信息处理方法、信息处理装置及程序与流程
将2018年5月24日提出的日本专利申请2018-099519的包括其说明书、附图及摘要的公开内容作为参照而全部援引于此。
本发明涉及信息处理方法、信息处理装置及程序。
背景技术:
在现有的信息处理技术中,进行使用了基于计算机的机器学习的判定及分类。作为该例子,进行生产的产品是合格品还是不合格品的判定(分类)。作为计算机的判定的一般性的技术,首先,以事先获得的合格品数据及不合格品数据为教师数据进行机器学习,生成学习模型。产品的缺陷包括各个类别(种类),为了按每个缺陷类别进行判定,需要每个缺陷类别的不合格品数据作为教师数据。图6是对于合格品数据及每个缺陷类别的不合格品数据而表示特征量的空间的示意图。如图6所示,在合格品数据及每个缺陷类别的不合格品数据各自之间设定判定的边界,在空间内分为合格品数据的组及每个缺陷类别的不合格品数据的组。在此,说明存在“缺陷1”“缺陷2”“缺陷3”作为缺陷类别的情况。
接下来,当得到成为检査的对象的产品数据时,向以该产品数据为输入数据而生成的所述学习模型输入。由此,产品数据被分类成与该产品数据具有的特征量最类似的特征量的组。即,通过图6的示意图进行说明时,进行成为对象的产品数据属于以所述判定的边界分割的多个区域(组)中的哪个区域的判定。日本特开2010-140444号公报公开了通过计算机进行机器学习及判定的技术。
在图6中,关于不合格品数据,存在“缺陷1”“缺陷2”“缺陷3”作为缺陷类别,按每个缺陷类别而特征量不同。根据以往的信息处理方法,如上所述,在表示特征量的空间内,在合格品数据及每个缺陷类别的不合格品数据各自之间设定判定的边界。即,判定的边界设定于通用的一个空间。于是,例如图6的箭头e所示,在成为对象的产品数据的特征量跨缺陷1与合格品的边界b1的情况下,具有该特征量的产品数据被(择一地)判定为是缺陷1和合格品中的任一方。
然而,在具有所述特征量的产品数据(箭头e)是基于与缺陷1不同的新的(未知的)类别的缺陷的数据的情况下,所述判定并非准确。在该情况下,存在如下的问题点:无论成为对象的产品数据是否为缺陷的数据,如果该特征相比已知的缺陷1而与合格品更相似,则在以往的信息处理方法中,都将该缺陷数据判定为是合格品的数据。
技术实现要素:
本发明的目的之一在于提供一种在成为对象的产品数据中包含基于未知的缺陷的数据的情况下,能够将该数据判定为是基于未知的缺陷的数据的信息处理方法、信息处理装置及程序。
本发明的一个方式的信息处理方法的结构上的特征在于,包括:学习步骤,进行以合格品数据为对象的有监督机器学习而生成合格品学习模型,并按每个缺陷类别进行以不合格品数据为对象的有监督机器学习而生成每个缺陷类别的不合格品学习模型;运算步骤,根据通过以成为对象的产品数据为输入数据并使用了所述合格品学习模型的运算而得到的输出数据,求出合格品的似然度,并且,根据通过以该产品数据为输入数据并使用了所述不合格品学习模型的运算而得到的输出数据,按每个缺陷类别求出不合格品的似然度;及判定步骤,当在所述运算步骤中求出的所述合格品的似然度及每个缺陷类别的所述不合格品的似然度满足与似然度相关的规定条件的情况下,将成为对象的所述产品数据判定为是基于未知的缺陷的数据。
附图说明
前述及后述的本发明的特征及优点通过下面的具体实施方式的说明并参照附图而明确,其中,相同的标号表示相同的部件。
