基于注意力机制的对抗攻击防御模型、构建方法及应用与流程
本发明属于图像处理领域,具体涉及一种基于注意力机制的对抗攻击防御模型及应用。
背景技术:
近年来,机器学习领域发展迅速,为人工智能问题提供了很好的解决方案。而神经网络可以看作是机器学习发展的巨大动力。从语音识别、机器翻译到图像识别,深层神经网络(dnn)成功被广泛证明。其中,深层神经网络在各种模式识别任务上,尤其是视觉分类问题上表现尤其突出。
同时,机器学习模型常常容易受到对其输入的对抗性操作而出现错误。人眼不可察觉的微小扰动的存在,可能导致深度学习模型受干扰图像的影响而产生分类错误。在计算机视觉(图像分类识别)方面,对抗性攻击有fgsm,igsm,jsma,c&w,deepfool等几种典型。此外,对抗性攻击也存在于自动编码器、强化学习、语义分割和目标检测方面。而在现实中,对抗性攻击也同样存在。人脸识别、手机摄像头、路牌识别等场景中都可以实施对抗性攻击。
随着人工智能的应用日益广泛,在人脸识别、自驾车、金融信用方面,深度学习模型的安全性也显得愈发重要。深度模型的脆弱性对安全条件苛刻的应用造成了很大的潜在威胁,所以成功实现深度学习模型的防御具有重要意义。goodfellow等人和huang等人在训练集中注入对抗性样本(也叫对抗性训练)能增强神经网络对对抗性样本的鲁棒性,但是所需训练时间长,代价大。xie等人发现对训练图像引入随机重缩放可以减弱对抗攻击的强度。通过jpeg压缩和图像再缩放,对抗性扰动可以被部分消除。papernot等人提出了防御蒸馏的概念来训练模型,这种方法修改了网络参数,但是所需成本较大。用以gan为基础的网络可以抵抗对抗攻击,而且lee提出在所有模型上用相同的办法来做可以抵抗对抗样本,但是这种方法应用型不强,效率不高。由于对抗样本的多样性,以及噪声分布和模型参数结构都不尽相同,目前并没有一种快速且高效的方法适用于任意对抗样本的防御。
技术实现要素:
为了克服目前防御方法对特征像素点针对性不强,处理能力差的问题,本发明提供了一种操作代价低、对多种模型适用的基于注意力机制的对抗攻击防御模型、构建方法及应用。
本发明解决其技术问题所采用的技术方案是:
一种基于注意力机制的对抗攻击防御模型的构建方法,包括以下步骤:
构建对抗攻击防御网络,对抗攻击防御网络包括特征提取单元、重构通道图单元、重构空间图单元以及重构图融合单元,其中,特征提取单元用于对输入的对抗样本进行特征提取,输出特征图;重构通道重构图单元用于采用通道注意力机制对特征图进行特征重构,输出通道重构图;重构空间重构图单元用于采用空间注意力机制对通道重构图进行特征强化,输出空间重构图;重构图融合单元,用于将对抗样本和空间重构图进行叠加融合,输出重构图;
利用对判别器对重构图进行判别,输出判别结果;
根据判别结果对对抗攻击防御网络中的网络参数和阈值进行调优;
当调优终止后,提取对抗攻击防御网络和确定的网络参数和阈值组成对抗攻击防御模型。
一种上述注意力机制的对抗攻击防御模型的构建方法构建得到的对抗攻击防御模型。
一种上述对抗攻击防御模型在恶性图片识别中的应用,应用时,将恶性图片的对抗样本输入至对抗攻击防御模型中,经计算输出识别结果。
与现有技术相比,本发明具有的有益效果为:
