一种泵站机组故障诊断系统的生成方法与流程
本发明涉及泵站技术领域,具体涉及一种泵站机组故障诊断系统的生成方法。
背景技术:
随着科学技术和国民经济的发展,水泵站在农业、电力、石油、采矿和跨流城调水等行业中的应用日益广泛,尤其在排涝、灌溉、发电、供水、调节航运水位等方面起着举足轻重的作用。而水泵机组是水泵站的关键设备,其运行状态的优劣直接影响泵站的安全运行,我国南水北调工程建成后,泵站机组运行时间长、投资大、可靠性要求高,因事故或故障停机而导致的供水中断将造成重大的经济损失和社会影响,因此对泵站的运行、维护、管理和检修等方面提出了更高的要求,尤其是安全可靠性已成为衡量泵站机组质量的重要指标,针对以上情况,泵站机组的故障诊断技术应运而生。故障诊断是指在泵站机组运行时,对机组进行监控,判断是否出现某种故障,从而对维修进行指导,帮助快速恢复生产。
现有的泵站机组故障诊断需要采集故障数据,对故障数据进行处理,人工对机器学习模型和参数进行选择,存在成本高、周期长,这对泵站机组故障诊断系统的功能扩展、旧算法更新造成很大的不便。
技术实现要素:
本发明提供一种泵站机组故障诊断系统的生成方法。
为解决上述技术问题,本发明采用如下技术方案:
对泵站机组发生故障的数据进行收集;
对收集到的数据信息提取特征向量,并从提取的特征向量中选择最优特征向量;
将最优特征向量与机器学习模型通过遗传算法进行排列组合,并选择出最优的特征向量和机器学习模型的组合;
将最优的特征向量和机器学习模型的组合组成诊断模型进行测试;
利用满足测试要求的诊断模型对泵站机组故障进行诊断。
进一步地,所述提取特征向量的具体方法为:对采集到的故障数据转换成多个数据点,将数据点作为该故障的特征向量。
进一步地,所述选择最优特征向量的具体方法为:根据提取出的特征向量计算出自身的方差,同时将特征向量与预测目标之间的关联性进行比较,如方差大于1且特征向量与预测目标之间的关联性高,则该特征向量为最优特征向量,反之,则被排除。
进一步地,所述将最优特征向量与机器学习模型通过遗传算法进行排列组合,选择出最优的特征向量和机器学习模型的组合的具体方法为:
s1、根据最优的特征向量与现有的机器学习模型随机生成n个初始组合;
s2、将n个初始组合通过遗传算法的复制、交叉和变异生成n个新的组合;
s3、将n个新的组合重新作为s1中的初始组合,并依次循环执行s2、s3;
s4、循环y次后得到最优的n个组合,从最优的n个组合中挑选出最优的1个组合作为寻找结果。
进一步地,所述循环y次后得到最优的n个组合的具体方法为:将不断生成的新的初始组合进行s2、s3的迭代,判断迭代次数是否达到设定值y次,达到后即为最优的组合。
进一步地,所述将最优的特征向量和机器学习模型的组合组成诊断模型进行测试的具体方法为:将需要测试的样本故障通过诊断模型进行诊断,得出的诊断结果与实际样本故障的结果进行比较,然后判断测试的准确度是否高于所设阈值,如高于则组成诊断模型,反之,则返回特征提取。
与现有技术相比,本发明的有益效果:
该泵站机组故障诊断系统的生成方法采用计算机科学人工智能领域中的遗传算法进行自动化排列组合,并选择出最优的特征向量和机器学习模型的组合,不需要人工对机器学习模型和参数进行选择,成本低、周期短、计算效果好,以及误差低,使得通过该生成方法形成的泵站机组诊断系统能够快速且有效对泵站机组故障进行检测。
附图说明
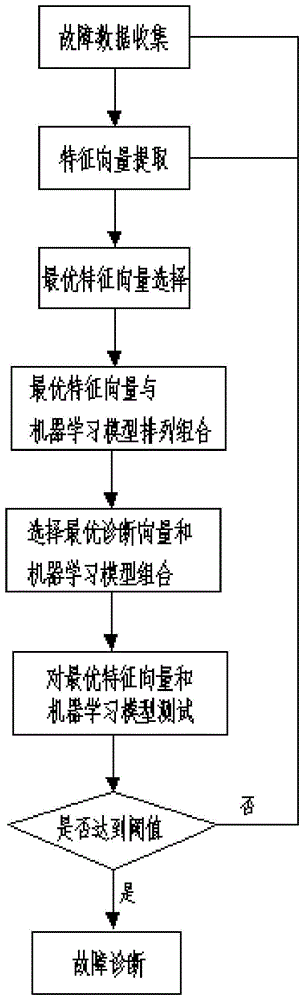
图1为本发明生成流程结构图;
图2为选择最优诊断模型流程结构图。
具体实施方式
下面结合附图对本发明的一种优选实施方式作详细的说明。
如图1-2所示,一种泵站机组故障诊断系统的生成方法,包括:
步骤一、对泵站机组发生故障的数据进行收集;
步骤二、对收集到的数据信息转换成多个数据点,将数据点作为该故障的特征向量提取特征向量;
步骤三、对获取的特征向量计算出自身的方差,同时将特征向量与预测目标之间的关联性进行比较,如方差大于1且特征向量与预测目标之间的关联性高,则该特征向量为最优特征向量,反之,则被排除;