图1是表示信息处理装置的硬件结构的一例的概略结构图。
图2是表示信息处理装置的软件结构的图。
图3是表示运算部及判定部进行的处理的概略的流程图。
图4是表示信息处理方法的流程图。
图5a、图5b、图5c是表示特征量的空间性的示意图。
图6是表示特征量的空间性的示意图(现有例)。
具体实施方式
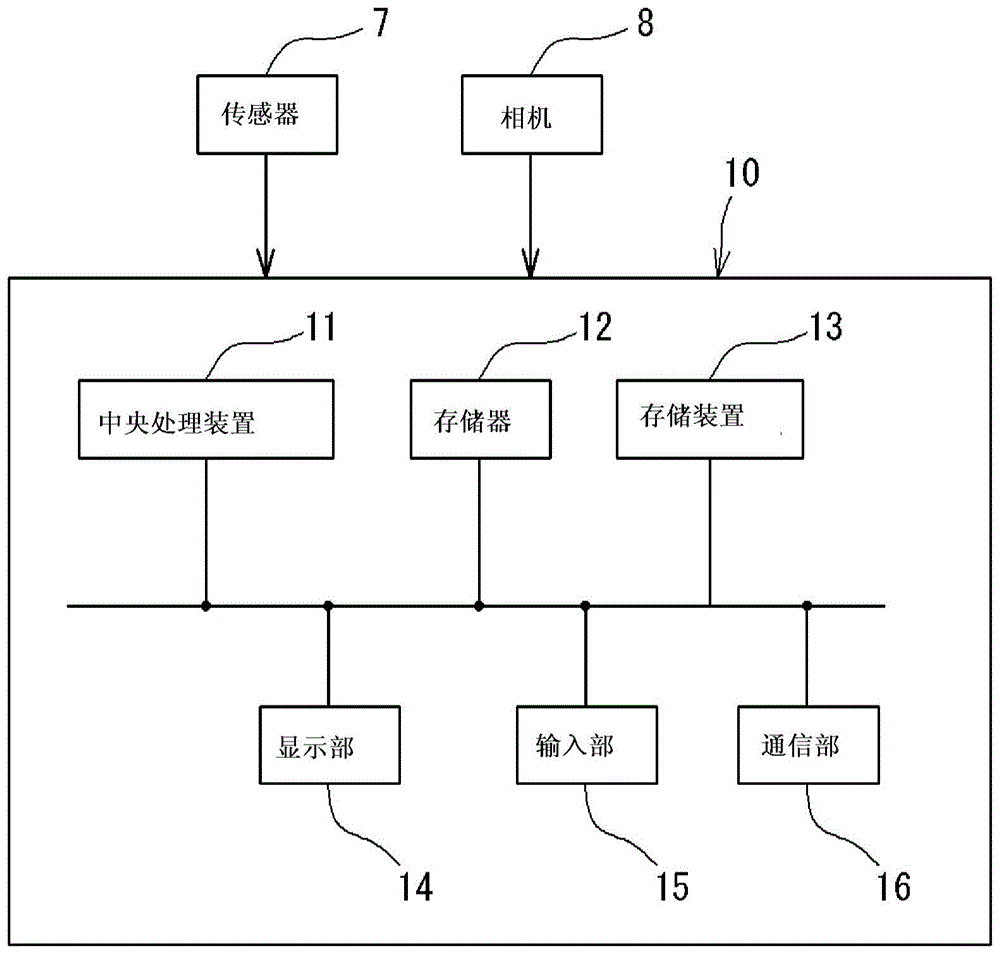
图1是表示信息处理装置的硬件结构的一例的概略结构图。本实施方式的信息处理装置10用于产品的生产线的检査工序。作为产品,除了例如滚动轴承的轨道圈那样的部件之外,还包括将多个部件组装而得到的组装品。作为组装品的例子,为例如转向装置(电动动力转向装置)及滚动轴承。
在产品为组装品的情况下,在检査工序中使产品动作(旋转),通过与产品的一部分接触的传感器7来计测产品的振动(声音)。通过传感器7的计测而得到的数据作为产品数据向信息处理装置10输入。产品无论是部件还是组装品,都可以在检査工序中通过相机8拍摄产品,进行外观检査。在该情况下,相机8的拍摄图像的数据作为产品数据向信息处理装置10输入。这样,能够将产品数据作为振动数据或图像数据(外观图像数据)。或者,产品数据可以是对于传感器7的振动数据(原始数据)进行了加工后的加工时据、或者对于相机8的图像数据(原始数据)进行了加工后的加工时据。作为加工时据的例子,可列举对于通过传感器7取得的作为时序数据的振动数据进行分析(傅里叶分析)而生成的频率数据。或者,加工时据可以是对拍摄图像的数据进行图像分析而得到的图像分析数据。在使用振动数据的情况下,信息处理装置10能够进行产品的动作检査。在使用图像数据的情况下,信息处理装置10能够进行产品的外观检査。
信息处理装置10具有对于在生产线中生产的产品进行合格品和不合格品的判别、对于不合格品进行其缺陷类别(种类)的判别、而且对于未知的缺陷也进行判别的功能。在此,对产品为转向装置并使用振动数据作为产品数据的情况进行说明。作为在该情况下的缺陷类别,可列举特定的齿轮部分的缺陷及特定的轴承部的缺陷作为例子。当使转向装置动作时,这些缺陷分别使具有不同的频率成分的振动产生。由于频率成分具有特征,因此基于该特征,信息处理装置10能够判别缺陷类别。此外,在使用图像数据作为产品数据的情况下,基于伤痕等的深浅被数据化,基于该数据而信息处理装置10能够判别缺陷类别。
说明信息处理装置10的结构。信息处理装置10具有中央处理装置(cpu)11、由rom及ram构成的存储器12、由硬盘驱动器构成的存储装置13、显示部14、输入部15及通信部16。中央处理装置11读取存储器12或存储装置13中存储的程序(计算机程序)而执行各种处理。存储装置13存储有从传感器7取得的数据、对该数据进行加工而得到的数据(产品数据)、各种阈值、后述的学习模型及程序等各种信息。后述说明的信息处理装置10具备的各种功能部(各功能部执行的处理)通过cpu11读取存储器12或存储装置13中保存的程序并执行该程序而实现。
