一种基于大数据深度学习方法的低阻层精准预测方法与装置与流程
本发明涉及一种基于大数据深度学习方法的低阻层精准预测方法,特别涉及一种基于大数据深度学习方法的低阻层精准预测方法与装置。
背景技术:
目前油田开发进入中、后期阶段,表现为高含水、高采出程度和剩余油高度分散的“三高”特征。在复杂断块油藏,由于受沉积微相、构造、岩性、钻井以及上下层等多因素影响,单纯依靠测井曲线分析将会漏失大量潜力层,并且井口解释资料中多数小层解释描述结论不准确,对富含大量剩余油的低阻层精准识别与预测难度大。应用大数据和深度学习方法从海量数据中高效挖掘有价值的信息,是低阻层挖潜关键技术,能够在一定程度上降低开发成本,提高采收率。
以测井数据为切入点,融合多种结构化数据(如钻井、录井数据,测井曲线解释数据等)与非结构化数据(如研究成果资料,单井施工总结相关资料等)。针对数据融合表中大量参数数据,如何客观准确的挖掘出各参数之间潜在的关联关系对于低阻层精准预测非常重要。传统的研究主要是根据历史生产数据、勘探规划探明储量情况以及现有的资源状况,用经验法或基于统计分析原理确定产量、产能等生产指标与冲次、冲程等影响指标之间的关系及影响程度,虽然能够在一定程度上定性分析各参数影响程度,但传统方法完全忽略了各参数之间隐含的交互影响关系,不能充分挖掘出各参数之间潜在的关联关系。
结合各影响产量参数的权重值可以提高小层相似度计算分析结果的精度,提高低阻层挖潜的精度,所以分析影响产量参数以及这些参数对产量的影响程度对于低阻层精准预测非常重要。传统的研究方法大多基于地质统计学方法、经验法以及油藏工程方法进行测算,地质统计学分析方法精度受空间参数数据的密度和分布影响,并且受各参数之间的自相关和互相关结构影响严重,对于油田上评价开发效果的某些指标实际上对高含水开发阶段的效果并不显著,并且油田的开发评价指标尚未上升到定量化计算阶段。
小层数据的合理分类可以根据各小层数据具有的特征自动将相似特征小层识别为一类,减少后期对小层相似度计算的工作量,提高低阻层挖潜的精度与速度,所以根据小层测井数据对各小层进行合理的分类对于低阻层精准预测非常重要。传统的分类方式采用决策树、支持向量机等有监督分类方法,虽然分类效果良好,但是有监督分类方法需要大量带有标记的样本,而有标记样本的实地获取是一项消耗大量人力、物力和财力的事情,并且带标记样本因不同解释时间、不同井况信息存在一定解释误差,分类结果与现实情况存在明显误差;有些学者采用直推式支持向量机进行分类,通过少量的有标签样本训练出一个决策边界,利用无标签数据来调整边界,但是损失函数的非凸性会导致局部的最优。
针对相似油层低阻层挖掘与发现问题,传统的低阻层挖掘与发现缺乏有效的识别手段,主要通过大量的专家团队依靠统计资料对低阻层的电阻率等测井曲线、物性、含油性等进行识别,通过分析时差与电阻率关系图版或渗透率-孔隙度关系等图版,进行相似油层低阻层的挖掘与发现,耗费大量的人力、物力和精力,并且解释资料中多数小层的解释结论不准确,无法进行大量准确有效的相似小层挖掘。
