一种水利门户信息混合推荐方法与流程
本发明属于信息处理技术领域,特别涉及一种水利门户信息混合推荐方法。
背景技术:
水利门户网站按照信息发布的时间先后顺序,将信息展现在网站上,然而,这种信息展现方式存在以下缺点:
(1)发布形式单一,缺乏灵活性。网站按照信息发布的时间顺序向所有用户提供相同信息,未考虑用户偏好,缺乏灵活性。
(2)用户查找信息难度大,体验感差。用户在浏览水利门户网站时,通常会根据需求在网站上查找门户信息。然而,随着水利门户信息的不断增多,用户查找目标信息的难度不断增加,用户浏览网站体验感差。
(3)用户易错过重要的水利门户信息。水利门户网站会经常对洪涝旱灾、台风等灾害情况作出预报,信息量的增多使得用户易错失重大灾害的预警信息。
个性化推荐系统是一种能够帮助用户快速获取有价值信息的工具。推荐技术通过分析用户历史行为找出用户的兴趣所在,向用户推荐满足其兴趣的信息,推荐技术在现实中经常能看见,例如,新闻网站根据人们的web浏览日志建立用户兴趣模型,为用户推荐其可能喜欢的新闻;电子商务网站通过获取用户在其他社交平台的好友列表以及好友在该平台上的喜好信息,并将好友喜欢的物品推荐给用户以满足其个性化需求;视频网站采用基于标签的个性化推荐方法,缩短用户寻找目标视频的时间。目前,国内外对于推荐技术的研究已达到了一定水平,但通过调研发现,推荐技术并未被应用到水利门户网站。当前个性化推荐领域通常采用基于用户的协同过滤推荐方法或者基于内容的推荐方法为用户进行推荐,将这些技术应用于水利门户网站还存在以下问题:
(1)冷启动问题:基于用户的协同过滤推荐方法存在着一定的“项目冷启动”问题,即新水利门户信息如果不被大量用户阅读将得不到有效推荐;两种方法都存在“用户冷启动”问题,即当新用户浏览网站时,因为没有用户历史性行为数据,对新用户的兴趣无法准确表达。
(2)数据稀疏性:基于用户的协同过滤推荐在相似度计算时存在一定的数据稀疏性问题,即随着推荐规模的不断增大,两个用户同时关注同一水利门户信息的可能性越来越小。
(3)适应性问题:水利门户网站根据时间和空间的变化业务会有所侧重,提高用户对本地区当前可能发生的与水利相关的重点问题的认知、突发状况防范意识很是重要。
技术实现要素:
发明目的:为了克服现有水利门户网站信息发布方式形式单一,缺乏吸引力,用户查找信息难度大,体验感差,满意度低,用户易错过重要的水利门户信息等缺点以及推荐技术应用到水利门户网站中存在的冷启动问题、数据稀疏性以及适应性问题,本发明提供一种水利门户信息混合推荐方法,将水利门户信息按照水利业务以及自身特性特征进行分类,在此基础上考虑用户兴趣衰减、水利门户信息时效以及不同时空下水利业务热点的变化,构建混合推荐模型,提高水利信息推荐的准确性和专业性,实现推荐技术在水利门户网站上的创新应用。
技术方案:为实现上述目的,本发明提供一种水利门户信息混合推荐方法,包括如下步骤:
(1)建立水利门户信息分类体系,将水利门户信息分为:水文信息、水资源信息、水环境水生态信息、水利工程信息、农村水利信息、水灾害即防汛抗旱信息、水土保持信息、移民信息、政务信息以及其他信息一共十类。
(2)建立水利门户信息分类模型;
(3)利用构建的分类模型实现水利门户信息推荐数据集每条水利门户信息类别判断;
(4)建立基于时空敏感的热点信息推荐模型,依据不同时间和空间位置,为用户推荐当前热点水利门户信息;
(5)建立基于用户和信息类别的协同过滤推荐模型,实现top-n推荐;
(6)建立基于信息内容的水利门户信息推荐模型,实现top-n推荐;