通过信息处理装置10进行的信息处理来进行产品(转向装置)的检査。产品的检査(检査工序)包含于生产产品的生产线。将针对作为合格品的产品而得到的产品数据称为“合格品数据”。相对于此,将针对作为不合格品的产品而得到的产品数据称为“不合格品数据”。产品的缺陷包括各个类别(种类)。因此,为了将存在多个的已知的缺陷类别进行区分,以下,作为缺陷类别而如缺陷1,缺陷2,……缺陷n那样标注连续编号进行说明(n为整数)。在该情况下,缺陷类别的数量为n。这多个缺陷1,缺陷2,……缺陷n分别为已知的缺陷。而且,在产品的生产中,存在产生已知的缺陷以外的“未知的缺陷”的情况。此外,对于已知的缺陷,通过信息处理装置10进行机器学习,在后文进行说明。相对于此,未进行机器学习的缺陷是未知的缺陷。
图2是表示信息处理装置10的软件结构的图。信息处理装置10具备学习部21、运算部22及判定部23作为所述功能部。如上所述,这各功能部通过执行所述程序来实现。即,该程序是用于使计算机作为所述学习部21、所述运算部22及所述判定部23发挥功能的程序。该程序保存于各种存储介质。对所述各功能部进行说明。
学习部21具有生成学习模型的功能。学习部21通过机器学习而生成合格品学习模型及与该合格品学习模型不同的不合格品学习模型。在本实施方式中,如上所述存在多个已知的缺陷,因此生成每个缺陷类别的不合格品学习模型。例如,在存在三个已知的缺陷(缺陷1、缺陷2、缺陷3)的情况下,生成三个不合格品学习模型(m1、m2、m3)。在将n设为1以上的整数的情况下,将缺陷n的不合格品学习模型设为“不合格品学习模型mn”。
学习部21为了生成合格品学习模型而进行以合格品数据为对象的有监督机器学习。而且,学习部21为了生成每个缺陷类别的不合格品学习模型mn而按每个缺陷类别进行以不合格品数据为对象的有监督机器学习。将所述的各机器学习中使用的合格品数据与作为教师标签的“合格品标签”的信息建立对应(建立纽带),将不合格品数据与作为教师标签的“不合格品标签”的信息建立对应(建立纽带)。不合格品标签按每个缺陷类别而不同,将各不合格品标签与不合格品数据建立对应。
通过与使用合格品数据作为教师数据进行机器学习(合格品学习)的算法相同的算法,按每个缺陷类别使用不合格品数据作为教师数据进行机器学习(合格品学习)。其结果是,生成基于合格品数据的合格品学习模型,按每个缺陷类别来生成基于不合格品数据的不合格品学习模型。
作为学习部21使用的学习模型的例子,可列举variationalautoencoder(vae,变分自动编码器)。将合格品数据向vae的学习模型输入,执行学习,由此生成具有学习了合格品的参数的合格品学习模型。该合格品学习模型当被输入合格品数据时以得到再现了合格品数据的输出的方式学习。按每个缺陷类别,将不合格品数据向vae的学习模型输入,执行学习,由此生成具有学习了不合格品的参数的不合格品学习模型。这样,学习部21进行以合格品数据为对象的有监督机器学习而生成合格品学习模型,并按每个缺陷类别进行以不合格品数据为对象的有监督机器学习而生成每个缺陷类别的不合格品学习模型。生成的合格品学习模型及每个缺陷类别的不合格品学习模型存储于存储装置13。
图3是表示运算部22及判定部23进行的处理的概略的流程图。当从生产线生产产品时,作为检査工序,通过所述传感器7(参照图1)取得该产品的数据(产品数据)(图3的步骤s10)。产品数据作为检査的对象而连续不断地存储于信息处理装置10(存储装置13)。运算部22将各产品数据向通过学习部21生成的全部的学习模型(合格品学习模型及每个缺陷类别的不合格品学习模型)分别输入,取得从各学习模型输出的输出数据。判定部23基于所述输出数据,进行判定该各产品数据是否具有分别符合合格品、缺陷1、……缺陷n的可能性的处理(将该处理称为“独立判定处理”)(图3的步骤s20,步骤s21……)。判定部23还基于所述独立判定处理的结果,进行成为对象的产品数据是符合合格品,是符合已知的缺陷1、……缺陷n中的任一个,还是符合未知的缺陷的判定(图3的步骤s30)。
