一种基于词汇相似性的LDA主题模型最优主题数确定方法与流程
本发明属于自然语言处理技术领域,涉及一种自然语言处理模型,具体涉及一种基于词汇相似性的lda主题模型最优主题数确定方法。
背景技术:
随着互联网的高速发展,微博作为开放的用户交流和信息传播平台,越来越受到人们的欢迎。挖掘用户兴趣偏好,分析用户偏好行为特征,对舆情监控和网络安全管理以及商业价值推广,具有十分重要作用。但每个用户每天浏览成千上百条微博,海量微博信息增加了用户获取自身需要信息的难度,影响了用户体验。精准获取用户偏好是微博平台主动推送用户感兴趣内容的关键。
在文本聚类方面,主题方法比传统方法更有效,这也使得隐含狄利克雷分布(lda,latentdirichletallocation)在文本处理方面得到越来越多的应用。lda主题模型是数据挖掘和文本信息处理方面不可或缺的模型。该主题模型是一种文本建模方法,能够以概率分布的形式表达出文本中隐藏的主题信息。lda主题模型打破了传统文本表示的思维模式,提出“主题”的概念,用于在海量文本中抽取出重要信息。
基于lda主题模型进行主题挖掘,最优主题数目直接影响用户兴趣偏好刻画精度。目前普遍认为gibbs采样的lda主题模型的最大问题是无法确定最优主题数目,在大多数情况下,都是通过经验人为设定主题数目,主题数目对迭代过程和结果非常重要,过多或者过少都会对模型产生很大的影响,导致最终的文档分布存在精度误差。
技术实现要素:
为了解决上述技术问题,本发明提供了一种基于词汇相似性的lda主题模型最优主题数确定方法。
本发明所采用的技术方案是:1.一种基于词汇相似性的lda主题模型最优主题数确定方法,其特征在于,包括以下步骤:
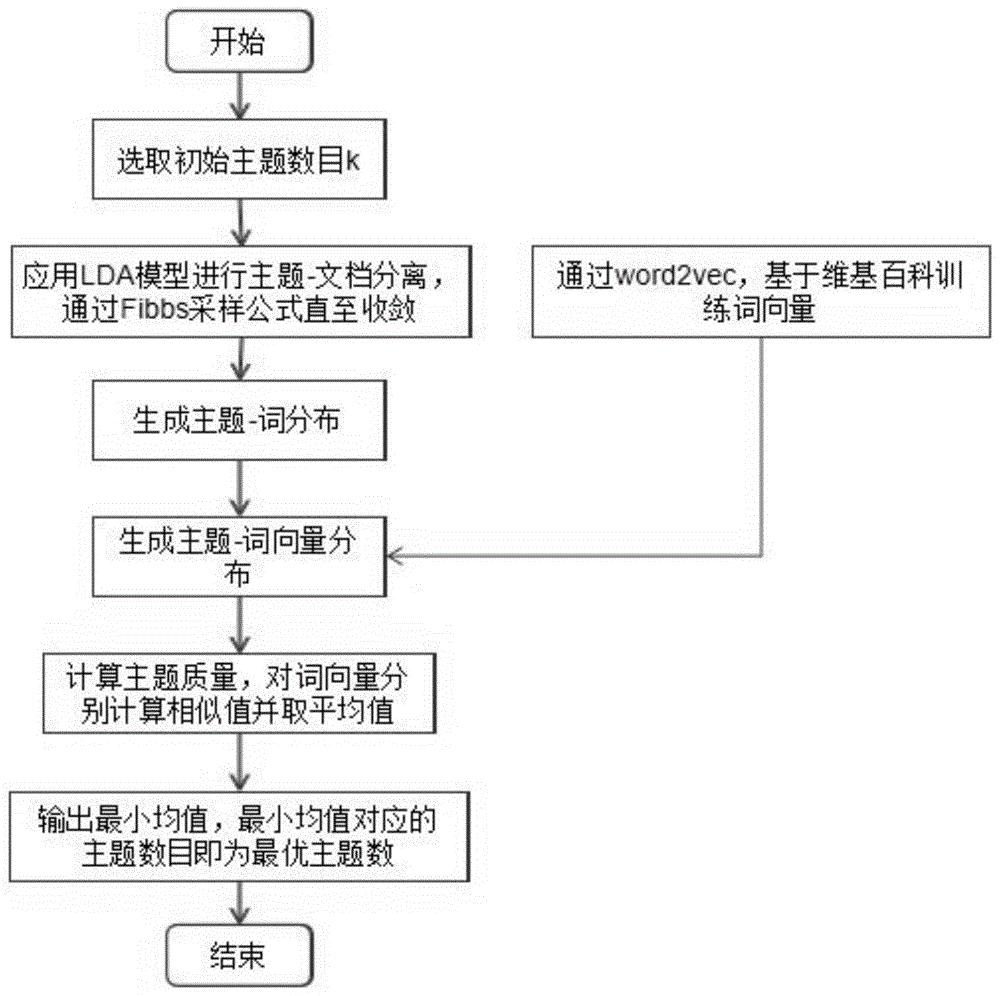
步骤1:选取初始k值,作为lda主题模型初始主题数目;
步骤2:进行文档主题分离,采样主题,直至收敛;
步骤3:生成主题-词分布,记为(t1,w11,w12,...,w1n)、(t2,w21,w22,...,w2n)、…、(tn,wn1,wn2,...,wnn);其中,t1、t2、…、tn为n个主题,wij为每个主题下的词分布;
步骤4:将主题-词分布转换为主题-词向量分布;
步骤5:计算主题质量,对每个主题下的词向量两两计算相似值,获取平均值;
步骤6:绘制
作为优选,步骤2中,根据gibbs采样公式采样主题。
作为优选,步骤4中,基于维基百科通过word2vec训练词向量,将主题-词分布转换为主题-词向量分布。
