基于语音识别的会议室预定方法、装置、设备及存储介质与流程
本发明涉及人工智能技术领域,尤其涉及一种基于语音识别的会议室预定方法、装置、设备及存储介质。
背景技术:
当前的会议室预定方法需要用户根据开会时间、与会人数等信息自行挑选可用的会议室,因此,会议室预定流程复杂,用户难以订到符合需要的会议室,会议室使用效率不高。
技术实现要素:
本发明提供一种基于语音识别的会议室预定方法、装置、设备及存储介质,旨在简化会议室预定流程,提高会议室预定的智能性。
为实现上述目的,本发明提供一种基于语音识别的会议室预定方法,所述方法包括:
接收用户发送的会议室预定语音;
识别所述会议室预定语音,获得待预定会议室参数;
基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度;
将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择。
优选地,所述将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择的步骤之后还包括:
获取用户选择的所述可用会议室以及预定时间,将用户选择的所述可用会议室标记为目标预定会议室;
将所述目标预定会议室在所述预定时间内的使用状态标记为使用中。
优选地,所述将所述目标预定会议室在所述预定时间内的使用状态标记为使用中的步骤之后还包括:
接收用户发送的会议室退订指令,从所述会议室退订指令获取待退订会议室;
将所述待退订会议室在退订时间段内的使用状态修改为空闲。
优选地,所述识别所述会议室预定语音,获得待预定会议室参数的步骤之前还包括:
提取所述会议室预定语音中的声纹信息,将所述声纹信息与预存声纹信息进行对比;
若所述声纹信息与所述预存声纹信息一致,则执行步骤:识别所述会议室预定语音,获得待预定会议室参数;
若所述声纹信息与所述预存声纹信息不一致,则忽略所述会议室预定语音。
优选地,所述识别所述会议室预定语音,获得待预定会议室参数的步骤包括:
对所述会议室预定语音进行预处理,切除所述会议室预定语音中首尾端的静音,并将所述会议室预定语音进行分帧,获得多个帧;
提取多个所述帧中的特征向量,并获得与所述特征向量对应的文字;
获取所述文字中的多个关键字;
将多个所述关键字分别填入预设的待预定会议室参数模板中,获得所述待预定会议室参数。
优选地,所述基于预设匹配度算法计算所述待预定会议室参数与可用会议室参数之间的匹配度的步骤之前还包括:
预先保存所有会议室的会议室参数和使用状态,将所述使用状态在特定时间段内为空闲的会议室标记为可用会议室,并将所述可用会议室的会议室参数标记为所述可用会议室参数,其中,所述特定时间段由预先设定的时间浮动范围以及所述会议室预定参数中的起始时间和持续时间决定。
优选地,所述基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度的步骤包括:
将所述待预定会议室ma表示为:ma=(fa,sa,la,na);
将所述可用会议室mr表示为:mr=(fr,sr,lr,nr);其中,fa,sa,la,na为所述待预定会议室参数,fr,sr,lr,nr为所述可用会议室参数,f表示楼层,s表示起始时间,l表示会议持续时长,n表示与会人数;
将所述匹配度计算公式表示为:
将所述权重因子、所述可用会议室参数、所述待预定会议室参数代入所述匹配度计算公式计算所述匹配度。
为实现上述目的,本发明还提供一种基于语音识别的会议室预定装置,所述基于语音识别的会议室预定装置包括:
接收模块,用于接收用户发送的会议室预定语音;
语音识别模块,用于识别所述会议室预定语音,获得待预定会议室参数;
计算模块,用于基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度;
推荐模块,用于将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择。
为实现上述目的本发明还提供一种基于语音识别的会议室预定设备,所述基于语音识别的会议室预定设备包括处理器,存储器以及存储在所述存储器中的基于语音识别的会议室预定程序,所述基于语音识别的会议室预定程序被所述处理器运行时,实现如上所述的基于语音识别的会议室预定方法的步骤。