说明运算部22进行的处理的具体例。运算部22求出作为输入数据的产品数据与输出数据之差(均方差)作为判定值。在此,向关于缺陷1的不合格品学习模型m1输入缺陷1的数据时,输出再现了缺陷1的数据的数据。因此,在向不合格品学习模型m1输入了缺陷1的数据时,所述判定值减小。相对于此,当向不合格品学习模型m1输入缺陷1的数据以外的数据(例如缺陷2的数据)时,与输入了缺陷1的数据的情况相比,所述判定值增大。运算部22将求出的所述判定值转换成似然度。似然度是表示似然性的指标。例如缺陷1的似然度是表示“缺陷1相像度”的指标。因此,在缺陷1的所述判定值(所述差)小的情况下,缺陷1的似然度高。即,向缺陷n的学习模型mn输入的产品数据的所述判定值小的情况下(似然度高的情况下),能够推定为该产品数据存在与类别为缺陷n的缺陷数据相像的可能性。同样,向合格品的学习模型输入的产品数据的所述判定值小的情况下(似然度高的情况下),可以推定为该产品数据存在类别为合格品的数据相像的可能性。
这样,运算部22根据通过以成为对象的产品数据为输入数据并使用了合格品学习模型的运算而得到的输出数据,求出合格品的似然度。而且,运算部22根据通过以成为对象的所述产品数据为输入数据并使用了不合格品学习模型mn的运算而得到的输出数据,按每个缺陷类别来求出不合格品的似然度。求出的似然度(所述判定值)按照使用的各学习模型来区分,存储于存储装置13。
说明判定部23进行的处理。判定部23将由运算部22求出的对于成为对象的产品数据的合格品的似然度与合格品用的阈值进行比较。此外,判定部23具有进行将对于该产品数据的缺陷n的似然度与缺陷n用的阈值比较的处理的功能。此外,判定部23具有基于上述比较的处理的结果判定该产品数据是合格品数据、是已知的不合格品数据、还是未知的不合格品数据的功能。此外,在判定为是已知的不合格品数据的情况下,也判定缺陷类别。此外,所述阈值是预先设定的值,在合格品的情况与不合格品的情况下可以不同,也可以相同。而且,按每个缺陷类别而所述阈值可以不同,也可以相同。判定部23对于产品数据,在缺陷n的似然度比缺陷n的阈值大的情况下(缺陷n的所述判定值小的情况下),能够判定(推定)为该产品的数据存在缺陷n的数据相像的可能性。
这样,判定部23进行由运算部22求出的合格品的似然度及每个缺陷类别的不合格品的似然度是否满足与似然度相关的规定条件的判定。作为一例,判定部23在由运算部22求出的合格品的似然度及每个缺陷类别的不合格品的似然度满足与似然度相关的“规定条件”的情况下,将成为对象的产品数据判定为是基于未知的缺陷的数据,在后文进行说明。所述“规定条件”是“按每个缺陷类别进行的与所述阈值的比较的结果为全部的不合格品的似然度小于不合格品的阈值且合格品的似然度小于合格品的阈值这样的条件”。判定部23的处理的详情通过后文的信息处理方法进行说明。
关于具备所述结构的信息处理装置10进行的信息处理方法,通过图4进行说明。在该信息处理方法中,首先,进行基于学习部21的机器学习(学习步骤),接下来,基于机器学习的结果,进行基于运算部22的运算(运算步骤)及基于判定部23的判定(判定步骤)。
