一种基于3D卷积神经网络的头部姿态估计方法与流程
本发明属于深度学习、模式识别领域,尤其涉及到基于深度卷积神经网络的头部姿态估计方法。
背景技术:
在计算机视觉的背景下,头部姿势估计最常被解释为推断人的头部相对于相机视图的方向的能力。更严格的是,头部姿势估计是推断头部相对于全局坐标系的方向的能力,但是这种细微差别需要知道固有的相机参数以消除来自透视畸变的感知偏差。一般成年男性的头部运动范围包括从-60.4°到69.6°的矢状屈曲和伸展(即从颈部向后运动),正面侧向弯曲(即颈部从右向左弯曲)-40.9°至36.3°,水平轴向旋转(从头部向左旋转)从-79.8°到75.3°[26]。肌肉旋转和相对取向的组合是经常被忽略的模糊性(例如,当相机从正面观看时与相机从正面和头部观看时相比,头部的轮廓视图看起来不完全相同转向侧面)。尽管存在这个问题,但通常假设人头部可以被建模为无实体的刚性物体。在这种假设下,人体头部的姿势受限于3个自由度(dof),其特征可以是俯仰角,滚动角和偏航角。
目前对驾驶行为的智能分析大多基于传统的图像处理手段,通过支持向量机来构建图像分类器。近些年来的相关研究表明,深度学习方法能够大大提高图像分类和预测的准确率。本发明基于3d深度神经网络,对分心驾驶行为做出预判,能够更好地规范驾驶行为,提高道路交通的安全性。
目前对头部姿态估计的智能计算大多使用基于模型的方法和基于外观的方法,其中使用最普遍的是基于外观的方法,对头部姿态图片进行特征提取,假定获取的人脸图像和真实图像存在某种特定关系,使用统计或者概率的方法训练关系模型来推断头部姿态。近些年的相关研究表明,使用深度学习方法对图片进行特征提取,并使用提取的特征对网络模型进行训练能大幅度提高图片分类和预测的准确率。本发明基于3d深度神经网络,对头部姿态进行预判,能让计算机准确的检测出人头部的姿态,实际应用可以极大的推进增强现实、人机交互、医疗康复、游戏娱乐等领域的发展。
技术实现要素:
本发明的目的在于提供一种基于3d卷积神经网络的头部姿态估计方方法。
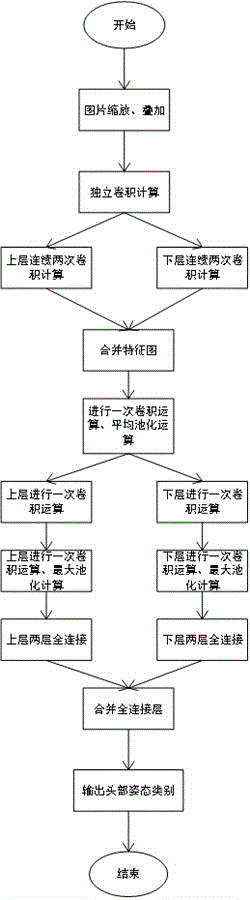
实现本发明目的的技术方案如下:对一个人的不同头部角度转动做叠加处理构建输入层。首先对图片立方体做卷积运算为网络的c1卷积层;然后通过两路不同的卷积核进行做卷积运算,连续重复两次,为网络的c2、c3卷积层;然后将c3输出的两类特征图做合并处理,再经过一次卷积运算,之后进行一次平均池化运算,为网络的c4卷积层;然后再通过两路不同的卷积核进行卷积运算,连续重复两次,第二次卷积进行完之后再进行一次最大池化运算,为网络的c5、c6卷积层;最后还是分两路的情况下对两类特征图分别经过全连接层f1,然后全连接层f2对两路全连接层进行合并,进行softmax计算,最后输出对应的头部姿态分类。
具体步骤如下:
步骤1:将头部姿态定义为9类。将图片强制缩放为150*120,然后将同一类头部姿态图片做叠加处理,将2d图片输入转为3d输入。
步骤2:使用步骤1获得的训练样本训练3d卷积神经网络
步骤2.1:输入立方体经过卷积计算,为c1卷积层;
步骤2.2:对步骤2.1输出的特征图立方体,通过两路不同的卷积核做卷积计算,连续重复两次,为网络的c2、c3卷积层。
步骤2.3:对步骤2.2输出的特征立方体图进行合并做卷积计算,在做平均池化计算。为网络的c4卷积层。
