基于张量分析的全分辨率深度卷积神经网络图像分类方法与流程
本发明涉及生物特征识别、人机交互、视频监控、无人驾驶等计算机视觉领域中图像分类方法,主要涉及基于深度卷积神经网络的图像分类方法。
背景技术:
图像分类是将给定的图像分成若干预先定义好的类别的过程。预先定义的类别包含行人、汽车、自行车、树木、电脑、飞机、船、鲜花等。图像分类包含特征提取和特征分类两个主要过程。深度卷积神经网络将这两个过程联合起来在一个框架下完成,其性能超越了独立手工特征设计和独立进行分类器设计的方法。需要特别指出的是,通过完成图像分类可以得到深度卷积神经网络的参数(主要是滤波器的参数),以这些参数作为初始参数将该深度卷积网络在物体检测、语义分割等其他任务为目的的图像数据库上重新训练可以得到适合进行这些新任务的网络参数。这个将以图像分类为任务的网络参数更新为以其他任务为目的的参数的过程称为参数微调,简称微调。实际上,大部分的深度卷积神经网络的参数都是从图像分类任务中得到初始参数,然后再在特定任务上进行微调的。因此,研究面向图像分类的深度卷积神经网络至关重要。本发明所提的方法除了可以进行图像分类外,也可以供其他任务进行参数微调。
深度卷积神经网络有两种策略:(1)从网络的输入层到输出层逐渐降低特征图的分辨率同时逐渐提高特征图的通道数,代表性的方法有:alexnet[1]、vggnet[2]、resnet[3]、densenet[4]等。由于顶层特征图的分辨率很低,导致其对小目标的分类性能较差。(2)从输入层到输出层始终保持各个特征层的分辨率与输入图像的分辨率一样大,这类方法称为全分辨率卷积神经网络。代表性方法有全分辨率残差网络(简称frrn)[5]和庞彦伟等提出的全分辨率深度卷积神经网络[6]。为了便于叙述,称文献[6]的全分辨率深度卷积神经网络为庞网络,对应英文为pangnet。全分辨率残差网络frrn[5]只能进行图像语义分割(即对图像每个像素赋予预先定义好的类别标签),但不能直接用来图像分类(即不能赋予整个图像一个预先定义好的类别标签)。与pangnet[6]相比,frrn[5]对特征图行了一系列的下采样和上采样,其起主要特征提取的卷积运算都是在下采样后的低分辨率特征图上进行的,而该下采样导致了较大程度的信息损失,其后虽然通过上采样得到了全分辨率特征图,但很难将损失信息重建出来。与frrn相比,pangnet能够完成图像分类。另外,pangnet全程没有进行下采样和上采样,所有卷积运算都是在全分辨率输入图像和特征图上进行的,是真正意义上的全分辨率深度卷积神经网络。
然而,文献[6]在得到全分辨率主干网络后进行分类时,将全分辨率特征图划分成若干区域,然后计算每个区域的平均值,最后对这些平均值进行全连接实现最终的分类。虽然计算平均值的效率很高,但这种方法本质上属于下采样操作,不能充分利用全分辨率特征图提供的大量信息。
参考文献:
[1]a.krizhevsky,i.sutskever,andg.e.hinton,“imagenetclassificationwithdeepconvolutionalneuralnetworks,”proc.advancesinneuralinformationprocessingsystems,2012.
[2]k.simonyananda.zisserman,“verydeepconvolutionalnetworksforlarge-scaleimagerecognition,”corr,vol.abs/1409.1556,2014.[online].available:http://arxiv.org/abs/1409.1556
[3]k.he,x.zhang,s.renandj.sun,“deepresiduallearningforimagerecognition,”inproc.ieeeconferenceoncomputervisionandpatternrecognition,pp.770-778,2016.
[4]g.huang,z.liu,andk.q.weinberger,“denselyconnectedcovolutionalnetworks,”inproc.ieeeinternationalconferenceoncomputervisionandpatternrecognition,2017.
[5]t.pohlen,a.hermans,m.mathias,andb.leibe,“full-resolutionresidualnetworksforsemanticsegmentationinstreetscenes,”inproc.ieeeinternationalconf.computervisionandpatternrecognition,2017
[6]庞彦伟,李亚钊,谢今,汪天才,张志杰,“基于全分辨率深度神经网络的图像分类方法”,中国发明专利,申请号:2019103795253,申请时间:2019年5月.
