一种信息处理方法、装置及存储介质与流程
本发明涉及业务支撑领域,具体涉及一种信息处理方法、装置及存储介质。
背景技术:
随着互联网业务的发展,用户数量的逐渐增加,系统数据库中累积的数据量急剧增加,在数据量增加的同时,数据的存储要求变得更高。
多租户软件架构作为一种新的软件架构改变了系统交付和用户使用的方式,更加灵活可扩展,易于快速定制和集成以便适应用户需求的变化。并且,多租户技术由于可以让多个租户共用一个应用程序或运算环境,在降低开发成本的同时,仍可确保各用户间数据的隔离性。
但由于不同的业务系统需求不一,数据的存储方式不同,数据需要的隔离程度也不一样;如果单独为用户分配独立的数据库,会给系统的成本带来较大的压力;如果所有用户共用一个数据库,虽然成本低,但隔离程度低安全性差。如果多个用户共用一个数据库使用程序隔离,难以实现数据共享。
技术实现要素:
有鉴于此,本发明的主要目的在于提供一种信息处理方法、装置及存储介质,能够灵活的为不同的业务系统提供多租户功能。
为达到上述目的,本发明的技术方案是这样实现的:
本发明实施例提供一种信息处理方法,应用于服务器侧,所述方法包括:
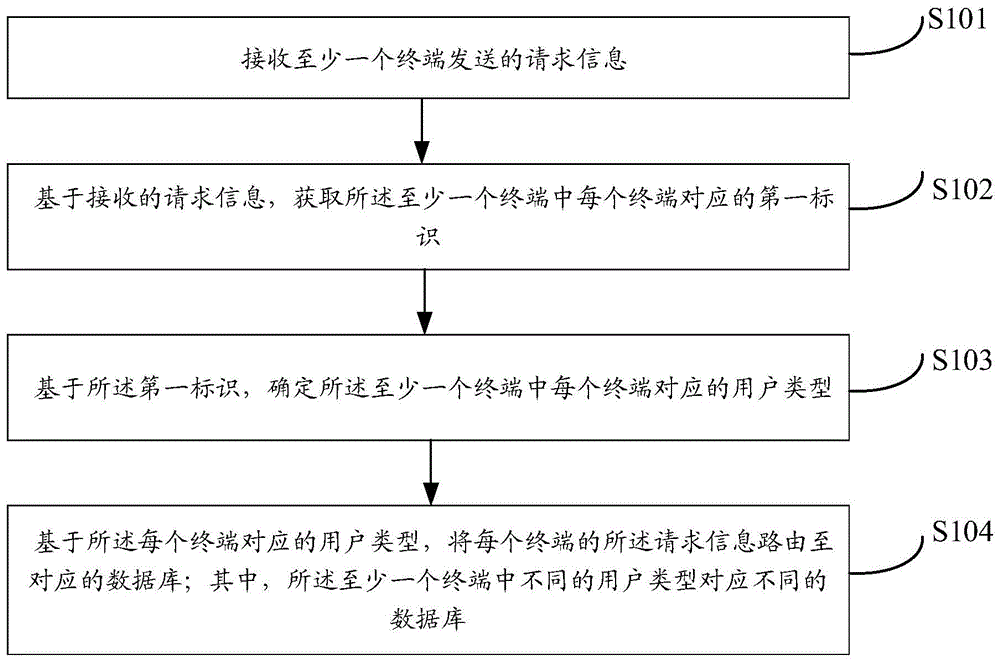
接收至少一个终端发送的请求信息;
基于接收的请求信息,获取所述至少一个终端中每个终端对应的第一标识;
基于所述第一标识,确定所述至少一个终端中每个终端对应的用户类型;
基于所述每个终端对应的用户类型,将每个终端的所述请求信息路由至对应的数据库;其中,所述至少一个终端中不同的用户类型对应不同的数据库。
在上述方案中,所述基于所述每个终端对应的用户类型,将每个终端的所述请求信息路由至对应的数据库,包括:
确定所述用户类型与数据库的映射关系;
基于所述映射关系,将所述请求信息路由至对应的数据库。
在上述方案中,所述确定所述用户类型与数据库的映射关系,包括:
基于路由中间件的配置信息确定所述用户类型与数据库的映射关系;
其中,所述配置信息至少包括每个终端对应的用户类型、数据分片信息以及数据库服务器的基本信息。
在上述方案中,所述接收至少一个终端发送的请求信息之前,所述方法还包括:
接收至少一个终端发送的注册信息,所述注册信息至少包括第一标识以及第二标识,所述第二标识用于表征所述终端对应的用户名。
在上述方案中,所述基于所述每个终端对应的用户类型,将每个终端的所述请求信息路由至对应的数据库之后,所述方法还包括:
基于所述第二标识,向所述第二标识对应的终端发送数据信息;
其中,所述数据信息包括私有信息和共享信息,所述私有信息通过数据库表中的第一字段标识,所述共享信息通过数据库表中的第二字段标识;所述第一字段与第二字段为不同的字段。
本发明实施例还提供一种信息处理装置,所述装置包括:通信接口以及处理器,其中,
所述通信接口,用于接收至少一个终端发送的请求信息;
所述处理器,用于基于接收的请求信息,获取所述至少一个终端中每个终端对应的第一标识;基于所述第一标识,确定所述至少一个终端中每个终端对应的用户类型;基于所述每个终端对应的用户类型,将每个终端的所述请求信息路由至对应的数据库;其中,所述至少一个终端中不同的用户类型对应不同的数据库。
在上述装置中,所述处理器,用于确定所述第一标识与数据库的映射关系;基于所述映射关系,将所述请求信息路由至对应的数据库。
在上述装置中,所述处理器,用于基于路由中间件的配置信息确定所述用户类型与数据库的映射关系;
其中,所述配置信息至少包括每个终端对应的用户类型、数据分片信息以及数据库服务器的基本信息。
在上述装置中,所述通信接口,还用于接收至少一个终端发送的注册信息,所述注册信息至少包括第一标识以及第二标识,所述第二标识用于表征所述终端对应的用户名。