针对以上问题,本发明所针对融合测井、录井与钻井等数据集中大量参数数据采用双重并行关联规则算法,挖掘潜在影响产油量等生产参数指标关系、挖掘变化参数与不变参数之间的相关性,从而描述一个小层或井口某些参数指标同时出现的规律和模式;对各参数进行相关性程度评定,针对不同相关性影响程度进行分类、建立回归权重模型,对各分类结果分别建模,将相关影响程度弱参数进行多元回归建模确定参数影响程度,将相关影响程度强参数进行岭回归建模确定参数影响程度,以此确立一套科学合理的老油田开发评价指标体系;对同一油组下小层测井数据采用t-sne算法进行降维,提高小层数据分类的速度与精度。对降维后的无标记测井数据采用基于局部密度快速聚类算法的相似油层识别方法,自动将具有相似油层、低阻层特征的小层数据识别为一类,不需要决策边界,减少了大量人工样本标签获取工作、人工分析工作,克服了解释数据中各小层解释结论描述不准确的问题。结合关联分析结果与回归分析各参数影响权重值计算小层数据相似度,分析典型低阻层数据特征,与每一类中部分相似小层进行验证,减少了大量的人力、物力工作,提高了相似小层挖掘的速度与精度,充分反映各小层的客观真实规律,实现低阻层的精准预测、更好的提高采收率。
总而言之,基于上述研究所存在的问题,本发明针对以测井数据为主、融合多种结构化与非结构化数据,提出了一种基于大数据深度学习方法的低阻层精准预测方法。本发明采用双重并行关联规则算法深度挖掘出潜在影响产油量等生产参数指标关系、变化参数与不变参数之间的相关性,对各参数进行相关性程度评定,针对不同相关性影响程度进行分类、建立回归权重模型,对各分类结果分别建模,采用t-sne算法将原始高维、复杂小层测井数据进行降维特征融合之后,采用基于局部密度快速聚类算法的相似油层识别方法对小层测井数据进行自动聚类,自动将具有相似油层、低阻层特征的小层数据识别为一类,针对识别出的包含典型井小层数据的类别做小层数据相似度计算分析,根据参数关联分析结果与回归分析参数权重值计算小层数据相似度,分析典型低阻层数据特征,与该类中部分相似小层进行验证,调整聚类参数以修正分类的准确性,基于相似小层计算结果与数据分析结果,建立小层数据画像,精准解释这一类相似小层具有的特征,便于实现低阻层的精准预测、更好的提高采收率。
技术实现要素:
为了解决现有技术问题,本发明提供了一种基于大数据深度学习方法的低阻层精准预测方法,本发明的基于大数据深度学习方法的低阻层精准预测方法,以测井数据为切入点,融合多种结构化数据(如钻井、录井数据,测井曲线解释数据,生产、监测数据,取心数据等)与非结构化数据(如研究成果资料,单井施工总结相关资料等)。建立基于大数据深度学习算法的低阻层的精准预测方法、基于典型小层的半监督低阻层相似性分析、基于多源异构数据融合的参数影响力分析。
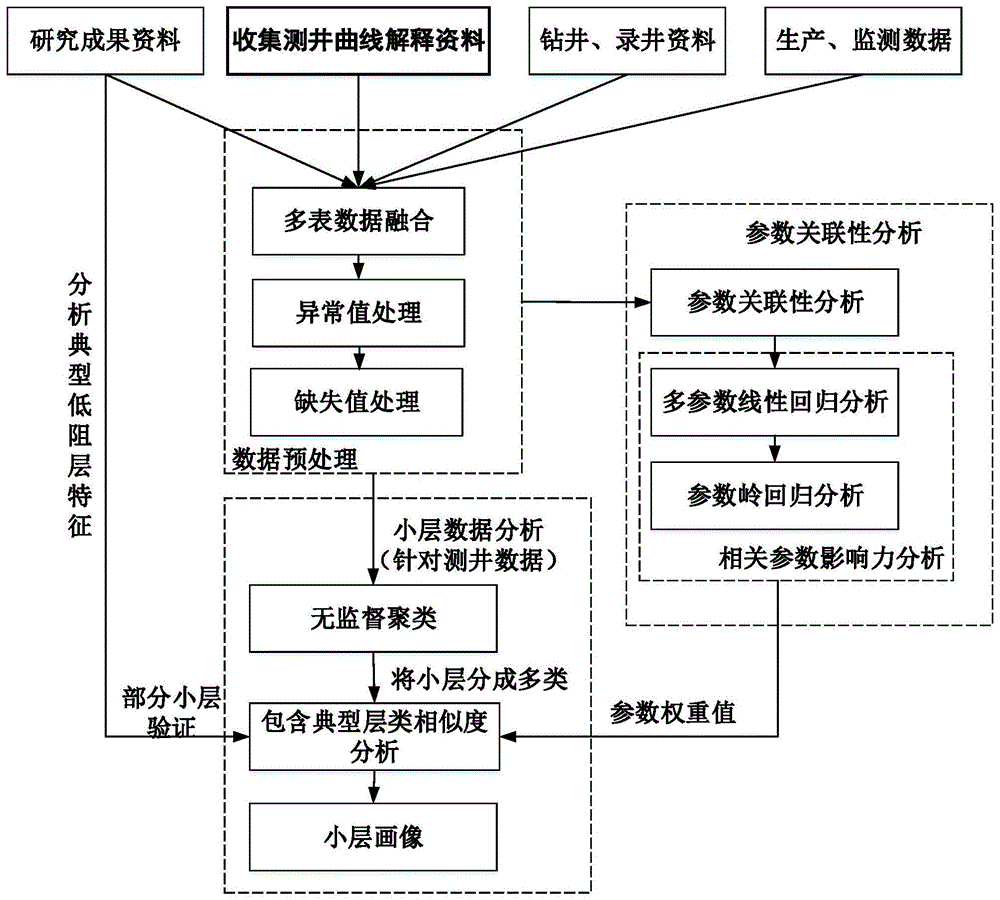
以测井数据为主,将所有测井、录井、钻井、生产、监测等数据进行多表数据融合,并对数据集进行数据预处理工作,填补缺失值与分析异常值;选取数据预处理后数据集中的月产油量等生产参数与泵径、冲程、冲次等影响参数进行关联性分析,挖掘潜在影响月产油量等生产参数指标关系;为定量分析各影响参数与生产参数之间的影响程度,对各参数进行相关性程度评定,针对不同相关性影响程度进行分类、建立回归权重模型,对各分类结果分别建模,建立基于多源异构数据融合的参数影响力分析模型;选取数据集中同一油组下,所有小层数据的测井数据进行基于局部密度快速聚类算法的相似油层识别方法,自动将具有相似油层、低阻层特征的小层数据识别为一类,有助于低阻层精准计算与预测,并针对识别出的包含典型井小层数据的类别做小层数据相似度计算分析,根据参数关联分析结果与回归分析参数权重值计算小层数据相似度,分析典型干层低阻层数据特征,与该类中部分相似小层进行验证。基于相似小层计算结果与数据分析结果,建立小层数据画像,精准解释这一类相似小层具有的特征,便于实现低阻层的精准预测、更好的提高采收率。
