一种基于Winograd的可配置卷积阵列加速器结构的制作方法
本发明涉及一种可配置卷积阵列加速器结构。特别是涉及一种基于winograd的可配置卷积阵列加速器结构。
背景技术:
神经网络在诸多领域应用特别是图像相关任务上表现优异,诸如图像分类、图像语义分割、图像检索、物体检测等计算机视觉问题上,开始替代大部分传统算法,并逐步被部署到终端设备上。
但是神经网络计算量非常巨大,从而存在神经网络处理速度慢、运行功耗大等问题。神经网络主要包含训练阶段和推理阶段。为了得到高精度的处理结果,权重数据在训练中需要从海量数据中通过反复迭代计算得到。在神经网络推理阶段中,需要在极短的响应时间(通常为毫秒级)内完成对输入数据的运算处理,特别是当神经网络应用于实时系统时,例如自动驾驶领域。此外,神经网络中涉及的计算主要包括卷积运算、激活运算和池化运算等。
已有研究表明,神经网络超过90%的计算时间被卷积过程占据。传统的卷积算法通过多重乘法累加运算,分别计算输出特征图中的每个元素。虽然之前使用该算法的解决方案已经取得了初步的成功,但当算法本身效率更高时,效率可能更高。因此,目前研究者们提出了winograd的卷积算法,该算法通过对输入特征图与权重进行特定的数据域转换,完成等效的卷积运算任务并减少卷积运算过程的乘法次数。由于实际应用中大多数神经网络处理器芯片的预测过程是采用固定神经网络模型,因此所采用的winograd卷积输出范式通常也是固定模式,其运算过程十分明确,具有较大的优化空间。如何设计并优化基于winograd神经网络加速器结构成为了一个研究重点。
另外,对于绝大数神经网络应用,输入定点类型的数据便可达到良好的实验结果,更能提高速度,降低功耗。然而现有的定点化神经网络中的卷积数据位宽是固定的,不能灵活配置,降低了适用性。通常,16bit的数据位宽便可以满足神经网络的精度需求,而对于一些精度要求不高的网络和场景,8bit数据位宽也可满足精度需求。因此,在神经网络中,实现数据位宽可配置能够得到更好的优化。
技术实现要素:
本发明所要解决的技术问题是,提供一种能够提高神经网络卷积运算的计算效率的基于winograd的可配置卷积阵列加速器结构。
本发明所采用的技术方案是:一种基于winograd的可配置卷积阵列加速器结构,包括:激活值缓存模块、权重缓存模块、输出缓存模块、控制器、权重预处理模块、激活值预处理模块、权重转换模块、激活值矩阵转换模块、点乘模块、结果矩阵转换模块、累加模块、池化模块和激活模块,其中,
激活值缓存模块,用于存储输入像素值或输入特征图值,与控制器相连,为激活值预处理模块提供激活值数据;
权重缓存模块,用于存储已训练好的权值,与控制器相连,为权重预处理模块提供权重数据;
输出缓存模块,用于存储一次卷积层结果,与控制器相连,当激活模块输出数据完成后,将数据传入输出缓存模块,用于下一层卷积;
控制器,根据计算过程控制待处理的激活值数据、权重数据、和卷积层数据的传输;
权重预处理模块,接收权重缓存模块传输的待运算数据,用于划分卷积核,得到时域权重矩阵k;
激活值预处理模块,接收激活值缓存模块传输的待运算数据,用于从激活值缓存模块取出激活值,用于划分激活值,得到时域激活值矩阵i;
权重转换模块,接收权重预处理模块传输的待运算数据,用于实现权重数据从时域转换为winograd域,得到winograd域权重矩阵u;
激活值矩阵转换模块,接收激活值预处理模块传输的待运算数据,用于实现激活值从时域转换为winograd域,得到winograd域激活值矩阵v;
点乘模块,分别接收权重转换模块和激活值矩阵转换模块传输的待运算数据,用于实现winograd域激活值矩阵与winograd域权重矩阵的点积操作,得到winograd域点积结果矩阵m;
结果矩阵转换模块,接收点乘模块传输的待运算数据,用于实现点积结果矩阵从winograd域到时域的转换,得到转换后的时域点积结果矩阵f;