步骤2.4:对步骤2.3输出的特征立方体图形,通过两路不同的卷积核做卷积计算,连续两次,并在第二次卷积运算后进行最大池化运算,为网络的c5、c6卷积层。
步骤2.5:对步骤2.4输出的特征图立方体,通过两路相同的全连接层,为f1全连接层。
步骤2.6:对步骤2.5两路相同全连接层输出结果合并,为f2全连接层。
步骤2.7:对步骤2.6输出计算softmax、loss,并根据loss反向修正网络参数。重复步骤2.1-步骤2.7,直至loss收敛。
步骤3:将测试图片根据步骤1中的数据预处理方式进行叠加处理,构建3d立方体结构。利用步骤2得到的3d卷积神经网络测试分类结果。
上述步骤1中,将2d图片输入转化为3d立方体输入包括:首先数据集在采集使用平面内的头部转动角度,主要分为垂直角度和水平角度,垂直角度分为+90、+60、+30、+15、+0、-15、-30、-60、-90,水平角度分为+90、+60、+30、+15、+0、-15、-30、-60、-90,头部姿态主要9类,分别为中、上、下、左、右、左上、右上、左下、右下,每个人每一类有9张图像,数据输入时先将图片大小缩放为统一尺寸,然后将同一类的9张图片做叠加处理后输入3d网络。
上述步骤2.1中,c1层的卷积核尺寸为32@3*5*2。
上述步骤2.2使用的两路不同卷积核,c2层卷积核尺寸为64@5*7*1和64@3*8*1;c3层的卷积核尺寸为:128@5*6*2和128@7*5*2。
上述步骤2.3中,c4层的卷积核尺寸为256@6*10*3。
上述步骤2.4中,c5层的卷积核尺寸分别为512@5*11*2和512@11*11*2,c6层的卷积核尺寸分别为512@8*6*2和512@5*6*2。
上述步骤2.5使用的两路相同全连接,f1层全连接使用1*1*4096,f2层全连接使用1*1*2048。
本发明的有益效果:(1)深度学习结构方面:采用双路不同卷积尺寸的卷积核做特征提取,双路相同全连接层进行数据处理,提高网络泛化能力。
(2)模型适配应用方面:本发明采用图片叠加方式构建输入层,对输入数据为视频的情况同样适用,只需要从视频中选择需要的一段头部转动视频,并从视频中选择若干帧构建3d立方体数据即可。
(3)产品实施应用方面:应用在人机交互、虚拟现实领域,通过对使用者的头部姿态分析系统做出相应回应,实现实时交互。
附图说明
图1为本发明的流程图。
图2为本发明的3d卷积神经网络结构图。
具体实施方法
步骤1:将头部姿态定义为9类。将图片强制缩放为120*150,然后将每个人同一类的9张头部姿态图片做叠加处理,此时立方体尺寸为3@120*150*9,其中3为通道数,9表示9张图片叠加,120*150为空间维度的大小。
步骤2:使用步骤1获得的训练样本训练3d卷积神经网络
步骤2.1:c1为神经网络第一层,对输入立方体做卷积计算。卷积核尺寸32@3*5*2,2是时间维度大小,3*5是空间维度大小,共有32个卷积核,步长为(1,1,1)。卷积计算之后输出的特征图的尺寸是32@(120-3+1)*(150-5+1)*(9-2+1)=32@118*146*8。其中卷积计算公式如下:
步骤2.2:c2层为神经网络第二层,使用两路不同卷积核对特征图立方体进行卷积计算。右边卷积层的卷积核尺寸为64@5*7*1,步长为(1,1,1)。卷积计算后输出的特征图尺寸为64@(118-5+1)*(146-7+1)*(8-1+1)=64@114*140*8。左边卷积层的卷积核尺寸为64@3*8*1,步长为(1,1,1)。卷积计算后输出的特征图尺寸为64@(118-3+1)*(146-8+1)*(8-1+1)=64@116*139*8。