(7)建立基于步骤(4)的时空敏感的热点信息推荐模型、基于步骤(5)的用户和信息类别的协同过滤推荐模型和步骤(6)的信息内容推荐模型线性加权的混合推荐模型,实现top-n推荐;
(8)对于新用户,采用步骤(4)的基于时空敏感的热点信息推荐模型推荐当前时间和空间位置的热点门户信息,对老用户,采用步骤(7)的混合推荐模型,推荐门户信息。
进一步的,所述步骤(2)中建立水利门户信息分类模型的具体步骤如下:
(2.1)通过网络爬虫收集水利门户信息分类数据集并对其按照事先定义好的水利门户信息分类体系分类;
(2.2)对分类好的水利门户信息分类数据进行预处理,包括分词和去除停用词;
(2.3)用向量空间模型对预处理好的词语进行表示,使用chi实现特征提取:
特征词tk对类别ci的chi如下:
其中,n表示训练集文档总数,n=a+b+c+d,a表示包含特征词tk且属于类别ci的文档次数,b表示包含特征词tk但不属于类别ci的文档次数,c表示不包含特征词tk但属于类别ci的文档次数,d表示不包含特征词tk且不属于类别ci的文档次数;
分别计算tk对每一类的chi值,再计算词条tk对于整个语料的chi值:
其中,c表示类别总数;选取出chi值最高的k个数对应的特征项用于文本表示;
(2.4)利用knn算法构建分类器,实现水利门户信息分类器构造:
每一类的权重计算如下,即:
其中,x为新的门户信息的特征向量,xj表示训练集文本j的特征向量,sim(x,xj)表示两者之间的相似度,s表示训练集文档的总数,y(xj,ci)表示类别属性函数,如果xj属于该业务类别,则设置为1,如果不属于,则设置为0。
进一步的,所述步骤(3)中利用构建的分类模型实现水利门户信息推荐数据集每条水利门户信息类别判断的具体步骤如下:
(3.1)推荐数据收集和预处理:推算算法的实现需要用户行为数据以及水利门户信息推荐数据,该部分数据通过调查获得,对获取的数据进行整理、筛选和格式统一,将用户行为数据表示成包括用户编号、信息编号、信息标题、信息内容、类别编号、发布日期、阅读日期的参数的形式,水利门户信息推荐数据表示成包括信息编号、信息标题、信息内容、类别编号、发布日期的参数的形式;
(3.2)水利门户信息推荐数据集类别标记:利用构建好的水利门户信息分类器对推荐数据集中的每篇水利门户信息类别进行判断。
进一步的,所述步骤(4)中建立基于时空敏感的热点信息推荐模型的具体步骤如下:
(4.1)网站根据其所处的空间位置事先定义好当前时间的热门水利门户信息类别;
(4.2)根据水利门户信息流行度和时效性计算用户对水利门户信息的兴趣度i;
(4.3)根据兴趣度i进行排名,生成top-n推荐列表。
进一步的,所述步骤(5)中建立基于用户和信息类别的水利门户信息协同过滤推荐模型的具体步骤如下:
(5.1)根据用户行为数据中用户阅读的水利门户信息的类别构建用户-水利门户信息类别兴趣度矩阵muwc,并加入用户兴趣衰减函数f(t)实现用户兴趣更新;
(5.2)根据矩阵muwc利用余弦相似度公式计算用户之间的相似度,找与当前用户类别兴趣相似的用户;
(5.3)与水利门户信息时效性公式k(t)相乘计算用户对相似用户阅读的水利门户信息的兴趣度i;
(5.4)根据兴趣度i进行排名,去除用户已经看过的水利门户信息,生成top-n推荐列表。
进一步的,所述步骤(6)中建立基于信息内容的水利门户信息推荐模型的具体步骤如下:
(6.1)对水利门户信息推荐数据以及用户行为数据进行预处理,包括分词和去除停用词;
