整方式于具体实施方式部分说明。
本发明相比现有技术,具有以下有益效果:
面对大量涌现的具有时空三维特征的数据,使用传统关系型数据库存储,使用其建立索引的方法为时空三维特征建立索引,已经无法满足日益增长的时空查询需求,本发明使用基于哈希和pca的方法,使得时空查询时间复杂度为o(1);与此同时,建立哈希索引带来的巨大的空间复杂度可以借助pca算法来显著降低,使得将该索引构建方法部署于时空数据库中成为可能。
附图说明
图1为本发明的方法整体流程图;
图2为本发明使用pca算法进行数据预处理过程的流程图。
图3为本发明进行索引计算的流程图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
一种基于哈希和pca的时空索引建立方法,包括如下步骤:
步骤1,数据采集,获取足够多的真实应用场景中的对象产生的具有经度、纬度、时间三个特征(称为时空三维特征)的数据,这三个特征字段不能存在任何缺失。
步骤2,数据预处理,将所有数据看作时空三维坐标系中的点,用(x,y,z)代表,其中x∈[-180,180]为经度,负值代表西经,正值代表东经,y∈[-90,90]代表纬度,负值代表南纬,正值代表北纬,z∈[0,+∞]代表时间,以步骤1中采集数据的最早时刻为时间零点。采用pca算法将数据的该坐标系的坐标轴进行旋转,得到数据在新坐标系中的坐标,方法如下:
步骤2a)采用pca算法的处理流程,对数据的时空三维坐标进行中心化处理,即对x、y、z分别减去μx、μy、μz,三者分别为数据在该维的均值,每个数据中心化后的坐标为(x',y',z')=(x-μx,y-μy,z-μz);
步骤2b)计算所有数据的协方差矩阵;
步骤2c)对协方差矩阵进行特征值分解,将特征值按照从大到小的顺序排列,相应的,将特征值对应的特征向量也按照相应的顺序排列,形成坐标转移矩阵w;
步骤2d)将数据中心化后的时空三维坐标(x',y',z')乘以转移矩阵w,得到数据在新坐标系中的坐标(x”,y”,z”);
步骤2e)根据实际数据的分布确定新坐标中每一维的最小值,最小值可以确定为比实际最小值小一些的值,并将所有新坐标减去最小值,得到最终坐标(x”',y”',z”'),可以确定,x”'、y”'、z”'均大于等于0。
步骤3,索引计算,根据每个数据的最终坐标计算哈希值,并根据数据分布情况调整哈希计算过程的参数,方法如下:
步骤3a)根据数据的分布确定每一维的间隔长度lx、ly、lz。可以有很多种方法,这里提出一种:
步骤3a1)lx、ly、lz确定了一个单位间隔立方体,按这个立方体的大小对最终坐标所在坐标系的空间进行均匀划分;初始化lx、ly、lz,设定一个阈值s,lx=(maxx-minx)/(numx/s)。其中,maxx为x”'的最大值,minx为x”'的最小值,numx为所有数据x”'不同取值的个数;ly、lz的初始化类似;
步骤3a2)根据数据分布,不断通过调整步骤3a1中的阈值s来调整lx、ly、lz的值,使得落在每个单位间隔立方体内的数据点个数不超过阈值v,v可根据实际情况而设,例如,v可以设为硬盘最小存储单元可以存储的数据的个数;
步骤3b)使用基于公式的计算方法,根据每个数据的最终坐标,从左到右,对坐标的每一维计算一个时空索引哈希值,即hashx=floor(x”'/lx),其中,floor(u)等于最大的不超过u的整数;hashy、hashz的计算方法类似;
步骤3c)将三个哈希值按序连接,形成一条数据最终索引值,即[hashxhashyhashz];
步骤4,索引建立,为三级索引分别建立三张表,第三级索引的表存储指向数据的指针,其余表存储指向下一级索引的指针,具体方法如下:
步骤4a)建立全局指针,代表时空索引,指向第一级索引表的表头;
步骤4b)第一级索引表是一个数组,每个数组元素为一个第二级索引表的表头,即第二级索引表个数与数组长度相等;数组的长度视hashx的可能取值范围而定,可定为max(hashx)*100;由于进行了pca处理,原始数据在最终坐标第一维的方向上方差最大,在第二、三维方向上的方差指数级递减。方差大意味着数据该方向分布得分散,方差小就意味着数据在该方向聚集在一个很小的范围内,即该维度的可能取值很少,也就是说,数据最终坐标的第一维的取值范围非常大,而二、三维的取值范围指数递减;
步骤4c)第二级索引表是一个数组,每个数组元素为一个第三级索引表的表头,数组的长度视索引第二块的可能取值的个数而定,如步骤4b的论述,这个数组的长度将比一级索引的数组长度小得多,可定为max(hashy)*10;
步骤4d)第三级索引表是一个数组,每个数组元素为指向一个链表的指针,该链表存储了所有具有相同最终索引值的数据,数组的长度视索引第二块的可能取值的个数而定,如步骤4b的论述,该数组的长度将比二级索引的数组长度小得多,可定为max(hashz)*2。
实际部署中,该索引的建立不能一劳永逸,需要根据新来的数据的分布进行索引的重建。在本发明的框架下,新来的数据的时空三维坐标可能超出索引支持的范围,这些数据可以单独存储于一个表中,待这个表大小超过一定阈值,即触发索引的重建,即执行上述所有步骤;另外,新数据的插入可能导致的单位间隔立方体容纳的数据点个数超过阈值v,需统计这些立方体的个数,当个数超过一定的阈值,亦触发索引的重建。
综上所述,本发明提出一种基于哈希和pca的时空索引建立方法,既能大幅降低时空查询的延迟,提高效率,又能控制索引建立的空间存储开销。其采用哈希方法,能够将查询时间复杂度控制在o(1);又充分利用pca算法的优点,可以极大地降低建立哈希索引所需要的空间开销。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!