说明学习部21进行的机器学习。使用缺陷1的不合格品标签作为教师标签而进行以产品数据(缺陷1的不合格品数据)为对象的机器学习,生成不合格品学习模型m1(图4的步骤s1)。该处理对于已知的全部缺陷反复(n次)单独进行。即,按照存在多个的每个缺陷类别进行所述那样的学习模型的生成处理,生成每个缺陷类别的不合格品学习模型(图4的步骤s2)。使用合格品标签作为教师标签进行以产品数据(合格品数据)为对象的机器学习,生成合格品学习模型(图4的步骤s9)。通过该学习步骤,生成每个缺陷类别的不合格品学习模型(即,n个不合格品学习模型)及一个合格品学习模型。在图3中,从步骤s1经由步骤s2进行步骤s9的工序是学习步骤。此外,所述教师标签的提取及建立对应由作业员进行。
当通过生产线生产产品时,例如通过传感器7(参照图1),按照每个产品取得产品数据da(步骤s11)。信息处理装置10(存储器12或存储装置13)具有保存数据(数据组)的存储区域。当运算部22取得一个产品数据作为处理对象时,将所述存储区域进行初始化(步骤s12)。在图4中,将该存储区域设为“阵列a[]”,在以下的说明中,也将该存储区域设为阵列a[]。
运算部22将成为处理对象的所述产品数据da向使用了学习部21生成的缺陷1的不合格品学习模型m1的运算算法输入,从该运算算法取得输出数据。运算部22基于该输出数据,算出以所述产品数据da为对象的缺陷1的似然度p1(步骤s21)。此外,以下进行的处理除了特别说明的情况之外是运算部22进行的处理。在本实施方式中,还求出输入的产品数据da与输出数据之差,将该差作为判定值。该判定值被转换成缺陷1的似然度p1。判定部23进行缺陷1的似然度p1与缺陷1用的阈值t1的比较(步骤s22)。在比较的结果是缺陷1的似然度p1为阈值t1以上的情况下(在步骤s22中为“是”的情况下),判定部23将似然度p1与阈值t1之差(p1-t1)存储于阵列a[](步骤s23)。相对于此,在比较的结果是缺陷1的似然度p1小于阈值t1的情况下(在步骤s22中为“否”的情况下),在阵列a[]不保存数据,进入下一步骤(步骤s24)。
所述处理按每个缺陷类别进行。即,运算部22将成为处理对象的所述产品数据da向使用了学习部21生成的缺陷n的不合格品学习模型mn的运算算法输入,从该运算算法取得输出数据。运算部22基于该输出数据,算出以所述产品数据da为对象的缺陷n的似然度pn(步骤s24)。进而,求出输入的产品数据da与输出数据之差,将该差作为判定值。该判定值被转换成缺陷n的似然度pn。判定部23进行缺陷n的似然度pn与缺陷n用的阈值tn的比较(步骤s25)。在比较的结果是缺陷n的似然度pn为阈值tn以上的情况下(在步骤s25中为“是”的情况下),判定部23将似然度pn与阈值tn之差(pn-tn)存储于阵列a[](步骤s26)。相对于此,在比较的结果是缺陷n的似然度pn小于阈值tn的情况下(在步骤s25中为“否”的情况下),在阵列a[]中不保存数据而进入下一步骤。
在对于全部缺陷类别进行所述产品数据da的处理时,判定部23判定在阵列a[]中是否保存有数据(步骤s27)。在保存有数据的情况下(在步骤s27中为“是”的情况下),判定部23在阵列a[]中提取所述差成为最大的缺陷类别。将提取到的缺陷类别判定为成为处理对象的所述产品数据da的缺陷类别(步骤s28)。
