一种基于深度学习的端到端车牌识别系统及其方法与流程
本发明涉及一种车牌识别系统,具体的说是一种端到端车牌识别系统及其方法,属于图像识别技术领域。
背景技术:
车牌识别lpr(licenseplaterecognition)在许多实际应用中发挥着重要作用,如自动收费,交通执法,停车场访问控制和道路交通监控等。它具有从安全性到交通控制的各种潜在应用,近年来,车牌识别技术受到了广泛的关注和研究。
商业化方案中,几个老牌的车牌识别公司都具有较好的商业化版本,应用也较为广泛,包括北京文通科技,北京易泊时代等,文通的技术源于清华的技术团队,研究早,商业化也比较完善,在车牌识别方案上应用广泛。成都的火眼臻视公司,做停车场卡口车牌识别,包括卡口相机,配套软件等,在停车场具有较高的市场占有率。北京精英智通科技主要针对智能泊车收费,其中车牌识别方案也具有较好的识别。目前市场上的车牌识别产品,大多采用检测,分割和识别联合的方案,这种方案依赖于分割的效果,对于图像模糊粘连处理有一定难度。
虽然车牌识别技术已得到很大发展,但是仍然存在难点。这些难点集中体现在以下几个方面:(1)由于光照、大雾、沙尘暴等天气影响,导致采集到的图像质较低,字符受到噪声干扰,造成部分目标图像被背景图像掩盖,降低车牌字符识别的准确率。(2)我国车牌的特殊性。(a)我国车牌的字符包括中文、数字和英文字母。由于中文字符的笔画较为复杂,在对中文字符进行二值化处理后,容易造成笔画模糊,从而导致错误的识别。同时在对车牌字符识别时,需要对英文字母和数字进行混合识别,受部分英文字母和数字字符相似的影响,会造成英文字母和数字的误识。(b)我国车牌识别颜色的多样性,比如蓝色白底、黄底黑字、黑底白字等,在利用车牌颜色的特征时需要考虑多种情况,增加了额外的工作量。
因此本发明利用改进的多尺度检测模块提升检测速度和精度,再利用双向门控循环单元与基于神经网络的时序类分类算法优化识别网络,加快网络的收敛速度,提升模型识别准确率。
技术实现要素:
本发明的目的是提供一种基于深度学习的端到端车牌识别系统及其方法,以改进yolov3为检测网络,bgru+ctc为识别网络构建整体的识别系统模型,通过检测网络获取目标车牌的anchorbox,将该anchorbox的相关坐标参数,及目标区域的内容以矩阵的形式传至识别网络,利用已经训练好的识别模型对目标区域的车牌内容进行文本识别,最终输出车牌定位的准确率,anchorbox角点坐标,车牌识别准确率,系统识别时间等信息
本发明的目的是这样实现的:一种基于深度学习的端到端车牌识别系统,包括车牌定位模块,车牌识别模块;
所述的车牌定位模块,位于系统的数据入口,利用yolov3对原始含有车辆的图像进行初步的多尺度检测,获取目标车牌的anchorbox和相应的坐标参数,再将目标区域的内容以矩阵的形式传至识别网络;
所述的车牌识别模块,在对输入数据进行统一标准的格式化后,以检测网络返回的相关数据为基础,利用bgru+ctc的联合方案对获取的目标车牌中的文本信息进行识别,最终输出车牌定位的准确率,anchorbox角点坐标,车牌识别准确率,目标图像大小,系统识别时间等信息。
一种基于深度学习的端到端车牌识别方法,包括车牌定位和车牌识别两部分;
所述车牌定位包括以下步骤:
步骤1:利用爬虫技术从互联网,或部分开源数据集等中获取训练数据dataset;
步骤2:使用开源数据标注工具对原始训练数据进行人工标注,生成相应的数据标记文件;
步骤3:利用python脚本将数据标记文件生成相应的txt标签和list文件;
步骤4:扩展yolov3的多尺度检测功能,提升其对小物体的定位准确率,并修改其对应的cfg文件中的网络参数;
步骤5:调整yolov3相关的配置文件中的参数,初始化所有的数据路径,在cfg文件中开启网络的训练模式;
步骤6:随着迭代次数的增加,在网络接近收敛,各项参数基本稳定的时候停止训练,获取检测网络的模型权重;
步骤7:修改darknet.py文件,在其原本的基础上增加新功能,用以获取检测网络的参数计算量bflops和帧率fps等,并设置相应配置文件和模型权重的路径;
步骤8:获取车牌定位的准确率,检测速度,anchorbox角点坐标等,并将其传至识别网络;
所述车牌识别包括以下步骤:
步骤1:利用训练好的yolov3对原始训练集dataset进行检测,并将获取的目标车牌图像裁剪并保存至指定文件夹;
