一种基于改进DBSCAN的三支聚类方法及系统与流程
本发明涉及数据处理
技术领域:
,具体是一种基于改进dbscan的三支聚类方法及系统。
背景技术:
:聚类是将物理或抽象对象的集合分成由类似的对象组成的多个类的过程,即将对象分类到不同的类(或者簇)的过程,同一个类中的对象有很大的相似性,属于不同类的对象有很大的相异性。现有技术中,文献“zhuy.,tingk.m.,angelovam.(2018)adistancescalingmethodtoimprovedensity-basedclustering.in:phungd.,tsengv.,webbg.,hob.,ganjim.,rashidil.(eds)advancesinknowledgediscoveryanddatamining.pakdd2018.lecturenotesincomputerscience,vol10939.”公开了一种使用多维距离缩放算法来提高基于密度聚类性能的方法,简称为dscale。该方法是一种预处理技术,在原数据计算的距离上进行缩放得到新的距离。将新距离值应用于现有的基于密度的聚类算法,能检测到具有不同密度的所有聚类,提高聚类准确率。文献在经典的具有噪声的基于密度的聚类算法(density-basedspatialclusteringofapplicationswithnoise,dbscan)上进行实验,提出了dscale-dbscan算法,实验证明dscale-dbscan在大部分数据集上能提高聚类准确率。虽然,dscale-dbscan克服了传统dbscan的缺点,但该算法本质上属于硬聚类算法。硬聚类假设每个对象必须分配到一个确定的集群中,一个对象只能属于其中的一个类,类和类之间存在确定清晰的边界。但在许多实际应用中,不同类之间可能不一定具有清晰的边界,一个对象可能同时属于两个或者两个以上的类。尤其在信息不完整或者不准确的情况下,很难给出一个明确的硬聚类结果。如果强制把一些对象划分到一个类中,将带来更高的错误率和决策风险。所以,硬聚类算法dscale-dbscan难以充分地解释对象和类之间的关系。技术实现要素:本发明的目的在于提供一种基于改进dbscan的三支聚类方法及系统,以解决上述
背景技术:
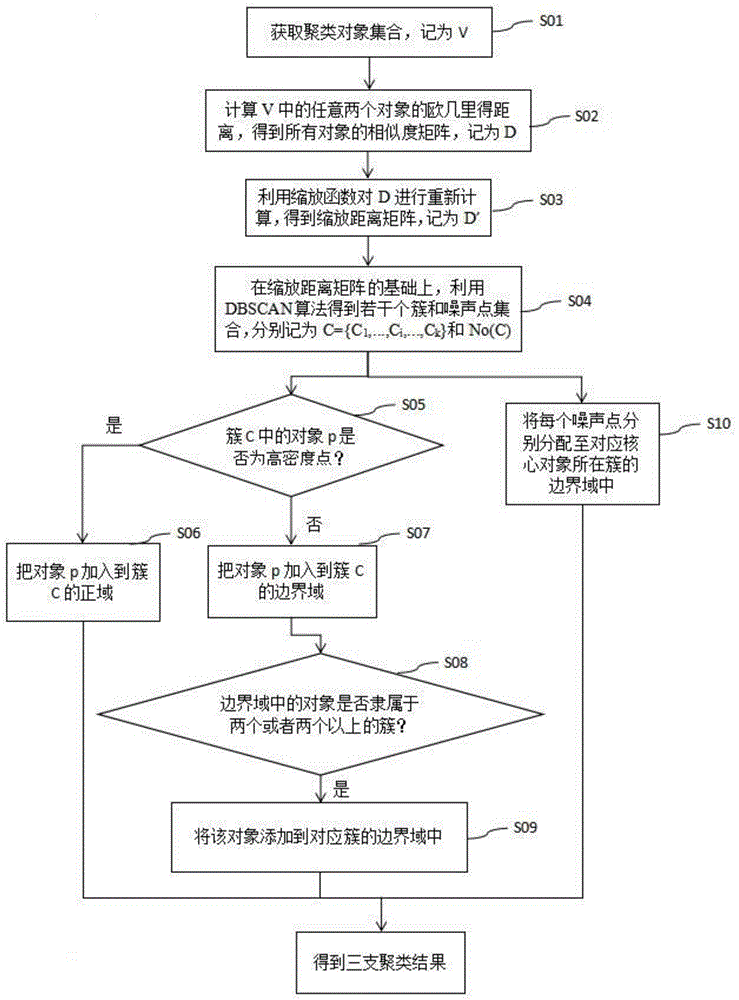
中提出的问题。为实现上述目的,本发明实施例提供如下技术方案:一种基于改进dbscan的三支聚类方法,包括以下步骤:获取聚类对象集合;计算聚类对象集合中的任意两个对象的欧几里得距离,得到所有对象的相似度矩阵;利用缩放函数对相似度矩阵进行重新计算,得到缩放距离矩阵;在缩放距离矩阵的基础上,利用dbscan算法得到若干个簇和噪声点集合;确定每个簇的正域和边界域,若簇中的对象是高密度点,则将该对象添加到正域中;若簇中的对象是低密度点,则将该对象添加到边界域中;判断每个簇的边界域中的对象是否隶属于两个或者两个以上的簇,若该边界域中的对象隶属于两个或者两个以上的簇,则将该对象添加到对应簇的边界域中;分别获取与每个噪声点的缩放距离最近的核心对象,并将每个噪声点分别分配至对应核心对象所在簇的边界域中。本发明实施例提供的一种优选方案,所述的步骤中,对于聚类对象集合中的任意对象x,其对应的缩放函数记为r(x),r(x)的计算公式如下:其中,tη(x)表示对象x的η邻域,η为邻域半径,n为聚类对象集合中的对象个数,h为每个对象的属性个数,dmax为相似度矩阵中最大的欧几里得距离。本发明实施例提供的另一种优选方案,所述的步骤中,利用缩放函数r(x)计算得到的缩放距离矩阵记为d′,d′=[d′(x,y)]n*n,d’(x,y)的计算公式如下:其中,m的值与dmax的值相等。