c3层为神经网络第三层,此层分别对c2层输出的特征图做卷积计算。右边卷积层的卷积核尺寸为128@5*6*2,步长为(1,1,1)。卷积计算后输出的特征图尺寸为128@(114-5+1)*(140-6+1)*(8-2+1)=128@110*135*7。左边卷积层的卷积核尺寸为128@7*5*2,步长为(1,1,1)。卷积计算后输出的特征图尺寸为128@(116-7+1)*(139-5+1)*(8-2+1)=128@110*135*7。
步骤2.3:c4层对c3卷积层的两路数据合并之后进行卷积运算,c4层的卷积核尺寸为256@6*10*3,步长为(1,1,1)。卷积计算后输出的特征图尺寸为256@(110-6+1)*(135-10+1)*(7-3+1)=256@105*126*5。c4池化窗口大小为3*3*1,池化后特征图大小为256@(105/3)*(126/3)*(5/1)=256@35*42*5。
步骤2.4:对步骤2.3输出的特征立方体图形,再次通过两路不同的卷积核做卷积计算。
c5为神经网络的第五层,右边卷积层的卷积核尺寸为512@5*11*2,步长为(1,1,1)。卷积计算后输出的特征图尺寸为512@(35-5+1)*(42-11+1)*(5-3+1)=512@31*32*4。左边卷积层的卷积核尺寸为512@11*11*2,步长为(1,1,1)。卷积计算后输出的特征图尺寸为512@(35-11+1)*(42-11+1)*(5-2+1)=512@25*32*4。
c6为神经网络的第六层,右边卷积层的卷积核尺寸为512@8*6*2,步长为(1,1,1)。卷积计算后输出的特征图尺寸为512@(31-8+1)*(32-6+1)*(5-2+1)=512@24*27*3。c6右边卷积层的池化窗口大小为3*3*1,池化计算后特征图大小为64@(24/3)*(27/3)*(3/1)=512@8*9*3。左边卷积层的卷积核尺寸为512@5*6*2,步长为(1,1,1)。卷积计算后输出的特征图尺寸为512@(25-5+1)*(32-6+1)*(5-2+1)=512@21*27*3。c6左边卷积层的池化窗口大小为3*3*1,池化计算后特征图大小为64@(21/3)*(27/3)*(3/1)=512@7*9*3。
步骤2.5:f1作为第一个全连接层,左右两层的全连接层相同,都有4096个神经元,右边全连接中每个神经元维度为512*8*9*3,得到的输出为1*1*1*4096。左边全连接中每个神经元维度为512*7*9*3,得出的输出为1*1*1*4096。f2层为第二层全连接层,是网络的输出层。f2层使用n个1*1*1*2048维神经元对f1层的输出合并再进行全连接计算,f2的输出大小为1*1*1*n。
其中全连接计算公式如下:
步骤2.6:根据步骤2.5的输出计算softmax、loss,并根据loss反向修正网络参数。重复步骤2.1-步骤2.6,直至loss收敛。softmax和loss的计算公式如下:
步骤3:将测试图片使用步骤1的方式进行图片叠加,将每个人同一类的9张头部姿态图片做叠加处理构建3d立方体输入。利用步骤2得到的3d卷积神经网络测试分类结果。
每类头部姿态转动角度如下表:
- 还没有人留言评论。精彩留言会获得点赞!