在上述装置中,所述通信接口,还用于基于所述第二标识,向所述第二标识对应的终端发送数据信息;其中,所述数据信息包括私有信息和共享信息,所述私有信息通过数据库表中的第一字段标识,所述共享信息通过数据库表中的第二字段标识;所述第一字段与第二字段为不同的字段。
本发明还提供一种计算机可读存储介质,其上存储有计算机程序,其中,所述计算机程序被处理器执行时实现上述所述方法的任一步骤。
本发明实施例提供的信息处理方法以及装置,基于接收的请求信息获取第一标识,进而再基于第一标识确定当前终端对应的用户类型,由此可以实现不同类型的用户信息存储在不同的数据库,同类型的用户存储在同一个数据库;这种设计可以同时满足存储的高隔离以及低隔离需求,实现适配不同的业务系统,满足不同的存储需求。
附图说明
图1为本发明实施例提供的信息处理方法的流程图;
图2为数据库中间件的作用关系图;
图3为发明实施例的具体场景图;
图4为本发明实施例提供的信息处理装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对发明的具体技术方案做进一步详细描述。以下实施例仅用于说明本发明,但不限制本发明的范围。
基于此,本发明实施例提供一种信息处理方法,应用于服务器侧,如图1所示,所述方法包括:
s101,接收至少一个终端发送的请求信息;
s102,基于接收的请求信息,获取所述至少一个终端中每个终端对应的第一标识;
s103,基于所述第一标识,确定所述至少一个终端中每个终端对应的用户类型;
s104,基于所述每个终端对应的用户类型,将每个终端的所述请求信息路由至对应的数据库;其中,所述至少一个终端中不同的用户类型对应不同的数据库。
需要说明的是,对于同一个应用系统来说,由于业务需求的不同,数据的存储存在差别,通过不同的数据库,不同的数据表进行存储已成为了一种趋势。当原来在一个数据库一个表的数据分离到不同的数据库、或是不同的表中时,为了实现对上层应用透明,不对应用产生影响,就需要一个中间层将上层应用的数据逻辑操作处理,然后下发到目标数据库数据表中;在收集数据,对数据进行处理后返回给上层应用。这里,设置数据库中间件作为中间层完成数据的处理与路由。
所述数据库中间件包括mycat中间件、dbproxy、oneproxy等,当然还可以是其他数据库中间件,对于本发明来说,只要是可以实现分库分表路由的中间件均行,在此不作列举。
所述数据库中间件安装在服务器侧,在配置文件中进行配置可以实现与不同数据库的连接。数据库中间件可以以多租户的形式给一个或多个应用提供服务,每个应用访问的可能是一个独立或者是共享的物理数据库。
为了更具体的描述本发明的技术方案,本发明实施例中采用mycat中间件作为中间层,进行数据的路由处理。
图2为数据库中间件的作用关系图,如图2所述,数据库中间件主要用于拦截用户发送过来的sql语句,对所述sql语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,查找涉及到的表,然后解析此表的定义,如果有分片规则,则获取到sql里分片字段的值,并匹配分片函数,得到所述sql对应的分片列表,然后将所述sql语句发往对应的数据库去执行,最后收集和处理所有分片返回的结果数据,并将返回的结果做适当的处理,最终再输出到客户端,返回给用户。
这里,所述终端可以包括诸如移动电话,智能电话、笔记本电脑、pad(平板电脑)等的移动终端,还可以为台式计算机等固定终端。
所述请求信息为用户在网页上进行的一切操作产生的sql语句;由于同一个业务系统存在同一个时刻有多个用户同时操作的情况,所述mycat中间件会同时收到来自不同客户端的多个操作请求。需要说明的是,用户在终端上的操作一般都是以sql语句的形式发送后台服务器。