本发明实施例提供的另一种优选方案,所述的步骤中,利用dbscan算法得到若干个簇和噪声点集合的方法包括以下步骤:(1)获取聚类对象集合中尚未检查过的对象,记为x,若x未被归为某个簇或者标记为噪声,则检查x的邻域,记为t∈(x);若|t∈(x)|≥minpts,即x为高密度点,建立新的簇,并将t∈(x)中的所有对象加入候选集中;若|t∈(x)|=1,即x为噪声点,则将x归入噪声点集合中;其中,t∈(x)={y∈v|d′(x,y)≤∈},v为聚类对象集合,∈为扫描半径,minpts为密度阈值;(2)获取候选集中所有尚未被处理的对象,记为y,并检查y的领域,记为t∈(y);若|t∈(y)|≥minpts,即y为高密度点,则将该t∈(y)中的所有对象加入候选集中,且若y未归入任何一个簇中,则将y归入上述新的簇中;若丨t∈(y)丨=1,即y为噪声点,则将y归入噪声点集合中;(3)重复步骤(2),直至候选集中的所有对象均被处理过为止;(4)重复步骤(1)~(3),直至聚类对象集合中的所有对象均被检查过为止,得到若干个簇和噪声点集合。本发明实施例提供的另一种优选方案,所述的步骤中,核心对象为所有簇的正域中的对象。本发明实施例还提供了一种基于改进dbscan的三支聚类系统,其包括:对象获取模块,用于获取聚类对象集合;距离计算模块,用于计算聚类对象集合中的任意两个对象的欧几里得距离,得到所有对象的相似度矩阵;缩放模块,用于利用缩放函数对相似度矩阵进行重新计算,得到缩放距离矩阵;初始聚类模块,用于在缩放距离矩阵的基础上,利用dbscan算法得到若干个簇和噪声点集合;划分模块,用于确定每个簇的正域和边界域,若簇中的对象是高密度点,则将该对象添加到正域中;若簇中的对象是低密度点,则将该对象添加到边界域中;判断模块,用于判断每个簇的边界域中的对象是否隶属于两个或者两个以上的簇,若该边界域中的对象隶属于两个或者两个以上的簇,则将该对象添加到对应簇的边界域中;分配模块,用于分别获取与每个噪声点的缩放距离最近的核心对象,并将每个噪声点分别分配至对应核心对象所在簇的边界域中。本发明实施例提供的另一种优选方案,所述的三支聚类系统中的初始聚类模块包括:第一处理单元,用于获取聚类对象集合中尚未检查过的对象,记为x,若x未被归为某个簇或者标记为噪声,则检查x的邻域,记为t∈(x);若|t∈(x)|≥minpts,即x为高密度点,建立新的簇,并将t∈(x)中的所有对象加入候选集中;若|t∈(x)|=1,即x为噪声点,则将x归入噪声点集合中;其中,t∈(x)={y∈v|d′(x,y)≤∈},v为聚类对象集合,∈为扫描半径,minpts为密度阈值;第二处理单元,用于获取候选集中所有尚未被处理的对象,记为y,并检查y的领域,记为t∈(y);若|t∈(y)|≥minpts,即y为高密度点,则将该t∈(y)中的所有对象加入候选集中,且若y未归入任何一个簇中,则将y归入上述新的簇中;若丨t∈(y)丨=1,即y为噪声点,则将y归入噪声点集合中。本发明实施例的提供的上述技术方案,相比于现有技术,具有以下技术效果:(1)对于一个有限非空的对象集合,本发明使用一种距离衡量公式得到相似矩阵,由于传统的dbscan方法在使用单一密度阈值的情况下,不能识别出密度不同的簇。为了克服dbscan的缺点,本发明使用dscale的距离缩放公式来改进相似度计算,得到缩放的相似矩阵,在该矩阵基础上使用dbscan算法得到初始的聚类结果。同时dbscan将所有的对象分成三种类型:高密度点、低密度点和噪声点。本发明结合对象的类型属性信息实施三支策略。