技术实现要素:
本发明提供一种面向全分辨率深度卷积神经网络的图像分类方法,其核心思想是在全分辨率深度卷积神经网络架构下通过一次或多次张量分析将主干网络输出层缩减为一个核张量,该核张量比主干网络输出层小很多;然后对该核张量实施一系列全连接完成最终的分类。与计算平均值不同,张量分析可以得到最优的低维特征,可以最大程度地利用全分辨率特征图所蕴含的信息。技术方案如下:
一种基于张量分析的全分辨率深度卷积神经网络图像分类方法,包括如下步骤:
步骤1:准备训练图像集合及集合中每幅图像的类别标签。设类别标签的个数为k、图像宽度为w、图像高度为h。
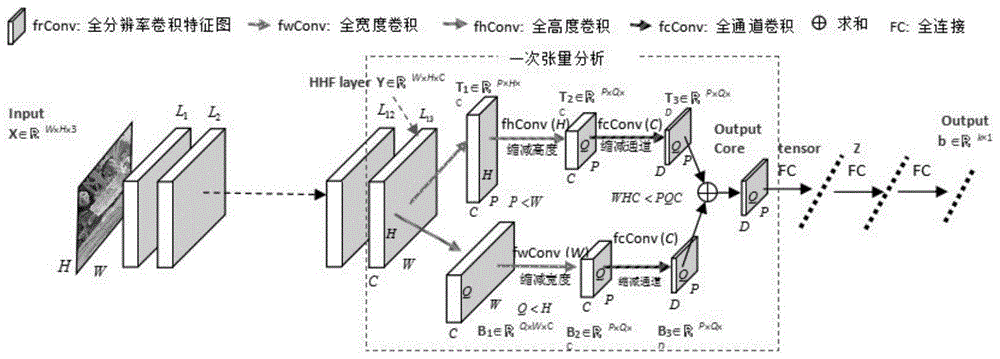
步骤2:设定全分辨率卷积神经网络的层数和计算全分辨率卷积所需要的滤波器参数,用全分辨率卷积得到主干网络,主干网络每个特征层的宽度和高度都与输入图像的宽度和高度一样大,记主干网络最后一层的特征图为张量y,其通道数为c,y的大小是whc。
步骤3:根据图像的大小确定张量分析次数,对张量y进行张量分析,以逐渐缩小y并得到核张量z,在第i次张量分析中将第i-1次张量分析的结果zi作输入,进行一次张量分析的过程如下:一次张量分析分为上下两个支路,对于上支路,首先对y进行全宽度卷积,将y的宽度缩减为p,得到张量记为t1,其大小为phc;然后对张量t1进行全高度卷积,将y的高度缩减为q,得到张量t2,其大小为pqc;接着对张量t2进行全通道卷积,将t2的通道数由c高度缩减为d,得到张量t3,其大小为pqd;下支路与上支路操作类似,但顺序不同,下支路依次进行全高度卷积、全宽度卷积和全通道卷积,对应地依次缩减高度、宽度和通道;下支路依次得到张量b1、b2和b3,其大小依次为wqc、pqc、和pqd;最后将上下两个支路的输出求和得到最终的核张量z,其大小为pqd;
步骤4:将步骤三张量分析得到的核张量z进行若干次全连接得到k维类别向量b,对类别向量的每个元素进行sigmoid运算,实现图像分类。
步骤5:设定整个深度卷积网络训练的损失函数,该损失函数主要衡量神经网络预测分类标签和图像真实标签之间的差别。
步骤6:通过反向传播算法,不断更新网络的权重参数,即全卷积滤波器的参数、张量分析的参数和全连接的参数,当迭代次数结束时,所学习的权重参数为最终的网络参数。
步骤7:给定待分类的图像,将其输入给全分辨率神经网络,输出的类别向量即是最终分类结果。
附图说明
图1:所提基于一次张量分析的全分辨率深度卷积神经网络结构图示意。适用于输入图像较小的情况。例如适用于大小为32×32的cifar图像数据库。
图2:所提基于二次张量分析的全分辨率深度卷积神经网络结构图示意。适用于输入图像较大的情况。例如适用于大小为224×224的imagenet图像数据库。
具体实施方式
本发明提供一种面向全分辨率深度卷积神经网络(如pangnet[6])的图像分类方法。跟其它深度卷积神经网络一样,pangnet等全分辨率深度卷积神经网络分为主干网络和分类网络(也称为分类模块)。本发明在给定某全分辨率深度卷积神经网络的主干网络基础上提出了一种新的分类模块,称之为深度张量分析模块。该模块旨在解决全分辨率深度卷积神经网络的主干网络输出层因分辨率太大而难以通过多层全连接操作进行有效分类的问题。将全分辨率特征图直接进行全连接需要非常多的参数,会导致过拟合现象也会严重降低计算效率。虽然文献[6]通过计算全分辨率特征图多个区域的平均值可以减少参数并提高计算效率,但计算平均值的过程损失了全分辨率特征图的信息。本发明的核心思想是在全分辨率深度卷积神经网络架构下通过一次或多次张量分析将主干网络输出层缩减为一个核张量,该核张量比主干网络输出层小很多;然后对该核张量实施一系列全连接完成最终的分类。与计算平均值不同,张量分析可以得到最优的低维特征,可以最大程度地利用全分辨率特征图所蕴含的信息。