(6.2)通过lda主题模型和向量空间模型提取用户行为数据中用户的主题兴趣向量tu和关键词兴趣向量ku,构建用户兴趣模型,并加入用户兴趣衰减函数f(t)实现用户兴趣模型更新;
(6.3)通过lda主题模型和向量空间模型提取水利门户信息推荐数据集中的主题特征向量tn和关键词特征向量kn,构建水利门户信息模型;
(6.4)计算用户兴趣模型和水利门户信息模型两种模型的配度,与水利门户信息时效性公式k(t)相乘计算用户对每篇水利门户信息的兴趣度i;
(6.5)根据兴趣度i进行排名,去除用户已经看过的水利门户信息,生成top-n推荐列表。
进一步的,所述步骤(7)中建立混合推荐模型的具体步骤如下:
(7.1)将三种推荐方式混合,设置初始推荐比例为1:1:1;
(7.2)根据用户的点击行为调整推荐比例;
(7.3)去除重复项,生成最终的推荐列表。
有益效果:本发明与现有技术相比具有以下优点:
对于单一的推荐方法,本发明所提的水利门户信息混合推荐方法在推荐准确率、召回率以及f1-score上有所提升;本发明所提的能更好地适应不同时间和空间的业务变化,提高用户对当前可能发生的与水利相关的突发状况的认识和防范意识,如洪水、台风、抗旱等;在考虑新老用户不同特征的情况下,有效解决冷启动问题以及数据稀疏性问题;最终实现推荐技术在水利门户网站的创新型应用,提高用户使用水利门户网站的满意度。
附图说明
图1为本发明的方法流程图;
图2为图1中混合推荐流程图;
图3为具体实施例中特征维数变化时f1-score变化规律图;
图4为具体实施例中主题变化时f1-score变化规律图;
图5为具体实施例中五种推荐算法准确率(precision)对比图;
图6为具体实施例中五种推荐算法召回率(recall)对比图;
图7为具体实施例中五种推荐算法f1-score对比图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
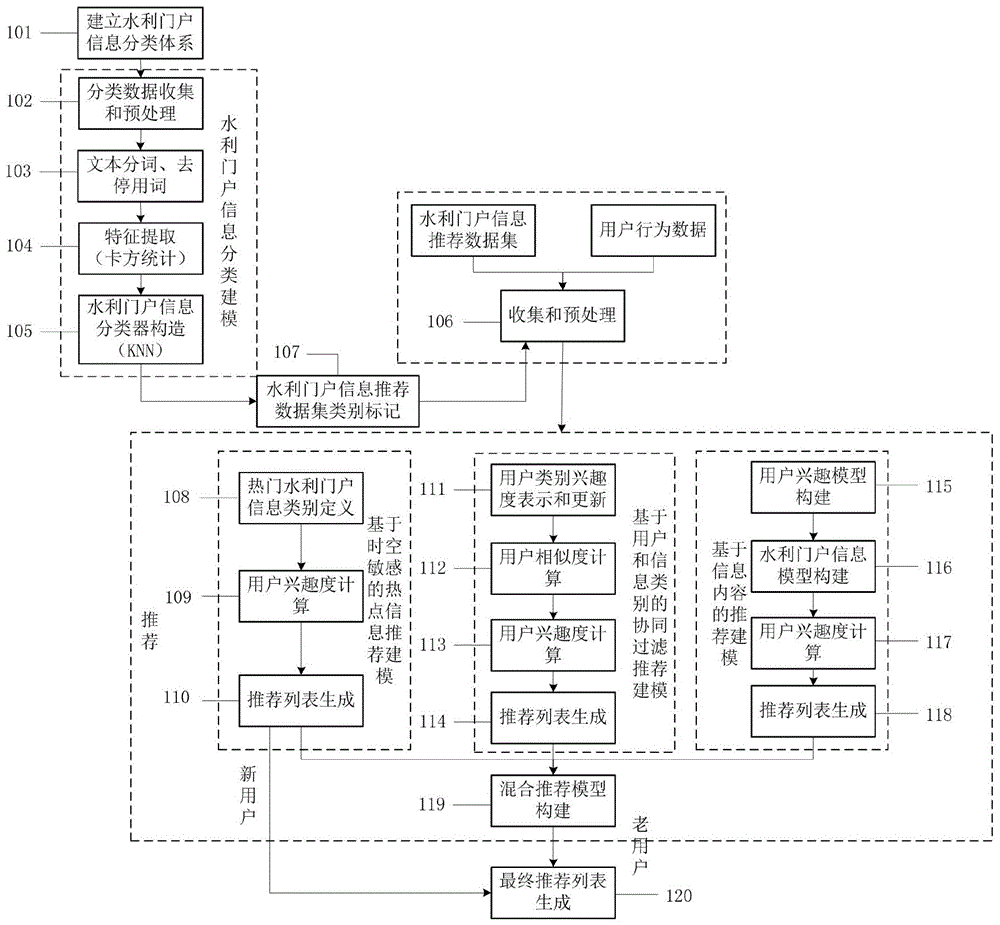
如图1所示,一种水利门户信息混合推荐方法,包括以下步骤:
步骤101:建立水利门户信息分类体系:将水利门户信息按照水利业务类别划分为水文信息、水资源信息、水环境水生态信息、水利工程信息、农村水利信息、水灾害(防汛抗旱)信息、水土保持信息、移民信息、政务信息、其他10种类别。
构建水利门户信息分类模型的具体步骤为:
步骤102:分类数据收集和预处理:分类数据是实现水利门户信息分类数据集类别判断的样本数据集,用于构建水利门户信息分类器。通过网络爬虫到各水利部门(如流域、水文局等)门户网站爬取各类水利门户信息,网站上获取的水利门户信息数量众多且数据格式没有得到统一,按照事先定义的水利门户信息分类体系对数据进行手动筛选、分类、格式统一,将分类数据集表示成包括类别编号、类别名、信息编号、信息标题以及信息内容的形式。
步骤103:文本分词、去除停用词
对语料库中的数据进行预处理,包括分词和去除停用词。经过多方面考虑与实践,本发明选择了jieba分词工具实现文本分词这一需求。利用哈工大停用词表、四川大学机器学习智能实验停用词库、百度停用词库等停用词库对停用词进行识别、去除。
步骤104:特征提取:在对文本进行预处理之后,用向量空间模型对词语进行表示。预处理后每个类别的特征词语集词数众多,会造成维度的灾害,同时对于分类也会有影响。因此需要进行特征选择,选出对分类贡献度大的词语代替原始特征集合,本发明通过使用chi实现特征提取。特征词tk对类别ci的chi如下:
其中,n表示训练集文档总数,n=a+b+c+d,a表示包含特征词tk且属于类别ci的文档次数,b表示包含特征词tk但不属于类别ci的文档次数,c表示不包含特征词tk但属于类别ci的文档次数,d表示不包含特征词tk且不属于类别ci的文档次数。
分别计算tk对每一类的chi值,再计算词条tk对于整个语料的chi值:
其中,c表示类别总数。选取出chi值最高的k个数对应的特征项用于文本表示。
步骤105:水利门户信息分类器构建:分类的关键在于分类器的构造,本发明选择用knn实现水利门户信息分类这一需求。
每一类的权重计算如下,即:
其中,x为新的门户信息的特征向量,xj表示训练集文本j的特征向量,sim(x,xj)表示两者之间的相似度,s表示训练集文档的总数,y(xj,ci)表示类别属性函数,如果xj属于该业务类别,则设置为1,如果不属于,则设置为0。
通过上面的一系列操作,完成水利门户信息分类器的构造,为下面的推荐模型构建做准备。
步骤106:推荐数据收集和预处理:推算算法的实现需要用户行为数据以及水利门户信息推荐数据,该部分数据通过调查获得,对获取的数据进行整理、筛选和格式统一,将用户行为数据表示成包括用户编号、信息编号、信息标题、信息内容、类别编号、发布日期、阅读日期等参数的形式,水利门户信息推荐数据表示成包括信息编号、信息标题、信息内容、类别编号、发布日期等参数的形式。
步骤107:水利门户信息推荐数据集类别标记:利用构建好的水利门户信息分类器对推荐数据集中的每篇水利门户信息类别进行判断。
基于时空敏感的热点信息推荐建模步骤如下:
步骤108:根据网站所处的空间位置事先定义好当前时间的热门水利门户信息类别;
步骤109:用户兴趣度计算:根据水利门户信息流行度和时效性计算用户对水利门户信息的兴趣度i。
(1)水利门户信息流行度。流行度越高,表示该大部分用户对该水利门户信息的兴趣度越高,使用所有用户对该水利门户信息的点击数来表示其流行度;
(2)水利门户信息时效性。考虑到用户对水利门户信息的兴趣度会随着时间衰减,因此在计算用户对水利门户信息兴趣度时,需要把时效性公式引入,最终得到如下公式所示的用户兴趣值i:
i(u,n)=pa×μun×k(t)
其中,u是用户,n是水利门户网站事先定义的热门水利门户信息类别中的水利门户信息,i(u,n)是用户u对水利门户信息n的最终兴趣程度,pa表示所有用户对水利门户信息n的点击数,μun表示用户u对水利门户信息n的初始兴趣度,μun设置为1,k(t)表示时效性。
步骤110:推荐列表生成:根据兴趣度i进行排名,生成top-n推荐列表
构建基于用户和信息类别的协同过滤推荐模型的具体步骤为:
步骤111:用户类别兴趣度表示和更新:每个用户阅读了很多水利门户信息,不同水利门户信息属于不同的类别,计算出用户对每种类别的兴趣度,构建用户-类别兴趣度矩阵muwc,用户的类别兴趣度计算方式包括初始表示和更新两种。具体过程如下:
(1)用户兴趣初始表示
本发明以天为单位计算用户对水利门户信息类别兴趣度。对用户首次行为当天的浏览记录分析,用户对每种类别的初始兴趣计算方法如下:
其中,pi表示用户对水利门户信息的i兴趣度,都设置为1。ωij表示水利门户信息i是否属于类别j,如果属于则ωij为1,反之,则为0。s表示用户阅读的总的水利门户信息的篇数。最终生成用户对所有类别的单日兴趣度向量cday,公式如下:
其中,ci表示类别i,
(2)用户兴趣更新