为实现上述目的本发明还提供一种计算机存储介质,所述计算机存储介质上存储有基于语音识别的会议室预定程序,所述基于语音识别的会议室预定程序被处理器运行时实现如上所述基于语音识别的会议室预定方法的步骤。
相比现有技术,本发明提出的一种基于语音识别的会议室预定方法、装置、设备及存储介质,该方法包括:接收用户发送的会议室预定语音;识别所述会议室预定语音,获得待预定会议室参数;基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度;将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择。本发明在人工智能的基础上,基于语音识别获得待预定会议室参数,再根据匹配度计算公式获得待预定会议室参数与可用会议室参数之间的匹配度,并将匹配度高于预设匹配度阈值的可用会议室推荐给用户,由此简化了会议室预定流程,提高了会议室预定的智能性。
附图说明
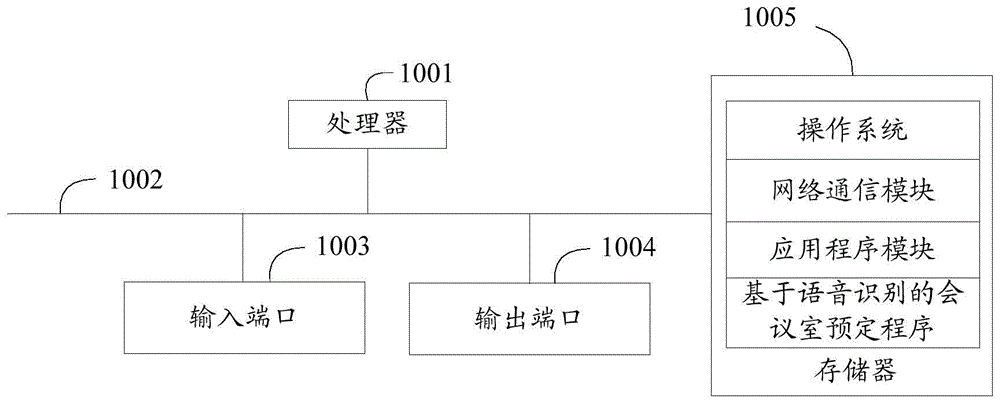
图1是本发明各实施例涉及的基于语音识别的会议室预定设备的硬件结构示意图;
图2是本发明基于语音识别的会议室预定方法第一实施例的流程示意图;
图3是本发明基于语音识别的会议室预定方法第二实施例的流程示意图;
图4是本发明基于语音识别的会议室预定装置第一实施例的功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明实施例主要涉及的基于语音识别的会议室预定设备是指能够实现网络连接的网络连接设备,所述基于语音识别的会议室预定设备可以是服务器、云平台等。
参照图1,图1是本发明各实施例涉及的基于语音识别的会议室预定设备的硬件结构示意图。本发明实施例中,基于语音识别的会议室预定设备可以包括处理器1001(例如中央处理器centralprocessingunit、cpu),通信总线1002,输入端口1003,输出端口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信;输入端口1003用于数据输入;输出端口1004用于数据输出,存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatilememory),例如磁盘存储器,存储器1005可选的还可以是独立于前述处理器1001的存储装置。本领域技术人员可以理解,图1中示出的硬件结构并不构成对本发明的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
继续参照图1,图1中作为一种可读存储介质的存储器1005可以包括操作系统、网络通信模块、应用程序模块以及基于语音识别的会议室预定程序。在图1中,网络通信模块主要用于连接服务器,与服务器进行数据通信;而处理器1001可以调用存储器1005中存储的基于语音识别的会议室预定程序,并执行本发明实施例提供的基于语音识别的会议室预定方法。
本发明实施例提供了一种基于语音识别的会议室预定方法。
参照图2,图2是本发明基于语音识别的会议室预定方法第一实施例的流程示意图。
本实施例中,所述基于语音识别的会议室预定方法应用于基于语音识别的会议室预定设备,所述方法包括:
步骤s101,接收用户发送的会议室预定语音;
当前很多会议室的预定都需要人工记录预定情况,即使有些公司开发了线上预定会议室的产品,但仍然用户需要在会议室预定过程中,在预设的会议室配置界面输入所需要会议室的详细信息,例如会议室编号、占用时间等。
本实施例中,利用基于语音识别的会议室预定设备的录音功能,接收用户的会议室预定语音,所述会议室预定语音包括待预定会议室参数,所述待预定会议室参数包括楼层、起始时间、会议持续时长、与会人数中的一个或多个。
进一步地,所述接收用户发送的会议室预定语音的步骤之前还包括:
通过基于语音识别的会议室预定设备的显示屏显示语音输入提示,以供用户参考所述语音输入提示进行语音输入。