相对于此,在阵列a[]中未保存数据的情况下(在步骤s27中为“否”的情况下),进入下一步骤s29。在步骤s29中,运算部22将成为处理对象的所述产品数据da向使用了学习部21生成的合格品学习模型的运算算法输入,从该运算算法取得输出数据。运算部22基于该输出数据,算出合格品的似然度p0(步骤s29)。此外,以下进行的处理是除了特别说明的情况之外运算部22进行的处理。在本实施方式中,求出输入的产品数据da与输出数据之差,将该差作为判定值。该判定值被转换成合格品的似然度p0。判定部23进行合格品的似然度p0与合格品用的阈值t0的比较(步骤s30)。在比较的结果是合格品的似然度p0为阈值t0以上的情况下(在步骤s30中为“是”的情况下),判定部23将成为对象的产品数据da判定为是合格品数据(步骤s31)。相对于此,在比较的结果是合格品的似然度p0小于阈值t0的情况下(在步骤s30中为“否”的情况下),判定部23将成为对象的产品数据da判定为是未知的缺陷的数据(步骤s32)。
如上所述,在阵列a[]中未保存数据的情况下(在步骤s27中为“否”的情况下),即,全部的不合格品的似然度小于不合格品的阈值的情况下,合格品的似然度p0小于阈值t0的情况下(在步骤s30中为“否”的情况下),判定部23将成为对象的产品数据da判定为是基于未知的缺陷的数据(步骤s32)。
如以上所述,本实施方式的信息处理方法包括学习步骤、运算步骤、判定步骤。运算步骤及判定步骤按照各产品数据反复执行。
在学习步骤中,进行以合格品数据为对象的有监督机器学习而生成合格品学习模型(图4的步骤s9),并按每个缺陷类别进行以不合格品数据为对象的有监督机器学习而生成每个缺陷类别的不合格品学习模型(图4的步骤s1、步骤s2)。学习步骤由学习部21执行。
作为运算步骤,根据通过以成为对象的产品数据da为输入数据并使用了所述合格品学习模型的运算而得到的输出数据,求出合格品的似然度p0(步骤s29)。伴随于此,根据通过以该产品数据da为输入数据并使用了所述不合格品学习模型的运算而得到的输出数据,按每个缺陷类别求出不合格品的似然度(p1,……pn)(步骤s21、步骤s24)。运算步骤由运算部22执行。
在本实施方式中,作为判定步骤,进行合格品的似然度p0与合格品的阈值t0的比较(步骤s30),并按每个缺陷类别进行不合格品的似然度(p1,……pn)与不合格品的阈值(t1,……tn)的比较(步骤s22、步骤s25)。此外,可以与图4所示的流程不同,先进行合格品的似然度p0与阈值t0的比较之后,进行不合格品的似然度(p1,……pn)与阈值(t1,……tn)的比较。然而,在本实施方式中,优选如图4所示的流程那样,先按每个缺陷类别进行不合格品的似然度(p1,……pn)与阈值(t1,……tn)的比较,然后进行合格品的似然度p0与阈值t0的比较。判定步骤由判定部23执行。