首先对于一个类中包含的对象,如果对象是高密度点,那么把对象添加到该类的正域。如果对象是低密度点,那么把对象添加到该类的边界域。接下来本发明通过边界域中对象的邻域来判断重叠对象,从而扩展边界域。最后对于每一个噪声点,本发明找出与之距离最近的高密度对象,将噪声点添加到高密度对象所在类的边界域中。(2)本发明实施例提供的基于改进dbscan的三支聚类方法由于使用了三支聚类思想,不同于硬聚类中用单一的集合表示类,其能够更好地表达出对象和类之间的关系。每个类使用一对下限和上限的嵌套集合表示,上下限把对象分成了类的三个区域:正域、边界域和负域。正域中的对象确定属于该类,负域中的对象确定不属于该类,边界域中的对象则不确定,可能同时属于两个或者两个以上的类。所以,本发明实施例提供的三支聚类更加符合人类的认知模式,其得到的边界域是延迟决策的结果,在实际应用中可以降低聚类的错误率或者决策风险。另外,通过将本发明实施例提供的三支聚类方法分别与两个现有技术中最新的聚类方法进行比较,实验结果表明本发明实施例提供的三支聚类方法在大多数数据集上都能得到较好的聚类结果。附图说明图1为实施例1提供的一种基于改进dbscan的三支聚类方法的流程图。图2为实施例2提供的一种基于改进dbscan的三支聚类系统的结构示意图。具体实施方式下面的具体实施例是结合本说明书中提供的附图对本申请的技术方案作出的具体、清楚的描述。其中,说明书的附图只是为了用于将本申请的技术方案呈现得更加清楚明了,并不代表实际生产或使用中的形状或大小,以及也不能将附图的标记作为所涉及的权利要求的限制。实施例1参照附图1,该实施例提供了一种基于改进dbscan的三支聚类方法,其包括以下步骤:s01、获取聚类对象集合;具体的,获取需要聚类的对象,建立一个有限非空的n个聚类对象集合,记为v,其中,每个对象有h个属性。s02、计算聚类对象集合中的任意两个对象的欧几里得距离,得到所有对象的相似度矩阵;具体的,对于v中任意两个对象x和y,利用欧几里得距离公式得到x与y之间的欧几里得距离,记为d(x,y),d(x,y)的值代表了对象x和y的相似度,由此可以得到所有对象的相似度矩阵,记为d。其中,d=[d(x,y)]n*n,dmax为d中最大的欧几里得距离,dmax=maxx,y∈vd(x,y)。s03、利用缩放函数对相似度矩阵进行重新计算,得到缩放距离矩阵;具体的,对于聚类对象集合中的任意对象x,其对应的缩放函数记为r(x),r(x)的计算公式如下:其中,tη(x)表示对象x的η邻域,η为邻域半径,n为聚类对象集合中的对象个数,h为每个对象的属性个数,dmax为相似度矩阵中最大的欧几里得距离。利用上述缩放函数r(x)计算得到的缩放距离矩阵记为d′,d′=[d′(x,y)]n*n,d’(x,y)的计算公式如下:其中,m的值与dmax的值相等。s04、在缩放距离矩阵的基础上,利用dbscan算法得到若干个簇和噪声点集合;具体的,dbscan算法需要两个参数:扫描半径∈和密度阈值minpts。t∈(x)表示与x距离在∈之内的所有邻居集合,也称对象x的∈邻域,t∈(x)={y∈v|d′(x,y)≤∈}。|t∈(x)|表示集合中的元素个数,如果|t∈(x)|≥minpts,对象x是高密度点。如果1<|t∈(x)|<minpts,对象x是低密度点。如果|t∈(x)|=1,对象x是噪声点。