一方面,所提张量分析过程与主干网络和最后的分类过程都是在深度学习框架下联合进行的,所以称为深度张量分析。另一方面,在进行一次张量分析缩减张量大小后再进行一下次张量分析进一步缩减张量大小,依次进行多次张量分析逐渐缩减张量的大小。接连进行张量分析的次数称为张量分析的深度,从这个意义上所提张量分析也是深度张分析。进行多次张量分析有助于得到鉴别能力更强的核张量,从而有助于分类任务。
图1给出了基于一次张量分析全分辨率深度卷积神经网络图像分类框架。图中“一次张量分析”模块是本发明创新点之一。首先对输入图像进行连续多次(图中为13次)全分辨率卷积,得到多层全分辨率特征层,分别记为:l1、l2、…、l13。将最后一层全分辨率特征层l13作为张量分析的输入。l13的大小为w×h×c,其中w和h分别是图像的宽度和高度,而c是该层特征图的通道个数。称l13为大小是w×h×c的三阶张量,记为y。张量分析的目的是将该张量y变换为大小p×q×d的三阶张量z。z的大小满足宽度p小于y的宽度w、高度q小于y的高度h、通道数d小于y的通道数c,并随之满足z的大小p×q×d小于y的大小w×h×c:p×q×d<w×h×c。称为尺度小于输入尺度的张量z为的核张量。下面重点叙述如何从y变换到核张量z。
为了说明所提张量分析模块的过程需要定义三种卷积。(1)全宽度卷积fwconv(w):在宽度方向上采用长度等于图像宽度w的卷积滤波器进行卷积,使输出的张量的宽度小于w,从而起到缩减宽度的作用;(2)全高度卷积fhconv(h):在高度方向上采用长度等于图像高度h的卷积滤波器进行卷积,使输出的张量的高度小于h,从而起到缩减高度的作用;(3)全通道卷积fcconv(c):在通道方向上采用长度等于主干网络通道数c的卷积滤波器进行卷积,使输出的张量的通道小于c,从而起到缩减通道的作用。
图1和图2分别给出了基于一次张量分析的分类过程和基于二次张量分析的分类过程。基于一次张量分析的分类过程适合于输入图像较小的情况,如cifar图像数据库中图像的大小是32×32;而基于二次张量分析的分类过程适用于输入图像较大的情况,如imagenet图像数据库中图像的大小是224×224。当图像继续增大时可以将二次张量分析扩展为三次、四次或更多次的张量分析。
图1所示一次张量分析模块分为上下两个支路。对于上支路,首先对y进行全宽度卷积fwconv(w),将y的宽度缩减为p(满足p<w),得到张量记为t1,其大小为p×h×c;然后对张量t1进行全高度卷积fhconv(h),将y的高度缩减为q(满足q<h),得到张量t2,其大小为p×q×c;接着对张量t2进行全通道卷积fcconv(c),将t2的通道数由c高度缩减为d(满足d<c),得到张量t3,其大小为p×q×d。简单来说,上支路依次进行全宽度卷积、全高度卷积和全通道卷积,对应地依次缩减宽度、高度和通道。下支路与上支路操作类似,但顺序不同。下支路依次进行全高度卷积、全宽度卷积和全通道卷积,对应地依次缩减高度、宽度和通道。下支路依次得到张量b1、b2和b3,其大小依次为w×q×c、p×q×c、和p×q×d。最后将上下两个支路的输出求和得到最终的核张量z,其大小为p×q×d,满足p×q×d<w×h×c。
张量分析模块后对核张量z进行若干次(图1和图2中是三次)全连接得到k维类别向量b,最后对类别向量的每个元素进行sigmoid运算,完成最终的图像分类。
- 还没有人留言评论。精彩留言会获得点赞!