该构建方法简单,适用于多种对抗攻击防御模型的构建,获得的对抗攻击防御模型能够适用于多种模型和多种攻击,采用注意力机制加强特征像素点的效果较好,降低了对抗性攻击成功的概率。在真实图像上的实验结果表明,该算法具有良好的适用性和精度,能够有效地滤除多种对抗性扰动,取得较好的防御效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
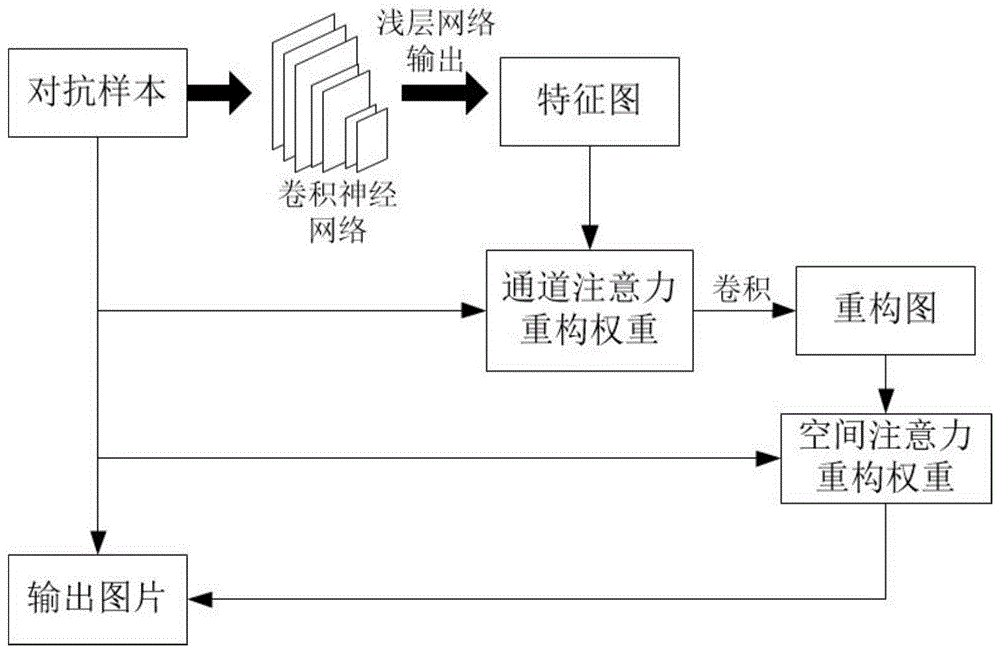
图1是本发明提供利用抗攻击防御模型进行对抗样本防御的流程图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
本发明提供的基于注意力机制的对抗攻击防御模型的构建方法的技术构思为:基于注意力机制的对抗攻击防御方法,适用于多种模型和数据集,达到防御对抗攻击的效果。首先利用特征图和通道注意力机制得到包含特征像素点的重构图,再利用特征像素点与原图相似度大的特点,运用空间注意力机制将无关像素点滤除,对特征像素点进行加强,最后得到防御后的图片,很大程度上降低了模型误判的概率,提高模型的鲁棒性。
如图1所示,实施例提供的一种基于注意力机制的对抗攻击防御模型的构建方法,包括以下步骤:
s101,构建对抗攻击防御网络。
本实施例构建的对抗攻击防御网络包括特征提取单元、重构通道图单元、重构空间图单元以及重构图融合单元,其中,特征提取单元用于对输入的对抗样本进行特征提取,输出特征图;重构通道重构图单元用于采用通道注意力机制对特征图进行特征重构,输出通道重构图;重构空间重构图单元用于采用空间注意力机制对通道重构图进行特征强化,输出空间重构图;重构图融合单元,用于将对抗样本和空间重构图进行叠加融合,输出重构图。
具体地,本实施例选取卷积神经网络作为特征提取单元,以提取对抗样本的特征,输出尺寸小于对抗样本尺寸的特征图。
针对对抗样本,将对抗样本缩放为统一大小w×h×3后,选取神经网络的第一层网络作为浅层特征层,输入w×h×3的对抗样本,有c个通道的卷积层扫描输入的图像,输出一张w’×h’×c的特征图,该层的输出图像即为特征图。
重构通道重构图单元主要用于对输入的特征图进行通道重构,输出通道重构图。具体地,在重构通道重构图单元中,
采用双线性插值方法对特征图进行上采样,将特征图重构为与对抗样本相同维度的空间,即将特征图放大到与对抗样本相同的尺寸(即尺寸为w×h×c),将上采样得到的特征图记为ifm;
将特征图矩阵和对抗样本矩阵分别做转置处理,原矩阵为[w,h,c],转置后为[c,w,h],w、h、c分别代表图像的长宽和通道数,获得特征向量vf和对抗样本向量vadv;
即:
利用公式(2)计算特征向量vf和对抗样本向量vadv之间的相似度距离α:
其中,tanh(·)为双曲正切函数;
利用公式(3)对相似度距离α进行归一化处理,得到通道注意力重构权重矩阵wc:
其中,wc为对相似度距离α进行归一化处理结果,该归一化处理结果作为通道注意力重构权重矩阵,min(α)为相似度矩阵α中最大值,同理max(α)为似度矩阵α中最大值;
以通道注意力重构权重为卷积滤波器,对特征图进行卷积操作,生成与对抗样本尺寸相同(即尺寸为w×h×c)的通道重构图。
