一种基于深度学习的房角图像自动分级方法与流程
本发明涉及医学影像图像处理领域,更具体地,涉及一种基于深度学习的房角图像自动分级方法。
背景技术:
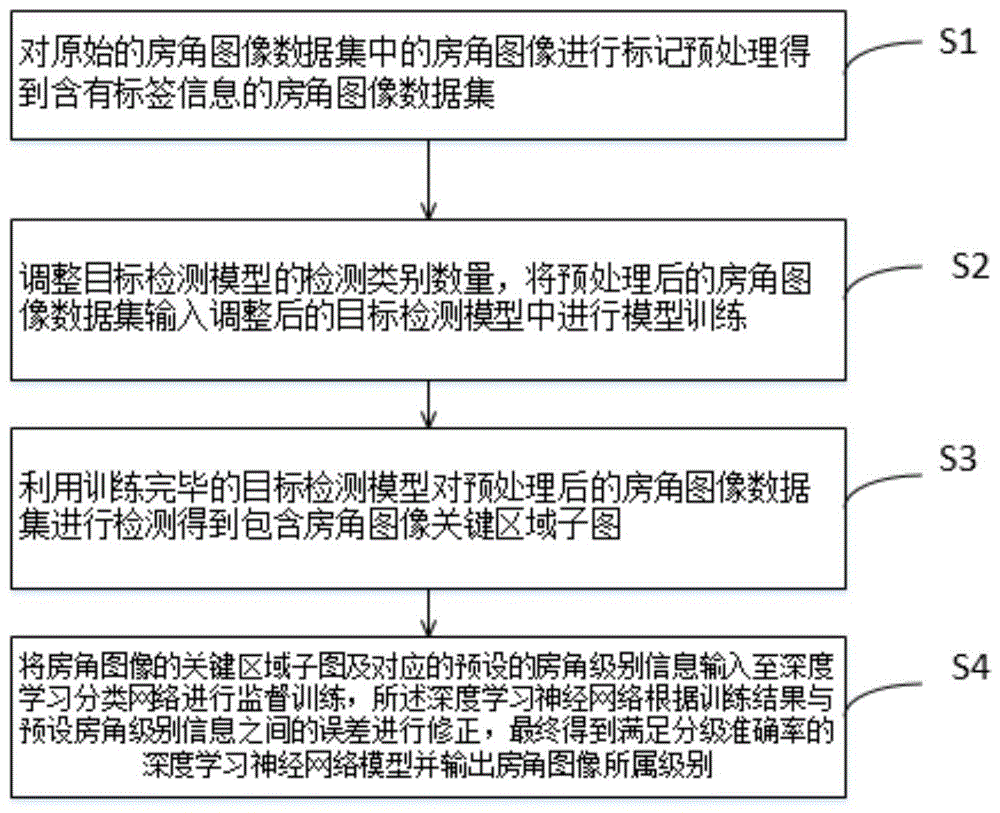
:前房角镜检查是青光眼临床工作中的一项重要检查,临床上主要根据前房角的状态来区分不同类型的青光眼,进而选择不同的治疗方案。前房角检查是通过房角镜检查观察房角的状态,主要是观察房角的:schwalbe线,小梁,巩膜突,睫状体带四个部位,依据能够观察到的部位数确定房角开闭程度的等级。房角一般分宽角与窄角,窄角进一步分为窄1,窄2,窄3和窄4四种类型如表1所示。表1分级房角结构宽(w)全部结构可见窄1(n1)可见部分睫状体带,未见虹膜根部窄2(n2)未见睫状体带,仅见巩膜突窄3(n3)未见后部小梁网目前青光眼研究与人工智能结合的应用较多的是在自动测算杯盘比进而预测青光眼方面。利用深度学习技术分析和处理数字图像,以检测与分割出眼底影像的视盘和视杯并计算杯盘比,其结果作为辅助意见供诊断医师参考。可取的有利用cnn、u-net等深度学习网络模型,通过在大量数据集上进行人工标记特征,然后将数据集和标记输入网络,网络根据数据集进行预测再根据人工标记对结果的误差进行反馈,不断训练致学习到了数据集的特征,以此可以用于检测与分割视杯视盘并测算杯盘比。而在房角的分级领域,暂无结合人工智能的相关研究及相关的自动化系统先例。技术实现要素:本发明为克服现有技术中因原始房角图像大关键区域占比小、干扰因素多导致分级效果不理想的缺陷,提供一种基于深度学习的房角图像自动分级方法。本发明的首要目的是为解决上述技术问题,本发明的技术方案如下:一种基于深度学习的房角图像自动分级方法,所述方法包括以下步骤:s1:对原始的房角图像数据集中的房角图像进行标记预处理得到含有标签信息的房角图像数据集;s2:调整目标检测模型的检测类别数量,将预处理后的房角图像数据集输入调整后的目标检测模型中进行模型训练;s3:利用训练完毕的目标检测模型对预处理后的房角图像数据集进行检测得到包含房角图像关键区域子图;s4:将房角图像的关键区域子图及对应的预设的房角级别信息输入至深度学习分类网络进行监督训练,所述深度学习神经网络根据训练结果与预设房角级别信息之间的误差进行修正,最终得到满足分级准确率的深度学习神经网络模型并输出房角图像所属级别。本发明通过对原始的房角图像数据集进行预处理得到含有标签信息的房角图像数据集,进而对调整后的目标检测模型进行训练,利用训练完毕的目标检测模型得到包含房角图像关键区域子图,最后将房角图像的关键区域子图及对应的预设的房角级别信息输入至深度学习分类网络进行监督训练不断的修正最终得到满足分级准确率的深度学习神经网络模型并输出房角图像所属级别。进一步地,所述房角图像预处理具体过程如下:s1.1:以房角图像左上顶点为坐标原点,设水平向右为x轴正方向,竖直向下为y轴正方向;s1.2:通过标记工具分别得到包含关键区域的矩形框的中心点的横坐标centerx,中心点的纵坐标centery,所述矩形框的宽度width,所述矩形框的高度height;s1.3:分别计算矩形框的中心的横坐标centerx、矩形框的宽度width与房角图像宽度的比值,记为:rx,rw;分别计算矩形框的中心的纵坐标centery、矩形框的高度height与房角图像高度的比值,记为:ry,rh;s1.4:将步骤s1.3得到的rx、rw、ry、rh及预设的房角级别信息c共同构成一个房角图像的标签信息。通过预处理之后得到包含有相对位置信息和预设的房角级别信息c的标签信息,所述的相对位置信息有利于关键区域的定位。进一步地,步骤s2所述目标检测模型为yolo-v3目标检测模型。进一步地,步骤s2调整目标检测模型的检测类别数量为1。将检测类别数量调整为1,即仅保留了所述目标检测模型的识别和检测目标的功能,一方面克服了yolo-v3目标检测模型房角图像分类效果不理想的缺陷,同时节省了参数存储空间。进一步地,步骤s3得到房角图像关键区域子图的具体过程为:利用训练完毕的目标检测模型对预处理后的房角图像数据集进行检测首先得到包含房角图像关键区的矩形框的位置信息,根据所述的位置信息在房角图像中截取出关键区域子图。