一种基于残差生成对抗网络的人脸视频增强方法与流程
本发明涉及深度学习与人脸图像、视频压缩技术领域,尤其涉及一种基于残差生成对抗网络的人脸视频增强方法。
背景技术:
随着微信等社交类软件的快速普及,其伴随的视频通讯技术也逐渐深入人心。但是视频通讯相比于文字通讯最大的缺点是:需要较大的数据传输量,同时在信号差的地方,视频通讯效果差。且对于偏远乡村地区来说,基站的不完善也可能会影响通讯的质量,从而必然会极大地影响用户的使用体验。对于跨洋通信来说,由于传输距离增大,网络传输环境相对较差,视频通讯软件只能通过降低清晰度从而保障视频流畅。
在调研中发现,当前使用的视频软件主要有微信、qq、skype等,其主要使用h.264编码格式,虽然其编码效率与视频画面质量均较高,且在基于对称生成对抗式残差网络的编码技术的基础上使用更加智能的算法,能够大幅度提高性能。但是在网络相对较差的环境中,使用者经常会感到卡顿和视频失真,其主要原因在于现在的视频软件在视频传输的过程中是对整体图像进行压缩,且未按照重要程度对图像的不同部分进行压缩,因此难以满足实时性需求。有人提出利用神经网络将视频整体进行压缩再传输,从而更进一步减小传输数据量,但其所用的神经网络模型复杂度高、难以全面推广。在某些情况下,视频聊天的对方并不关注你所处的环境信息,如背景信息,此时如何能够抛弃背景等冗余信息,对人们更加关注的信息如人脸图像进行压缩,弱化背景等次要信息,更大程度上地压缩有效信息成为亟待解决的问题。
技术实现要素:
发明目的:针对现有在视频聊天的过程中,如何能够在对所有信息进行编码后,将其中的冗余信息抛弃,将有效信息进行解码的问题,本发明提出一种基于残差生成对抗网络的人脸视频增强方法。
技术方案:为实现本发明的目的,本发明所采用的技术方案是:
一种基于残差生成对抗网络的人脸视频增强方法,所述方法具体包括如下步骤:
s1:获取聊天视频中的每个人脸图像,并将所述人脸图像转换为预设大小的三通道rgb图像,同时还获取预设大小的三通道rgb图像表示的三维矩阵m1;
s2:获取所述预设大小的三通道rgb图像中人脸的m个特征点集合,所述m≥2且m为整数,使用白色像素和黑色像素对预设大小的三通道rgb图像进行表示,获取得到特征图像和特征图像表示的三维矩阵m2;
s3:将所述三维矩阵m1和三维矩阵m2进行拼接,获取拼接图像;
s4:将所述拼接图像和预设大小的三通道rgb图像作为残差生成对抗网络模型的输入,对所述残差生成对抗网络模型进行训练,获取训练后的残差生成对抗网络模型;
s5:根据所述训练后的残差生成对抗网络模型,视频聊天的用户双方均可以接收并恢复对方的图像,同时还可以获取得到原图像和残差生成对抗网络模型中的压缩图像之间的压缩比大小。
进一步地讲,所述步骤s1获取预设大小的三通道rgb图像表示的三维矩阵m1,具体如下:
s1.1:获取聊天视频中的每个人脸图像,将所有所述人脸图像放在同一个集合中,形成视频数据集;
s1.2:将所述视频数据集中的每个人脸图像进行放大或缩小,直至所述人脸图像的尺寸达到预设尺寸,所述预设尺寸的人脸图像即为预设大小的三通道rgb图像;
s1.3:根据所述预设大小的三通道rgb图像像素的宽度、高度和深度,将所述预设大小的三通道rgb图像表示为三维矩阵m1,具体为:
其中:m1为预设大小三通道rgb图像表示的三维矩阵,h1为预设大小三通道rgb图像像素的宽度,w1为预设大小三通道rgb图像像素的高度,c1为预设大小三通道rgb图像像素的深度。
进一步地讲,所述步骤s2获取得到特征图像和特征图像表示的三维矩阵m2,具体如下:
s2.1:获取所述预设大小的三通道rgb图像中人脸的m个特征点,并将所述m个特征点放在同一个集合中,形成预设大小的三通道rgb图像中人脸的m个特征点集合,具体为:
s={pi|pi=(x,y),x∈(0,1,…,h1-1),y∈(0,1,…,w1-1),0≤i≤m}
