一种实现数据库动态切换的方法及计算机可读存储介质与流程
本发明涉及一种实现数据库动态切换的方法及计算机可读存储介质。
背景技术:
对于大型的互联网应用来说,数据库单表的记录行数可能达到千万级,并且数据库面临着极高的并发访问。为了满足高并发的访问,同时保证数据库的高可用,一种有效的方式是采用读写分离的架构,以缓解单台数据数据库读写压力;读写分离架构指:一个主库用于写数据,多个从库完成读数据的操作,主从库之间通过某种机制进行数据的同步;在一个项目种实现读写分离,数据库连接池要进行区分,哪些是读连接池,哪个是写连接池;传统方式往往采用硬编码的形式实现,业务代码和数据源切换代码耦合严重,不利于后期的维护和拓展。
springboot:是业内流行的分布式java开发框架,它简化了spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员只需要定义样板化的配置即可轻松完成各种插件的配置。另外我们可以利用该原理定义自己的springboot的插件。
切面编程:aop主要实现的目的是针对业务处理过程中的切面进行提取,它所面对的是处理过程中的某个步骤或阶段,以获得逻辑过程中各部分之间低耦合性的隔离效果;
术语:
1.pointcut(切入点):本质上是一个捕获连接点的结构。在aop中,可以定义一个pointcut,来捕获相关方法的调用。
2.advice(通知):是pointcut的执行代码,是执行“方面”的具体逻辑。
3.aspect(切面):pointcut和advice结合起来就是aspect,它类似于oop中定义的一个类,但它代表的更多是对象间横向的关系。
线程副本:多线程并发之所以会不安全,就是因为线程不拥有资源,它们共享竞争着进程的资源,这样线程并发起来不安全,一般的解决方案便是用锁,保证每时每刻一个资源最多只能被一个线程拥有。而在java的多线程中,threadlocal为解决多线程程序的并发问题提供了一种新的思路。threadlocal解决多线程的并发问题的思路很简单:就是为每一个线程维护一个副本变量,从而让线程拥有私有的资源,就不再需要去竞争进程中的资源。每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
技术实现要素:
本发明要解决的技术问题,在于提供一种实现数据库动态切换的方法及计算机可读存储介质,无需其他业务控制代码,即可实现高内聚低耦合,且性能不受影响;在此基础上通过配置可以实现数据库读写分离。
本发明之一是这样实现的:一种实现数据库动态切换的方法,包括:
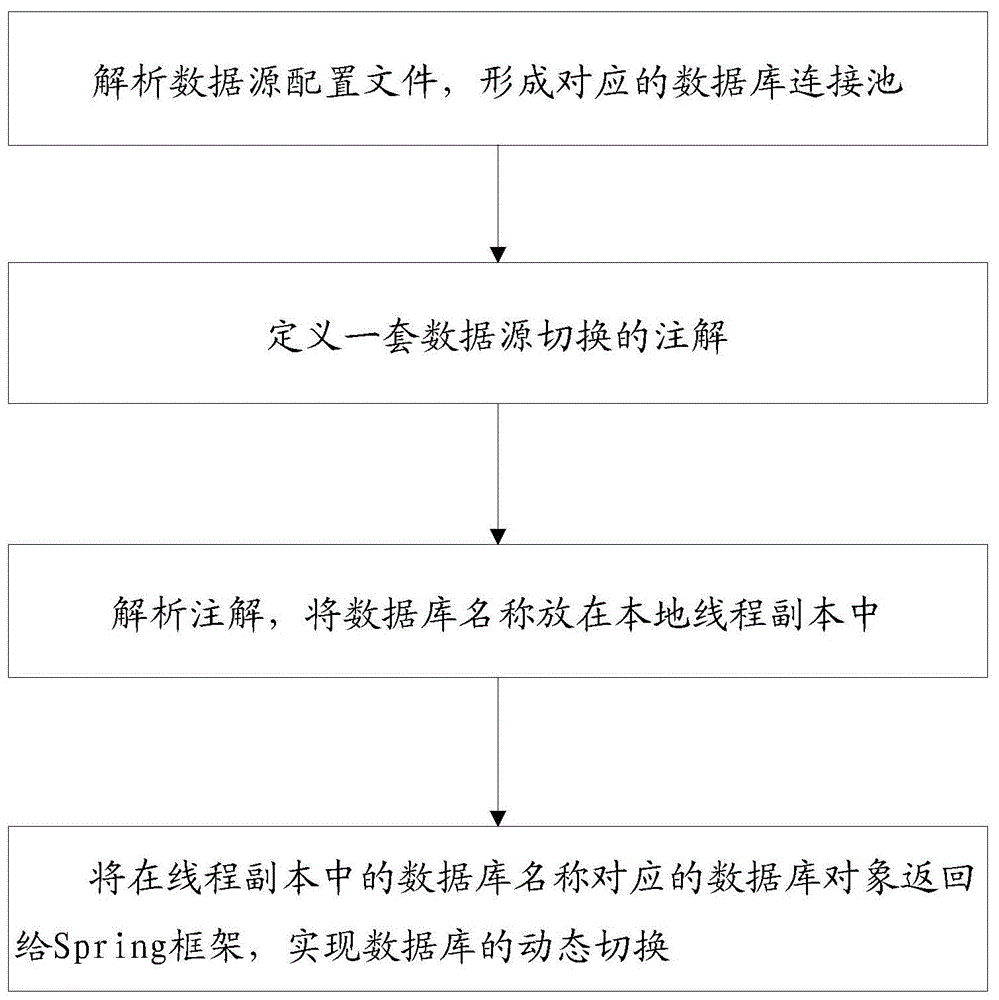
步骤1、解析数据源配置文件,形成对应的数据库连接池;
步骤2、定义一套数据源切换的注解;
步骤3、解析注解,将数据库名称放在本地线程副本中;
步骤4、将在线程副本中的数据库名称对应的数据库对象返回给spring框架,实现数据库的动态切换。
进一步地,所述步骤1进一步具体为:解析数据源配置文件,得到单个数据源配置对象;
根据数据源配置文件创建数据源对象;最终生成一个存有数据库列表信息的map对象,其中,key为数据库的名称,value为对应的数据库实例。
进一步地,所述步骤2进一步具体为:定义注解类ds,其为retentionpolicy.runtime类型的注解,其在代码运行时解析,且只有一个属性用来定义数据源名称。
进一步地,所述步骤3进一步具体为:设置切入点,使用spring提供的abstractpointcutadvisor接口实现切入点设置,实现切面逻辑;利用annotationmatchingpointcut类,实现匹配所有ds.class注解的类和方法;