步骤2:对裁剪好的车牌图像数据集进行人工数据标注,生成数据集,按照9:1的比例分割新数据集,生成对应的训练集和验证集,并编写python脚本生成对应标签文件trainlabel.txt和vaidlabel.txt;
步骤3:以bgru+ctc的联合方案构建车牌识别模型;
步骤4:将数据进行预处理操作后,根据识别模型入口参数对数据进行格式化;
步骤5:调整模型训练的参数,修改模型存储路径,并设置批次间隔动态保存模型;
步骤6:待网络模型基本收敛时,停止训练,获取识别模型的权重文件;
步骤7:修改识别网络模型输入接口,与检测网络的输出接口进行匹配,进一步融合检测,识别两个模块;
步骤8:利用开源数据集open-its测试识别系统性能,输出车牌定位的准确率,anchorbox角点坐标,车牌识别准确率,目标图像大小,系统识别时间等信息。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明扩展了yolov3的多尺度检测功能,改进识别网络,利用bgru+ctc实现无需车牌字符分割的识别任务,其中,(1)本发明提出的模型可以在一次前向传播中完成车牌端到端的定位与识别任务,整个网络不需要依靠人工提取特征,全部可由深度神经网络自身进行学习,并进行精细化的自动提取操作,端到端的方式节约了车牌识别的时间,极大地提升了系统的识别效率;(2)模型联合车牌定位和识别功能,无需对车牌字符预先进行分割,再进行识别操作,简化了识别过程,提升了模型的识别效率;(3)本发明改进yolov3网络,并扩展多尺度检测的功能,细化定位精度,提升车牌定位效率;(4)本发明利用bgru+ctc改进识别网络完成对已定位车牌的无字符分割的识别任务,明显缩短训练时间,提升了网络的收敛速度和识别准确率。
附图说明
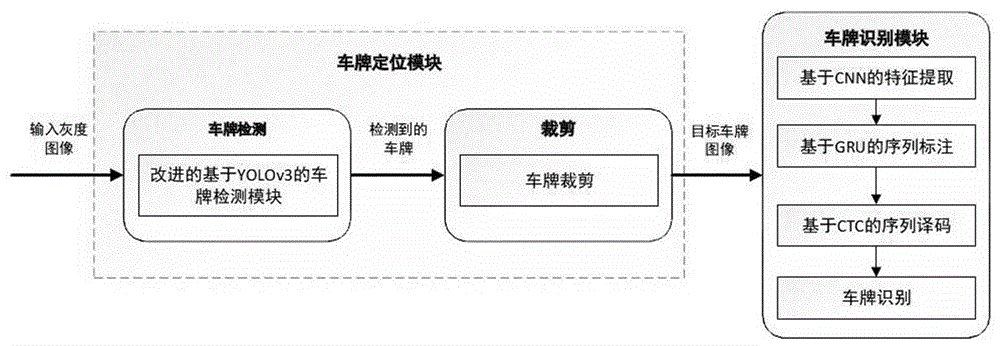
图1为本发明系统架构示意图。
图2为本发明中车牌定位模型图。
图3为本发明中车牌识别模型图。
图4为本发明中车牌识别模型参数图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
为了使本发明的目的,技术方案及优点更加清楚明白,便于本领域普通技术人员理解和实施本发明,以下结合附图1--系统架构示意图,附图2—车牌定位模型图,附图3-车牌识别模型图,和附图4-车牌识别模型参数图,通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
一种基于深度学习的端到端车牌识别系统及方法,所述车牌识别系统包括车牌定位模块100和车牌识别模块200;
车牌定位模块100包括以下步骤:
步骤101:在互联网上采取网络爬虫技术,利用python的scrapy框架以“车牌”为关键词进行大规模多线程的爬取,并对爬取的数据做清洗,整理和标注,另外在结合开源数据集ccpd,制作训练数据集dataset;
步骤102:使用开源数据标注工具labelimage对原始训练数据进行人工标注,生成相应的xml数据标记文件;
步骤3:利用python脚本对xml数据标记文件进行批量处理和转换,生成相应的txt标签和list文件,并根据8:1:1的比例制作对应的训练,验证和测试集;
步骤4:扩展yolov3的多尺度检测功能,将原有的三尺度检测扩展为四尺度检测,以增强网络的特征交互,提升目标检测的精度,并修改其对应的cfg配置文件中的网络参数,网络结构如附图2所示,在yolov3特征交互层处,添加卷积操作,生成104*104,75通道的featuremap,然后在此进行分类和位置回归;
步骤5:调整yolov3相关的配置文件,将cfg/voc.data中class设置为1,初始化train,valid,names,backup文件的相关路径,将cfg/voc.names中的类别设置为plate,cfg/yolov3-voc.cfg的配置如步骤四中所示,再定义cfg中相关参数的初始值,batch=64,subdivisions=16,width=416,height=416,channels=3,momentum=0.9,decay=0.0005,angle=0,saturation=1.5,exposure=1.5,hue=.1,learning_rate=0.001,burn_in=1000,max_batches=50200,policy=steps,steps=40000,45000,scales=.1,.1,最后,在cfg配置文件中开启网络的训练模式;
