一种基于多源观测数据的水质模型粒子滤波同化方法与流程
本发明属于水环境技术领域,尤其涉及一种基于多源观测数据的水质模型粒子滤波同化方法。
背景技术:
面对日趋严重的水环境问题,观测分析和模型模拟是水环境管理中的重要手段。观测分析手段主要包括实地采样实验室分析手段和遥感监测手段,实地采样实验室分析手段通过布设断面采集水样,然后通过实验室分析获取水质状况,这种监测手段虽然监测精度高,但耗时耗力,且只能获取点上的水质状况,监测频次有限,难以满足水环境动态管理的需求;遥感监测能够快速获取湖泊水质的时空分布,越来越多地应用于湖泊水环境的监测和管理。水动力水质模型是水环境管理的重要工具,可以获取时空连续的水质分布,但受模型参数、模型输入和模型结构等不确定性因素的影响,模拟精度有待提高。数据同化可以实现观测和模型模拟优势互补,利用同化算法可以将多源观测数据合理地融入水质模型,校正模型模拟结果,同步更新模型参数,提升模型模拟精度和预测能力。
粒子滤波在非线性非高斯模型数据同化中表现出色,逐渐应用于一维水质模型数据同化。现有水质模型粒子滤波数据同化研究中多采用空间均一的模型参数,忽略模型参数的空间变异性,难以同时得到不同空间(区域)水质模拟结果最优估计,无法适应二维水质模型数据同化;此外,水质模型粒子滤波数据同化中使用的多为水质原型观测数据,未能将水质原型观测和遥感观测的优势和水质模型模拟优势充分结合,限制了二维水质模型模拟和预测精度。
技术实现要素:
针对现有技术中的上述不足,本发明提供的一种基于多源观测数据的水质模型粒子滤波同化方法解决了现有水质模型粒子滤波数据同化研究中多采用空间均一的模型参数,忽略模型参数的空间变异性,难以同时得到不同空间(区域)水质模拟结果最优估计,无法适应二维水质模型数据同化的问题,以及水质模型粒子滤波数据同化中不能将水质原型观测和遥感观测的优势和水质模型模拟优势充分结合,从而限制了二维水质模型模拟和预测精度的问题。
为了达到以上目的,本发明采用的技术方案为:
本方案提供一种基于多源观测数据的水质模型粒子滤波同化方法,包括如下步骤:
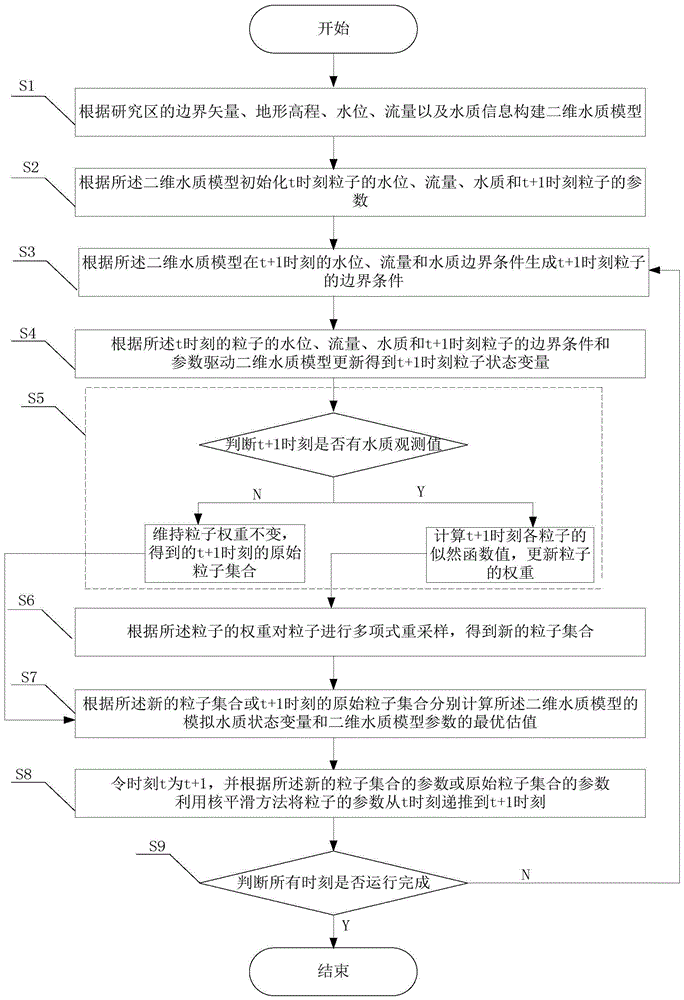
s1、根据研究区的边界矢量、地形高程、水位、流量以及水质信息构建二维水质模型;
s2、根据所述二维水质模型初始化t时刻粒子的水位、流量、水质和t+1时刻粒子的参数;
s3、根据所述二维水质模型在t+1时刻的水位、流量和水质边界条件生成t+1时刻粒子的边界条件;
s4、根据所述t时刻的粒子的水位、流量、水质和t+1时刻粒子的边界条件和参数驱动二维水质模型更新得到t+1时刻粒子状态变量;
s5、判断t+1时刻是否有水质观测值,若有,则计算t+1时刻各粒子的似然函数值,更新粒子的权重,并进入步骤s6,反之,则维持粒子权重不变,得到的t+1时刻的原始粒子集合,并进入步骤s7;
s6、根据所述粒子的权重对粒子进行多项式重采样,得到新的粒子集合;
s7、根据所述新的粒子集合或t+1时刻的原始粒子集合分别计算所述二维水质模型的模拟水质状态变量和二维水质模型参数的最优估值;
s8、令时刻t为t+1,并根据所述新的粒子集合的参数或原始粒子集合的参数利用核平滑方法将粒子的参数从t时刻递推到t+1时刻;
s9、判断所有时刻是否运行完成,若否,则返回步骤s3,直至所有时刻运行完成,反之,则结束对粒子的滤波同化,从而实现对水质模型粒子的滤波同化。
进一步地,所述步骤s1中构建二维水质模型的表达式如下:
其中,u表示守恒向量,f和g分别x、y轴方向上的对流通量,
再进一步地,所述步骤s2具体为:
根据t时刻的二维水质模型在各个自适应网格处的状态变量和参数的先验分布采样生成n个等权重的粒子,并初始化各粒子的权重为
再进一步地,所述初始化粒子的水位、流量、水质和参数的表达式如下:
其中,
再进一步地,所述步骤s3中生成粒子的边界条件
其中,
再进一步地,所述步骤s4中更新粒子状态变量
其中,f(·)表示二维水质模型,mt+1和mt分别为t+1时刻二维水质模型水位和水质的状态变量,nmt+1和
再进一步地,所述步骤s5中计算t+1时刻各粒子的似然函数值
其中,
再进一步地,所述步骤s6包括如下步骤:
s601、利用多项式重采样算法将所述粒子的权重集合组成多项式分布
s602、随机生成nr个服从(0,1]均匀分布的随机数rk~u(0,1],其中,rk表示均匀分布的随机数,且k=1,2...nr,nr=n,n表示粒子的总数,u表示状态变量和参数的均匀分布;
s603、计算各粒子的权重累积和序列,所述各粒子的权重累积和序列的表达式如下:
其中,ci+1,j表示第j个网格处第i+1个粒子权重累加值,ci,j表示第j个网格处第i粒子个权重累加值,
s604、统计权重累积区间(ci,j,ci+1,j]中落入随机数rk的次数,并将所述落入随机数rk的次数记为ni,j,得到粒子复制信息;
s605、根据所述粒子复制信息依次对粒子的状态变量进行复制,从而得到重采样后权重均等新的粒子集合
再进一步地,所述步骤s7中根据所述新的粒子集合计算所述二维水质模型的模拟水质状态变量的最优估值
其中,i表示粒子的编号,n表示粒子的总数,
根据所述新的粒子集合计算二维水质模型参数的最优估值
其中,
根据t+1时刻的原始粒子集合计算二维水质模型的模拟水质状态变量的最优估值
其中,i表示粒子的编号,n表示粒子的总数,
根据t+1时刻的原始粒子集合计算所述二维水质模型参数的最优估值
其中,
再进一步地,所述步骤s8中根据所述新的粒子集合的参数利用核平滑方法将粒子的参数从t时刻递推到t+1时刻,其表达式如下:
其中,
根据所述原始粒子集合的参数利用核平滑方法将粒子的参数从t时刻递推到t+1时刻,其表达式如下:
其中,
本发明的有益效果:
本发明采用基于自适应网格和并行计算的二维水质模型(hydrowqm2d-ap,2-dhydrodynamicandwaterqualitymodelbasedonadaptivegridsandparallelcomputation),通过考虑了水质模拟关键参数的时空变异性,利用粒子滤波算法将原位观测和遥感观测等多源观测数据合理地融入二维水质模型,动态更新了二维水质模型参数,提高了二维水质模型的模拟精度和预测能力,解决了现有水质模型粒子滤波数据同化研究中多采用空间均一的模型参数,忽略模型参数的空间变异性,难以同时得到不同空间(区域)水质模拟结果最优估计,无法适应二维水质模型数据同化的问题,以及现有水质模型粒子滤波数据同化中不能将水质原型观测和遥感观测的优势和水质模型模拟优势充分结合,从而限制了二维水质模型模拟和预测精度的问题。
附图说明
图1为本发明的方法流程图。
图2为在具体实施例中鄱阳湖地形、水位、水质观测点位置的示意图。
图3为在具体实施例中初始网格中心点空间分布的示意图。
图4为在具体实施例中星子、都昌、棠荫和康山水位模拟值和观测值的示意图。
图5为在具体实施例中蛤蟆石、星子、老爷庙、蚌湖、都昌、三山叶绿素a浓度模拟值和观测值的示意图。