作为判定步骤,当在运算步骤中求出的合格品的似然度p0及每个缺陷类别的不合格品的似然度(p1,……pn)满足与似然度相关的“规定条件”的情况下,将成为对象的所述产品数据da判定为是基于未知的缺陷的数据(步骤s32)。即,如所述实施方式那样,按每个缺陷类别进行不合格品的似然度(p1,……pn)与不合格品的阈值(t1,……tn)的比较(步骤s22、步骤s25)。伴随于此,进行合格品的似然度p0与合格品的阈值t0的比较(步骤s30),按每个缺陷类别进行的所述比较的结果是全部的不合格品的似然度(p1,……pn)小于不合格品的阈值(t1,……tn)且合格品的似然度p0小于合格品的阈值t0的情况下,将成为对象的所述产品数据da判定为是基于未知的缺陷的数据。即,所述“规定条件”是“按每个缺陷类别进行的所述比较的结果是全部的不合格品的似然度(p1,……pn)小于不合格品的阈值(t1,……tn)且合格品的似然度p0小于合格品的阈值t0这样的条件”。
在所述比较的结果为“全部的不合格品的似然度(p1,……pn)小于不合格品的阈值(t1,……tn)”的情况下,不认为成为对象的产品数据da是具有已知的缺陷的不合格品的数据。并且,在“合格品的似然度p0小于合格品的阈值t0”的情况下,不认为成为对象的产品数据da是合格品数据。因此,在满足所述规定条件的情况下,能够将成为对象的产品数据da判定为是基于未知的缺陷的数据。
在判定步骤中,按每个缺陷类别进行的比较的结果是对于多个缺陷类别(例如,对于缺陷1及缺陷n),不合格品的似然度为不合格品的阈值以上时(p1≥t1且pn≥tn时),即,在步骤s22中为“是”且在步骤s25中也为“是”时的具体的判定如下所述。将这多个缺陷类别中的与不合格品的阈值之差为最大的缺陷类别判定为成为对象的产品数据da的缺陷类别。例如,设缺陷1的似然度p1与其阈值t1之差(p1-t1)为α,缺陷n的似然度pn与其阈值tn之差(pn-tn)为β。在此,在α比β大的情况下,判定为成为对象的产品数据da是缺陷数据,且缺陷类别是“缺陷1”。差(p1-t1)被保存于阵列a[],由于该差(p1-t1)成为最大,因此将缺陷类别判定为“缺陷1”。
在此,所述“不合格品的似然度为不合格品的阈值以上”且“不合格品的似然度与不合格品的阈值之差为最大”这样的情况是指多个缺陷类别之中该缺陷类别最相像的情况。因此,即使对于多个缺陷类别不合格品的似然度成为不合格品的阈值以上时(p1≥t1且pn≥tn时),也能够判定似然的一个缺陷类别。
在判定步骤中,在按每个缺陷类别进行的比较的结果(步骤s22、步骤s25)是对于一个类别的不合格品的似然度为不合格品的阈值以上时,将成为对象的产品数据da判定为是基于该一个类别的缺陷的数据。例如,在缺陷1的似然度p1为其阈值t1以上(在步骤s22中为“是”)且其他的全部的缺陷的似然度小于该阈值的情况下,仅将与缺陷1的似然度p1相关的数据保存于阵列a[]。因此,根据步骤s28,将缺陷类别判定为“缺陷1”。通过进行这样的判定,能够判定似然的一个缺陷类别。
另外,在判定步骤中,在按每个缺陷类别进行的比较的结果是全部的不合格品的似然度(p1,……pn)小于不合格品的阈值(t1,……tn)(在步骤s22及步骤s25中分别为“否”)且合格品的似然度p0为合格品的阈值t0以上的情况下(在步骤s30中为“是”的情况下),将成为对象的产品数据da判定为是基于合格品的数据。即,在所述比较的结果为“全部的不合格品的似然度(p1,……pn)小于不合格品的阈值(t1,……tn)”的情况下,不认为成为对象的产品数据da是具有已知的缺陷的不合格品数据。并且,在“合格品的似然度p0为合格品的阈值t0以上”的情况下,不认为成为对象得到产品数据da是合格品的数据。因此,能够将该情况下的成为对象的产品数据da判定为是基于合格品的数据。