累加模块,接收结果矩阵转换模块传输的待运算数据,通过将接收的数据累加,得到最终的卷积结果;
池化模块,接收累加模块传输的待运算数据,将最终的卷积结果阵进行池化;
激活模块,接收池化模块传输的待运算数据,将池化结果进行relu激活函数处理,得到激活后的结果,传输到输出缓存模块。
所述的权重预处理模块包括:
(1)将一个大小为5*5的卷积核通过补零,扩展成6*6的卷积矩阵;
(2)将6*6的卷积矩阵划分为四个3*3的卷积核;
具体划分如下所示,其中kinput表示一个5*5的权重矩阵,下侧分别是4个对应的划分后的时域待处理权重矩阵k1、k2、k3、k4。在计算u=gkgt中,k值依次为k1、k2、k3、k4:
所述的激活值预处理模块是将6*6大小的激活值矩阵划分为重叠的4个4*4大小的矩阵。划分如下所示,其中iinput表示一个5*5的权重矩阵,下侧分别是划分后的大小为4*4的时域待处理激活值矩阵i1、i2、i3、i4。在计算v=btib中,i值依次为i1、i2、i3、i4:
所述的权重转换模块,是通过行列向量相加减完成计算中的矩阵乘,从而执行winograd卷积中针对权重矩阵的转换,得到winograd域权重矩阵u=[gkgt]其中,k表示时域权重矩阵、g是权重转换辅助矩阵、u是winograd域权重矩阵;
具体操作:将权重矩阵k的第一行向量作为临时矩阵c2的第一行,其中临时矩阵c2=gtk;将权重矩阵k中的整数右移补0、负数右移补1完成除二;当权值为正值时,权值右移,权值左边补0;当权值为负时,权值右移,权值左边补1;将权重矩阵k的第一、二、三行元素相加之后再右移一位之后的向量结果作为临时矩阵c2的第二行;将权重矩阵k的第一、二、三行元素相加之后再右移一位之后的向量结果作为临时矩阵c2的第三行;将权重矩阵k的第三行向量作为临时矩阵c2的第四行;将临时矩阵c2第一列向量作为winograd域权重矩阵u的第一列;将临时矩阵c2的第一、二、三列相加之后再右移一位之后的向量结果作为winograd域权重矩阵u的第二列;将临时矩阵c2的第一、二、三列相加之后再右移一位之后的向量结果作为winograd域权重矩阵u的第三列;将临时矩阵c2的第三列向量作为winograd域权重矩阵u的第四列,最后得到winograd域权重矩阵u。
所述的激活值矩阵转换模块,是通过行列向量相加减,完成计算中的矩阵乘,从而执行winograd卷积中针对时域激活值矩阵的转换操作,得到矩阵v=[btib]其中,i是时域激活值矩阵、b是激活值转换辅助矩阵、v是winograd域激活值矩阵;
具体操作:将时域激活值矩阵i的第一行减第三行的向量差值作为临时矩阵c1的第一行,其中临时矩阵c1=bti;将时域激活值矩阵i的第二行与第三行相加的结果作为临时矩阵c1的第二行;将时域激活值矩阵i的第三行减第二行的向量差值作为临时矩阵c1的第三行;将时域激活值矩阵i的第二行减第四行的向量差值作为临时矩阵c1的第四行;将临时矩阵c1的第一列减第三列的向量差值作为winograd域激活值矩阵v的第一列;将临时矩阵c1的第二列与第三列相加的结果作为winograd域激活值矩阵v的第二列;将临时矩阵c1的第三列减第二列的向量差值作为winograd域激活值矩阵v的第三列;将临时矩阵c1的第二列减第四列的向量差值作为winograd域激活值矩阵v的第四列,最后得到winograd域激活值矩阵v。
所述的点乘模块是通过执行winograd域权重矩阵u和winograd域激活值矩阵v的点积操作,获得winograd域点积结果矩阵m,公式表达为m=u⊙v,其中,u是winograd域权重矩阵,v是winograd域激活值矩阵;所述的点乘模块以实现数据位宽可配置的点积,有8位乘法器和16位乘法器两个工作模式,分别对应进行8bit和16bit两种数据位宽的运算,实现8*8bit和16*16bit的定点乘法运算。