实现切面逻辑,作用在切入点匹配的类和方法上;获取ds注解的属性名称,也就是获取ds注解的方法和类要使用的数据库名称,并将数据库名称放在本地线程副本中。
进一步地,所述步骤4进一步具体为:使用spring提供的abstractroutingdatasource接口实现数据源的切换;其方法determinedatasource返回数据源实例,即从本地副本中获取当前方法使用的数据源的名称,并从数据源列表中获取对应的数据源实例。
本发明之二是这样实现的:一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现以下步骤:
步骤1、解析数据源配置文件,形成对应的数据库连接池;
步骤2、定义一套数据源切换的注解;
步骤3、解析注解,将数据库名称放在本地线程副本中;
步骤4、将在线程副本中的数据库名称对应的数据库对象返回给spring框架,实现数据库的动态切换。
进一步地,所述步骤1进一步具体为:解析数据源配置文件,得到单个数据源配置对象;
根据数据源配置文件创建数据源对象;最终生成一个存有数据库列表信息的map对象,其中,key为数据库的名称,value为对应的数据库实例。
进一步地,所述步骤2进一步具体为:定义注解类ds,其为retentionpolicy.runtime类型的注解,其在代码运行时解析,且只有一个属性用来定义数据源名称。
进一步地,所述步骤3进一步具体为:设置切入点,使用spring提供的abstractpointcutadvisor接口实现切入点设置,实现切面逻辑;利用annotationmatchingpointcut类,实现匹配所有ds.class注解的类和方法;
实现切面逻辑,作用在切入点匹配的类和方法上;获取ds注解的属性名称,也就是获取ds注解的方法和类要使用的数据库名称,并将数据库名称放在本地线程副本中。
进一步地,所述步骤4进一步具体为:使用spring提供的abstractroutingdatasource接口实现数据源的切换;其方法determinedatasource返回数据源实例,即从本地副本中获取当前方法使用的数据源的名称,并从数据源列表中获取对应的数据源实例。
本发明具有如下优点:本发明是基于springboot注解、spring动态代理和切面编程技术,只需在特定类或者方法上注解,实现多数据源集成,数据源的动态切换等。该方法无需其他业务控制代码,即可实现高内聚低耦合,且性能不受影响;在此基础上通过配置可以实现数据库读写分离。
附图说明
下面参照附图结合实施例对本发明作进一步的说明。
图1为本发明方法执行流程图。
具体实施方式
如图1所示,本发明依托springboot的注解机制,设计一套注解,完成动态数据库链接池构造,并注入到spring上下文中,动态数据源通过获取本地线程副本的数据源名称确定使用哪个数据源。同时通过切面编程原理实现在业务层通过注解,解析出调用方法上配置的数据源名称,并存储在本地线程副本中。
数据源配置:application.yml是springboot的默认配置文件,我们采用springboot的风格配置master-slaves的数据库架构,支持多个slave节点;
初始化数据源:根据数据源配置项,不同的数据库地址,形成不同的数据库连接池,等待需要的时候调用;
定义注解:自定义一套数据源切换的注解。用户只需要在类或者方法上使用注解,并通过注解属性选择需要使用的数据源,即可完成多数据源配置下,数据源的灵活切换;用户配置注解的过程其实就是设置需要代理的类和方法的过程;
解析注解:使用aop(切面编程技术),在方法运行时将用户注解在类或者方法上的数据库名称解析出来,放在本地线程副本中;