其中:s为预设大小的三通道rgb图像中人脸的m个特征点集合,pi为预设大小的三通道rgb图像中像素点的数值位置,h1为预设大小三通道rgb图像像素的宽度,w1为预设大小三通道rgb图像像素的高度,i为预设大小的三通道rgb图像中的第i个像素点,m为图像中人脸的特征点个数;
s2.2:根据所述预设大小的三通道rgb图像中人脸的m个特征点集合,使用白色像素表示所述预设大小的三通道rgb图像中人脸的面部表情线条,使用黑色像素表示所述预设大小的三通道rgb图像中的其余部分,获取得到特征图像;
s2.3:根据所述特征图像像素的宽度、高度和深度,将特征图像表示为三维矩阵m2,具体为:
其中:m2为特征图像表示的三维矩阵,h2为特征图像像素的宽度,w2为特征图像像素的高度,c2为特征图像像素的深度。
进一步地讲,所述特征图像表示的矩阵中的每个元素的像素值,具体为:
其中:i(i,j)为三维矩阵m2中每个元素的像素值,(i,j)为三维矩阵m2中每个元素的坐标,t为白色面部表情线条对应的各个像素点的坐标集合。
进一步地讲,所述步骤s3获取拼接图像,具体如下:
s3.1:根据所述三维矩阵m1和三维矩阵m2,将所述三维矩阵m1中的元素直接接在三维矩阵m2中元素的右侧,得到三维矩阵m3,具体为:
其中:m3为拼接图像表示的三维矩阵,h3为拼接图像像素的宽度,w3为拼接图像像素的高度,c3为拼接图像像素的深度;
s3.2:根据所述三维矩阵m3,获取得到拼接图像像素的宽度、高度和深度,由拼接图像像素的宽度、高度和深度,可以获取得到拼接图像。
进一步地讲,所述残差生成对抗网络模型进行训练的过程中包括有残差生成对抗网络模型的生成模型和残差生成对抗网络模型的判断模型。
进一步地讲,所述残差生成对抗网络模型的生成模型包括有编码层和解码层,所述编码层由8个编码器和1个全连接层构成,所述解码层由1个全接连层和8个解码器构成,其中所述解码层的一个全接连层的输出,具体为:
inputde_1=outputen_9
其中:inputde_1为解码层的一个全接连层的输出,outputen_9为编码层的一个全接连层的输出;
所述解码层中的编码器的输出,具体为:
其中:inputde_n为解码层中的编码器decoder_n的输出,concat为矩阵的拼接操作,
进一步地讲,所述步骤s4获取训练后的残差生成对抗网络模型,具体如下:
s4.1:将所述拼接图像作为生成模型的输入,通过所述生成模型的输出,获取得到生成模型中生成图像的尺寸,并通过所述生成图像的尺寸,获取生成图像表示的三维矩阵m4,具体为:
其中:m4为生成图像表示的三维矩阵,h4为生成图像像素的宽度,w4为生成图像像素的高度,c4为生成图像像素的深度;
s4.2:将所述预设大小的三通道rgb图像作为判断模型的输入,通过所述判断模型的输出,获取得到判断模型中真实图像的尺寸,通过所述真实图像的尺寸,获取真实图像表示的三维矩阵m5,具体为:
其中:m5为真实图像表示的三维矩阵,h5为真实图像像素的宽度,w5为真实图像像素的高度,c5为真实图像像素的深度;
s4.3:根据所述三维矩阵m4和三维矩阵m5,获取对生成图像预测的置信度和对真实图像预测的置信度,具体为:
其中:predict_fake为对生成图像预测的置信度,predict_real为对真实图像预测的置信度,h4为生成图像像素的宽度,w4为生成图像像素的高度,c4为生成图像像素的深度,h5为真实图像像素的宽度,w5为真实图像像素的高度,c5为真实图像像素的深度,xi,j,z为矩阵中元素的像素值;
s4.4:通过所述对生成图片预测的置信度和对真实图像预测的置信度,获取判断模型中评估函数的最小值和生成模型中评估函数的最小值,具体为:
其中:mindv1(predictfake)为判断模型中评估函数的最小值,mingv2(m4,m5)为生成模型中评估函数的最小值,predict_fake为对生成图像预测的置信度,predict_real为对真实图像预测的置信度,f为均方误差计算式;