当检测到用户需要输入会议室预定语音时,通过所述基于语音识别的会议室预定设备的显示屏显示语音输入提示,或者以语音的方式播放预先录制的语音输入提示文件。参例如所述语音输入提示可以是:我需要预定今天下午x点到y点xx楼x人的会议室。
步骤s102,识别所述会议室预定语音,获得待预定会议室参数;
本实施例中,所述识别所述会议室预定语音,获得待预定会议室参数的步骤包括:
步骤s102-1,对所述会议室预定语音进行预处理,切除所述会议室预定语音中首尾端的静音,并将所述会议室预定语音进行分帧,获得多个帧;
首先获取所述会议室预定语音中的静音:将所述会议室预定语音分成固定长度的语音,并形成一个语音序列,提取所述语音序列中每一段语音的短时能量、短时过零率和短时信息熵三个音频特征参数;根据音频特征参数计算每一帧数据的短时能频值,并形成一个短时能频值序列;从第一段语音开始,分析短时能频值序列,并找出每一段语音的起点和终点;将所述起点和所述终点之外的语音标记为静音期,所述静音期内的语音即为静音。所述静音包括所述会议室预定语音中首尾端的静音,由此通过消除所述静音以达到在不降低业务质量的情况下节省资源并降低干扰的作用。进一步地,将切除了静音的所述会议室预定语音切开成一小段一小段,例如每25ms为一小段,每一小段称为一帧,由此分帧后可获得多个帧,一般地,可以使用移动窗函数来实现,相邻的帧之间一般有相互交叠的部分。若每帧的长度为25ms,可以在相邻的帧之间设置15ms的交叠,如此,以帧长25ms,帧移10ms进行分帧。
步骤s102-2,提取多个所述帧中的特征向量,并获得与所述特征向量对应的文字;
分帧后,所述会议室预定语音变成了多个帧,但是波型在时域上不具有描述能力,因此必须进一步进行波型变换。具体地,对所述多个帧进行加窗,获得多个短时分析窗,得到对应的频谱;并用滤波器对所述频谱进行滤波获得滤波频谱;对所述滤波频谱通过取对数、逆变换的方式进行倒谱分析,获得获得所述会议室预定语音的特征向量。由此,根据所述会议室预定语音中的声学特征将所述会议室预定语音中的每一帧变成一个多维的特征向量,所述特征向量包括该帧会议室预定语音的内容信息。
所述获得与所述特征向量对应的文字的步骤包括:
具体地,预先提取大量训练语音中的特征向量,获得训练特征向量,利用所述训练特征向量进行声学模型训练。所述声学模型可以输出与所述特征向量对应的音素信息。从字典中查询与所述音素信息对应的字和/或词。将所述字和/或词输入预先训练的所述语言模型,得到与所述字和/或词相互关联的概率,再基于所述概率,输出语序合理的文字,所述文字与所述特征向量对应。其中所述语言模型是通过对大量文本信息进行训练后得到的,利用所述语言模型可以获得单个字或词相互关联的概率。
步骤s102-3,获取所述文字中的多个关键字;
具体地,获取与会议室预定相关的关键字,并去除多余的文字。预先设置关键字库,所述关键字库包括数字、时间、楼层等与会议室预定有关的关键字。将所述文字中与所述关键字库中相同的字和\或词标记为关键字。可以理解地,所述关键字有多个。
步骤s102-4,将多个所述关键字分别填入预设的待预定会议室参数模板中,获得所述待预定会议室参数。
本实施例中,预先设置待预定会议室参数模板,所述待预定会议室参数模板中包括多个所述关键字的填入位置,以便填入所述关键字,获得所述待预定会议室参数。例如所述待预定会议室参数模板可以设置为:楼层是(xf),起始时间是(xs),持续时长是(xl),与会人数是(xn);其中括号内的xf、xs、xl以及xn为相应内容的数值。
进一步地,所述识别所述会议室预定语音,获得待预定会议室参数的步骤之前还包括:
步骤s102a:提取所述会议室预定语音中的声纹信息,将所述声纹信息与预存声纹信息进行对比;
本实施例中,预先采集一个或多个预定声纹信息,为所述预定声纹信息配置会议室预定权限,并记录所述会议室预定声纹信息对应用户的详细信息,例如姓名、联系电话、邮箱、职位等。当接收到用户发送的会议室预定语音后,提取所述会议室预定语音中的声纹信息,并将所述声纹信息与预存声纹信息进行对比;