本发明所采用的技术方案如下:
一种基于大数据深度学习方法的低阻层精准预测方法,主要包括以下步骤:
a、融合月产油量、冲程、冲次、油压、套压等参数数据集进行深度关联关系挖潜,挖掘一个小层或井口某些生产参数指标同时出现的规律和模式。
b、为定量分析影响产量的参数对产油量的影响程度对小层潜力精准预测非常重要,需对各参数进行相关性程度评定,针对不同相关性影响程度进行分类、建立回归权重模型,确立一套科学合理的老油田开发评价指标体系。
c、选取同一油组下所有小层数据的测井数据(如自然电位、井径、自然伽马、补偿中子、补偿密度、补偿声波、浅中深电阻率等9条测井数据)进行基于局部密度快速聚类算法的相似油层识别方法,自动将具有相似油层、低阻层特征的小层数据识别为一类,包含多种特征的小层数据识别为多类,有助于低阻层精准计算与预测。
d、针对识别出的包含典型井小层数据的类别做小层数据相似度计算分析,将该类数据中典型井的油层、油水同层、含油水层、低产油层与该类中其他小层做相似度计算,
选取相似度计算数值最高小层作为相似小层;分析典型低阻层数据特征,与每一类中部分相似小层进行验证。
步骤a中,所述的深度关联关系挖潜是指:通过双重并行关联规则算法充分挖掘存在于大量参数指标数据集中的关联性以及变化参数与不变参数之间的相关性,从而描述一个小层或井口某些参数指标同时出现的规律和模式。
步骤b中,所述的回归权重模型是指:对各分类结果分别建模,将相关影响程度弱参数进行多元回归建模确定参数影响程度;将相关影响程度强参数进行岭回归建模确定参数影响程度,以此确立一套科学合理的老油田开发评价指标体系。
步骤c中,所述的多类数据是指:通过无监督快速聚类算法的相似油层识别方法将小层数据自动划分成差异性较大的几类数据集,此时多类数据可能属于同一相似典型小层,可能一类数据由多种典型小层数据构成。
步骤d中,所述的相似度计算是指:结合深度关联关系挖潜结果、回归权重模型计算结果与小层参数数据进行融合计算。
另一方面,本发明提供了一种基于大数据深度学习方法的低阻层精准预测装置,主要包括以下模块:
深度关联关系挖潜模块:融合月产油量、冲程、冲次、油压、套压等参数数据集进行深度关联关系挖潜,通过双重并行关联规则算法充分挖掘存在于大量参数指标数据集中的关联性以及变化参数与不变参数之间的相关性,从而描述一个小层或井口某些参数指标同时出现的规律和模式。
相关参数影响力分析模块:为定量分析影响产量的参数对产油量的影响程度对小层潜力精准预测非常重要,需对各参数进行相关性程度评定,针对不同相关性影响程度进行分类、建立回归权重模型,对各分类结果分别建模,将相关影响程度弱参数进行多元回归建模确定参数影响程度;将相关影响程度强参数进行岭回归建模确定参数影响程度,以此确立一套科学合理的老油田开发评价指标体系。
小层数据分析模块:选取同一油组下所有小层的测井数据(如自然电位、井径、自然伽马、补偿中子、补偿密度、补偿声波、浅中深电阻率等9条测井数据)进行基于局部密度快速聚类算法的相似油层识别方法,自动将具有相似油层、低阻层特征的小层数据识别为一类,包含多种特征的小层数据识别为多类,有助于低阻层精准计算与预测;针对识别出的包含典型井小层数据的类别做小层数据相似度计算分析,将该类数据中典型井的油层、油水同层、含油水层、低产油层与该类中其他小层做相似度计算,选取相似度计算数值最高小层作为相似小层;分析典型低阻层数据特征,与每一类中部分相似小层进行验证。