进一步地,步骤s4所述的深度学习神经网络为resnet34网络。与现有技术相比,本发明技术方案的有益效果是:本发明通过对房角图像进行关键区域检测并截取,减少了检测时的非房角区域干扰因素,同时克服了因原始房角图像大关键区域占比小导致的分类效果不佳的缺陷,同时利用深度学习网络对关键区域的特征进行监督训练从而提高房角图像分级的准确率。附图说明图1为本发明方法流程图。图2为本发明预处理流程图。图3为本发明技术路线图。图4为关键区域检测过程示意图。图5为yolo-v3模型参数表为。图6为调整后的yolo-v3模型。图7为resnet34分类网络参数表。图8为resnet34分类原理示意图。具体实施方式下面结合附图和实施例对本发明的技术方案做进一步的说明。实施例1如图1示出了本发明的发明流程图,图3为本发明技术路线图,一种基于深度学习的房角图像自动分级方法,所述方法包括以下步骤:s1:对原始的房角图像数据集中的房角图像进行标记预处理得到含有标签信息的房角图像数据集;需要说明的是本实施例使用labelme标记工具进行标记预处理。如图2所示,所述房角图像预处理具体过程如下:s1.1:以房角图像左上顶点为坐标原点,设水平向右为x轴正方向,竖直向下为y轴正方向;s1.2:通过标记工具分别得到包含关键区域的矩形框的中心点的横坐标centerx,中心点纵坐标centery,所述矩形框的宽度width,所述矩形框的高度height;s1.3:分别计算矩形框的中心的横坐标centerx、矩形框的宽度width与房角图像宽度的比值,记为:rx,rw;分别计算矩形框的中心的纵坐标centery、矩形框的高度height与房角图像高度的比值,记为:ry,rh;s1.4:将步骤s1.3得到的rx、rw、ry、rh及预设的房角级别信息c共同构成一个房角图像的标签信息。需要说明的是,通过预处理之后得到包含有相对位置信息和预设的房角级别信息c的标签信息,所述的相对位置信息有利于关键区域的定位。如图4是关键区域检测过程示意图。s2:预调整yolo-v3目标检测模型检测类别数量为1,将预处理后的房角图像数据集输入调整后的目标检测模型中进行模型训练;如图5所示为yolo-v3模型参数表。图6所示为调整后的的yolo-v3模型。需要说明的是,将检测类别数量为1,即仅保留了所述目标检测模型的识别和检测目标的功能,一方面克服了yolo-v3目标检测模型房角图像分类效果不理想的缺陷,同时节省了参数存储空间。s3:利用训练完毕的目标检测模型对预处理后的房角图像数据集进行检测得到首先得到包含房角图像关键区的矩形框的位置信息,根据所述的位置信息在房角图像中截取出关键区域子图。s4:将房角图像的关键区域子图及对应的预设的房角级别信息输入至resnet34深度学习分类网络进行监督训练,所述深度学习神经网络根据训练结果与预设房角级别信息之间的误差进行修正,最终得到满足分级准确率的resnet34学习分类网络模型并输出房角图像所属级别。如图7所示为resnet34分类网络参数表,如图8所示为resnet34分类原理示意图。需要说明的是,由于房角图像整体较大(3264*2448,单位:像素),而关键区域是一条狭长且在原图占比较小的区域,同时原图上还有其他眼科部位的干扰,使得直接将原图放至普通分类器诸如vgg16上时不能很好的提取关键区域的特征,对其进行5分类时在测试集上的分类准确率在20%上下,接近于随机选择。通过本发明方法对房角图像关键区域进行分类,进行5分类时在测试集上可以达到40%左右的分类准确率,提升接近20%。最终用resnet34网络进行分类,5分类测试集上的分类准确率可达到47%。本发明通过对原始的房角图像数据集进行预处理得到含有标签信息的房角图像数据集,进而对调整后的目标检测模型进行训练,利用训练完毕的目标检测模型得到包含房角图像关键区域子图,最后将房角图像的关键区域子图及对应的预设的房角级别信息输入至深度学习分类网络进行监督训练不断的修正最终得到满足分级准确率的深度学习神经网络模型并输出房角图像所属级别。相同或相似的标号对应相同或相似的部件;附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1