另外,利用dbscan算法得到若干个簇和噪声点集合的方法具体包括以下步骤:(1)获取聚类对象集合中尚未检查过的对象,记为x,若x未被归为某个簇或者标记为噪声,则检查x的邻域,记为t∈(x);若|t∈(x)|≥minpts,即x为高密度点,建立新的簇,并将t∈(x)中的所有对象加入候选集n中;若|t∈(x)|=1,即x为噪声点,则将x归入噪声点集合no(c)中;其中,t∈(x)={y∈v|d′(x,y)≤∈},v为聚类对象集合,∈为扫描半径,minpts为密度阈值;(2)获取候选集n中所有尚未被处理的对象,记为y,并检查y的领域,记为t∈(y);若|t∈(y)|≥minpts,即y为高密度点,则将该t∈(y)中的所有对象加入候选集n中,且若y未归入任何一个簇中,则将y归入上述新的簇中;若丨t∈(y)丨=1,即y为噪声点,则将y归入噪声点集合no(c)中;(3)重复步骤(2),直至候选集中的所有对象均被处理过为止;(4)重复步骤(1)~(3),直至聚类对象集合中的所有对象均被检查过为止,得到若干个簇c={c1,...,ci,...,ck}和噪声点集合no(c),k值为利用dbscan算法得到的聚类的个数,即改进dbscan算法得到的初始聚类结果为c={c1,...ci,...,ck}∪no(c)。s05、确定每个簇的正域和边界域,若簇中的对象是高密度点,则将该对象添加到正域中;若簇中的对象是低密度点,则将该对象添加到边界域中;具体的,在三支聚类中簇ci表示为ci=[pos(ci),bnd(ci)]。其中,pos(ci)表示正域,bnd(ci)表示边界域。对改进dbscan算法中得到的簇ci中的所有对象p进行检查,如果对象p是高密度点,则进入步骤s06。如果对象p是低密度点,则把它添加到集合bnd(ci),并进入步骤s07。需要说明的是,是否为高密度点的判断方法与步骤s04的一样,在这边就不作赘述了。s06、将对象p加入簇c的正域pos(ci)中。s07、将对象p加入簇c的边界域bnd(ci)中,并进入步骤s08。s08、判断每个簇的边界域中的对象是否隶属于两个或者两个以上的簇,若该边界域中的对象隶属于两个或者两个以上的簇,则将该对象添加到对应簇的边界域中;具体的,检查边界域中的元素是否为重叠元素,即判断它是否有可能隶属于两个或者两个以上的簇,如果是,则进入步骤s09。其中,判断的公式如下:等式右边中bnd(ci)和bnd(cj)分别代表上个步骤s05中确定的边界域,ci表示改进dbscan算法中得到的簇ci,j∈[1,k]。s09、将重叠元素(即隶属于两个或者两个以上的簇的对象)添加到对应簇的边界域bnd(ci)中;s10、分别获取与每个噪声点的缩放距离最近的核心对象,并将每个噪声点分别分配至对应核心对象所在簇的边界域中;具体的,核心对象为所有簇的正域中的对象,记所有簇的正域中的对象集合为allpos,对于每个噪声点x,找到与其距离最近的核心对象y,再把x划分到y所在簇的边界域,其算法公式如下:y=argminy∈allposd′(x,y),x∈no(c)。利用上述实施例提供的三支聚类方法对3l、4c、iris、glass、pathbased和aggeragation六个数据集进行聚类处理实验。其中,3l和4c为合成数据集,iris和glass为uci数据集,pathbased和aggeragation为形状数据集,各个数据集的样本数和真实簇的个数如下表1。表1数据集样本数真实簇的个数3l56034c12504iris1503glass2146pathbased3003aggeragation7887在上述聚类处理实验过程中,采用3个有效性聚类指标评价聚类性能:准确度(accuracy,acc),f1分数和标准互信息(normalizedmutualinformation,nmi)。由于三支聚类中一个簇是由一对集合下限和上限来表示,在聚类性能评估时将所有簇的上限元素集合和下限元素集合分别当作两个不同聚类结果进行评估。