动态数据源切换:在操作数据库之前,将在线程副本中的数据库名称对应的数据库对象返回给spring框架,实现数据库的动态切换;
1、定义数据源
我们采用springboot风格的配置方式来配置数据源;例如:配置文件的基本结构;
spring.datasource.dynamic为数据源的根路径
spring.datasource.dynamic.primary为默认数据源名称
spring.datasource.dynamic.datasource为数据源列表,其中master,slave_1,slave_2是测试用例中的三个数据源名称,每个数据源名称有以下属性:
username:数据库登录用户名
password:数据库登录密码
url:数据库连接地址
driver-class-name:为数据库驱动类;
2、初始化数据源:
由于要实现数据库的灵活切换,首先要获取多数据源的对象,在这个过程中,需要完成以下几个子步骤:
解析数据库配置文件:根据步骤1中数据源的配置信息,解析成单个数据源配置对象,数据源配置对象是从配置文件中解析出来的,包含了链接数据库所需要的信息,入用户名,密码,数据库地址等。
根据数据库的配置文件创建数据源对象(对应上面的单个数据源配置对象,配置对象存储了数据源的信息;用来初始化数据源;数据源对象是根据配置对象生成的数据库链接实例);可以使用阿里巴巴的开源数据库连接池druid库,创建名为druiddatasource数据库对象;最终生成一个存有数据库列表信息的map对象,key为数据库的名称(数据库名称会通过注解标注在用户的类上),value为对应的数据库实例;
一个数据源会初始化一个连接池,多个数据源初始化可以初始化多个连接池,此时,这里是一个连接池集合:key数据源名称,value是对应的连接池对象
3、定义和使用注解:
注解定义:注解类:ds,是一个retentionpolicy.runtime类型的注解,其特点是可以在代码运行时解析,它只有一个属性value,用来定义数据源名称;
使用注解:注解是用户直接使用的api,注解使用非常简单,只需要需要在数据库操作的方法上添加ds注解即可:例如下面代码@ds("slave_1"),意思是selectusersfromds方法使用slave_1数据库;
4、解析注解
解析用户注解是非常重要的步骤,是用户告诉程序使用哪一个数据库的入口;我们通过springaop(面向切面编程)来实现;
设置切入点:可以使用spring提供的abstractpointcutadvisor接口实现切入点设置,实现切面逻辑,利用annotationmatchingpointcut类,可以实现匹配所有ds.class注解的类和方法;如下代码,设置匹配自定义注解ds的方法和类作为切入点;
实现切面逻辑:切面的逻辑会作用在切入点匹配的类和方法上;切面的核心是获取ds注解的属性名称,也就是获取ds注解的方法和类要使用的数据库名称,并将数据库名称放在本地线程副本中,命名为dynamicdatasourcecontentholder
5、实现动态数据源切换
通过上面的步骤,我们已经初始化了数据源、获取到方法指定的数据源名称并保存在本地线程副本中,接下来我们可以使用spring提供的abstractroutingdatasource接口实现数据源的切换;它的核心方法determinedatasource()返回数据源实例,我们从本地副本中获取当前方法使用的数据源的名称,并从数据源列表中获取对应的数据源实例;
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!