s4.5:根据所述判断模型中评估函数的最小值和生成模型评估函数的最小值对残差生成对抗网络模型的损失函数进行优化,在优化的过程中,通过反向传播将残差生成对抗网络模型中的神经元的权重进行更新,当更新后的神经元权重与更新前的神经元权重不同时,则重复步骤s4.1-步骤s4.5,直至神经元的权重不再改变,获取最终的神经元的权重,当更新后的神经元权重与更新前的神经元权重相同时,则神经元权重不需要更新变换;
s4.6:根据所述获取到的最终的神经元权重,将所述残差生成对抗网络模型中的神经元权重更新为最终的神经元权重,所述残差生成对抗网络模型进行收敛,获取得到训练后的残差生成对抗网络模型。
进一步地讲,所述步骤s4.5获取最终的神经元的权重,具体如下:
s4.5.1:根据所述判断模型中评估函数的最小值和生成模型评估函数的最小值,获取生成模型的损失函数和判断模型的损失函数,具体为:
其中:loss1为生成模型的损失函数,loss2为判断模型的损失函数,wd和wg为权重系数,mindv1(predictfake)为判断模型中评估函数的最小值,mingv2(m4,m5)为生成模型中评估函数的最小值,predict_fake为对生成图像预测的置信度,predict_real为对真实图像预测的置信度;
s4.5.2:对所述生成模型的损失函数和判断模型的损失函数进行优化,具体为:
其中:l1为生成模型的损失函数的最小值,l2为判断模型的损失函数的最小值,loss1为生成模型的损失函数,loss2为判断模型的损失函数;
s4.5.3:在对损失函数进行优化的过程中,通过反向传播将残差生成对抗网络模型中的神经元的权重进行更新,当更新后的神经元权重与更新前的神经元权重不同时,则重复步骤s4.1-步骤s4.5,直至神经元的权重不再改变,获取最终的神经元的权重,当更新后的神经元权重与更新前的神经元权重相同时,则神经元权重不需要更新变换,其中最终的神经元权重,具体为:
其中:wi为更新后的神经元权重,w′i为更新前的神经元权重,α为学习率,loss(w)为损失值。
进一步地讲,所述步骤s5获取得到原图像和残差生成对抗网络模型中压缩图像之间的压缩比大小,具体如下:
s5.1:视频聊天中的一位用户,将自身聊天视频中的人脸图像发送给所述训练后的残差生成对抗网络模型中的编码层,通过所述编码层对发送的人脸图像提取高维特征,由所述高维特征得到残差生成对抗网络模型中的压缩图像,并将所述压缩图像发送至视频聊天中的另一位用户,其中发送的自身聊天视频中的人脸图像为原图像;
s5.2:视频聊天中的另一位用户接收到发送的压缩图像后,将所述压缩图像通过训练后的残差生成对抗网络模型中的解码层进行解码,将所述压缩图像还原为发送图像的用户的人脸图像,即为获取还原图像;
s5.3:根据所述还原图像和压缩图像,获取所述原图像和残差生成对抗网络模型中压缩图像之间的压缩比大小,具体为:
其中:c为原图像和压缩图像之间的压缩比,v原图为原图像的尺寸,v压缩为残差生成对抗网络模型中的压缩图像的尺寸。
有益效果:与现有技术相比,本发明的技术方案具有以下有益技术效果:
(1)本发明通过基于残差生成对抗网络的方法,实现在视频聊天中对人脸图像进行编码和解码的目的,且在对人脸图像的压缩与复原的过程中,压缩比可以达到662,从而可以实现节约流量带宽的目标;
(2)本发明在视频聊天的过程中,只对人脸进行压缩,且将压缩比达到662,从而不仅能够解决当前传输数据量大、延迟高的问题,同时还能够在更大程度上地压缩有效信息,减小传输数据量。
附图说明
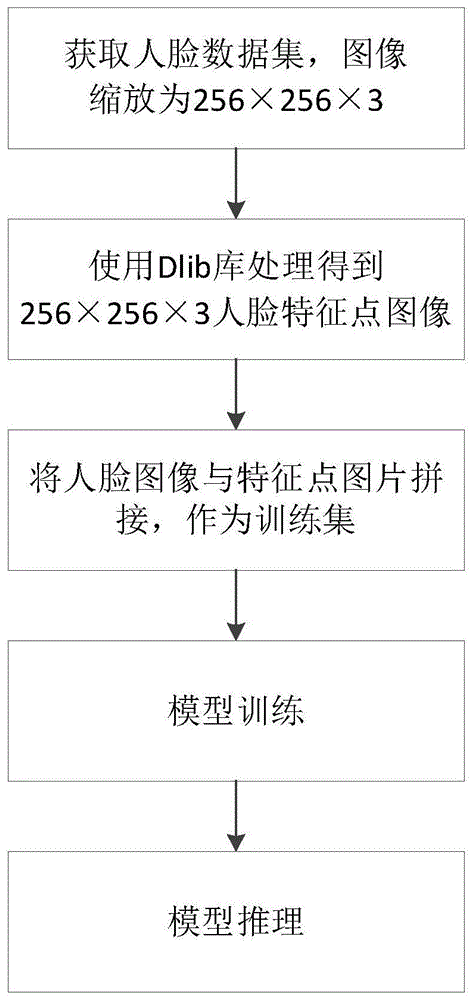
图1是本发明的人脸视频增强方法的流程示意图;
图2是本发明的图像张量变换的示意图;
图3是本发明的生成模型的拓扑结构示意图;
图4是本发明的判断模型的拓扑结构示意图
图5是本发明的模型推理示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。其中,所描述的实施例是本发明一部分实施例,而不是全部的实施例。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。
