一种基于YOLOV3-tiny的改进目标检测方法与流程
本发明属于图像识别技术领域,具体涉及一种基于目标检测神经网络yolov3-tiny算法的优化方法,特别适用于在嵌入式平台等计算能力较弱的硬件上进行小目标检测任务。
背景技术:
近年来,随着人工智能、深度学习技术的发展,利用卷积神经网络进行图像理解类任务逐渐代替人工提取特征制作分类器的方法。对于卷积神经网络模型,随着网络层数的增加,神经网络对图像的理解越来越丰富,目标检测识别精度越来越高,但计算量也随之增长。现阶段运算目标检测算法一般是在拥有gpu加速的服务器上运算,这种设备价格昂贵,无法在工业上被广泛采用。而一般的嵌入式平台由于计算能力有限,因此对于大型目标检测网络会出现无法计算出结果或计算耗时长的问题。yolov3-tiny网络是基于yolov3算法的一个轻量化目标检测网络,其网络层数少、参数量少,在一般的嵌入式平台上可以基本保证实时运算。但yolov3-tiny只在13*13和26*26这两个尺度上预测,所以面对小物体检测场景效果不佳。
技术实现要素:
为解决现有技术存在的上述问题,本发明要设计一种面对小物体检测场景效果好的基于yolov3-tiny的改进目标检测方法。
为了实现上述目的,本发明的技术方案如下:一种基于yolov3-tiny的改进目标检测方法,包括以下步骤:
第一步,确认要检测的目标种类
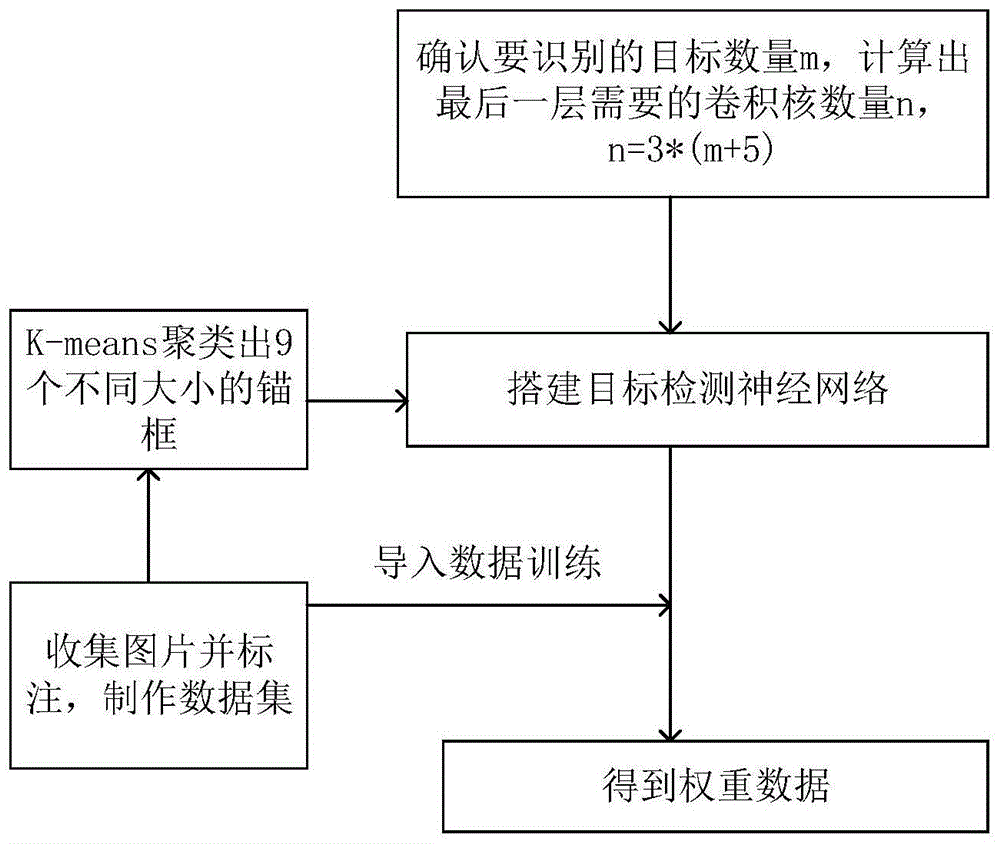
确认要识别的目标数量m,则最后一层滤波器的数量为n=3*(m+5),其中“3”代表3个锚框,“5”代表检测框的中心点x坐标,中心点y坐标、宽度、高度以及置信度这5个量。收集若干张包含目标的图片,并在每张图片中标记出目标的位置,将图片和标记文件构成数据集。
第二步,获取所有目标标注框的宽高占原图宽高的比例数据
对于图片中的每个标注框,设其宽度和高度分别为w和h,对应原图宽度和高度分别为w和h。获取所有目标标注框的宽度和高度占原图宽度和高度的比例数据,即w/w和h/h,这样得到若干组数据。
第三步,用k-means算法聚类出9个不同大小的锚框
根据所有宽高的比例数据,用k-means算法聚类出9个不同大小的锚框。聚类步骤如下:
a、任意选取9组数据,作为9个聚类质心。
b、计算其余所有数据与这9组数据的交并比,对于每组数据,与这9组数据中交并比最大的那组数据属于一类,这样把数据分成了9类。其中交并比计算公式为:
式中w1、h1和w2、h2分别为两组数据的宽高占比。
c、对于分出来的9类数据,将每类数据的宽度中位数和高度中位数作为该类数据新的聚类质心。
d、转到步骤b,直到聚类质心不变。将最终得到的9个聚类质心乘416即得到9个锚框的参数。
第四步,搭建目标检测神经网络
搭建目标检测神经网络yolov3-tiny并在52*52的尺度上增加一个预测结果。具体网络结构如下:
输入图片为r、g和b的彩色图片,大小为416*416。
经过卷积层,使用16个大小为3*3的卷积核,步长为1,得到416*416*16的输出数据;通过核大小为2*2,步长为2的最大池化层,得到数据大小为208*208*16;
经过卷积层,使用32个大小为3*3的卷积核,步长为1,得到208*208*32的输出数据;通过核大小为2*2,步长为2的最大池化层,得到数据大小为104*104*32;
经过卷积层,使用64个大小为3*3的卷积核,步长为1,得到104*104*64的输出数据;通过核大小为2*2,步长为2的最大池化层,得到数据大小为52*52*64;
经过卷积层,使用128个大小为3*3的卷积核,步长为1,得到52*52*128的输出数据;通过核大小为2*2,步长为2的最大池化层,得到数据大小为26*26*128;
