文本情感分类方法与流程
本发明涉及自然语言处理,具体是一种文本情感分类方法。
背景技术:
随着互联网技术的发展以及模型化深度学习的兴起,文本情感分析的研究越来越热门。该研究不仅对于科研人员,而且对日常生活也有着非常重要的实际意义,例如政府部门可以通过分析网络舆论情感倾向引导舆论发展,电商商家可以通过分析用户评论情感倾向了解用户偏好等。
目前常用的文本情感分类方法包括基于词典的情感分类、基于传统机器学习的情感分类和基于深度学习的分类方法。前两种分类方法对人工先验知识要求较高,需要人工提取特征和构建情感词典等,工作繁重复杂且不容易推广,因此现在更为流行和实用的是基于深度学习的情感分类方法。
文本情感分析目前还存在有跨语言、语料缺乏等问题。现有的很多分析模型在英文数据集上有良好的表现,但在中文数据集上不一定适用,而语料的缺乏又会影响到模型的性能,使得最终分析出的文本情感不准确或无法分析。
技术实现要素:
本发明提供了一种文本情感分类方法,对基于深度学习的分类方法进行了改进,以能够更准确的分析出中文词语语义,并且提升数据模型在小样本数据集上的分类能力。
本发明的文本情感分类方法,包括有对待处理的文本数据进行预处理,步骤包括有:
a.在所述的预处理中包括了通过不同的现有的词向量模型对待处理的文本数据进行预训练,将同一个词经不同的词向量模型预训练后所对应的所有不同的词向量表达拼接为一个整体,形成优化后的词向量;
b.将所述优化后的词向量输入到不同的神经网络中,分别提取待处理的文本数据的不同特征;
c.将不同神经网络提取的所有特征拼接后进行分类处理,得到待处理的文本数据的每个处理样本属于不同情感类别的概率值。
通过多种不同的现有的词向量模型对文本数据进行预训练,并将所有训练后的词向量拼接进行优化,能够极大程度避免单个词向量模型对文本数据分析的局限性和片面性,有效提高了最终对文本所述不同情感类别的判断。
进一步的,步骤b中所述不同的神经网络包括卷积神经网络和循环神经网络。卷积神经网络(convolutionalneuralnetworks,cnn)是一类包含卷积计算且具有深度结构的前馈神经网络(feedforwardneuralnetworks),是深度学习的代表算法之一;循环神经网络(recurrentneuralnetwork,rnn)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。循环神经网络在自然语言处理,如语音识别、语言建模、机器翻译等领域有重要的应用,其具有记忆性、参数共享并且图灵完备等特点,能以很高的效率对序列的非线性特征进行学习。
具体的,所述的卷积神经网络通过不同尺寸的卷积核来提取所述文本数据中不同尺寸的特征,卷积核的尺寸一般在3~7之间。并将提取的所述特征经relu函数(rectifiedlinearunit,修正线性单元,一种人工神经网络中常用的激活函数,通常指代以斜坡函数及其变种为代表的非线性函数)非线性激活之后再进行一次topk(k个最大值)的池化操作进一步提取其特征,然后将进一步提取的特征拼接起来输出到步骤c中。
具体的,在所述的循环神经网络中依次通过双向lstm网络(longshort-termmemory,长短期记忆网络)和双向gru网络(lstm网络的一种变体)来提取所述文本数据的上下文特征,然后将提取的上下文特征输出到步骤c中。
进一步的,在步骤c中所述的分类处理中包括两个深度学习中常规的全连接层,并在每个全连接层后对拼接后的特征数据进行正则化和非线性变换,然后通过分类器输出待处理的文本数据的每个处理样本属于不同情感类别的概率值。其中正则化和非线性变换为本领域的常规方法,其步骤在此不再做详述。
优选的,步骤a中将所述的所有不同的词向量表达通过串联拼接为一个整体。
进一步的,为了防止不同的词向量模型过拟合,在步骤b所述的将优化后的词向量输入到不同的神经网络之前,通过spatialdropout方法(深度学习训练过程中的一种现有方法)随机置零一部分优化后的词向量数据。