所述的8位乘法器包括依次连接的第一选通单元、第一取反单元、第一移位单元、第一累加单元、第二选通单元、第二取反单元和第三选通单元,其中,
第一选通单元分别接收:权重转换模块和激活值矩阵转换模块的数据信息以及权重转换模块的符号控制信号;
第一取反单元接收第一选通单元的数据信息,对接收的数据进行取反;
第一移位单元接收第一取反单元的数据信息,以及接收第一选通单元的符号位信息,根据符号信息对接收的数据进行移位;
第一累加单元接收第一移位单元的数据信息,对接收的数据进行累加;
第二选通单元接收第一累加单元的数据信息和第一选通单元的符号位信息,并传送给第二取反单元;
第二取反单元接收第二选通单元的数据信息,对接收的数据进行取反;
第三选通单元分别接收第二取反单元和第一累加单元的数据信息,并输出。
所述的16位乘法器包括依次连接的第四选通单元、第三取反单元、8位乘法器、第二移位单元、第二累加单元、第五选通单元、第四取反单元和第六选通单元,其中,
第四选通单元分别接收:权重转换模块和激活值矩阵转换模块的数据信息以及权重转换模块的符号控制信号;
第三取反单元接收第四选通单元的数据信息,对接收的数据进行取反;
8位乘法器进行8bit数据位宽的运算,实现8*8bit的定点乘法运算;
第二移位单元接收8位乘法器的数据信息,对接收的数据进行移位;
第二累加单元接收第二移位单元的数据信息,对接收的数据进行累加;
第五选通单元接收第二累加单元的数据信息和第四选通单元的符号位信息,并传送给第四取反单元;
第四取反单元接收第五选通单元的数据信息,对接收的数据进行取反;
第六选通单元接收第四取反单元的数据信息,并输出。
所述的结果矩阵转换模块是通过winograd域点积结果矩阵m行列向量移位加减操作执行针对winograd域点积结果矩阵m的转换操作f=atma,其中,m是winograd域点积结果矩阵,a是winograd域点积结果矩阵m的换辅助矩阵,f是时域点积结果矩阵;
具体操作:将winograd域点积结果矩阵m的第一、二、三行相加的向量结果作为临时矩阵c3的第一行,其中临时矩阵c3=atm;将点winograd域点积结果矩阵m的第二、三、四行相加的向量结果作为临时矩阵c3的第二行;将临时矩阵c3的第一、二、三列相加的向量结果作为转换后的时域点积结果矩阵f的第一列;将临时矩阵c3的第二、三、四列相加的向量结果作为转换后的时域点积结果矩阵f的第二列,最后得到转换后的时域点积结果矩阵f。
本发明的一种基于winograd的可配置卷积阵列加速器结构,根据固定范式的winograd卷积算法的运算特点,设计了位宽可配置的卷积阵列加速器,灵活满足不同神经网络以及不同卷积层对位宽的需求。另外,还设计了专用的数据位宽可配置的乘法器单元,从而提高了神经网络卷积运算的计算效率,降低了计算功耗。
附图说明
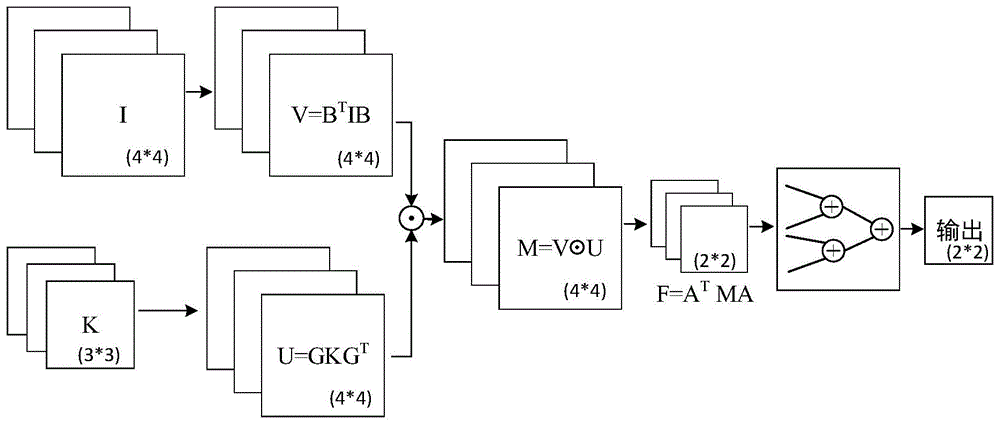
图1是winograd卷积阵列加速器总体架构图;
图2是本发明一种基于winograd的可配置卷积阵列加速器结构的构成示意图;
图3是数据位宽可配中8位乘法器的示意图;
图4是数据位宽可配中16位乘法器的示意图。
具体实施方式
下面结合实施例和附图对本发明的一种基于winograd的可配置卷积阵列加速器结构做出详细说明。
神经网络的卷积计算中,winograd转换公式为
out=at[(gkgt)⊙(btib)]a(1)
其中k表示时域权重矩阵,i表示时域激活值矩阵,a、g、b分别表示与点乘结果矩阵[(gkgt)⊙(btib)]、时域权重矩阵k、时域激活值矩阵i对应的转换矩阵,转换矩阵a、g、b具体如下所示:
本发明中所用到winograd卷积的输出范式为f(2*2,3*3),第一个参数2*2表示输出特征图的大小,第二个参数3*3表示卷积核的大小。
