一种基于无线射频信号的细粒度人体姿态估计方法与流程
本发明涉及人体姿态感知技术领域,具体为基于无线射频信号的细粒度人体姿态估计方法。
背景技术:
目前随着科学技术的发展以及人们生活水平的提高,智能家居理念与虚拟现实技术得到了迅速的发展。在视频监控、人机交互、运动分析和虚拟现实等计算机视觉领域的众多应用场合中,人体都是主要的被处理对象,对人体动作和行为的识别都是一个必不可少的环节,有着迫切的应用需求,已经成为计算机视觉领域中一个非常热门的研究方向。人体姿态估计是从单张rgb图像或视频中获取人体骨点位置以及骨点之间的相互连接,最终输出人体全部或局部肢体相关参数(各个关节点的相对位置关系)的过程,例如人体轮廓、头部的位置与朝向、人体关节的位置和部位类别等。人体姿态估计在智能监控、人机交互以及手势识别等领域有着广阔的应用前景。
为了进行像人体分割和姿势估计这一类细粒度的人体感知,目前主要使用了三大类传感器:摄像头,雷达和激光雷达。这些传感器可以在2d图像,深度图或3d点云中直接捕获具有高空间分辨率的人体。例如,300*300像素的摄像机,深度分辨率约为2厘米的雷达,或32波束的激光雷达。
基于摄像头进行人体分割和姿态估计的方法,可以在2d图像中直接捕获具有高空间分辨率的人体。但是,也受到了许多限制,例如,服装、背景、照明和遮挡等技术挑战以及诸如隐私问题等社会限制。
基于雷达传感器进行人体分割和姿态估计的方法,可以在深度图中直接捕获具有高空间分辨率的人体。但是,需要专用的硬件,例如,使用频率调制连续波(fmcw)技术,宽带宽(1.78ghz),精心组装和同步的16+4t形天线阵列。
基于高清晰度的激光雷达传感器进行人体分割和姿态估计的方法,可以在3d点云中直接捕获具有高空间分辨率的人体。但是,激光雷达非常昂贵并且耗电,因此难以在日常生活和家庭环境中大规模使用。
技术实现要素:
针对现有技术中存在的问题,本发明提供一种基于无线射频信号的细粒度人体姿态估计方法,利用普通的商用wifi,通过分析信道状态信息的不同变化模式来识别人体姿态变化,进行细粒度的人体感知,能够在实现较高识别准确度,同时满足方便性与安全性的。
本发明是通过以下技术方案来实现:
一种基于无线射频信号的细粒度人体姿态估计方法,包括以下步骤:
s1、采用具有多根天线的无线发射端和无线接收端建立波形稳定的wifi场,同时在无线发射端设置一个与无线发射端时间戳对准的同步相机;
s2、执行目标在wifi场中执行人体姿态,无线接收端接收穿过执行目标,以及在执行目标或周围物体上反射和折射的wifi信号,根据无线接收端接收的wifi信号计算得到人体姿态的信道状态信息csi值,同时,时间戳同步相机获取人体姿态的视频画面,完成数据的收集;
s3、根据信道状态信息csi值和所有视频帧的画面建立训练数据集d;
d={(it,ct),t∈[1,n]};
其中,it和ct分别为同一时刻的视频帧和csi值,t表示采样时刻,n是数据集大小;
s4、构建深度学习网络;
s5、根据训练数据集d对深度学习网络进行训练,得到训练好的深度学习网路,根据训练好的深度网路进行人体姿态估计。
优选的,步骤s2中得到信道状态信息csi值的方法具体如下:
csi=m×a×b×c
其中,m是接收到的wifi包的数量,a是ofdm载波数,b和c分别是无线发射端和无线接收端的天线数量。
优选的,步骤s3所述深度学习网络包括教师网路和学生网络,学生网络包括编码模块、特征提取模块和解码模块;
编码模块,用于将csi值ct的尺寸上采样至rgb标准尺寸;
特征提取模块,用于对上采样后的ct提取特征,并输出提取特征后的csi值ft;
解码模块,用于根据提取特征后的csi值ft,输出姿势相邻矩阵的相应预测矩阵ppamt;
