文本分类方法、模型和装置与流程
本发明涉及计算机领域,特别涉及一种文本分类方法、模型和装置。
背景技术:
随着互联网和社交媒体的发展,目前网络上已经有海量的文本信息,包括维基百科词条、学术文章、新闻报道、以及各种售后服务评论,而这些文本信息中蕴含了大量有价值的信息,现有的文本分类技术可以粗略的提取其中特定的信息,如通过对售后评论进行情感分析可以得知消费者对于该产品或者服务的满意度,通过对新闻数据进行分类可以大致区分新闻报道的领域,通过对维基百科数据的句子进行分类可以获得知识图谱中的关系等。总之,文本分类是一种极其重要的技术,目前,比较常用的方法包括传统文本分类方法,如svm、最近邻和决策树等,以及深度学习模型。
目前比较流行的深度学习模型有rnn(recurrentneuralnetwork)、cnn(convolutionalneuralnetworks)和transformer等。
rnn擅长对长序列的文本进行文本分类。cnn最先应用于图像处理,之后才应用于人工智能领域,cnn的优势在于可以更好地识别局部文本信息。transformer是谷歌提出来的新一代的编码器,其克服了rnn对序列信息之前状态的依赖,并且在大多数的人工智能处理任务中的表现都优于rnn和cnn,但transformer在中小型数据集上表现较差,并且训练极不稳定、长距离依赖能力并没有传统rnn优秀。
技术实现要素:
有鉴于此,本发明提供一种文本分类方法、模型和装置,以解决现有深度学习模型的不足。
本发明提供一种文本分类方法,该方法包括
将待分类文本转换为字向量v1;
将字向量v1输入cnn模型的卷积部分,cnn模型的卷积部分输出特征向量v3,将特征向量v3输入第一池化层,第一池化层输出特征向量v4;以及,将字向量v1输入第二池化层,第二池化层输出特征向量v5;
将特征向量v4和特征向量v5合并为特征向量v6;
将特征向量v6输入全连接层,全连接层输出待分类文本的文本分类。
本发明还提供一种文本分类模型,该模型包括:
向量转换层:用于将待分类文本转换为字向量v1;
特征提取层:用于将字向量v1输入cnn模型的卷积部分,cnn模型的卷积部分输出特征向量v3,将特征向量v3输入第一池化层,第一池化层输出特征向量v4;以及,用于将字向量v1输入第二池化层,第二池化层输出特征向量v5;
特征合并层:用于将特征向量v4和特征向量v5合并为特征向量v6;
全连接层:将特征向量v6输入全连接层,全连接层输出待分类文本的文本分类。
本发明还提供一种非瞬时计算机可读存储介质,非瞬时计算机可读存储介质存储指令,指令在由处理器执行时使得处理器执行上述的文本分类方法中的步骤。
本发明还提供一种文本分类装置,其特征在于,包括处理器和上述的非瞬时计算机可读存储介质。
本发明的文本分类方法,通过利用rnn和cnn的串联结构和其各具特点的建模方式获取到了不同语义层次的、更丰富的词向量特征,提高了分类的准确率。
该方法或模型结合了rnn优秀的长序列建模能力和cnn的局部建模的优势,在大多文本分类任务中的分类效果都要优于传统的rnn和cnn模型。
与transformer相比,本发明的文本分类方法或模型训练稳定,而且因为模型参数更少,只需要更少的硬件资源开销。
附图说明
图1为本发明文本分类方法的第一流程图;
图2为本发明文本分类方法的第二流程图;
图3为本发明文本分类方法的第一结构图;
图4为本发明文本分类方法的第二结构图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