若所述声纹信息与所述预存声纹信息一致,则判定所述声纹信息对应的用户具有会议室预定权重,则执行步骤:识别所述会议室预定语音,获得待预定会议室参数;若所述声纹信息与所述预存声纹信息不一致,则判定所述声纹信息对应的用户不具有会议室预定权重,则忽略所述会议室预定语音。由此,可以防止不具有权限的用户进行会议室预定,便于会议室预定的管理。
步骤s103,基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度;
本实施例中,所述基于预设匹配度算法计算所述待预定会议室参数与可用会议室参数之间的匹配度的步骤之前还包括:预先保存所有会议室的会议室参数和使用状态,将所述使用状态在特定时间段内为空闲的会议室标记为可用会议室,并将所述可用会议室的会议室参数标记为所述可用会议室参数,其中,所述特定时间段由预先设定的时间浮动范围以及所述会议室预定参数中的起始时间和持续时间决定。由此,预先获得本公司、本建筑内的所有会议室的所述会议室参数,并将所有会议室的所述会议室参数保存至数据库,以便调用。可以理解地,所述使用状态包括使用中、空闲以及维护状态。对于会议室而言,所述使用状态又与时间相关,故将在特定时间段内为空闲的会议室标记为可用会议室。其中,所述特定时间段由预先设定的时间浮动范围以及所述会议室预定参数中的起始时间和持续时间决定。所述时间浮动范围可以具体设置,例如所述起始时间的前后的一定时长,例如60min、120min等;或者所述起始时间点的向前或向后移动预设天数,例如起始时间点向前一天或往后若干天。
本实施例中,所述基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度的步骤包括:
步骤a:将所述待预定会议室ma表示为:ma=(fa,sa,la,na);
步骤b:将所述可用会议室mr表示为:mr=(fr,sr,lr,nr);其中,fa,sa,la,na为所述待预定会议室参数,fr,sr,lr,nr为所述可用会议室参数,f表示楼层,s表示起始时间,l表示会议持续时长,n表示与会人数;
可以理解地,所述待预定会议室参数和所述可用会议室参数可以包括比f、s、l、n更多或更少的参数。
步骤c:将所述匹配度计算公式表示为:
进一步地,所述ηf、ηs、ηl、ηn的设置方法如下:
其中,x1,x2,x3,x4,x5表示所述楼层差,本实施例中x1<x2<x3<x4<x5,均为正整数,根据所述楼层差确定所述楼层权重因子ηf的取值:当所述楼层差在[0,x1]之间,所述ηf的取值为ηf1;当所述楼层差在[x2,x3]之间,所述ηf的取值为ηf2;当所述楼层差在[x4,x5]之间,所述ηf的取值为ηf3;其中ηf1,ηf2,ηf3的值可以根据经验设置,例如分别设置为0.8、1.0以及1.2。
其中,y1,y2,y3,y4,y5表示所述起始时间差,并且y1<y2<y3<y4<y5,根据所述起始时间差确定所述起始时间权重因子ηs的取值:当所述楼层差在[0,y1]之间,所述ηs的取值为ηs1;当所述楼层差在[y2,y3]之间,所述ηs的取值为ηs2;当所述楼层差在[y4,y5]之间,所述ηs的取值为ηs3;其中,ηs1,ηs2,ηs3的值可以根据经验设置,例如分别设置为0.8、1.0以及1.2。
其中,z1,z2,z3,z4,z5表示所述会议持续时长差,并且z1<z2<z3<z4<z5,根据所述会议持续时长差确定所述会议持续时长因子ηl的取值:当所述会议持续时长差在[0,z1]之间,所述ηl的取值为ηl1;当所述会议持续时长差在[z2,z3]之间,所述ηl的取值为ηl2;当所述会议持续时长差在[z4,z5]之间,所述ηl的取值为ηl3;其中,ηl1,ηl2,ηl3的值可以根据需要具体设置,例如分别设置为0.8、1.0以及1.2。
其中,m1,m2,m3,m4,m5表示所述人数差,m1,m2,m3,m4,m5均为正整数,并且m1<m2<m3<m4<m5,根据所述人数差确定所述人数权重因子ηn的取值:当所述人数差在[0,m1]之间,所述ηn的取值为ηn1,当所述人数差在[m2,m3]之间,所述ηn的取值为ηn2,当所述人数差在[m4,m5]之间,所述ηn的取值为ηn3;其中,ηn1,ηn2,ηn3的值可以根据需要具体设置,例如分别设置为0.8、1.0以及1.2。