这里,本实施例以用户登陆网页为例进行说明,本领域技术人员可以理解,此处的请求信息也可以是用户在网页上进行的查询操作请求,浏览操作请求等。
所述请求信息中至少携带有第一标识,所述mycat中间件在收到请求信息后,对所述请求信息进行解析获取所述终端的第一标识,基于所述第一标识,可以确定所述终端对应的用户类型,即,在解析获取第一标识后,mycat中间件根据第一标识,可以确定在所述终端上进行操作的用户类型。
所述用户类型用于表征用户对应的数据库,不同的用户类型对应不同的数据库;在获取到用户类型后,所述mycat中间件可以将所述用户的操作路由到对应的数据库中。例如,假设用户类型为a时,对应的数据库为dba,则在确定用户类型为a时,将所述用户路由至dba数据库。
其中,所述基于所述每个终端对应的用户类型,将每个终端的所述请求信息路由至对应的数据库,包括:
确定所述用户类型与数据库的映射关系;基于所述映射关系,将所述请求信息路由至对应的数据库。
这里,由于在接收请求信息后,会根据解析得到的第一标识将请求路由到相应的数据库,那么在路由之前,需要知道用户类型与数据库的对应关系,即第一标识与数据库的映射关系。
进一步地,所述确定所述用户类型与数据库的映射关系,包括:
基于路由中间件的配置信息确定所述用户类型与数据库的映射关系;
其中,所述配置信息至少包括每个终端对应的用户类型、数据分片信息以及数据库服务器的基本信息。
这里,所述路由中间件的配置信息为配置文件中的信息;以mycat中间件为例,在安装mycat软件后,找到conf文件,所述conf文件用于存放配置文件。在conf文件中,server.xml文件是mycat服务器参数调整和用户授权的配置文件,用于设置账号,参数等;schema.xml文件是逻辑库定义、数据库表以及分片定义的配置文件;rule.xml文件是分片规则的配置文件。
根据业务需要设计好相应的分库分表策略后,基于设计的分库分表策略,在mycat中间件的conf文件下进行参数的配置。基于所述配置,在获取用户类型后,将用户的请求信息路由至相应的数据库以及数据库表中。
这里,在配置文件中,所述server.xml文件的参数包括user、name、password、schemas、privileges等,所述user参数为用户配置节点;所述name参数为登录的用户名,也就是连接mycat的用户名;所述password参数为登录的密码,也就是连接mycat的密码;所述schemas参数为数据库名;需要说明的是,所述schemas参数会与schema.xml文件中的配置关联,多个用逗号分开;例如,所述用户需要管理两个数据库db1,db2,则配置db1,db2;所述privileges参数为配置用户针对表的增删改查的权限。
需要说明的是,一般而言,所述server.xml文件中的配置是在安装完mycat软件后就进行,对于不同的业务系统,可以采用相同的配置。
对于本发明实施例而言,为了匹配不同的业务系统,需要对schema.xml文件进行配置。所述schema.xml文件对应于每类用户的信息,即用户类型。
所述schema.xml文件的参数包括schema、datanode、datahost等;所述schema参数为逻辑数据库设置,在schema参数中存在name节点,所述name为逻辑数据库名,与server.xml中schema参数相对应,即上述mycat中间件获取到的第一标识。所述schema.xml中schema参数的配置如下:
<schemaname="a"checksqlschema="false"datanode="dn1">
</schema>
<schemaname="b"checksqlschema="false"datanode="dn2">