用户的兴趣并非一成不变,随着时间的推移,用户的对某一事物的兴趣如果得不到加强,会呈现出衰减趋势。根据艾宾浩斯遗忘曲线研究表明,用户遗忘的过程并非均匀变化,会经历一个先快后慢最后趋于稳定的过程。很多学者利用这一规律,推导出了能够描述这一变化的公式。用户的兴趣的衰减过程类似于用户对事物的遗忘过程,因此利用如下公式所示的遗忘曲线模拟公式来表示用户兴趣衰减的过程。
其中,f(t)表示用户的兴趣衰减函数,tnow为当前日期,tupdate为兴趣值最近一次更新的日期。ω为系统预置参数,决定着用户兴趣衰减的速率。
对用户的类别兴趣度进行更新,计算方法如下:
cnow=f(t)×cupdate+cday
其中,cnow表示用户当前的类别兴趣度向量,cupdate表示上一次更新后生成的用户类别兴趣度向量,cday表示本次行为当天行为产生的类别兴趣度向量,最终,实现对用户水利门户信息类别兴趣度的更新。
步骤112:用户相似度计算:根据用户-类别兴趣度矩阵计算用户兴趣是否相似,选择余弦相似度完成这一功能。假设用户a对水利门户信息类别的兴趣度为xa={xa1,xa2,...xak},用户b对水利门户信息类别的兴趣度为xb={xb1,xb2,...xbk},则用户a和用户b的余弦相似度如下:
步骤113:用户兴趣度计算:根据用户相似度,选出u个喜好最接近的用户,提取出这u个用户阅读过的所有信息,过滤用户已经观看过的部分,计算用户对这些信息的兴趣度,生成基于用户和信息类别的协同过滤推荐列表合集。
水利门户信息存在着时效性特点,因此在进行推荐时,需要对用户对水利门户信息的兴趣度进行时间上的降权处理,时效性如下:
其中,tnow表示当前时间,tpublish表示水利门户信息发布时间。
最终,用户兴趣度计算方式如下:
i(a,b,n)=simab×μan×k(t)
其中,a是目标用户,b是相似用户,n是用户b看过的水利门户信息,i(a,,b,n)是用户a对相似用户b看过的水利门户信息n的最终兴趣程度,simab表示用户a和用户b之间的相似度,μan表示用户a对水利门户信息n的初始兴趣度,μan设置为1,k(t)表示时效性。
步骤114:推荐列表生成:根据兴趣度进行排名,去除用户已经看过的水利门户信息,生成top-n推荐列表。
构建基于信息内容的推荐模型具体步骤为:
步骤115:用户兴趣模型构建:人们对水利门户信息的兴趣一般表现在对水利方面某些关键词或者其抽象主题的兴趣上,因此采用lda主题模型和向量空间模型对用户阅读过的水利门户信息进行特征表示,同时考虑用户兴趣衰减特点,实现用户兴趣模型的构建。具体过程如下:
(1)文本预处理
构建用户兴趣模型首先要对用户行为数据中的水利门户信息分词、去除停用词,生成表示用户行为的词语序列,此处采用jieba分词工具完成这一功能。
(2)主题兴趣向量初始表示与更新
利用主题模型挖掘水利门户信息隐含主题,得到用户阅读的第一次阅读的所有水利门户信息的主题权值,用如下矩阵表示:
其中,ts={(t1,ωs1),(t2,ωs2),...,(tk,ωsk)}表示用户当日阅读的每篇水利门户信息的主题特征向量,ωij表示用户阅读的第i篇文章的第j个主题的权重,k为主题的个数,s表示文章篇数。
计算用户对每个主题的兴趣度,用户的主题兴趣度计算如公式如下:
其中,pi表示用户对水利门户信息的i兴趣度,都设置为1。ωij表示用户阅读的水利门户信息i中主题j的权值。s表示用户阅读的总的水利门户信息的篇数,最终生成用户对所有主题的初始兴趣向量tday:
其中,ti表示主题,
用户主题兴趣向量更新原理与业务兴趣向量的更新原理类似,因此对用户兴趣向量进行更新,最终生成用户当前主题兴趣向量tu:
tu={(t1,ω1),(t2,ω2),…,(tk,ωk)}
(3)关键词兴趣向量初始表示与更新
利用向量空间模型挖掘用户关键词兴趣,使用tf-idf进行关键词权值计算,得到用户首次阅读的所有水利门户信息的主题权值,计算用户对每个关键词的兴趣度,关键词兴趣向量的初始表示与更新方式与主题类似,最终生成用户当前关键词兴趣向量ku:
ku={(k1,ω1),(k2,ω2),…,(kn,ωn)}
步骤116:水利门户信息模型构建:水利门户信息模型的表示方式应该用户兴趣模型的表示方式相关联,因此水利门户信息的模型构建也是从主题、关键词两方面着手。建立水利门户信息模型时,与用户兴趣模型建模类似,要对文本预处理,即对水利门户信息进行分词、去除停用词,将水利门户信息生成能表征文本语义的词语序列。对生成的词语序列进行lda主题模型训练以及关键词提取,得到水利门户信息的主题特征向量tn以及水利门户信息关键词特征向量kn,其中k表示主题的个数,其中n表示关键词个数:
tn={(t1,ω1),(t2,ω2),...,(tk,ωk)}
kn={(k1,ω1),(k2,ω2),...,(kn,ωn)}
步骤117:用户兴趣度计算:分别计算用户主题兴趣向量tu与水利门户信息主题特征向量tn相似度sim(tu,tn)以及用户关键词兴趣向量ku与水利门户信息关键词特征向量kn相似度sim(ku,kn),该过程采用余弦相似度公式完成,判断用户兴趣模型与水利门户信息模型之间相似度如下:
sim(u,n)=α×sim(tu,tn)+β×sim(ku,kn)
其中,α和β用于调整两种相似度之间的比例,α+β=1;
计算用户对水利门户信息的兴趣度,这部分用户兴趣度的计算也需要考虑水利门户信息时效性,用户兴趣度计算如公式如下:
i(u,n)=sim(u,n)×μun×k(t)
其中,u是目标用户,n是待推荐水利门户信息集中的水利门户信息,i(u,n)是用户u对水利门户信息n的最终兴趣程度,sim(u,n)表示用户和用户之间的相似度,μun表示用户u对水利门户信息n的初始兴趣度,μun设置为1,k(t)表示时效性。
步骤118:推荐列表生成:根据兴趣度进行排名,去除用户已经看过的水利门户信息,生成top-n推荐列表。
步骤119:混合推荐模型构建:本发明采用混合推荐方式为用户推荐水利门户信息,如图2所示,为混合推荐流程图具体步骤为:
(1)将基于用户和信息类别的协同过滤推荐、基于信息内容的推荐以及基于时空敏感的热点信息推荐三种推荐方式混合,设置初始推荐比例为α:β:γ=1:1:1;
(2)当用户对推荐的信息产生点击行为,根据用户对每种方式点击的个数调整推荐信息权值比例,
(3)去除重复项,生成混合推荐列表。
步骤120:最终推荐列表生成:考虑到用户访问门户时信息推荐的冷启动问题,对新用户和老用户分别采用不同模型进行推荐,如果是网站新用户,因为没有用户的历史行为数据,将基于时空敏感的热点信息推荐生成的推荐列表推荐给用户;如果是网站老用户,将混合推荐方式生成的推荐列表推荐给用户。
实施例
下面结合水利门户网站信息推荐原型系统的实施来介绍具体的推荐实施过程。
(1)数据准备
(1)水利门户信息分类数据集的获取