图6为在具体实施例中鄱阳湖6个水质监测站点叶绿素a浓度同化结果及其90%置信区间的示意图。
图7为在具体实施例中鄱阳湖6个水质监测站点叶绿素a浓度同化值和模拟值平均相对误差的示意图。
图8为在具体实施例中2012年7月鄱阳湖叶绿素a浓度遥感观测、模型模拟和数据同化结果的示意图。
图9为在具体实施例中参数k1c最优估计和90%置信区间的示意图。
图10为在具体实施例中2012年7月鄱阳湖叶绿素a浓度模拟参数k1c估计结果的示意图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
实施例
本发明采用基于自适应网格和并行计算的二维水质模型(hydrowqm2d-ap,2-dhydrodynamicandwaterqualitymodelbasedonadaptivegridsandparallelcomputation),通过考虑了水质模拟关键参数的时空变异性,利用粒子滤波算法将原位观测和遥感观测等多源观测数据合理地融入二维水质模型,动态更新了二维水质模型参数,提高了二维水质模型的模拟精度和预测能力。
如图1所示,本发明公开了一种基于多源观测数据的水质模型粒子滤波同化方法,其实现方法如下:
s1、根据研究区的边界矢量、地形高程、水位、流量以及水质信息构建二维水质模型,以鄱阳湖为例,收集鄱阳湖边界矢量、地形高程、水位、水质相关数据,构建基于自适应网格和并行计算的二维水质模型hydrowqm2d-ap,其构建二维水质模型的表达式如下:
其中,u表示守恒向量,f和g分别x、y轴方向上的对流通量,
在具体实施例中,二维水质模型hydrowqm2d-ap模型基于wasp水质模型原理,考虑了氨氮(c1)、硝酸盐氮(c2)、无机磷(c3)、浮游植物碳(c4)、碳质生化需氧量(c5)、溶解氧(c6)、有机氮(c7)、有机磷(c8)8个水质指标之间的生化反应关系,可以模拟这8种水质参数的时空变化,二维水质模型采用自适应网格技术,根据地形坡度、水位梯度和污染物浓度梯度自动调整网格大小,此外,采用并行计算openmp技术对二维水质模型进行并行化改造,提高水质模型的计算效率,进而提高数据同化计算效率,以鄱阳湖为例,如图2所示,鄱阳湖边界矢量利用2014年8月5日丰水期一景landsat8影像确定二维水质模型计算范围,扣除与湖区无水动力交互的康山湖和军山湖,地形数据采用鄱阳湖2010年1:25000实测高程数据,水动力边界条件采用2012年修水、赣江、抚河、饶河、信江五河入湖流量数据和湖口水位数据,水质边界条件采用五河控制站水质实测数据;初始水位采用2012年1月1日星子、都昌、棠荫、康山4个水文站观测水位均值,初始水质采用蛤蟆石、星子、老爷庙、蚌湖、都昌和三山6个站点水质观测值均值,自适应结构网格采用三级网格划分,叶网格(0级网格)、1级网格、2级网格和3级网格大小分别为1600m×1600m、800m×800m、400m×400m和200m×200m;如图3所示,二维水质模型模拟前,首先根据地形对计算自适应网格进行划分,坡度大于0.02的区域均采用3级网格,此外,为了提高枯水期鄱阳湖河相模拟精度,河道及周边区域均采用3级网格划分,且在模拟过程中网格划分水平保持不变;模拟过程中根据水位梯度和干湿边界交替情况对其余网格大小进行自适应调整,二维水质模型采用冷启动的方式,预热1个月以消除初始条件的影响,为了有效模拟干湿边界的动态交替,设置最