教师网络,用于根据视频帧it输出姿势相邻矩阵pamt,对预测矩阵ppamt进行监督优化。
优选的,所述教师网络输出姿势相邻矩阵pamt的方法如下:
首先,使用alphapose方法处理视频中的每一帧画面,得到视频帧中执行目标的边界框,再将边界框通过姿势回归器进行处理,得到边界框中执行目标的姿势,以及生成n个三元素预测,n为要估计的关节点的数量;
然后,将人体的姿势和三元素预测转换姿势相邻矩阵pamt。
优选的,所述学生网络输出姿势相邻矩阵ppamt的方法如下:
所述编码模块为csi-net网络,使用双线性插值运算将ct∈r150×3×3进行上采样到ct∈r150×144×144;
特征提取模块为resnets网络中的4个基本resnet块,ct∈r150×144×144经过resnets网络的学习,输出ft∈r300×18×18;
解码模块为fcn网络,输入经过特征提取后的csi值ft,经过两个卷积层学习人物姿态特征,输出姿势相邻矩阵的相应预测矩阵ppamt。
优选的,采用损失函数l对预测矩阵ppamt进行优化,具体如下:
其中,ppamx和pamx分别是x轴上人体关节点坐标的预测矩阵和姿势相邻矩阵,ppamy和pamy分别是y轴上人体关节点坐标的预测矩阵和姿势相邻矩阵。
与现有技术相比,本发明具有以下有益的技术效果:
本发明提供的基于无线射频信号的细粒度人体姿态估计方法,利用无线发射端和无线接收端建立wifi场,当用户在wifi覆盖区内行走或做出某种动作时,会对wifi信道产生特定的影响,无线接收端接收wifi信号并计算人体姿态的csi值,同时获取用户在的行走或动作视频,根据获取的数据建立训练数据集d,根据训练数据集对深度学习网络进行训练,得到训练好的深度学习网路,根据训练好的深度网路进行人体姿态估计,实现利用wifi设备来进行单人姿态估计,本发明能够在实现较高识别准确度的同时满足方便性、易用性与安全性,且不需要用户携带任何特殊设备,具有方便易部署,安全性高的特点。
进一步,深度学习网络选择使用alphapose作为教师网络以及wisppn作为学生网络,可以避免仅使用alphapose方法进行回归关节点坐标所导致的损害人体姿态估计的泛化能力问题,也避免了仅使用wifi设备做人体感知导致的信号叠加,得到的空间信息较为粗粒度的问题。使得姿态估计能够实现较高识别准确度与细粒度。
附图说明
图1是本发明的总体框架图;
图2是实验场景部署示意图;
图3是相机部署示意图;
图4是相机与wifi信号同步示意图;
图5是构建姿态相邻矩阵(pam)过程示意图;
图6是本工作提出的一种新的深度网络的框架示意图;
图7是使用resnets网络来完成特征提取的过程示意图;
图8是特征提取过程的参数示意图;
图9是使用fcn网络对csi进行解码的过程示意图;
图10是实验结果图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,所述是对本发明的解释而不是限定。
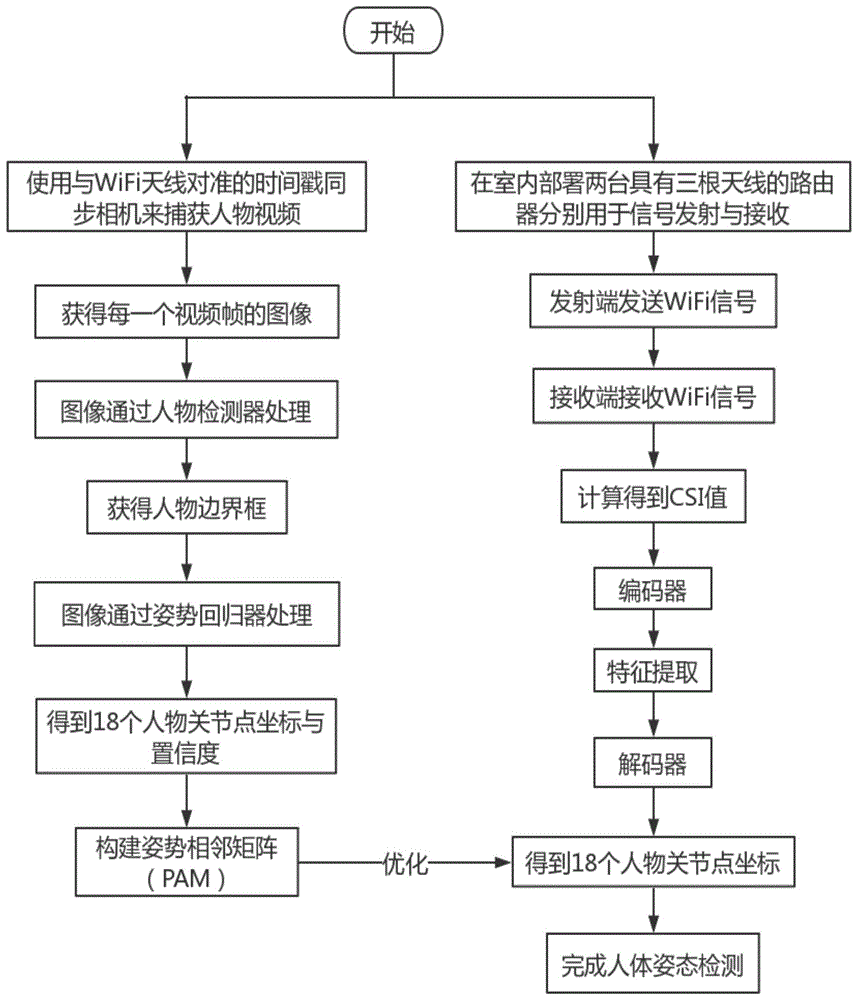
参阅图1,一种基于无线射频信号的细粒度人体姿态估计方法,具体步骤如下:
步骤1、参见图2,无线发射端使用具有三根天线的wifi发射器,和无线发射端使用具有三根天线的wifi接收器,建立波形稳定的wifi场。
步骤2、参见图3,在无线发射端旁边部署一个与wifi天线对准的时间戳同步相机,用来捕获人物每一帧的视频画面,图4所示为相机视频帧画面与wifi信号时间同步。
步骤3、一个人站在无线发射端和无线发射端之间所建立的wifi场中执行人体姿态,各个脉冲信号从发射端天线广播到接收端天线,wifi信号穿透人体或在人体、家具或/和墙表面进行反射或/和折射,wifi接收器用于接收所有的wifi信号,同时相机用来捕捉人体姿态的实时画面。