</schema>
<schemaname="c"checksqlschema="false"datanode="dn3">
</schema>
这里,所述schema标签中,所述name属性即为代表用户类型的第一标识,所述mycat中间件基于请求信息获取到第一标识后,基于第一标识就可以得到所述用户类型对应的数据库名,进而可以将所述请求信息路由至相应的数据库。
对于data参数,所述datanode参数为分片信息,也就是分库相关配置。例如:
<datanodename="dn1"datahost="host1"database="dba"/>
<datanodename="dn2"datahost="host2"database="dbb"/>
<datanodename="dn3"datahost="host3"database="dbc"/>
这里,所述datanode标签中,所述database属性代表了不同用户类型对应的数据库名,如第一标识为a对应的数据库为dba。
对于datahost参数,所述datahost参数为物理数据库的配置信息;由于每个datahost的配置信息基本相同,在此只给出了其中一个的配置方法,例如:
<datahostname="host1"maxcon="1000"minconnode="10"balance="0"writetype="0"dbtype="mysql"dbdriver="jdbc">
<heartbeat>selectuser()</heartbeat>
<writehosthost="host1"url="databasehost"user="root"password="123"/>
</datahost>
这里,所述datahost标签中,所述user属性为用户配置节点;所述name参数为登录的用户名;所述password参数为登录的密码,所述用户名与密码用于连接mycat中间件。
通过上面的配置之后,拥有不同第一标识的用户的数据请求即可对应到datahost配置的相应数据库。
这里,所述接收至少一个终端发送的请求信息之前,所述方法还包括:
接收至少一个终端发送的注册信息,所述注册信息至少包括第一标识以及第二标识,所述第二标识用于表征所述终端对应的用户名。
这里,用户在终端上操作后,后台服务器侧即收到了相应的sql语句,对sql语句进行解析后,就可以对相对应的数据库进行操作。但是所述后台服务器在接收请求信息之前,会先接收注册信息。
所述注册信息为终端用户对应的账户注册信息,在用户注册账户信息后,后续可基于注册的账户信息进行登录操作,或者是查询操作。所述注册信息中至少包括有第一标识以及第二标识,即用户类型和用户名。
需要说明的是,在实际的注册过程中,还会有密码信息;基于注册的第一标识、第二标识以及密码信息,所述用户可以实现账户的登陆。
所述基于所述每个终端对应的用户类型,将每个终端的所述请求信息路由至对应的数据库之后,所述方法还包括:
基于所述第二标识,向所述第二标识对应的终端发送数据信息;
其中,所述数据信息包括私有信息和共享信息,所述私有信息通过数据库表中的第一字段标识,所述共享信息通过数据库表中的第二字段标识;所述第一字段与第二字段为不同的字段。
这里,在终端的账户登陆后,服务器侧会收到请求信息,对所述请求信息解析后,可以获取用户类型、用户名,进而获取对应的数据库信息。由于第二标识用于表征所述终端对应的用户名,那么在用户登陆后,所述服务器将所述用户名对应的信息发送给所述终端。例如,用户admin的用户类型为a,那么用户admin在登陆后,由于解析后获取的用户类型为a,则将所述admin用户的操作信息路由至dba,并将所述dba中关于admin用户的相关内容发送至admin用户的终端上,那么admin用户进行登陆操作后就可以看到自己账号对应的数据信息。