小水深1.0×10-3m,小于等于最小水深的网格为干单元,反之则为湿单元,自适应网格状态变量更新、自适应网格梯度计算等过程均采用并行计算,糙率系数manning是表征下垫面对水流阻力的变量,是水动力模拟的关键参数,二维水质模型采用统一糙率,经率定糙率系数manning最终设置为0.035s/m1/3,如图4所示,2012/2/1~2012/12/31星子、都昌、棠荫和康山模拟水位和观测水位,可以看出,初始条件对模拟结果的影响可以很快消除,4个观测站的模拟水位和观测水位基本一致,星子、都昌、棠荫和康山模拟水位的效率系数nash分别为0.99、0.99、0.96和0.93,证明二维水质模型可以模拟鄱阳湖水位的动态变化,在具体实施例中,利用2012/2/1~2012/12/31鄱阳湖区蛤蟆石、星子、老爷庙、蚌湖、都昌和三山6个监测站点监测的叶绿素a浓度、氨氮、总氮、总磷、溶解氧等水质参数对二维水质模型参数进行率定,二维水质模型所需率定的主要参数和率定结果,如表1所示:
表1
如图5所示,以叶绿素a浓度模拟结果为例,2012/2/12012/12/31鄱阳湖区蛤蟆石、星子、老爷庙、蚌湖、都昌和三山6个监测站点监测的叶绿素a浓度模拟值和观测值对比,可以看出6个水质监测站点处叶绿素a浓度变化趋势模拟结果和观测的叶绿素a浓度变化趋势大体一致,但受模型参数、模型输入和模型结构不确定性的影响,观测值和模拟值之间还是存在一定的差异;
s2、根据所述二维水质模型初始化t时刻粒子的水位、流量、水质和t+1时刻粒子的参数,在具体实施例中,根据t时刻模型在各个网格处的状态变量x(水位z、流量q、水质c)和参数n的先验分布采样生成n个等权重的粒子,状态变量和参数的先验分布均采用均匀分布,初始化各粒子权重为
其中,
s3、根据所述二维水质模型在t+1时刻的水位、流量和水质边界条件生成t+1时刻粒子的边界条件,在具体实施例中,根据t+1时刻边界条件的先验分布,这里所有粒子的水质边界条件和模型的水质边界条件保持一致。
其中,
s4、根据所述t时刻的粒子的水位、流量、水质和t+1时刻粒子的边界条件和参数驱动二维水质模型更新得到t+1时刻粒子状态变量,在具体实施例中,利用t时刻各个粒子所代表的水流和水质状态作为初始条件,利用t+1时刻粒子边界条件和参数边界条件依驱动二维水质模型,实现二维水质模型模拟水位、流量和水质从t时刻到t+1时刻的更新,在具体实施例中,二维水质模型采用有限体积法离散二维水质模型控制方程,根据t时刻二维水质模型的水位、流量、水质和t+1时刻二维水质模型的边界条件和参数,采用显示方法muscl-hancock得到t+1时刻二维水质模型水位和水质:
其中,f(·)表示二维水质模型,mt+1和mt分别为t+1时刻二维水质模型水位和水质的状态变量,nmt+1和
s5、判断t+1时刻是否有水质观测值,若有,则计算t+1时刻各粒子的似然函数值,更新粒子的权重,并进入步骤s6,反之,则维持粒子权重不变,得到的t+1时刻的原始粒子集合,并进入步骤s7,所述计算t+1时刻各粒子的似然函数值
其中,