如图1所示,winograd卷积可以分为三个阶段执行。第一阶段,将从缓存中读取的权重矩阵g与时域激活值矩阵i从时域转为winograd域,具体操作为矩阵乘法运算,计算结果用u与v表示,其中u=gkgt,v=btib;第二阶段,将winograd域权重矩阵u与winograd域激活值矩阵v执行点积操作“⊙”,得到winograd域点积结果矩阵m=u⊙v;第三阶段将点积结果从winograd域转为时域。
如图2所示,本发明的一种基于winograd的可配置卷积阵列加速器结构,包括:激活值缓存模块1、权重缓存模块2、输出缓存模块3、控制器4、权重预处理模块5、激活值预处理模块6、权重转换模块7、激活值矩阵转换模块8、点乘模块9、结果矩阵转换模块10、累加模块11、池化模块12和激活模块13,其中,
1)激活值缓存模块1,用于存储输入像素值或输入特征图值,与控制器4相连,为激活值预处理模块6提供激活值数据;
2)权重缓存模块2,用于存储已训练好的权重,与控制器4相连,为权重预处理模块5提供权重数据;
3)输出缓存模块3,用于存储一次卷积层结果,与控制器4相连,当激活模块13输出数据完成后,将数据传入输出缓存模块3,用于下一层卷积;
4)控制器4,根据计算过程控制待处理的激活值数据、权重数据、和卷积层数据的传输;
5)权重预处理模块5,接收权重缓存模块2传输的待运算数据,用于划分卷积核,分别得到四个时域待处理权重矩阵k1、k2、k3、k4;
所述的权重预处理模块5包括:(1)将一个大小为5*5的卷积核通过补零,扩展成6*6的卷积矩阵;(2)将6*6的卷积矩阵划分为四个3*3的卷积核;这样就可以用3*3的winograd输出范式实现5*5的卷积,高效且不会增加功耗乘法次数。
具体划分如下所示,其中kinput表示一个大小为5*5的时域输入权重矩阵,右侧是时域输入权重矩阵扩展后的6*6时域权重矩阵划分后的四个处理结果,下面分别是4个对应的划分后的时域待处理权重矩阵k1、k2、k3、k4。在计算u=gkgt中,k值依次为k1、k2、k3、k4:
6)激活值预处理模块6,接收激活值缓存模块1传输的待运算数据,用于从激活值缓存模块1取出激活值,用于划分激活值,分别得到时域待处理激活值矩阵i1、i2、i3、i4。在计算v=btib中,i值依次为i1、i2、i3、i4:
所述的激活值预处理模块6实现激活值的读取并对其进行预处理。在winograd算法中,激活值需要与权重相对应,而其中有许多重复使用的数据,所以将其重叠划分。所述的激活值预处理模块6是将6*6大小的激活值矩阵划分为重叠的4个4*4大小的矩阵,分别对应所述的4个3*3的卷积核;划分如下所示,其中iinput表示一个大小为6*6的时域输入激活值矩阵,下方分别为划分后的大小为4*4的时域待处理激活值矩阵i1、i2、i3、i4。在计算v=btib中,i值依次为i1、i2、i3、i4:
7)权重转换模块7,接收权重预处理模块5传输的待运算数据,用于实现权重数据从时域转换为winograd域,得到winograd域权重矩阵u;
所述的权重转换模块7,是通过行列向量相加减完成计算中的矩阵乘,从而执行winograd卷积中针对权重矩阵的转换,得到winograd域权重矩阵u=[gkgt]其中,k表示时域权重矩阵、g是权重转换辅助矩阵、u是winograd域权重矩阵;
具体操作:将时域权重矩阵k的第一行向量作为临时矩阵c2的第一行,其中临时矩阵c2=gtk;因为权重矩阵中存在值1/2,所以只需要将时域权重矩阵k中的整数右移补0、负数右移补1完成除二;当权重为正值时,权重右移,权重左边补0;当权重为负时,权重右移,权重左边补1;将时域权重矩阵k的第一、二、三行元素相加之后再右移一位之后的向量结果作为临时矩阵c2的第二行;将时域权重矩阵k的第一、二、三行元素相加之后再右移一位之后的向量结果作为矩阵c2的第三行;将时域权重矩阵k的第三行向量作为临时矩阵c2的第四行;将临时矩阵c2的第一列向量作为winograd域权重矩阵u的第一列;将临时矩阵c2的第一、二、三列相加之后再右移一位之后的向量结果作为winograd域权重矩阵u的第二列;将临时矩阵c2的第一、二、三列相加之后再右移一位之后的向量结果作为winograd域权重矩阵u的第三列;将临时矩阵c2的第三列向量作为winograd域权重矩阵u的第四列,最后得到winograd域权重矩阵u。
