基于主成分分析和神经网络的三峡水库水温预测方法与流程
本发明属于水电工程水文监测领域,具体涉及一种基于主成分分析和神经网络的三峡水库水温预测方法。
背景技术:
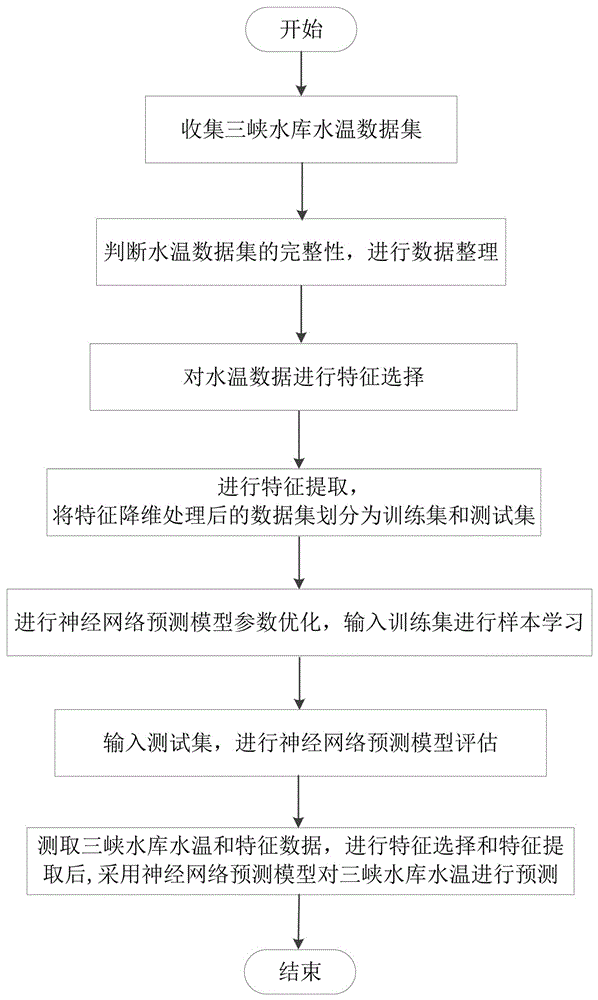
:在考虑河流水质和生物条件等问题时,水温具有经济和生态双重意义。水温是决定水生生态系统整体健康的河流生态学参数之一,对水生生物乃至水生生态系统有极其重要的影响。因此,对水温进行有效及精确的预测显得尤为重要。目前,在三峡库区中对水温进行预测的研究方法较少。现有技术中主要是通过传统的经验方法或者以数学模型为基础的数值预测,例如考虑水温与水流运动之间的关系建立二维k-ε模型进行水温预测的方法。这些预测方法的实时性不高,虽然在一定程度上可以反映当地流场、温度场的分布情况,但是由于本身的简化省略掉了许多重要的物理现象,精度不高。技术实现要素:本发明的技术问题是现有技术的三峡库区水温预测方法数据量大、数据冗余而导致的模型运行时间长、预测效果不好、预测精度不高。本发明的目的是提供一种基于主成分分析和神经网络的三峡水库水温预测方法,采用lightgbm方法、主成分分析法对水温数据进行特征选择和特征提取,形成数据集并对神经网络预测模型进行训练,使用神经网络预测模型对三峡库区水温进行预测。本发明的技术方案是基于主成分分析和神经网络的三峡水库水温预测方法,包括以下步骤,步骤1:收集多变量的三峡水库水温数据集;步骤2:判断三峡水库水温数据集的完整性,对数据集进行异常值检测,对数据集中的缺失值或者异常值,使用各自对应的特征平均值替代;步骤3:对水温数据进行特征选择,对特征参数进行重要性分析,选择出有较高重要性的特征集与水温组合成新的数据集;步骤4:进行特征提取,使用主成分分析法对新的数据集进行做特征降维处理,将特征降维处理后的数据集划分为训练集和测试集;步骤5:建立神经网络预测模型并进行参数优化,输入训练集,进行样本学习;步骤6:神经网络预测模型训练完成后,输入测试集,进行神经网络预测模型评估;步骤7:测取三峡水库水温和特征数据,采用步骤3的重要性分析方法进行特征选择,采用步骤4的主成分分析法进行特征提取后,作为神经网络预测模型的输入,采用神经网络预测模型对三峡水库水温进行预测。进一步地,步骤1中,所述多变量的三峡水库水温数据集包括降雨量、输出流量、输入流量、风速、相对湿度、气温、辐射和水温。进一步地,步骤3中,所述对特征参数进行重要性分析采用lightgbm方法。进一步地,步骤3中,所述新的数据集包括输出流量、输入流量、风速、相对湿度、气温、辐射和水温。进一步地,步骤5中,所述神经网络预测模型采用lstm神经网络。进一步地,所述lstm神经网络包含双层隐含层,批处理大小为72,隐含层维度为150。进一步地,所述lstm神经网络包括输入层、隐含层、dropout层和输出层。进一步地,所述的lstm神经网络采用relu激活函数、mse损失函数、adam优化器。相比现有技术,本发明的有益效果是本发明的方法有效地提高三峡库区水温预测精度、减小水温预测模型的计算量、提升数据的合理性。附图说明下面结合附图和实施例对本发明作进一步说明。图1为基于主成分分析和神经网络的三峡水库水温预测方法的流程示意图。图2为累积的特征重要性与特征数量的关系图。具体实施方式如图1所示,基于主成分分析和神经网络的三峡水库水温预测方法,包括以下步骤,步骤1:收集多变量的三峡水库水温数据集;步骤2:判断三峡水库水温数据集的完整性,对数据集进行异常值检测,对数据集中的缺失值或者异常值,使用各自对应的特征平均值替代;步骤3:使用lightgbm方法对水温数据进行特征选择,对特征参数进行重要性分析,选择出有较高重要性的特征集与水温组合成新的数据集;步骤4:进行特征提取,使用主成分分析法对新的数据集进行做特征降维处理,将特征降维处理后的数据集划分为训练集和测试集;步骤5:建立lstm神经网络预测模型并进行参数优化,输入训练集,进行样本学习;步骤6:lstm神经网络预测模型训练完成后,输入测试集,进行神经网络预测模型评估;步骤7:测取三峡水库水温和特征数据,采用步骤3的重要性分析方法进行特征选择,采用步骤4的主成分分析法进行特征提取后,作为lstm神经网络预测模型的输入,采用lstm神经网络预测模型对三峡水库水温进行预测。