如以上所述,根据本实施方式的信息处理方法,在学习步骤中,与合格品学习模型另行地生成每个缺陷类别的不合格品学习模型。图5a、图5b、图5c是对于合格品数据及每个缺陷类别的不合格品数据通过执行本实施方式的学习步骤而得到的表示特征量的空间的示意图。即,进行以合格品数据为对象的有监督机器学习(合格品学习)而生成合格品学习模型。由此,如图5a所示,在表示用于判定合格品的特征量的空间中,能得到仅包含合格品数据而且在学习使用的合格品数据的附近设定的判定边界l0。进行以缺陷1的不合格品数据为对象的有监督机器学习(不合格品学习)而生成不合格品学习模型m1,由此如图5b所示,在表示用于判定缺陷1的特征量的空间中,能得到仅包含缺陷1的不合格品数据而且在学习使用的不合格品数据的附近设定的判定边界l1。而且,进行以缺陷n的不合格品数据为对象的有监督机器学习(不合格品学习)而生成不合格品学习模型mn。由此,如图5c所示,在表示用于判定缺陷n的特征量的空间中,能得到仅包含缺陷n的不合格品数据而且在学习使用的不合格品数据的附近设定的判定边界ln。以上,如图5a、图5b、图5c所示,用于进行合格品及不合格品(各类别)的判别的所谓判定的边界按照每个合格品及缺陷的类别,分别作为相互不同的空间而得到。
因此,在以成为对象的产品数据da为输入数据在运算步骤中求出的合格品的似然度及每个缺陷类别的不合格品的似然度满足与似然度相关的所述规定条件的情况下,能够将成为该对象的产品数据判定为是基于未知的缺陷的数据(步骤s32)。即,在表示图5a、图5b、图5c所示的特征量的各空间中,在产品数据da的特征量存在于各判定边界的外的区域的情况下,将该产品数据da判定为是基于未知的缺陷的数据。
此外,在以往的信息处理方法中,如通过图6说明那样,如果成为对象的产品数据为未知的缺陷的数据(箭头e),其特征(虽然与已知的缺陷1及合格品的特征存在分隔但是)相比已知的缺陷1而与合格品更相似,则将该缺陷数据判定为是合格品的数据。然而,根据本实施方式的信息处理方法,在成为对象的产品数据da为未知的缺陷的数据的情况下,能够将该产品数据da判定为是基于未知的缺陷的数据。即,能够防止将不合格品判定为合格品的情况。
另外,在本实施方式中,如上所述(参照图4),作为判定步骤,在判定为按每个缺陷类别求出的不合格品的似然度(p1,……pn)是否满足与似然度相关的规定条件之后,判定合格品的似然度p0是否满足与似然度相关的规定条件。因此,难以发生虽然成为对象的产品数据da为基于不合格品的数据但是判定为是基于合格品的数据的差错。
本次公开的实施方式在全部的点上为例示而不受限制。本发明的权利范围没有限定为上述的实施方式,包括与权利要求书的范围记载的结构等同的范围内的全部变更。成为对象的产品可以是转向装置及滚动轴承以外的产品,各种组装品及机械部件成为对象。产品数据可以是振动数据及图像数据以外的数据,可以是温度数据(温度变化数据)等。在所述实施方式中,说明了求出作为输入数据的产品数据与输出数据之差作为判定值,将该判定值转换成似然度的情况。然而,关于似然度的计算,也可以为其他的手段。
根据本发明,在成为对象的产品数据包含基于未知的缺陷的数据的情况下,能够判定为该数据是基于未知的缺陷的数据。
- 还没有人留言评论。精彩留言会获得点赞!