例如,将a公司的ηf、ηs、ηl、ηn分别设置如下:
步骤d:将所述权重因子、所述可用会议室参数、所述待预定会议室参数代入所述匹配度计算公式计算所述匹配度。
具体地,再根据所述待预定会议室参数和所述可用会议室参数获得对应的ηf、ηs、ηl、ηn;再根据匹配度计算公式即可获得所述可用会议室参数、所述待预定会议室参数之间的匹配度,可以理解地,所述匹配度所述可用会议室参数、所述待预定会议室参数与各个可用会议室与待预定会议室对应。由于所述可用会议室有一个或多个,故所述匹配度也对应有一个或多个。
步骤s104,将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择。
本实施例中,预先设置匹配度阈值,例如80%。若某个可用会议室参数与所述待预定会议室参数完全一致时,所述匹配度c为100;若某个可用会议室参数与所述待预定会议室参数的差别越小,所述匹配度c越大;若某个可用会议室参数与所述待预定会议室参数的差别越大,所述匹配度c越小。因此,本实施例将所述匹配度高于预设匹配度阈值的所述对应可用会议室显示在会议室推荐界面,以供用户选择。
进一步地,还可以设置排队功能,接收用户发送的排队指令,当所述可用会议室中有匹配度更高的可用会议室时,则将所述匹配度更高的会议室推荐给用户。
本实施例通过上述方案,接收用户发送的会议室预定语音;识别所述会议室预定语音,获得待预定会议室参数;基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度;将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择。本发明基于语音识别获得待预定会议室参数,再根据匹配度计算公式获得待预定会议室参数与可用会议室参数之间的匹配度,并将匹配度高于预设匹配度阈值的可用会议室推荐给用户,由此简化了会议室预定流程,提高了会议室预定的智能性。
如图3所示,本发明第二实施例提出一种基于语音识别的会议室预定方法,基于上述图2所示的第一实施例,所述将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择的步骤之后还包括:
步骤s105,获取用户选择的所述可用会议室以及预定时间,将用户选择的所述可用会议室标记为目标预定会议室;
本实施例中,接收用户在所述会议室推荐界面选择的可用会议室,确定所述预定时间,由于所述预定时间可能与待预定会议室参数中的起始时间和\或会议持续时长不一致,故需要重新进行确认。所述预定时间可以由用户自主设置,也可以根据所述起始时间和所述会议持续时长计算后获得。
待接收到用户发送的确认指令后,将用户选择的所述可用会议室标记为目标预定会议室。
步骤s106,将所述目标预定会议室在所述预定时间内的使用状态标记为使用中。
具体地,所述目标预定会议室在被预定之前在所述预定时间内的使用状态为空闲,故在用户确定预定之后,将所述预定时间内的使用状态修改为使用状态。
进一步地,所述步骤s106:将所述目标预定会议室在所述预定时间内的使用状态标记为使用中的步骤之后还包括:
接收用户发送的会议室退订指令,从所述会议室退订指令获取待退订会议室;
将所述待退订会议室在退订时间段内的使用状态修改为空闲。
具体地,当用户预定会议室后,可能需要退订。因此接收用户通过语音或触控指令发送的会议室退订指令,并从所述会议室退订指令获取待退订会议室;然后将所述待退订会议室在退订时间段内的使用状态修改为空闲。
可以理解地,由于会议室可能需要维护故还有会议室处于维护状态,当处于维护状态的所述会议室在维护完成后,则将所述维护状态的会议室的使用状态修改为空闲,以供用户预定。
本实施例通过上述方案,获取用户选择的所述可用会议室以及预定时间,将用户选择的所述可用会议室标记为目标预定会议室;将所述目标预定会议室在所述预定时间内的使用状态标记为使用中,由此简化了会议室预定流程,提高了会议室预定的智能性。
此外,本实施例还提供一种基于语音识别的会议室预定装置。参照图4,图4为本发明基于语音识别的会议室预定装置第一实施例的功能模块示意图。