8)激活值矩阵转换模块8,接收激活值预处理模块6传输的待运算数据,用于实现激活值从时域转换为winograd域,得到winograd域激活值矩阵v;
所述的激活值矩阵转换模块8,是通过行列向量相加减,完成计算中的矩阵乘,从而执行winograd卷积中针对时域激活值矩阵的转换操作,得到winograd域激活值矩阵v=[btib]其中,i是时域激活值矩阵、b是激活值转换辅助矩阵、v是winograd域激活值矩阵;
具体操作:将时域激活值矩阵i的第一行减第三行的向量差值作为临时矩阵c1的第一行,其中临时矩阵c1=bti;将时域激活值矩阵i的第二行与第三行相加的结果作为临时矩阵c1的第二行;将时域激活值矩阵i的第三行减第二行的向量差值作为临时矩阵c1的第三行;将时域激活值矩阵i的第二行减第四行的向量差值作为临时矩阵c1的第四行;将临时矩阵c1的第一列减第三列的向量差值作为winograd域激活值矩阵v的第一列;将临时矩阵c1的第二列与第三列相加的结果作为winograd域激活值矩阵v的第二列;将临时矩阵c1的第三列减第二列的向量差值作为winograd域激活值矩阵v的第三列;将临时矩阵c1的第二列减第四列的向量差值作为winograd域激活值矩阵v的第四列,最后得到winograd域激活值矩阵v。
9)点乘模块9,分别接收权重转换模块7和激活值矩阵转换模块8传输的待运算数据,用于实现winograd域激活值矩阵与winograd域权重矩阵的点积操作,得到winograd域点积结果矩阵m,也是卷积中最消耗计算时间和资源的模块;
所述的点乘模块9是通过执行winograd域权重矩阵u和winograd域激活值矩阵v的点积操作,获得winograd域点积结果矩阵m,公式表达为m=u⊙v,其中,u是winograd域权重矩阵,v是winograd域激活值矩阵;所述的点乘模块9以实现数据位宽可配置的点积,有8位乘法器和16位乘法器两个工作模式,分别对应进行8bit和16bit两种数据位宽的运算,实现8*8bit和16*16bit的定点乘法运算。其中,
(1)如图3所示,所述的8位乘法器包括依次连接的第一选通单元14、第一取反单元15、第一移位单元16、第一累加单元17、第二选通单元18、第二取反单元19和第三选通单元20,其中,
第一选通单元14分别接收:权重转换模块7和激活值矩阵转换模块8的数据信息以及权重转换模块7的符号控制信号;
第一取反单元15接收第一选通单元14的数据信息,对接收的数据进行取反;
第一移位单元16接收第一取反单元15的数据信息,以及接收第一选通单元14的符号位信息,根据符号信息对接收的数据进行移位;
第一累加单元17接收第一移位单元16的数据信息,对接收的数据进行累加;
第二选通单元18接收第一累加单元17的数据信息和第一选通单元14的符号位信息,并传送给第二取反单元19;
第二取反单元19接收第二选通单元18的数据信息,对接收的数据进行取反;
第三选通单元20分别接收第二取反单元19和第一累加单元17的数据信息,并输出。
8位乘法器具体操作:根据两个乘数的符号位,相异或得到结果的符号位,并且根据符号位判断正负,若为负数则提出符号位,将后七位数取反加1;若为正数,则后七位数保持不变。判断正负后的乘数a1分别判断乘数b1每个二进制位是否为1,若为1则对应中间值为乘数a1后七位左移相应的位置,若为0则对应中间值为8位的0。判断完乘数b1的后七位后,将所有中间值相加得到相乘的结果h2,然后根据结果符号位决定是否需要将其取反加1,若结果符号位1则将相乘的结果h2取反加1,若结果符号位为0则保持不变,得到相乘结果h3,最后在相乘结果h3的第八位取结果符号位,得到最终的结果。无符号8位乘则无需考虑符号位,将根据乘数b1的8位数据移位相加得到结果。