实施例1
参考图1,本实施例提供了一种基于生成对抗式残差网络的人脸视频增强方法,具体包括如下步骤:
步骤s1:通过爬虫技术获取需要复原的人脸的清晰视频数据集,其中视频数据集由视频中的多个人脸图像组合而成。同时还通过python技术将每个人脸图像转换为256×256×3尺寸大小的预设大小的三通道rgb图像,并获取预设大小的三通道rgb图像表示的三维矩阵m1,具体如下:
步骤s1.1:通过爬虫技术获取用户的聊天视频中的每个人脸图像,将所有的人脸图像放在同一个集合中,形成视频数据集。也就是说,视频数据集由用户的聊天视频中的所有人脸图像组合而成。
步骤s1.2:将视频数据集中的每一帧人脸图像,均通过python技术进行放大或缩小。本实施例中,将视频数据集中的每一帧人脸图像通过python技术转换为尺寸为256×256×3的三通道rgb图像,具体地讲,预设大小的三通道rgb图像为256×256×3的三通道rgb图像。
步骤s1.3:根据尺寸为256×256×3的预设大小的三通道rgb图像像素的宽度、高度和深度,将预设大小的三通道rgb图像表示为三维矩阵m1,具体为:
其中:m1为预设大小三通道rgb图像表示的三维矩阵,h1为预设大小三通道rgb图像像素的宽度,w1为预设大小三通道rgb图像像素的高度,c1为预设大小三通道rgb图像像素的深度。
步骤s2:通过dlib人脸特征检测技术,获取预设大小的三通道rgb图像中人脸的m个特征点集合,其中m≥2且m为整数,并使用白色像素和黑色像素对预设大小的三通道rgb图像进行表示,获取得到特征图像和特征图像表示的三维矩阵m2,具体如下:
步骤s2.1:通过dlib人脸特征检测技术,获取预设大小的三通道rgb图像中人脸的68个特征点集合。也就是说,通过dlib人脸特征检测技术,对步骤s1.2中得到的每一帧预设大小的三通道rgb图像中人脸的特征点进行求取。其中,预设大小的三通道rgb图像中人脸的68个特征点集合,具体为:
s={pi|pi=(x,y),x∈(0,1,…,h1-1),y∈(0,1,…,w1-1),0≤i≤67}
其中:s为预设大小的三通道rgb图像中人脸的68个特征点集合,pi为预设大小的三通道rgb图像中像素点的数值位置,h1为预设大小三通道rgb图像像素的宽度,w1为预设大小三通道rgb图像像素的高度,i为预设大小的三通道rgb图像中的第i个像素点。
步骤s2.2:根据预设大小的三通道rgb图像中人脸的68个特征点集合s,绘制人脸的轮廓图。在本实施例中,使用白色像素表示预设大小的三通道rgb图像中人脸的面部表情线条,其中人脸的面部表情线条指的是人脸的眉毛、眼睛、鼻子、嘴和人脸的框图,使用黑色像素表示预设大小的三通道rgb图像中的其余部分,从而可以获取得到特征图像,其中白色像素的像素值为(255,255,255),黑色像素的像素值为(0,0,0)。
步骤s2.3:根据获取到的特征图像像素的宽度、高度和深度,将特征图像表示为三维矩阵m2,具体为:
其中:m2为特征图像表示的三维矩阵,h2为特征图像像素的宽度,w2为特征图像像素的高度,c2为特征图像像素的深度。
同时在本实施例中,三维矩阵m2中的每个元素的像素值,具体为:
其中:i(i,j)为三维矩阵m2中每个元素的像素值,(i,j)为三维矩阵m2中每个元素的坐标,t为白色面部表情线条对应的各个像素点的坐标集合。
步骤s3:将步骤s1.3中得到的三维矩阵m1和步骤s2.3中得到的三维矩阵m2进行拼接,获取预设大小的三通道rgb图像和特征图像组成的拼接图像,具体如下:
步骤s3.1:根据步骤s1.3中得到的三维矩阵m1和步骤s2.3中得到的三维矩阵m2,将所述三维矩阵m1中的元素直接接在三维矩阵m2中元素的右侧,得到三维矩阵m3。