所述数据信息由私有信息和共享信息这2部分组成,即由所述账户对应的信息以及所有账户可以查看的公共信息组成。
这里,所述账户对应的信息为用户登陆后,该账号对应的只有该账号可以看到的信息;例如,admin用户登陆后,会显示关于admin用户对应的任务信息、日志等,这部分信息为私有信息,只有admin用户自己可以看到。
所述所有账户可以查看的公共信息为用户登陆后,除该账号私有信息之外的信息;例如,admin用户登陆后,页面会显示一些公共信息,比如说查询框、图标等所有用户登陆后都存在的内容,所有用户都可以访问到这部分数据。
为了区分私有信息和共享信息,可以在数据库中设置不同的字段对其进行区分,所述私有信息通过数据库表中的第一字段标识,所述共享信息通过数据库表中的第二字段标识;例如,第一字段可以设置为用户名,第二字段可以设置为default。所述用户名字段的值与系统分配的用户名对应起来,并在用户每次请求数据信息时都将该字段携带。所述default字段的值保证这部分数据为公共信息。
为了区分私有信息和共享信息,还可以是将数据库中需要隔离或共享的字段分别增加一个tenantid字段,根据该数据可以被哪个用户读取或是可以被所有用户访问,将tenantid字段设置为对应的用户名或是“default”,这样当用户访问该数据库表中的数据就可以只将用户名对应的数据和“default”数据返回给用户。
为了更清晰的表达本实施例的内容,这里结合具体应用情况进行说明,以如下业务需求为例:
图3为本发明实施例的具体场景图,如图3所述,当业务系统中的用户需要单独的数据库来存储数据信息,或是业务系统的设计人员出于性能、安全等方面的考虑,需要将系统中的用户数据分配到不同的数据库中进行存储时,首先需要为这些用户分配唯一的第一标识,所述第一标识由具体的业务系统进行设计,只要可以保证第一标识有意义且唯一即可。
具体地,为应用系统中需要单独数据库存储的用户类型配置用户类型信息,即为不同的用户类型分配不同的第一标识,比如为用户类型1,用户类型2分别分配schemaid1和schemaid2;在分配设计好后,设置mycat数据路由中间件的配置文件,将不同用户类型的请求分配到对应的数据库中,比如将schemaid1的请求分配到数据库1,将schemaid2的请求分配到数据库2中。所述数据库1用于保存用户类型1的数据,所述数据库2用于保存用户类型2数据,采用这种物理隔离方式可以满足数据的高隔离要求。
为隔离请求不高的且数据存储量较小的用户在系统中分配不同的第二标识tenantid,比如为用户1和用户2分别分配第二标识tenant1和tenant2,并通过系统将tenant1和tenant2中的数据进行隔离,为公共信息分配一个default标识,使得该信息为数据库中的公共信息;这里,所述用户1与用户2为同一个用户类型,即都为用户类型3,由此,用户1与用户2的数据对应的数据库都为数据库3;在数据库3的数据库表中,设置tenantid字段以及default字段用于区分信息的类型,由此可以基于字段的不同,明确信息的处理方式,实现数据在同一个数据库的逻辑隔离,有效降低数据库的使用空间。
本发明实施例提供的信息处理方法,通过设置第一标识和第二标识的方式,可以支持不同类的用户数据存储在不同的数据库中,实现数据的物理隔离;对于同类的用户,可以通过对数据库表的字段进行设置,实现用户与用户之间的逻辑隔离,从而有效的降低数据库的使用空间。由于本发明的信息处理方法提供了混合存储方案,在实现对隔离度高的用户进行分数据库存储,对隔离度不高的用户进行逻辑隔离的基础上,可以满足对不同需求业务的处理需求。