作为优选,步骤5中,对每个主题下的词向量两两计算相似值,计算方法是,选取主题t,通过向量相加平均法得到每个主题下的主题词相似度之和的平均值,其公式如下所示:
其中,nt为主题数,w为主题t下的主题词数目,e(wi,wj)为两词语间的相似度,相似度通过余弦值得到,即:
wi和wj分别为词语的向量表示;主题词i与主题词j计算相似度值,然后取得主题t下所有分布词的相似度之和,计算得到平均值。
作为优选,步骤6中所述绘制
本发明提供的lda主题数目确定方法,可以有效的避免根据经验人为设定主题数目的局限,提供最优的lda初始主题数目,从而有效地解决了主题个数的选择问题,得到更好的模型聚类效果。
附图说明
图1本发明实施例的流程图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
请见图1,本发明提供的一种基于词汇相似性的lda主题模型最优主题数确定方法,包括以下步骤:
步骤1:选取初始k值,作为lda主题模型初始主题数目;
步骤2:进行文档主题分离,采样主题,直至收敛;
本实施例中,首先对要分析的文本数据进行预处理,分词并去除停用词。然后应用lda模型,根据gibbs采样公式,采样至收敛,并生成主题-词分布。
步骤3:生成主题-词分布,记为(t1,w11,w12,...,w1n)、(t2,w21,w22,...,w2n)、…、(tn,wn1,wn2,...,wnn);其中,t1、t2、…、tn为n个主题,wij为每个主题下的词分布;
步骤4:将主题-词分布转换为主题-词向量分布;
本实施例中,为了获得词语的向量表示,可通过爬取维基百科等海量文本数据并基于word2vec训练词向量,然后将生成的主题-词分布转化为主题-词向量分布。
步骤5:计算主题质量,对每个主题下的词向量两两计算相似值,获取平均值;
本实施例中,对每个主题下对应的词向量分布相互计算相似值,通过向量相加平均法,得到每个主题下的主题词相似度之和的平均值,具体计算方法如下:
其中,nt为主题数,w为主题t下的主题词数目,e(wi,wj)为两词语间的相似度,相似度通过余弦值得到,即:
wi和wj分别为词语的向量表示。主题词i与主题词j计算相似度值,然后取得主题t下所有分布词的相似度之和,计算得到平均值。
步骤6:绘制
本实施例中,通过进一步的绘制
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!