小层画像模块:列出典型层的所有相似小层、将相似小层的岩性描述、各参数数值以及相似小层数据分析结果展示出来,构成数据画像,精准解释这一类相似小层具有的特征,便于实现低阻层的精准预测、更好的提高采收率。
本发明提供的技术方案以及基于大数据深度学习方法的低阻层精准预测装置带来的有益效果是:
本发明的基于大数据深度学习方法的低阻层精准预测方法,以测井数据为切入点,融合多种结构化数据(如钻井、录井数据,测井曲线解释数据,生产、监测数据,取心数据等)与非结构化数据(如研究成果资料,单井施工总结相关资料等)。建立基于大数据深度学习算法的低阻层的精准预测方法、基于典型小层的半监督低阻层相似性分析、基于多源异构数据融合的参数影响力分析,实现低阻层的精准预测、降低成本、更好的提高采收率。
附图说明
为了更清楚的说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的一种基于大数据深度学习方法的低阻层精准预测算法执行流程图。
图2为本发明一实施例提供的基于大数据深度学习方法的低阻层精准预测装置的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
实施例一
本实施例的基础在于,由于目前油田开发剩余油高度分散、挖潜难度大,借助于当前已有的大数据分析算法和工具,充分发挥开发五十多年积累的海量数据,由模型驱动向数据驱动+模型驱动转换,在复杂断块油藏,应用大数据分析,探索出一套提高采收率的方法。应用大数据和深度学习方法从海量数据中高效挖掘有价值的信息,是低阻层挖潜关键技术,能够在一定程度上降低开发成本,提高采收率。因此,以测井数据为主,将所有测井、录井、钻井、生产、监测等数据进行多表数据融合,并对数据集进行数据预处理工作,填补缺失值与分析异常值。
选取数据预处理后数据集中的月产油量等生产参数与泵径、冲程、冲次等影响参数进行双重关联性分析,挖掘潜在影响月产油量等生产参数指标关系以及变化参数与不变参数之间的相关性;为分析影响产量的参数以及这些参数对产量的影响程度,需对各参数进行相关性程度评定,针对不同相关性影响程度进行分类、建立回归权重模型,对各分类结果分别建模,将相关影响程度弱参数进行多元回归建模确定参数影响程度;将相关影响程度强参数进行岭回归建模确定参数影响程度,以此确立一套科学合理的老油田开发评价指标体系,建立基于多源异构数据融合的参数影响力分析模型。
选取数据集中同一油组下,所有小层数据的测井数据进行基于局部密度快速聚类算法的相似油层识别方法,自动将具有相似油层、低阻层特征的小层数据识别为一类,包含多种特征的小层数据识别为多类,有助于低阻层精准计算与预测,针对识别出的包含典型井小层数据的类别做小层数据相似度计算分析,将该类数据中典型井的油层、油水同层、含油水层、低产油层与该类中其他小层做相似度计算,选取相似度计算数值最高小层作为相似小层;分析典型低阻层数据特征,与每一类中部分相似小层进行验证。
基于相似小层计算结果与数据分析结果,建立小层数据画像,精准解释这一类相似小层具有的特征,便于实现低阻层的精准预测、更好的提高采收率。
- 还没有人留言评论。精彩留言会获得点赞!