进一步的,步骤a中,将不同的词向量模型预训练后所得到的所有不同的词向量表达先进行格式统一后,再拼接为一个整体。
在本发明方法的应用中,词向量模型可以包括现有技术中的任何词向量模型;对词向量表达的拼接可以是两种词向量模型预训练后的词向量表达的拼接,也可以是多种词向量模型预训练后的词向量表达的拼接;随机置零的词向量数据可以通过交叉验证的方法进行调整。
本发明的文本情感分类方法,显著提高了中文词语语义分析的准确性,并且大幅度提升了数据模型在小样本数据集上的分类能力。
以下结合实施例的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。在不脱离本发明上述技术思想情况下,根据本领域普通技术知识和惯用手段做出的各种替换或变更,均应包括在本发明的范围内。
附图说明
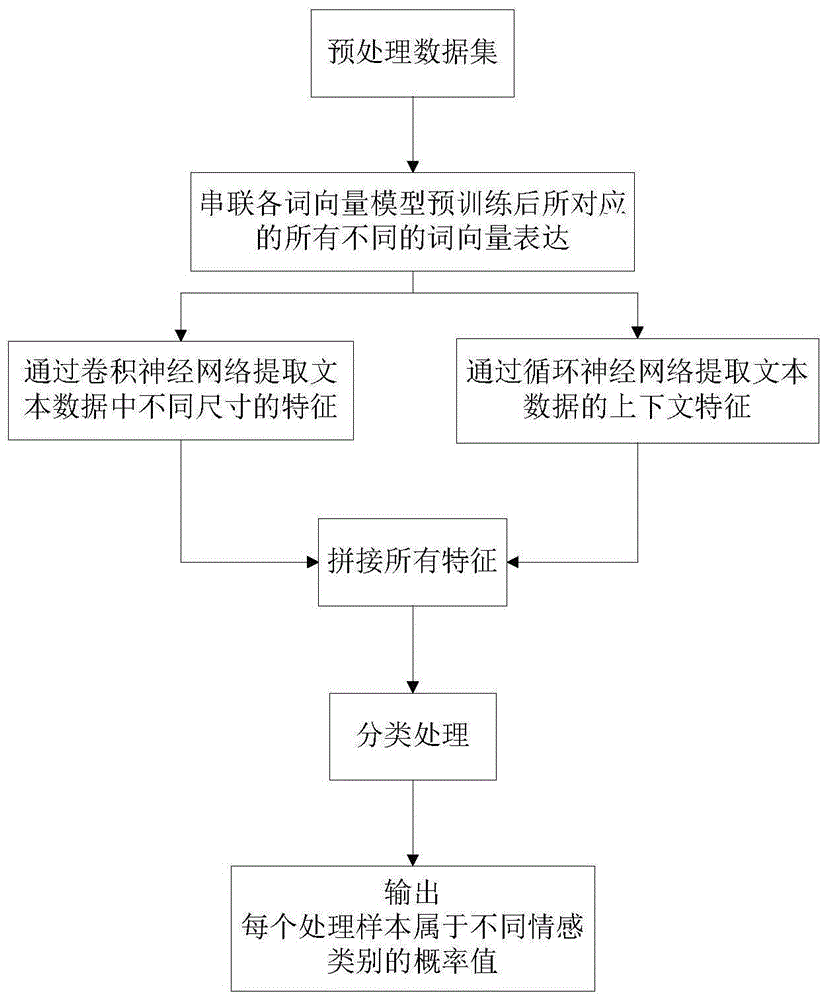
图1为本发明文本情感分类方法的流程图。
图2为现有的cnn分类模型和bilstm模型与本发明的对比实验数据图。
具体实施方式
如图1所示本发明文本情感分类方法,以nlpcc2013(naturallanguageprocessing)文本情感分析数据集为例,步骤包括有:
a.先对待处理的文本数据进行预处理,包括数据清洗、中文文本分词、去停用词等。在所述的预处理中还通过不同的现有的如word2vec、glove、fasttext等词向量模型对所述待处理的文本数据进行预训练。在本实施例的优化词向量中,首先在预训练时选择的数据集为搜狗全网新闻数据集,训练了word2vec和glove两种词向量,这两种词向量的训练可以按照分别直接调用自然语言处理的gensim库中的word2vec模块和斯坦福大学在github上公开的开源代码。将word2vec和glove两种词向量模型预训练后所得到的所有不同的词向量表达先进行格式统一后,再将同一个词经不同的词向量模型预训练后所对应的所有不同的词向量表达串联为一个整体,形成优化后的词向量。并且,为了防止不同的词向量模型过拟合,还通过spatialdropout方法随机置零一部分优化后的词向量数据。其中不同的词向量表达的拼接时可以是两种词向量技术的拼接,也可以是多种词向量技术的拼接,随机置零的概率值也可以通过交叉验证的方法进行调整。
b.将待处理的文本数据按8:1:1的比例划分为训练数据集、校验数据集和测试数据集;将所述串联后的词向量分别输入到卷积神经网络和循环神经网络中。在卷积神经网络中通过尺寸在3~7之间的卷积核来提取所述训练数据集中不同尺寸的特征,参数如表1所示。并将提取的所述特征经relu函数非线性激活之后再进行一次topk的池化操作进一步提取其特征。然后将进一步提取的特征拼接起来;在循环神经网络中依次通过双向lstm网络和双向gru网络来提取所述训练数据集的上下文特征。
表1:
本领域普通技术人员应当理解,卷积神经网络具有n个不同的卷积核,n为大于等于1的自然数,这些卷积核每两个之间尺寸可以相同也可以不同。表1中的其他参数也会随着实验数据的变化而变化。
c.将卷积神经网络进一步提取并拼接的特征、以及循环神经网络提取的上下文特征拼接后进行分类处理。在所示的分类处理中包括有两个深度学习中常规的全连接层,并在每个全连接层后对拼接后的特征数据进行正则化和非线性变换,然后通过softmax分类器输出待处理的文本数据的每个处理样本属于不同情感类别的概率值。
图2为现有的cnn分类模型和bilstm模型与本发明的对比实验数据。图2中的acc、p、r、f1分别表示准确率、精确率、召回率和f1-score,这几个值是文本情感分类中常用到的评价指标,对比实验为svm分类模型(bilstm模型)和最基本的卷积神经网络模型,thcrnn-att是本发明的分类模型。图2的条形图中,最左侧条形为svm分类模型的数据,中间条形为本发明分类模型的数据,最右侧条形为cnn分类模型的数据。从图2的实验数据中可以看出,本发明分类模型的性能在各个评价指标上都比现有的常规模型有了非常明显的提升。
- 还没有人留言评论。精彩留言会获得点赞!