步骤6:随着迭代次数的增加,在网络模型接近收敛时,各项参数基本稳定,此时停止训练,获取检测网络的模型权重yolov3-voc.backup;
步骤7:修改darknet.py文件,在其原本的基础上增加新功能,用以获取检测网络的参数计算量bflops和帧率fps,平均ap值map,召回率recall等,并在net和meta位置处设置相应配置文件和模型权重的路径;
步骤8:运行yolov3检测网络,获取车牌定位的准确率,检测速度,anchorbox角点坐标等,并将其传至识别网络;
车牌识别模块200包括以下步骤:
步骤1:利用训练好的yolov3网络对原始训练集dataset进行检测,将获取的目标车牌图像裁剪并保存至指定文件夹;
步骤2:对裁剪好的车牌图像数据集进行人工数据标注,生成数据集,按照9:1的比例分割新数据集,生成对应的训练集,验证集,并编写python脚本生成对应标签文件trainlabel.txt和vaidlabel.txt;
步骤3:根据附图4中模型参数图,以bgru+ctc的联合方案构建车牌识别模型,主要的输入参数为检测模型中返回的anchorbox的角点坐标,和转化为矩阵形式的目标车牌区域的信息,整体识别模块的结构图如附图2所示,识别流程主要分为基于cnn的特征提取,基于bgru的序列标注,和基于ctc的序列译码三大部分;
步骤4:用滑动窗口的方式在整个图像中提取相应的特征。首先,对图像做一定的预处理,将每一个检测到的车牌转为灰度图像,然后将车牌的大小调整为164*48,其高度与cnn模型的输入高度相同,中文车牌是由7个字符组成,其中包含1位省份汉字简称和6位字母和数字的混合体,另外中国车牌共有31个省份,混合体中包含10个阿拉伯数字和24个英文字母(o和i不计算在内),故而全连接层共有65个类,而最终根据所需的位数,利用softmax层做分类。经过序列识别网络的处理,全连接层输出了18*66维(含1位空格符)的特征向量,候选车牌图像上的特征也被从左到右被依次提取,本发明中该特征图从左往右依次和7个字符信息网络层相对应,并利用dropout进行随机(rate=0.25)删除一些隐藏神经元,分类层输出的7位结果对应网络的识别结果;
步骤5:序列标注即对特征序列中的每一层特征都用gru递归处理,每一次都会用一个非线性的函数g(.)来更新状态ht,该函数还会同时将当前特征xt和邻接状态ht-1或ht+1作为输入;
随后是softmax层,其将gru的状态转换为7个类的概率分布;
整个特征序列被最终转换为概率估计序列p={p1,p2,…,pl},其长度与输入序列相等;
步骤6:序列译码即通过gru的输出序列找到具有最大概率的近似最优路径,将概率估计p的序列转换为字符串;
步骤7:将此前准备好的数据进行预处理操作后,根据识别模型入口参数对数据进行统一格式化;
步骤8:调整模型训练的参数,batch_size=128,img_size=(164,48),num_channels=3,label_len=7,samples_per_epoch=800,nb_epoch=25,修改模型存储路径,并设置在每一个nb_epoch结束时动态保存模型;
步骤9:在参数变化趋近于稳定,网络模型基本收敛时,停止训练,并保存识别模型的权重文件bgru_ctc_model.h5;
步骤10:修改整体系统识别网络模型输入接口,将其与检测网络的输出接口进行匹配,进一步融合检测,识别两个模块;
步骤11:利用开源数据集open-its测试识别系统性能,输出车牌定位的准确率,anchorbox角点坐标,车牌识别准确率,目标图像大小,系统识别时间等信息。
综上所述,本发明针对传统车牌识别系统检测速度慢,识别准确率低的问题,本发明提供了一种基于深度学习的端到端车牌识别系统及其方法,扩展多尺度检测功能,以改进yolov3的检测网络,加强对小物体的识别,提升定位准确率,以bgru+ctc为识别网络构建整体的识别系统模型,加快了网络训练的收敛速度,提升了识别准确率。
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!