在具体实施例中,收集鄱阳湖2012/2/1~2012/12/31蛤蟆石、星子、老爷庙、蚌湖、都昌、三山6个水质监测站点的叶绿素a浓度原位监测数据,监测频次为每月1次,此外,还收集2012/4、2012/7和2012/10共3期叶绿素a浓度遥感监测结果,基于叶绿素a浓度原位观测和遥感观测数据开展鄱阳湖水质模型粒子滤波数据同化研究,叶绿素a浓度遥感监测均方根误差介于0.95~2.2μg/l,观测误差σ和同化频率af是影响同化效果的关键参数,同化精度随粒子数的增加而增加,但计算时间随粒子数的增加会呈线性增加,综合考虑同化精度和计算效率,将粒子数设置为100个;相比于叶绿素a浓度遥感监测,叶绿素a浓度原位观测具有更高的精度,同化过程中叶绿素a浓度原位观测σobs和三期叶绿素a浓度遥感观测标准差σrs分别设置为0.5μg/l和2μg/l(2012/4)、2μg/l(2012/7)、1μg/l(2012/10);同化频率和叶绿素a浓度原位和遥感观测频率保持一致;
s6、根据所述粒子的权重对粒子进行多项式重采样,得到新的粒子集合,在具体实施例中,多项式重采样算法通过将更新前的粒子权重集合组成多项式分布
s601、利用多项式重采样算法将所述粒子的权重集合组成多项式分布
s602、随机生成nr个服从(0,1]均匀分布的随机数rk~u(0,1],其中,rk表示均匀分布的随机数,且k=1,2...nr,nr=n,n表示粒子的总数,u表示状态变量和参数的均匀分布;
s603、计算各粒子的权重累积和序列,所述各粒子的权重累积和序列的表达式如下:
其中,ci+1,j表示第j个网格处第i+1个粒子权重累加值,ci,j表示第j个网格处第i粒子个权重累加值,
s604、统计权重累积区间(ci,j,ci+1,j]中落入随机数rk的次数,并将所述落入随机数rk的次数记为ni,j,得到粒子复制信息;
s605、根据所述粒子复制信息依次对粒子的状态变量进行复制,从而得到重采样后权重均等新的粒子集合
s7、根据所述新的粒子集合或t+1时刻的原始粒子集合分别计算所述二维水质模型的模拟水质状态变量和二维水质模型参数的最优估值,其中,
根据所述新的粒子集合计算所述二维水质模型的模拟水质状态变量的最优估值
其中,i表示粒子的编号,n表示粒子的总数,
根据所述新的粒子集合计算二维水质模型参数的最优估值
其中,
根据t+1时刻的原始粒子集合计算二维水质模型的模拟水质状态变量的最优估值
其中,i表示粒子的编号,n表示粒子的总数,
根据t+1时刻的原始粒子集合计算所述二维水质模型参数的最优估值
其中,
s8、令时刻t为t+1,并根据所述新的粒子集合的参数或原始粒子集合的参数利用核平滑方法将粒子的参数从t时刻递推到t+1时刻,其中,
根据所述新的粒子集合的参数利用核平滑方法将粒子的参数从t时刻递推到t+1时刻,其表达式如下:
其中,
根据所述原始粒子集合的参数利用核平滑方法将粒子的参数从t时刻递推到t+1时刻,其表达式如下:
其中,
在具体实施例中,如图6所示,2012/2/1~2012/12/31蛤蟆石、星子、老爷庙、蚌湖、都昌和三山站叶绿素a浓度同化值以及对应90%置信区间,可以看出,叶绿素a浓度同化值比模拟值要更加接近叶绿素a浓度观测值;如图7所示,6个监测站点叶绿素a浓度同化值和模拟值的平均相对误差对比,可以看出,6个监测站点叶绿素a浓度模拟值are介于25%~35%之间,模拟值are均值为29.8%,叶绿素a浓度同化值are介于9.6%~23.1%之间,同化值are均值为17.2%,通过同化叶绿素a浓度观测值,显著提升了叶绿素a浓度的模拟精度,由于该同化系统仅考虑了参数k1c的不确定性,所以叶绿素a浓度同化90%置信区间未能包含全部观测值。