本发明提供的基于语音识别的会议室预定装置,存储于图1所示的基于语音识别的会议室预定设备的存储器1005中,以实现基于语音识别的会议室预定程序的所有功能:用于接收用户发送的会议室预定语音;用于识别所述会议室预定语音,获得待预定会议室参数;用于基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度;用于将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择。
具体地,本实施例中所述基于语音识别的会议室预定装置包括:
接收模块10,用于接收用户发送的会议室预定语音;
语音识别模块20,用于识别所述会议室预定语音,获得待预定会议室参数;
计算模块30,用于基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度;
推荐模块40,用于将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择。
进一步地,所述接收模块还用于:
获取用户选择的所述可用会议室以及预定时间,将用户选择的所述可用会议室标记为目标预定会议室;
将所述目标预定会议室在所述预定时间内的使用状态标记为使用中。
进一步地,所述接收模块还用于:
接收用户发送的会议室退订指令,从所述会议室退订指令获取待退订会议室;
将所述待退订会议室在退订时间段内的使用状态修改为空闲。
进一步地,所述语音识别模块还用于:
提取所述会议室预定语音中的声纹信息,将所述声纹信息与预存声纹信息进行对比;
若所述声纹信息与所述预存声纹信息一致,则执行步骤:识别所述会议室预定语音,获得待预定会议室参数;
若所述声纹信息与所述预存声纹信息不一致,则忽略所述会议室预定语音。
进一步地,所述语音识别模块还用于:
对所述会议室预定语音进行预处理,切除所述会议室预定语音中首尾端的静音,并将所述会议室预定语音进行分帧,获得多个帧;
提取多个所述帧中的特征向量,并获得与所述特征向量对应的文字;
获取所述文字中的多个关键字;
将多个所述关键字分别填入预设的待预定会议室参数模板中,获得所述待预定会议室参数。
进一步地,所述计算模块还用于:
预先保存所有会议室的会议室参数和使用状态,将所述使用状态在特定时间段内为空闲的会议室标记为可用会议室,并将所述可用会议室的会议室参数标记为所述可用会议室参数,其中,所述特定时间段由预先设定的时间浮动范围以及所述会议室预定参数中的起始时间和持续时间决定。
进一步地,所述计算模块还用于:
将所述待预定会议室ma表示为:ma=(fa,sa,la,na);
将所述可用会议室mr表示为:mr=(fr,sr,lr,nr);其中,fa,sa,la,na为所述待预定会议室参数,fr,sr,lr,nr为所述可用会议室参数,f表示楼层,s表示起始时间,l表示会议持续时长,n表示与会人数;
将所述匹配度计算公式表示为:
将所述权重因子、所述可用会议室参数、所述待预定会议室参数代入所述匹配度计算公式计算所述匹配度。
此外,本发明还提出一种计算机存储介质,所述计算机存储介质上存储有基于语音识别的会议室预定程序,所述基于语音识别的会议室预定程序被处理器运行时实现如上所述的基于语音识别的会议室预定方法的步骤。
相比现有技术,本发明提出的一种基于语音识别的会议室预定方法、装置、设备及存储介质,该方法包括:接收用户发送的会议室预定语音;识别所述会议室预定语音,获得待预定会议室参数;基于预设匹配度计算公式计算所述待预定会议室参数与可用会议室参数之间的匹配度;将所述匹配度高于预设匹配度阈值的对应可用会议室显示在会议室推荐界面,以供用户选择。本发明在人工智能的基础上,基于语音识别获得待预定会议室参数,再根据匹配度计算公式获得待预定会议室参数与可用会议室参数之间的匹配度,并将匹配度高于预设匹配度阈值的可用会议室推荐给用户,由此简化了会议室预定流程,提高了会议室预定的智能性。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备执行本发明各个实施例所述的方法。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!