基于前述实施例相同的技术构思,本发明实施例还提供一种信息处理装置,如图4所示,所述信息处理装置200包括:通信接口201、处理器202,其中,
所述通信接口201,用于接收至少一个终端发送的请求信息;
所述处理器202,用于基于接收的请求信息,获取所述至少一个终端中每个终端对应的第一标识;基于所述第一标识,确定所述至少一个终端中每个终端对应的用户类型;基于所述每一个终端对应的用户类型,将每个终端的所述请求信息路由至对应的数据库;
其中,所述至少一个终端中不同的用户类型对应不同的数据库。
这里,所述终端可以包括诸如移动电话,智能电话、笔记本电脑、pad(平板电脑)等的移动终端,还可以为台式计算机等固定个终端。
所述请求信息为用户在网页上进行的一切操作;由于同一个业务系统存在同一个时刻有多个用户同时操作的情况,所述mycat中间件会同时收到来自不同客户端的多个操作请求,需要说明的是,用户在终端上的操作一般是以sql语句的形式发送后台服务器。
这里,所述请求信息中至少携带有第一标识,所述mycat中间件在收到请求信息后,对所述请求信息进行解析获取所述终端的第一标识,基于所述第一标识,可以确定所述终端对应的用户类型,即,在解析获取第一标识后,mycat中间件根据第一标识,可以确定在所述终端上进行操作的用户的类型。
进一步地,所述处理器202,用于确定所述用户类型与数据库的映射关系;
基于所述映射关系,将所述请求信息路由至对应的数据库。
这里,由于在接收请求信息后,会根据解析得到的第一标识将请求路由到相应的数据库,那么在路由之前,需要知道用户类型与数据库的对应关系,即第一标识与数据库的映射关系。
其中,所述处理器202,具体用于基于路由中间件的配置信息确定所述用户类型与数据库的映射关系;其中,所述配置信息至少包括每个终端对应的用户类型、数据分片信息以及数据库服务器的基本信息。
这里,所述路由中间件的配置信息为配置文件中的信息;以mycat中间件为例,在安装mycat软件后,找到conf文件,所述conf文件用于存放配置文件。在conf文件中,server.xml文件是mycat服务器参数调整和用户授权的配置文件,用于设置账号,参数等,schema.xml文件是逻辑库定义、数据库表以及分片定义的配置文件,rule.xml文件是分片规则的配置文件。
根据业务需要设计好相应的分库分表策略后,基于设计的分库分表策略,在mycat中间件的conf文件下进行参数的配置。基于所述配置,在获取用户类型后,将用户的请求信息路由至相应的数据库以及数据库表中。
进一步地,所述通信接口201,还用于接收至少一个终端发送的注册信息,所述注册信息至少包括第一标识以及第二标识,所述第二标识用于表征所述终端对应的用户名。
这里,用户在终端上操作后,后台服务器侧即收到了相应的sql语句,对sql语句进行解析后,就可以对相对应的数据库进行操作。但是所述后台服务器在接收请求信息之前,会先接收注册信息。
所述注册信息为终端用户对应的账户注册信息,在用户注册账户信息后,后续可基于注册的账户信息进行登录操作,或者是查询操作。所述注册信息中至少包括有第一标识以及第二标识,即用户类型和用户名。
需要说明的是,在实际的注册过程中,还会有密码信息;基于注册的第一标识、第二标识以及密码信息,所述用户可以实现账户的登陆。
除此之外,所述通信接口201,还用于,基于所述第二标识,向所述第二标识对应的终端发送数据信息;
其中,所述数据信息包括私有信息和共享信息,所述私有信息通过数据库表中的第一字段标识,所述共享信息通过数据库表中的第二字段标识;所述第一字段与第二字段为不同的字段。