在具体实施例中,由于叶绿素a浓度原位观测数据有限,利用粒子滤波同化算法同化叶绿素a浓度原位观测数据只能校正原位观测点处的叶绿素a浓度模拟结果,而叶绿素a浓度遥感监测结果能够捕捉叶绿素a浓度的空间分布,同化叶绿素a浓度遥感监测结果,能够校正整个湖区叶绿素a浓度的空间分布。如图8所示,以2012/7鄱阳湖叶绿素a浓度模型模拟结果、遥感监测结果和数据同化结果为例,可以看出,相比于叶绿素a浓度模拟结果,叶绿素a浓度同化结果和遥感监测结果更加接近,同化遥感观测数据,可以在同化时刻为模型提供更加准确的叶绿素a浓度的空间分布(初始条件)。
在具体实施例中,利用叶绿素a浓度观测值估计粒子叶绿素a浓度后验分布时,可以同步估计参数“20℃浮游植物饱和生长速率”(k1c)的后验分布,得到参数k1c的最优估计值。如图9所示,2012/2/1~2012/12/31鄱阳湖蛤蟆石、星子、老爷庙、蚌湖、都昌和三山6个监测站点处参数k1c的最优估计和90%置信区间,可以看出,6个监测站点处参数k1c最优估计随时间不断变化,不同监测站点处参数k1c的变化趋势并不一致;此外,不同时刻参数k1c90%不确定性区间的宽度不同,参数k1c90%不确定性区间并没有随同化次数的增加而逐渐变窄,说明参数k1c具有明显的时空变异性。粒子滤波同化算法校正叶绿素a浓度模拟结果的同时,可以根据粒子后验权重估计参数k1c的动态变化,但参数k1c的最优估计并不能代表20℃浮游植物真实的饱和生长速率,因为粒子权重是根据叶绿素a浓度模拟值和观测值之间的误差确定的,这个误差为模型参数不确定性、模型输入不确定性、模型结构不确定性导致的综合误差,参数k1c的最优估计能够一定程度平衡上述不确定性导致的模型模拟误差。由于不同时刻模型参数、模型输入和模型结构不确定性导致的误差可能会不断的变化,所以参数k1c的最优取值也可能不断变化,为了更好地估计参数k1c的动态变化,提高叶绿素a浓度模拟精度,应该增加同化的频次。
在具体实施例中,叶绿素a浓度原位观测数据有限,同化叶绿素a浓度原位观测数据只能校正原位观测点处的叶绿素a浓度模拟结果和参数k1c的取值,而叶绿素a浓度遥感监测结果能够捕捉叶绿素a浓度的空间分布,同化叶绿素a浓度遥感监测结果,校正整个湖区叶绿素a浓度的同时,可以估计参数k1c的空间分布。如图10所示,以同化2012/7鄱阳湖叶绿素a浓度遥感监测结果得到参数k1c的最优估计,可以看出利用粒子滤波同化算法得到的参数k1c的最优估计具有明显的时空变异性,同化不同时期叶绿素a浓度遥感监测结果得到参数k1c最优估计的空间分布存在较大差异,同化同一时期叶绿素a浓度遥感监测结果得到不同区域参数k1c的最优估计也存在较大差异,主要特征表现为:叶绿素a浓度模拟结果低于遥感监测结果的区域,参数k1c的最优估计要大于参数k1c的率定值,叶绿素a浓度模拟结果高于遥感监测结果的区域,参数k1c的最优估计要小于参数k1c的率定值,说明粒子滤波算法可以根据叶绿素a浓度模拟误差动态调整参数k1c取值。参数k1c最优估计的时空变异性表明了模型模拟误差同样具有时空变异性,为了更好地提高二维水质模型模拟效果,应当增加叶绿素a浓度遥感监测频次,及时更新二维水质模型的参数。
本发明通过以上设计,解决了现有水质模型粒子滤波数据同化研究中多采用空间均一的模型参数,忽略模型参数的空间变异性,难以同时得到不同空间(区域)水质模拟结果最优估计,无法适应二维水质模型数据同化的问题,以及水质模型粒子滤波数据同化中不能将水质原型观测和遥感观测的优势和水质模型模拟优势充分结合,从而限制了二维水质模型模拟和预测精度的问题。
- 还没有人留言评论。精彩留言会获得点赞!