不同的环境因素对水温产生不同的影响,因此在对三峡水库库区的水温进行预测时,考虑多方面的水温影响因素,收集九年三峡水库的多变量的水温数据集,内容包括降雨量、输出流量、输入流量、风速、相对湿度、气温、辐射和水温。预测当前时刻的水温需要考虑前一时刻或者前几时刻的影响,属于时间序列问题,对处理长期依赖问题有良好效果的lstm神经网络用于水温预测具有独特优势。步骤2中,特征选择是指从已有的特征中选择重要性较高的几个特征组成新的数据集,以降低神经网络预测模型训练任务的难度和速度,增强对特征和特征值之间的理解。使用lightgbm方法计算各个特征参数的特征重要性,计算结果如表1所示,归一化后进行排序并进行累加,结果如附图2所示:在特征数量为6时,累积的特征重要性达到了0.998667,降雨量的特征重要性较低,因此选择其余的6个参数和水温组合成新的数据集。表1各个参数的特征重要性步骤3中,为了减小数据信息的冗余,对新的数据集使用主成分分析法进行特征提取。kmo(kaiser-meyer-olkin)值和bartlett球形度检验结果如表2所示,kmo值和barlett球形度检验均满足要求;解释的总方差如表3所示,可以看到成分1和成分2的特征值大于1,并且它们合计能解释78.252%的方法,因此提取出两个主成分,根据成份矩阵和成份得分系数矩阵确定提取因子与原来的参数之间的相关关系,得到降维后的特征参数集。收集的九年三峡水库的多变量的水温数据集中,将前五年的数据划分为训练集,后四年的数据划分为测试集,分别归一化后作为实验数据。表2kmo值和bartlett球形度检验结果表表3解释的总方差表本发明采用的lstm神经网络预测模型包括输入层、隐含层、dropout层和输出层,输出层采用线性输出。隐含层选取的神经元激活函数采用relu函数f(x)=max(0,x)当输入x<0时,输出为0,当x>0时,输出为x。该激活函数使lstm神经网络更快速地收敛并对抗梯度消失问题。lstm神经网络预测模型的目标误差函数采用mae函数式中,n为数据样本个数,y为真实值,为预测值。lstm神经网络预测模型采用adam优化器,adam优化器用来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值,从而最小化或者最大化损失函数。lstm神经网络预测模型经过优化后的参数:双层隐含层、批处理大小为72、隐含层维度为150、训练周期为300。本实施例分别使用步骤1的水温数据集和步骤3新的数据集,在4组神经网络模型上进行分析比较,实验结果如表4、表5所示,4组神经网络模型分别为cnn神经网络模型、rnn神经网络模型、gru神经网络模型、lstm神经网络模型。表4原数据集在不同模型上的实验结果表评价指标cnnrnngrulstmmae2.0270.3920.3040.275rmse2.6010.4910.4070.37r2_score0.730970.990400.993420.99421表5经过处理的数据集在不同模型上的实验结果表评价指标cnnrnngrulstmmae0.7910.2690.2590.254rmse1.0340.3870.3830.335r2_score0.957500.994040.994160.99538如表4、表5所示,分析比较结果表明,本发明提出的特征选择、特征提取的特征处理方法可以有效地提升数据的合理性、减小模型的计算量、提高模型的预测精度。同时,数据集在经过优化后的lstm神经网络上的表现优于其它的神经网络模型。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1