所述数据信息由私有信息和共享信息这2部分组成,即由所述账户对应的信息,以及所有账户可以查看的公共信息组成。这里,所述账户对应的信息为用户登陆后,该账号对应的只有该账号可以看到的信息,例如,admin用户登陆后,会显示关于admin用户对应的任务信息、日志等,这部分信息为私有信息,只有admin用户自己可以看到。所述所有账户可以查看的公共信息为用户登陆后,除该账号私有信息之外的信息,例如,admin用户登陆后,页面会显示一些公共信息,比如说查询框、图标等所有用户登陆后都存在的内容,所有用户都可以访问到这部分数据。
为了区分私有信息和共享信息,可以在数据库中设置不同的字段对其进行区分,所述私有信息通过数据库表中的第一字段标识,所述共享信息通过数据库表中的第二字段标识,例如,第一字段可以设置为用户名,第二字段可以设置为default。所述用户名字段的值与系统分配的用户名对应起来,并在用户每次请求数据信息时都将该字段携带。所述default字段的值保证这部分数据为公共信息。
为了区分私有信息和共享信息,还可以是将数据库中需要隔离或共享的字段分别增加一个tenantid字段,根据该数据可以被哪个用户读取或是可以被所有用户访问,将tenantid字段设置为对应的用户名或是“default”,这样当用户访问该数据库表中的数据就可以只将用户名对应的数据和“default”数据返回给用户。
需要说明的是,由于所述信息处理装置200解决问题的原理与前述信息处理方法相似,因此,所述信息处理装置200的具体实施过程及实施原理均可以参见前述方法和实施过程,以及实施原理的描述,重复之处不再赘述。
本发明实施例提供的信息处理装置,通过设置第一标识和第二标识的方式,可以支持不同类的用户数据存储在不同的数据库,实现数据的隔离;对于同类的用户,可以通过对数据库表的字段进行设置,实现用户与用户之间的逻辑隔离,从而有效的降低数据库的使用空间。由于本发明的信息处理装置可以用于提供混合存储的方案,在实现对隔离度高的用户进行分数据库存储,对隔离度不高的用户进行逻辑隔离的基础上,可以满足对不同需求业务的处理需求。
本发明实施例还提供一种计算机存储介质,其上存储有计算机程序,其中,该计算机程序被处理器执行时实现实施例一种所述方法的步骤。并且该计算机程序被处理器执行时实现执行实施例一中所提供的方法的各个步骤,这里不再赘述。
本发明实施例上述装置如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实施例的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器、或者网络设备等)执行本发明各个实施例所述方法的全部或部分。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤。而前述的存储介质包括:移动存储设备、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
上述本发明实施例揭示的方法可以应用于处理器中,或者由处理器实现。处理器可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器可以是通用处理器、数字信号处理器(dsp,digitalsignalprocessor)、分立硬件组件等。处理器可以实现或者执行本发明实施例中的公开的各方法、步骤及逻辑框图。结合本发明实施例所公开的方法的步骤,可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于存储介质中,该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成前述方法的步骤。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!