其中三维矩阵m2是特征图像表示的三维矩阵,三维矩阵m1是预设大小的三通道rgb图像表示的三维矩阵,同时特征图像为使用白色像素值和黑色像素值进行表示的预设大小的三通道rgb图像,也就是说,三维矩阵m1和三维矩阵m2中每个元素的像素值是不同的,但是矩阵m1和矩阵m2的形式是相同的,具体为:
h2=h1,w2=w1,c2=c1
其中:h1为预设大小三通道rgb图像像素的宽度,w1为预设大小三通道rgb图像像素的高度,c1为预设大小三通道rgb图像像素的深度,h2为特征图像像素的宽度,w2为特征图像像素的高度,c2为特征图像像素的深度。
三维矩阵m1和三维矩阵m2之间的拼接,也就是将三维矩阵m1中的元素直接接在三维矩阵m2中元素的右侧,不改变三维矩阵m2的行数,只改变三维矩阵m2的列数,从而即可得到一个新的三维矩阵m3,具体为:
其中:m3为拼接图像表示的三维矩阵,h3为拼接图像像素的宽度,w3为拼接图像像素的高度,c3为拼接图像像素的深度。
步骤s3.2:根据三维矩阵m3,可以得知拼接图像像素的宽度、高度和深度。由拼接图像像素的宽度、高度和深度,则可以组合形成预设大小的三通道rgb图像和特征图像组成的拼接图像。
步骤s4:参考图2、图3和图4,将拼接图像和预设大小的三通道rgb图像作为残差生成对抗网络模型的输入,对残差生成对抗网络模型进行训练,获取训练后的残差生成对抗网络模型。在本实施例中,在对残差生成对抗网络模型进行训练的过程中,包括有残差生成对抗网络模型的生成模型和残差生成对抗网络模型的判断模型。其中将拼接图像作为生成模型的输入,将预设大小的三通道rgb图像作为判断模型的输入,然后对残差生成对抗网络模型进行训练,获取训练后的残差生成对抗网络模型,具体如下:
步骤s4.1:将拼接图像作为生成模型的输入,在生成模型中经过卷积、填充和激活处理后,从生成模型中传输出来,此时从生成模型中得到的是生成模型中生成图像的尺寸。通过生成图像的尺寸,可以知道生成图像像素的宽度、高度和深度,从而可以获取得到生成图像表示的三维矩阵m4,具体为:
其中:m4为生成图像表示的三维矩阵,h4为生成图像像素的宽度,w4为生成图像像素的高度,c4为生成图像像素的深度。
生成模型包括有两部分,分别为:编码层和解码层。其中编码层由8个编码器和1个全连接层构成,解码层由1个全接连层和8个解码器构成。
在本实施例中,编码层中的8个编码器分别表示为encoder_1、encoder_2、encoder_3、encoder_4、encoder_5、encoder_6、encoder_7和encoder_8,1个全连接层表示为encoder_9。
解码层中的1个全接连层表示为decoder_1,8个编码器分别表示为、decoder_2、decoder_3、decoder_4、decoder_5、decoder_6、decoder_7、decoder_8和decoder_9。
具体地讲,编码层的拓扑结构为:
第一个编码器encoder_1:包含有一层卷积层,其卷积核数目为64,卷积核的大小为3×3,使用same方式进行填充,滑动步长为2,输入的图像尺寸为256×256××3,输出的图像尺寸为128××128××64。
第二个编码器encoder_2:包含有一层卷积层,其卷积核数目为64××2,卷积核的大小为3×3,使用same方式进行填充,滑动步长为2,输入的图像尺寸为128×128×64,输出的图像尺寸为64×64×128。
第三个编码器encoder_3:包含有一层卷积层,其卷积核数目为64×4,卷积核的大小为3×3,使用same方式进行填充,滑动步长为2,输入的图像尺寸为64×64×128,输出的图像尺寸为32×32×256。
第四个编码器encoder_4:包含有一层卷积层,其卷积核数目为64×8,卷积核的大小为3×3,使用same方式进行填充,滑动步长为2,输入的图像尺寸为32×32×256,输出的图像尺寸为16×16×512。