步骤4、当被穿透,折射和反射的信号到达接收天线时,折射信号和反射信号的叠加为单个信号样本,根据单个信号样本计算各个不同人的人体姿态的信道状态信息csi值,解析的csi值是一个尺寸为m×30×3×3的张量;
其中,m是接收到的wifi包的数量,30是ofdm载波数,最后两个3分别代表发送方和接收方的天线数量,完成数据收集。
步骤5、根据csi值和视频建立训练数据集为d={(it,ct),t∈[1,n]};
其中,it和ct分别是一对同步视频帧和csi值,t表示采样时刻,n是数据集大小。
步骤6、如图6所示,构建深度学习网络,通过训练数据集为d训练深度学习网络,目的是学习从csi序列到人体关节点的映射规则,深度网络包括作为教师网络的alphapose(称为t(·))和作为学生网络wisppn(称为s(·))组成,学生网络wisppn包括编码模块、特征提取模块和解码模块。
编码模块为csi-net网络,用于将csi值ct的尺寸上采样到rgb标准尺寸;
特征提取模块,使用resnets网络来完成特征提取,将4个基本的resnet块(16个卷积层)作为特征提取器,用于提取人物姿态特征,输出提取特征后的csi值。
解码模块,使用fcn网络方法学习人物姿态特征,输出姿势相邻矩阵的相应预测矩阵ppamt。
教师网络,用于根据视频帧it输出姿势相邻矩阵pamt,对预测矩阵ppamt进行优化。
步骤7、教师网络输出姿势相邻矩阵pamt,对于每个(it,ct),视频帧it作为的t(·)输入,t(·)输出相应的人体关节点坐标和置信度(xt,yt;ct),将输出转化为姿势相邻矩阵pamt,t表示采样时刻;所以教师网络的运行形式为t(it)→pamt,其中,pamt是为了跨模式监督s(·),具体方法如下。
步骤7.1、使用alphapose方法处理步骤3中相机捕捉到的人物在执行每一个人体姿态时每一视频帧的画面,将捕捉到的画面通过人物检测器处理,得到视频帧图像中人物的边界框,将边界框再通过姿势回归器进行处理,得到人物边界框内的人体的姿势,以及获得以(xi,yi;ci)的格式生成n个三元素预测;
其中,n是要估计的关节点的数量,关节点的坐标为(x,y,c),如图5所示;本工作中n=18,xi和yi分别是第i个关节点的横、纵坐标,ci是关节点坐标的置信度;
步骤7.2、将步骤7.1得到的人体的姿势和三元素预测转换为姿势相邻矩阵pamt,姿势相邻矩阵pamt由三个子矩阵(x′,y′,c′)组成,矩阵x′,矩阵y′和矩阵c′通过如下公式从18个三元素项(xi,yi;ci),i∈[1,2,…18]中生成,得到了一个3×18×18的pamt矩阵,即pam∈r3×18×18,成功的将人物关节点坐标以及关节点之间的位移嵌入到pamt中。
其中,i为矩阵的行,j为矩阵的列。
步骤8、学生网络wisppn(称为s(·)),在训练阶段,将csi值ct作为s(·)的输入,通过编码模块、特征提取模块和解码模块,输出姿势相邻矩阵的相应预测矩阵ppamt,具体方法如下。
步骤8.1、通过编码模块将csi值ct的尺寸上采样至rgb图像的尺寸;
由于wifi设备和摄像机的采样率分别设置为100hz和20hz。因此,一个配对数据集(it,ct)中每5个连续csi值和一个图像帧通过它们的时间戳同步。根据步骤4可知,csi尺寸为m×30×3×3,所以ct∈r5×30×3×3,沿着时间轴重新生成ct∈r150×3×3;但是,一般rgb图像大小为3×224×224,所以需要扩大csi值ct的宽度和高度以达到匹配;
为了扩大csi值ct的宽度和高度,ct作为输入,通过编码模块将csi值ct上采样到适当的宽度和高度来适合于之后的特征提取模块,具体编码过程如下:
csi-net网络使用双线性插值运算直接将其输入ct∈r150×3×3进行上采样到ct∈r150×144×144,为下一步特征提取做好准备;
步骤8.2、将经过上采样之后的ct作为输入,通过特征提取模块学习人物姿态估计的有效特征,具体特征提取过程如下:
如图7所示,使用resnets网络来完成特征提取,将4个基本的resnet块(16个卷积层)作为特征提取器,将ct∈r150×144×144经过resnets网络的学习,输出ft∈r300×18×18,ft是经过特征提取后的csi值,ct→ft具体转换过程如图8所示。
步骤8.3、将经过特征提取后的ft作为输入,通过解码模块学习人物姿态特征,输出姿势相邻矩阵的相应预测ppamt;
如图9所示,具体解码过程如下:将ft∈r300×18×18作为输入,使用fcn网络方法经过两个卷积层学习人物姿态特征,并输出姿势相邻矩阵的相应预测矩阵ppamt,从而重构了一维的空间信息;由于人体关节点可以被定位为x,y两个坐标,所以输出为ppamt∈r2×18×18;
步骤10、采用姿势相邻矩阵pam对ppamt监督优化,输处优化后的ppamt,优化方法如下;
在训练阶段,由教师网络的相应结果pam∈r3×18×18做监督,学生网络的结果ppamt∈r2×18×18作为预测,通过损失函数l对ppamt不断地进行优化,一旦学生网络学得很好,它就能获得仅用ct输入进行单人姿势估计ppamt的能力。
其中,ppamx和pamx分别是x轴上人体关节点坐标的姿态相邻矩阵的预测和监督,ppamy和pamy分别是y轴上人体关节点坐标的姿态相邻矩阵的预测和监督;
步骤11、学生网络wisppn对于每一个输入ct,学生网络wisppn都做出了姿势相邻矩阵的相应预测矩阵ppamt,即运行形式为s(ct)→ppamt,从而完成了人体姿态估计。
本发明提供的基于无线射频信号的细粒度人体姿态估计方法,利用具有三根天线的无线发射端建立wifi场,当用户在wifi覆盖区内行走或做出某种动作时,会对wifi信道产生特定的影响,利用具有三根天线的无线接收端接收wifi信号并计算人体姿态的csi值,对csi进行编码、提取特征、解码这一系列操作,使用与wifi天线对准的时间戳同步相机来捕获人物视频,利用人们在wifi场内移动或者执行某种姿态时捕捉到的画面通过人物检测器和姿势回归器输出人物姿势坐标和置信度,将输出结果转换为姿势相邻矩阵(pam),对通过wifi信号处理得到的人物姿势相邻矩阵的相应预测(ppam)进行监督并进行优化,从而实现利用wifi设备来进行单人姿态估计,本发明能够在实现较高识别准确度的同时满足方便性、易用性与安全性,且不需要用户携带任何特殊设备,不会记录用户的隐私生活,具有方便易部署,安全性高的特点。
如图10所述,在系统部署时需要使用具有三根天线的无线发射端发射稳定的wifi场,并使具有三根天线的无线接收端,增加了天线的数量可以捕获来自不同路径的信号,在接收天线处可以产生多种不同的信号叠加模式,有利于提高对人体姿态的识别精准度,使得结果相比于使用雷达、照相机等设备进行人体感知更加细粒度。
本发明有以下优点:使用本发明中的人体姿态估计技术与现有技术相比,这是第一个利用普通商用wifi设备进行人体感知对人体姿态估计的工作,之前的工作是利用相机、雷达或激光雷达对人体姿态进行估计的;使用普通商用wifi设备比雷达和激光雷达都更便宜和更省电,对照明不变,并且与使用相机进行人体姿态估计相比几乎没有隐私问题。而且,相对于使用相机、雷达或激光雷达设备做人体感知,可以实现细粒度的人体感知,能够在实现较高识别准确度的同时,满足方便性与安全性的一种基于无线射频信号的细粒度人体姿态估计方法。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!