(2)如图4所示,所述的16位乘法器包括依次连接的第四选通单元21、第三取反单元22、8位乘法器23、第二移位单元24、第二累加单元25、第五选通单元26、第四取反单元27和第六选通单元28,其中,
第四选通单元21分别接收:权重转换模块7和激活值矩阵转换模块8的数据信息以及权重转换模块7的符号控制信号;
第三取反单元22接收第四选通单元21的数据信息,对接收的数据进行取反;
8位乘法器23进行8bit数据位宽的运算,实现8*8bit的定点乘法运算;
第二移位单元24接收8位乘法器23的数据信息,对接收的数据进行移位;
第二累加单元25接收第二移位单元24的数据信息,对接收的数据进行累加;
第五选通单元26接收第二累加单元25的数据信息和第四选通单元21的符号位信息,并传送给第四取反单元27;
第四取反单元27接收第五选通单元26的数据信息,对接收的数据进行取反;
第六选通单元28接收第四取反单元27的数据信息,并输出。
16位乘法器是通过4个8位乘法器装置实现得到的,其中所用8位乘法器的选通信号为0,即无符号乘法器。首先,根据两个16位乘数的符号位判断正负,若为正则保持不变,若为负则取反加1;其次将判断后的16位数分为高8位数与低8位数,然后对应相乘;之后将两个高8位数相乘的结果左移16位,分别将乘数d高8位乘数e低8位相乘的结果、乘数d低8位乘数e高8位相乘的结果相加之后左移8位,将移位后的结果加上乘数a低8位与乘数b低8位相乘得到相乘结果l;最后,根据结果符号位决定是否需要取反加1,若相乘结果l符号为1则将相乘的结果取反加1,若相乘结果l符号位为0则保持不变,最后在相乘结果l首位取符号位的值得到最后输出结果。
10)结果矩阵转换模块10,接收点乘模块9传输的待运算数据,用于实现点积结果矩阵从winograd域到时域的转换,得到转换后的时域点积结果矩阵f;
所述的结果矩阵转换模块10是通过winograd域点积结果矩阵m行列向量移位加减操作执行针对winograd域点积结果矩阵m的转换操作f=atma,其中,m是winograd域点积结果矩阵,a是winograd域点积结果矩阵m的转换辅助矩阵,f是时域点积结果矩阵;
具体操作:将winograd域点积结果矩阵m的第一、二、三行相加的向量结果作为临时矩阵c3的第一行,其中c3=atm;将winograd域点积结果矩阵m的第二、三、四行相加的向量结果作为临时矩阵c3的第二行;将临时矩阵c3的第一、二、三列相加的向量结果作为转换后的时域点积结果矩阵f的第一列;将临时矩阵c3的第二、三、四列相加的向量结果作为转换后的时域点积结果矩阵f的第二列,最后得到时域点积结果矩阵f。
11)累加模块11,接收结果矩阵转换模块10传输的待运算数据,通过将接收的数据累加,得到最终的卷积结果,一个2*2大小的结果矩阵;
12)池化模块12,接收累加模块11传输的待运算数据,将最终的卷积结果阵进行池化;可采用不同的池化方法,包括求最大值法、求平均值法、求最小值法,对输入的神经元进行池化操作。由于winograd卷积f(2*2,3*3)最后输出的结果矩阵为2*2大小,则可以直接进行2*2的池化操作,通过三次大小对比得到池化结果:第一次是结果矩阵第一行的两个数进行对比,第二次是第二行的两个数进行对比,第三次是将前两次对比的结果进行对比,得到该结果矩阵的最大池化结果。
13)激活模块13,接收池化模块12传输的待运算数据,将池化结果进行relu激活函数处理,得到激活后的结果,传输到输出缓存模块3。
- 还没有人留言评论。精彩留言会获得点赞!