第五个编码器encoder_5:包含有一层卷积层,其卷积核数目为64×8,卷积核的大小为3×3,使用same方式进行填充,滑动步长为2,输入的图像尺寸为16×16×512,输出的图像尺寸为8×8×512。
第六个编码器encoder_6:包含一层卷积层,其卷积核数目为64×16,卷积核大小为3×3,使用same方式进行填充,滑动步长为2,输入的图像尺寸为8×8×512,输出的图像尺寸为4×4×1024。
第七个编码器encoder_7:包含有一层卷积层,其卷积核数目为64×16,卷积核的大小为3×3,使用same方式进行填充,滑动步长为2,输入的图像尺寸为4×4×1024,输出的图像尺寸为2×2×1024。
第八个编码器encoder_8:包含有一层卷积层,其卷积核数目为64×16,卷积核的大小为3×3,使用same方式进行填充,滑动步长为2,输入的图像尺寸为2×2×1024,输出的图像尺寸为1×1×1024。
一个全接连层encoder_9:包含有一层全连接层,其神经元数量为100,输入的图像尺寸为1×1024,输出为100维一元向量。
解码层的拓扑结构为:
一个全接连层decoder_1:包含有一层全连接层,其神经元数量为1024,输入为100维向量,输出的图像尺寸为1×1×1024。
第一个编码器decoder_2:包含有一层relu激活层和一层反卷积层,其卷积核数目为64×16,反卷积核的大小为3×3,使用same方式进行填充,滑动步长为2。输入的图像尺寸为1×1×(1024×2),输出的图像尺寸为2×2×1024。
第二个编码器decoder_3:包含一层relu激活层和一层反卷积层,其卷积核数目为64×16,反卷积核的大小为3×3,使用same方式进行填充,滑动步长为2。输入的图像尺寸为2×2×(1024×2),输出的图像尺寸为4×4×1024。
第三个编码器decoder_4:包含有一层relu激活层和一层反卷积层,其卷积核数目为64×16,反卷积核的大小为3×3,使用same方式进行填充,滑动步长为2。输入的图像尺寸为4×4×(1024×2),输出的图像尺寸为8×8×1024。
第四个编码器decoder_5:包含有一层relu激活层和一层反卷积层,其卷积核数目为64×8,反卷积核的大小为3×3,使用same方式进行填充,滑动步长为2。输入的图像尺寸为8×8×(1024×2),输出的图像尺寸为16×16×512。
第五个编码器decoder_6:包含一层relu激活层,一层反卷积层,其卷积核数目为64×4,反卷积核的大小为3×3,使用same方式进行填充,滑动步长为2。输入的图像尺寸为16×16×(512×2),输出的图像尺寸为32×32×256。
第六个编码器decoder_7:包含有一层relu激活层和一层反卷积层,其卷积核数目为64×2,反卷积核的大小为3×3,使用same方式进行填充,滑动步长为2。输入的图像尺寸为32×32×(256×2),输出的图像尺寸为64×64×128。
第七个编码器decoder_8:包含有一层relu激活层,一层反卷积层,其卷积核数目为64,反卷积核大小为3×3,使用same方式进行填充,滑动步长为2。输入的图像尺寸为64×64×(128×2),输出的图像尺寸为128×128×64。
第八个编码器decoder_9:包含有一层relu激活层和一层反卷积层,其卷积核数目为3,反卷积核的大小为3×3,使用same方式进行填充,滑动步长为2。输入的图像尺寸为128×128×(64×2),输出的图像尺寸为256×256×3。
其中解码层的一个全接连层decoder_1的输出inputde_1只与编码层的一个全接连层encoder_9的输出outputen_9有关,具体为:
inputde_1=outputen_9
其中:inputde_1为解码层的一个全接连层的输出,outputen_9为编码层的一个全接连层的输出。
解码层中的编码器decoder_n的输出inputde_n与解码层的一个全接连层decoder_1的输出inputde_1不同,具体为:
其中:inputde_n为解码层中的编码器decoder_n的输出,concat为矩阵的拼接操作,
从中可以发现,生成模型输出的真实图像的尺寸为解码层中第八个编码器decoder_9输出的图像尺寸,也就是说生成模型输出的真实图像的尺寸为256×256×3。
步骤s4.2:将预设大小的三通道rgb图像作为判断模型的输入,在判断模型中经过卷积、填充和激活处理后,从判断模型中传输出来,此时从判断模型中得到的是判断模型中真实图像的尺寸。通过真实图像的尺寸,可以知道真实图像像素的宽度、高度和深度,从而可以获取得到真实图像表示的三维矩阵m5,具体为:
其中:m5为真实图像表示的三维矩阵,h5为真实图像像素的宽度,w5为真实图像像素的高度,c5为真实图像像素的深度。
在本实施例中,判断模型包括有五层layer层,分别表示为:layer_1、layer_2、layer_3、layer_4和layer_5。
判断模型的拓扑结构为:
第一个layer层layer_1:包含有一层卷积层,其卷积核数目为64,卷积核大小为3×3,使用valid方式进行填充,滑动步长为2,批标准化操作,lrelu激活函数激活。输入的图像尺寸为256×256×6,输出的图像尺寸为128×128×64。
第二个layer层layer_2:包含有一层卷积层,其卷积核数目为64×2,卷积核大小为3×3,使用valid方式进行填充,滑动步长为2,批标准化操作,lrelu激活函数激活。输入的图像尺寸为128×128×64,输出的图像尺寸为64×64×128。
第三个layer层layer_3:包含有一层卷积层,其卷积核数目为64×4,卷积核大小为3×3,使用valid方式进行填充,滑动步长为2,批标准化操作,lrelu激活函数激活。输入的图像尺寸为64×64×128,输出的图像尺寸为32×32×256。
第四个layer层layer_4:包含有一层卷积层,其卷积核数目为64×8,卷积核大小为3×3,使用valid方式进行填充,滑动步长为1,批标准化操作,lrelu激活函数激活。输入的图像尺寸为32×32×256,输出的图像尺寸为32×32×512。
第五个layer层layer_5:包含有一层卷积层,其卷积核数目为1,卷积核大小为3×3,使用valid方式进行填充,滑动步长为1,sigmoid操作。输入的图像尺寸为32×32×512,输出的图像尺寸为32×32×1。
其中判断模型中第一个layer层layer_1的输出为第二个layer层layer_2的输入,第二个layer层layer_2的输出为第三个layer层layer_3的输入,第三个layer层layer_3的输出为第四个layer层layer_4的输入,第四个layer层layer_4的输出为第五个layer层layer_5的输入,所以第五个layer层layer_5的输出为判断模型的输出。从中可以发现,判断模型输出的真实图像的尺寸为32×32×1。
步骤s4.3:根据步骤s4.1得到的三维矩阵m4和步骤s4.2得到的三维矩阵m5,获取得到对生成图像预测的置信度和对真实图像预测的置信度,具体为:
其中:predict_fake为对生成图像预测的置信度,predict_real为对真实图像预测的置信度,h4为生成图像像素的宽度,w4为生成图像像素的高度,c4为生成图像像素的深度,h5为真实图像像素的宽度,w5为真实图像像素的高度,c5为真实图像像素的深度,xi,j,z为矩阵中元素的像素值。
步骤s4.4:通过对生成图片预测的置信度和对真实图像预测的置信度,获取得到判断模型中评估函数的最小值和生成模型中评估函数的最小值,具体为:
其中:mindv1(predictfake)为判断模型中评估函数的最小值,mingv2(m4,m5)为生成模型中评估函数的最小值,predict_fake为对生成图像预测的置信度,predict_real为对真实图像预测的置信度,f为均方误差计算式。