通过网络爬虫从珠江委门户网站、水旱灾害防御、水土保持、水资源管理、全国节约用水办公室、中国水文、水利部农村水利水电司、中华人民共和国水利部建设与管理司、水库移民与水利扶贫、山东省水利移民管理局、城市水资源环境网的官方门户网站上获取各种水利门户信息,总共3000条信息,按照十个信息类别对数据进行手动标记。将每个类别数据按照2:1比例划分为训练集和测试集。
(2)用户行为数据以及水利门户信息推荐数据获取
采用调查的方式获取该部分数据,按照3:7的比例随机选取30名普通用户和70名与水利行业相关的用户,让用户2018年7月份不定期浏览中华人民共和国水利部、珠江水利委员会、长江水利委员会、黄河水利委员会的官方网站,记录下这一个月中的浏览行为,包括自己感兴趣的水利门户信息的标题、水利门户信息来源以及自己的浏览日期,最终得到100名用户一个月的浏览记录,包括用户编号、信息标题、信息来源、浏览日期。
对收集到的数据进行整理、筛选和格式统一,生成用户行为数据以及水利门户信息推荐数据,用户行为数据包括用户编号、信息编号、信息标题、信息内容、发布日期、阅读日期,水利门户信息推荐数据包括信息编号、信息标题、信息内容、发布日期。将一个月总的浏览行为少于30篇的用户去除,最终整理得到了86个人对于698条水利门户信息的4234条行为数据,将每个用户的后15篇浏览记录提取出来作为测试集,剩下的作为训练集。
(2)实验结果及分析
(1)分类模型参数确定
对分类算法实验参数进行了实验测定,确定分类效果最好的情况下特征维数m。
实验中,选择python的jieba分词工具对文本进行分词,去除停用词,使用chi进行特征词提取,最后使用knn算法作为文本分类算法,其中knn中的k=10。
图3显示了在不同特征维数下的f1-score的变化。从图中可以看出,在特征维数m=400时,分类效果趋于稳定,且在m=600时,分类效果最佳。
以水灾害为例,为排在前10位的特征词,分别为:防汛、防洪、洪水、洪灾、台
风、灾情、防治、防汛抗旱、防御、抗旱。
(2)主题k的数量
实验中,在基于信息内容的推荐中,使用python做主题模型和tf-idf权值计算,用户的兴趣衰减函数的参数ω=0.05,即半衰期为两周,用户的兴趣度两周之后衰减为原来的一半。水利门户信息时效性公式的参数λ=0.2,即半衰期为四天,水利门户信息两天之后时效性衰减为原来的一半。lda模型训练中,先验参数α=50/k,β=0.01。本次实验中关键字的权重和主题的权重按照1:1的比例设置。
图4展示了推荐篇数在n=12,24的情况下,主题数目k=10,20,30,40,50的情况下推荐的f1-score。其中,横轴为主题的个数k,纵轴为f1-score。从图中可以看出,随着主题数目的不断增多,推荐性能先增后减,且两种情况下都是主题值设为k=40的情况下,推荐的性能最好。
(3)相似用户数u
基于用户和信息类别的协同过滤推荐首先要对相似用户数u进行确定。相似用户过多会导致实验效果下降,相似用户数过少会导致实验结果过于个人化,设置时效性参数为λ=0.2。
表1f1-score值随相似用户的增长变化情况表
表1显示了推荐篇数在n=12,24的情况下,u=5,10,15,20情况下的f1-score值。从表中可以看出,两种情况下随着相似用户数的增多,推荐性能先增后减在u=10的情况下推荐效果最好。
(4)top-n推荐结果及分析
将所提的水利门户信息混合推荐模型(hra)与基于用户和信息类别的协同过滤推荐模型(uccf)基于信息内容的推荐模型(cb)、基于时空敏感的热点信息推荐模型(tsb)以及使用传统user-cf方法计算用户相似度的混合推荐模型(hra-n)进行了实验对比。