此外,分别采用实施例1提供的三支聚类方法、现有技术中的ce3k-means聚类方法和dscale-dbscan聚类方法对上述各个数据集进行聚类处理,并进行比较,其比较结果如下表2。其中,由于ce3k-means属于三支聚类,dscal-dbscan属于硬聚类,因此将dscale-dbscan得到的聚类结果视为三支聚类中的上限元素集合。表2从上表2可以知道,本发明实施例提供的三支聚类方法在大多数的数据集上都能得到较好的聚类结果(acc、nmi和f1三者的值越大,说明聚类结果越好)。实施例2参照附图2,该实施例提供了一种用于实现上述实施例1提供的基于改进dbscan的三支聚类方法的系统,其包括:对象获取模块、距离计算模块、缩放模块、初始聚类模块、划分模块、判断模块和分配模块,初始聚类模块包括第一处理单元和第二处理单元。其中,对象获取模块,用于获取聚类对象集合。距离计算模块,用于计算聚类对象集合中的任意两个对象的欧几里得距离,得到所有对象的相似度矩阵。缩放模块,用于利用缩放函数对相似度矩阵进行重新计算,得到缩放距离矩阵;所述的缩放模块采用的缩放函数记为r(x),r(x)的计算公式如下:其中,x表示聚类对象集合中的对象,tη(x)表示对象x的η邻域,η为邻域半径,n为聚类对象集合中的对象个数,h为每个对象的属性个数,dmax为相似度矩阵中最大的欧几里得距离。所述的缩放模块利用缩放函数r(x)计算得到的缩放距离矩阵记为d′,d′=[d′(x,y)]n*n,d’(x,y)的计算公式如下:其中,m的值与dmax的值相等。初始聚类模块,用于在缩放距离矩阵的基础上,利用dbscan算法得到若干个簇和噪声点集合。第一处理单元,用于获取聚类对象集合中尚未检查过的对象,记为x,若x未被归为某个簇或者标记为噪声,则检查x的邻域,记为t∈(x);若|t∈(x)|≥minpts,即x为高密度点,建立新的簇,并将t∈(x)中的所有对象加入候选集中;若|t∈(x)|=1,即x为噪声点,则将x归入噪声点集合中;其中,t∈(x)={y∈v|d′(x,y)≤∈},v为聚类对象集合,∈为扫描半径,minpts为密度阈值;第二处理单元,用于获取候选集中所有尚未被处理的对象,记为y,并检查y的领域,记为t∈(y);若|t∈(y)|≥minpts,即y为高密度点,则将该t∈(y)中的所有对象加入候选集中,且若y未归入任何一个簇中,则将y归入上述新的簇中;若丨t∈(y)丨=1,即y为噪声点,则将y归入噪声点集合中。划分模块,用于确定每个簇的正域和边界域,若簇中的对象是高密度点,则将该对象添加到正域中;若簇中的对象是低密度点,则将该对象添加到边界域中。判断模块,用于判断每个簇的边界域中的对象是否隶属于两个或者两个以上的簇,若该边界域中的对象隶属于两个或者两个以上的簇,则将该对象添加到对应簇的边界域中。分配模块,用于分别获取与每个噪声点的缩放距离最近的核心对象,并将每个噪声点分别分配至对应核心对象所在簇的边界域中;所述的核心对象为所有簇的正域中的对象。需要说明的是,上述实施例只是针对本申请的技术方案和技术特征进行具体、清楚的描述。而对于本领域技术人员而言,属于现有技术或者公知常识的方案或特征,在上面实施例中就不作详细地描述了。当然,本申请的技术方案不只局限于上述的实施例,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,从而可以形成本领域技术人员可以理解的其他实施方式。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1