步骤s4.5:根据判断模型中评估函数的最小值和生成模型中评估函数的最小值,对残差生成对抗网络模型的损失函数进行优化,在优化的过程中,通过反向传播将残差生成对抗网络模型中的神经元的权重进行更新,当更新后的神经元权重与更新前的神经元权重不同时,则重复步骤s4.1-步骤s4.5,直至神经元的权重不再改变,获取最终的神经元的权重,当更新后的神经元权重与更新前的神经元权重相同时,则神经元权重不需要进行更新变换,具体如下:
步骤s4.5.1:根据判断模型中评估函数的最小值和生成模型中评估函数的最小值,获取得到生成模型的损失函数和判断模型的损失函数,具体为:
其中:loss1为生成模型的损失函数,loss2为判断模型的损失函数,wd和wg为权重系数,mindv1(predictfake)为判断模型中评估函数的最小值,mingv2(m4,m5)为生成模型中评估函数的最小值,predict_fake为对生成图像预测的置信度,predict_real为对真实图像预测的置信度。
步骤s4.5.2:对生成模型的损失函数和判断模型的损失函数进行优化,具体为:
其中:l1为生成模型的损失函数的最小值,l2为判断模型的损失函数的最小值,loss1为生成模型的损失函数,loss2为判断模型的损失函数。
从中可以发现对生成模型的损失函数和判断模型的损失函数进行优化,也就是获取生成模型的损失函数的最小值和判断模型的损失函数的最小值。
步骤s4.5.3:在对损失函数进行优化的过程中,通过反向传播将残差生成对抗网络模型中的神经元的权重进行更新,当更新后的神经元权重与更新前的神经元权重不同时,重复步骤s4.1-步骤s4.5,直至神经元的权重不再改变,获取最终的神经元的权重,当更新后的神经元权重与更新前的神经元权重相同时,则神经元权重不需要进行更新变换。其中获取得到的最终的神经元权重,具体为:
其中:wi为更新后的神经元权重,w′i为更新前的神经元权重,α为学习率,loss(w)为损失值。
步骤s4.6:根据获取得到的最终的神经元权重wi,将残差生成对抗网络模型中的神经元权重更新为最终的神经元权重wi,此时的残差生成对抗网络模型将进行收敛,从而获取得到训练后的残差生成对抗网络模型。
步骤s5:参考图5,根据训练后的残差生成对抗网络模型,不同用户之间进行视频聊天时,其中的一位用户可以接收并恢复另一位用户的图像,同样地,另一位用户也可以接收并恢复对方的图像。同时还可以获取得到原图像和残差生成对抗网络模型中的压缩图像之间的压缩比大小,具体如下:
步骤s5.1:视频聊天中的一位用户,将自身聊天视频中的人脸图像发送给训练后的残差生成对抗网络模型中的编码层,对自身的人脸图像提取高维特征,得到100维向量,根据得到的100维向量获取残差生成对抗网络模型中的压缩图像,并将该压缩图像发送至视频聊天中的另一位用户,其中发送给训练后的残差生成对抗网络模型中的编码层的自身聊天视频中的人脸图像为原图像。
步骤s5.2:视频聊天中的另一位用户接收到发送的压缩图像后,将传送过来的压缩图像通过训练后的残差生成对抗网络模型中的解码层进行解码,将压缩图像还原为发送图像的用户的人脸图像,即256×256×3的人脸图像,也为还原图像。也就是说,尺寸为256×256×3的人脸图像为还原图像。因为还原图像就是将原图像压缩后并进行还原的图像,所以还原图像的尺寸与原图像的尺寸相同,也就是说,原图像的尺寸为256×256×3。
步骤s5.3:根据尺寸为256×256×3的原图像、根据100维向量获取的压缩图像,获取原图像和残差生成对抗网络模型中压缩图像之间的压缩比大小,具体为:
其中:c为原图像和压缩图像之间的压缩比,v原图为原图像的尺寸,v压缩为残差生成对抗网络模型中的压缩图像的尺寸。
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构和方法并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!