图5、图6、图7分别是推荐篇数分别为n=6,12,18,24,30,36的情况下的四种推荐方法的准确率(precision)、召回率(recall)和f1-score。从图5可以看出,随着推荐篇数的增多,五种方法的准确率不断下降。从图6可以看出,随着推荐篇数的增多,五种方法的召回率不断上升。从图7可以看出,随着推荐篇数的增多,五种方法的f1-score先上升后下降,在推荐篇数为24的情况下,整体推荐性能最好。本文所提的混合推荐(hra)f1-score最高达到了26.5%,相对于单一模式下的uccf提升了3.9%,tsb提升了2.7%,cb提升了2.1%,相对于hra-n提升了0.7%,证明了本文方法的有效性。
从图中可以看出,对于单一的推荐方法,本发明所提的水利门户信息混合推荐方法在推荐准确率、召回率以及f1-score上有所提升;本发明所提的能更好地适应不同时间和空间的业务变化,提高用户对当前可能发生的与水利相关的突发状况的认识和防范意识,如洪水、台风、抗旱等;本发明所提的混合推荐方法在考虑新老用户不同特征的情况下,有效解决冷启动问题以及数据稀疏性问题;最终实现推荐技术在水利门户网站的创新型应用,提高用户使用水利门户网站的满意度。
(5)水利门户信息推荐系统实施
本发明在所提的水利门户信息混合推荐方法的基础上设计并实现了一个水利门户信息推荐系统,该系统主要是为水利门户网站提供推荐服务。系统与水利门户网站共享部分用户行为数据和水利门户信息数据,系统利用java程序调用python脚本文件实现水利门户信息分类和推荐,增加了爬虫模块,扩充为用户推荐的信息库,通过java调用webservice接口接收水利门户网站传递的参数并将推荐结果返回。系统根据需求分为五大功能模块:抓取信息管理模块、门户信息管理模块、用户信息管理模块、模型管理模块、推荐服务模块。
抓取信息管理模块实现对其他水利门户网站数据的抓取,将抓取的水利门户信息存入系统数据库中,增加推荐的信息库。通过这一模块,在使用基于内容的推荐为用户推荐信息时,除了可以推荐本系统服务的水利门户网站的信息,还可以把从其他网站爬取的与用户兴趣相似的水利门户信息推荐给用户,该模块有效实现抓取频率修改、抓取网站修改、抓取信息查看、抓取信息删除、抓取信息类别修改、抓取信息分类查看;
门户信息管理模块是对本系统服务网站的水利门户信息的管理,通过该模块可以实现门户信息查看、门户信息分类查看、门户信息类别修改;
用户管理模块是对从门户网站上获取用户行为信息的管理,该模块有效实现浏览记录查看、推荐信息查看;
模型管理模块是对本系统实现分类和推荐操作的python脚本文件的管理,通过该模块,通过该模块可实现分类模型管理、推荐模型管理、推荐方式修改,推荐方式为实验中的推荐方式;
推荐服务模块主要实现与服务的水利门户网站的交互,该模块通过java调用webservice接口,本系统生成的推荐列表提供给水利门户网站。当水利门户网站用户登录水利门户网站之后,会传递一个string类型的用户id请求参数,本系统接收用户id参数并根据该id在本系统的数据库中查询,如果是该id系统数据库中没有,则将最热门业务的水利门户信息以xml串的方式返回给水利门户网站,如果该id系统数据库中有,将根据该用户历史行为生成的推荐结果以xml串的方式返回给水利门户网站。门户网站对传来的xml数据解析,推荐信息将以弹窗的形式展示在水利门户网站右下方。
- 还没有人留言评论。精彩留言会获得点赞!