通道重构图中包含了图片特征,而对抗样本在像素点上增加了对抗性扰动,通过对两者像素点求相似度的方法可以判断像素点是否为特征像素点,以此给神经网络赋不同的权重。重构空间重构图单元主要用于采用空间注意力机制对通道重构图进行特征强化。具体地,在重构空间重构图单元中,
利用公式(4)计算通道图向量vr与对抗样本iadv之间的二次相似距离矩阵β:
β=ave(iadv*vr)(4)
其中,ave(·)表示取平均值函数,*代表矩阵对应元素相乘;
利用公式(5)对二次相似距离矩阵β进行归一化处理,得到空间注意力重构权重矩阵ws:
其中,ws为对相似度距离β进行归一化处理结果,该归一化处理结果作为空间注意力重构权重矩阵,min(β)为二次相似度矩阵β中最大值,max(β)为二次相似度矩阵β中最小值;
设定一个阈值r,遍历空间注意力重构权重矩阵ws中的每个像素点ai,j,若ai,j<阈值γ,则将像素点ai,j的值置为0,反之则不做改动,这样即获得了空间重构图imap。
在重构图融合单元,利用公式(6)对抗样本和空间重构图进行叠加融合,输出重构图iout:
iout=iadv×imap(6)
其中,iadv为对抗样本,imap为空间重构图。
s102,利用对判别器对重构图进行判别,输出判别结果。
具体地,判别器为全连接层、softmax分类器。即可以将全连接层或softmax分类器连接到重构图融合单元的输出,即对重构图融合单元输出的重构图进行对抗样本判别,输出判别结果(即预测概率)。
s103,根据判别结果对对抗攻击防御网络中的网络参数和阈值进行调优。
本实施例中,可以首先设置阈值γ为0.1,若生成的重构图为全黑,则说明阈值γ设置过大,反之,当生成的重构图非常模糊,则说明阈值γ设置过小。在调优的过程中,反复修改调节阈值γ,多次实验生成图片给模型判断,直到取得最佳γ0。
s104,当调优终止后,提取对抗攻击防御网络和确定的网络参数和阈值组成对抗攻击防御模型。
上述注意力机制的对抗攻击防御模型的构建方法,该构建方法简单,适用于多种对抗攻击防御模型的构建,且制备得到的对抗攻击防御模型能够适用于多种模型和多种攻击,采用注意力机制加强特征像素点的效果较好,降低了对抗性攻击成功的概率。
本实施例还提供了一种上述对抗攻击防御模型的构建方法构建得到的对抗攻击防御模型。该对抗攻击防御模型能够适用于多种模型和多种攻击,采用注意力机制加强特征像素点的效果较好,很大程度上降低了模型误判的概率,提高模型的鲁棒性,降低了对抗性攻击成功的概率。
本实施例还提供了一种上述对抗攻击防御模型在恶性图片识别中的应用。应用时,将恶性图片的对抗样本输入至对抗攻击防御模型中,经计算输出识别结果。
恶性图片是指包含有色情、暴力的色情暴力图片,这些恶性图片在受到上传者的对抗性扰动操作后,不能被分类器识别成恶性图片,在网上得到传播。本实施例提供的抗攻击防御模型可以能够精确识别恶性图片。
应用时,针对恶性图片采用多种攻击方法生成能够成功欺骗分类器对抗样本,然后对抗样本输入到基于注意力机制的对抗攻击防御模型中,经过对对抗样本进行特征提取、特征重构、特征强化以及特征融合,得到过滤掉对抗性扰动的重构图。这些重构图输入至分类器中,能被分类器识别成恶性图片,从而阻止其在网上传播。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!