经过卷积层,使用256个大小为3*3的卷积核,步长为1,得到26*26*256的输出数据;通过核大小为2*2,步长为2的最大池化层,得到数据大小为13*13*256;
经过卷积层,使用512个大小为3*3的卷积核,步长为1,得到13*13*512的输出数据;通过核大小为2*2,步长为1的最大池化层,得到数据大小为13*13*512;最后连接一个卷积层使用1024个大小为3*3的卷积核,步长为1,得到13*13*1024的数据。
对于最终得到的13*13*1024的特征图数据,先通过卷积层,使用256个1*1大小的卷积核,得到13*13*256大小的数据;再通过卷积层,使用512个3*3大小的卷积核,最后连接一个有n个1*1大小的卷积核,得到13*13这个尺度上的预测结果,其中n由第一步计算得到。在这个尺度上使用9个锚框中面积最大的三个锚框进行预测。
对于13*13这个尺度中的13*13*256的数据,经过128个1*1卷积核的卷积层得到13*13*128大小的数据,将这个数据上采样得到26*26*128大小的数据,并与卷积层5的输出相连接,得到26*26*384大小的数据,再经过256个3*3卷积核的卷积层得到26*26*256大小的数据,最后通过n个1*1卷积核的卷积层得到26*26这个尺度上的预测结果,其中n在第一步中算出。在这个尺度上使用9个锚框中面积中等的三个锚框进行预测。
再对于26*26这个尺度上的26*26*256大小的数据,经过128个1*1卷积核得到数据大小为26*26*128,然后向上采样得到52*52*128,与卷积层4的输出结果相连接,得到52*52*256大小的数据,再通过256个3*3卷积核的卷积层得到52*52*256大小的数据,最后通过n个1*1卷积核的卷积层得到52*52这个尺度上的预测结果,其中n在第一步中算出。在这个尺度上使用9个锚框中面积最小的三个锚框进行预测。
得到13*13,26*26和52*52这三个尺度的预测结果之后使用非极大值抑制算法得到最终的检测结果。
第五步,得到训练权重文件
用第一步中获得的数据集训练第三步中搭建的目标检测神经网络,并判断训练误差,当误差长时间保持在2.0以下则停止训练,得到训练权重文件。
与现有技术相比,本发明的有益技术效果在于:
1、本发明采用轻量化目标检测网络yolov3-tiny,计算量小,能够在嵌入式硬件中进行目标检测任务并保证实时性。
2、就yolov3-tiny这个网络而言,目标检测分别在13*13和26*26这两个尺度上产生预测结果。例如原图大小为416*416,那么理论上能被检测出来的最小目标尺寸为16*16,若目标大小小于16*16则无法被检测出来。本发明通过在原始yolov3-tiny网络上增加52*52的预测尺度,来提高目标检测网络对小物体的检测效果,增加52*52尺度后,理论上能被检测出来的最小目标尺寸为8*8,能够在不降低检测速度的前提下提高对小物体的检测精度。
附图说明
图1是本发明的流程图。
图2是优化后的目标检测网络结构图。
具体实施方式
下面结合附图对本发明进行进一步地说明。如图1所示,一种基于yolov3-tiny的改进目标检测方法,包括以下步骤:
第一步,确认要检测的目标种类;
第二步,获取所有目标标注框的宽高占原图宽高的比例数据;
第三步,用k-means算法聚类出9个不同大小的锚框;
第四步,搭建如图2所示的目标检测神经网络;
第五步,得到训练权重文件。
本发明不局限于本实施例,任何在本发明披露的技术范围内的等同构思或者改变,均列为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!