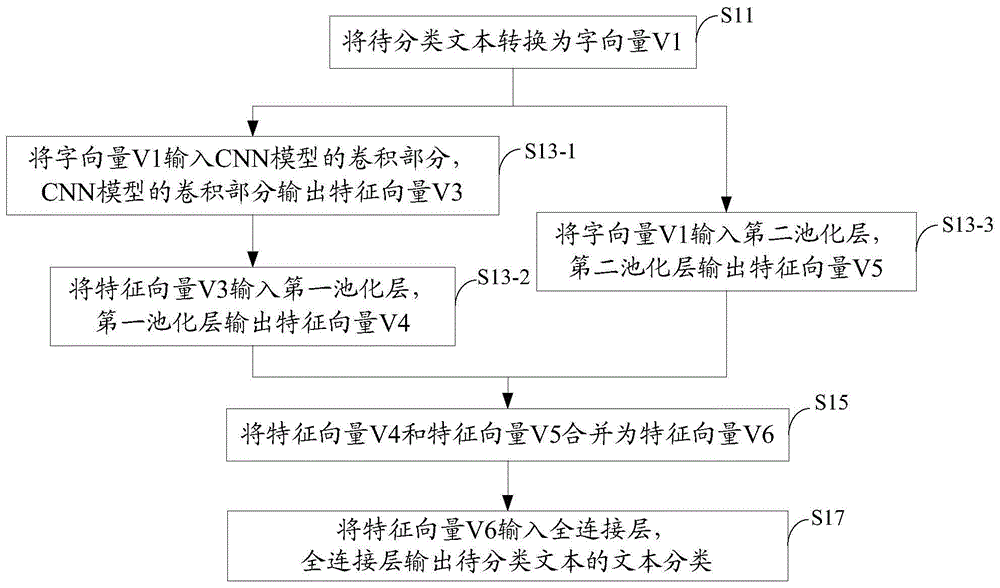
本发明提供一种文本分类方法,如图1所示,该方法包括
s11:将待分类文本转换为字向量v1;
s13包括s13-1、s13-2和s13-3;
s13-1:将字向量v1输入cnn模型的卷积部分,cnn模型的卷积部分输出特征向量v3;
s13-2:将特征向量v3输入第一池化层,第一池化层输出特征向量v4;
s13-3:将字向量v1输入第二池化层,第二池化层输出特征向量v5;
s15:将特征向量v4和特征向量v5合并为特征向量v6;
s17:将特征向量v6输入全连接层,全连接层输出待分类文本的文本分类。
其中,cnn模型的卷积部分包括一个卷积层或多个串联卷积层,每个卷积层由在先的多尺度卷积核卷积和在后的池化层组成。
其中,第一池化层和第二池化层可以是最大池化层或平均池化层。
可选地,如图2所示,还可以在s11与s13之间增加:
s12:将字向量v1输入blstm(bidirectionallongshort-termmemory)模型,blstm模型输出特征向量v1’;
相应地,s13-1调整为:将特征向量v1’输入cnn模型的卷积部分,cnn模型的卷积部分输出特征向量v3;
s13-3调整为:将特征向量v1’输入第二池化层,第二池化层输出特征向量v5;
blstm能双向提取待分类文本中长距离词的相关性,有利于提高后期文本分类的准确率。
本发明的文本分类方法,通过利用rnn和cnn的串联结构和其各具特点的建模方式获取到了不同语义层次的、更丰富的词向量特征,提高了分类的准确率。
该方法结合了rnn优秀的长序列建模能力和cnn的局部建模的优势,在大多文本分类任务中的分类效果都要优于传统的rnn和cnn模型。
与transformer相比,本发明的文本分类方法训练稳定,而且因为模型参数更少,只需要更少的硬件资源开销。
本发明还提供文本分类模型,如图3所示,该模型包括:向量转换层、特征提取层、特征合并层和全连接层。
向量转换层:用于将待分类文本转换为字向量v1;
特征提取层包括cnn模型的卷积部分、第一池化层和第二池化层;
cnn模型的卷积部分:用于将字向量v1输入cnn模型的卷积部分,cnn模型的卷积部分输出特征向量v3;
第一池化层:用于将特征向量v3输入第一池化层,第一池化层输出特征向量v4;
第二池化层:用于将字向量v1输入第二池化层,第二池化层输出特征向量v5;
特征合并层:用于将特征向量v4和特征向量v5合并为特征向量v6;
全连接层:将特征向量v6输入全连接层;全连接层输出待分类文本的文本分类。
其中,如图4所示,在向量转换层和特征提取层之间还可以包括:
blmst模型,blmst模型输入字向量v1,输出特征向量v1’。
相应地,cnn模型的卷积部分适用性调整为:用于将特征向量v1’输入cnn模型的卷积部分,cnn模型的卷积部分输出特征向量v3;
第二池化层适用性调整为:用于将特征向量v1’输入第二池化层,第二池化层输出特征向量v5。
本发明还提供一种非瞬时计算机可读存储介质,非瞬时计算机可读存储介质存储指令,指令在由处理器执行时使得处理器执行上述的文本分类方法中的步骤。
本发明还提供一种文本分类装置,其特征在于,包括处理器和上述的非瞬时计算机可读存储介质。
需要说明的是,本发明的文本分类模型或装置的实施例,与文本分类方法的实施例原理相同,相关之处可以互相参照。
以上所述仅为本发明的较佳实施例而已,并不用以限定本发明的包含范围,凡在本发明技术方案的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!