步骤四、自动机器学习技术对最优的特征向量与现有的机器学习模型随机生成n个初始组合;将n个初始组合通过遗传算法的复制、交叉和变异生成n个新的组合;将n个新的组合重新作为初始组合,并通过遗传算法的复制、交叉和变异生成n个新的组合,再次将n重新作为初始组合通过遗传算法再次生成n个新的组合,重复循环以上步骤;判断迭代次数是否达到设定值y次,达到后即为最优的组合,得到最优的n个组合,从最优的n个组合中挑选出最优的1个组合作为寻找结果;
步骤五、最优的特征向量和机器学习模型的组合组成诊断模型,将需要测试的样本故障通过诊断模型进行诊断,得出的诊断结果与实际样本故障的结果进行比较,然后判断测试的准确度是否高于所设阈值,如高于80%则组成诊断模型,反之,则返回特征提取,当返回特征提取后再次进行步骤三、步骤四和步骤五,反复计算3次后,如测试的准确度是仍未达到所需阈值,则返回步骤一,进行原始数据的收集。
步骤六、利用最优诊断模型对泵站机组故障进行诊断。
工作过程:
泵轴转子故障:当泵站机组中泵轴转子发生故障时,首先采集转子正常样本数量、转子不对中样本数量、转子不平衡样本数量和接触摩擦样本数量下的传感器泵轴y方向的摆度信号,将根据采集的摆度信号形成时域图,然后利用傅立叶变换得到频谱,从频谱中按照特征规则(该特征规则是提取(0,0.4×]、(0.4×,0.5×)、[0.5×]、(0.5×,1×)、[1×]、[2×]、[3×,5×]、[6×,高频)这8个频段的最大幅值,其中“()”代表开区间,“[]”代表闭区间,“×”代表倍频)提取出特征向量,此时样本数据为[y,8],(其中y代表样本数量,8代表单个样本原始数据经特征提取后得到的特征维度),对提取的特征向量计算出各个特征维度自身的方差,计算公式为v1=var(a1,b1,……,x1),式中:v1为维度1的方差,a1为样本数据a的维度1、b1为样本数据b的维度1、x1为样本数据x的维度1,同理可计算出维度2、维度3、维度4、维度5、维度6、维度7和维度8的方差,同时计算特征向量中维度1与预测目标之间的关联性corr1,比较公式为corr1=mi(vx,p),式中:mi代表两个变量vx和p之间的互信息,vx为不同样本数据下的维度1组成的特征向量[a1,b1,……,x1],p代表预测值组成的向量[pa,pb,……,px],其中p1为样本数据a在八个不同维度下的预测值,p2为样本数据b在八个不同维度下的预测值,px为样本数据x在八个不同维度下的预测值,同理可计算出特征向量中维度2、维度3、维度4、维度5、维度6、维度7、维度8与预测目标之间的关联性,如各个维度的方差大于1且特征向量与预测目标之间的关联性高,则该特征向量为最优特征向量,反之,则被排除,选择当前代数种群中准确率在前90%的机器学习模型作为下一代种群中机器学习模型,从机器学习模型中随机选出两个,将得到的最优特征向量与机器中选择的两个学习模型通过遗传算法进行交叉和变异,进行迭代,最终得到一个最优的诊断模型,将最优的诊断模型分成5份,依次选择其中的1份作为诊断模型测试样本,剩下4份作为训练样本,这样会对诊断模型进行5次训练并得到对应的5个诊断模型测试结果,以这5次测试结果的平均值作为最终的诊断模型测试结果,以最终的诊断模型测试结果与真实的故障结果进行比较,形成误差函数,将误差函数指导诊断模型的训练,将需要测试的样本故障通过诊断模型进行诊断,得出的诊断结果与实际样本故障的结果进行比较,当最终的模型测试效果(即准确率)高于最低效果80%时,机器利用最终的模型测试对泵站机组故障进行诊断,反之,则返回特征提取,当返回特征提取后再次进行特征选择、最优特征提取和训练模型,反复计算3次后,如测试效果仍低于所需阈值,则返回步骤一,进行原始数据的收集。
轴承故障:当泵站机组中轴承发生故障时,首先通过安装在轴承上的加速度传感器收集轴承样本数量下的加速度信号,对加速度信号进行小波变换,然后将分解后的前5个小波系数作为提取的特征向量,这样将一段信号变成一个五维的向量,对获取的特征向量计算出自身的方差,计算公式为v1=var(a1,b1,……,x1),式中:v1为维度1的方差,a1为样本数据a的维度1、b1为样本数据b的维度1、x1为样本数据x的维度1,同理可计算出维度2、维度3、维度4、维度5的方差,同时计算特征向量中维度1与预测目标之间的关联性corr1,比较公式为corr1=mi(vx,p),式中:mi代表两个变量vx和p之间的互信息,vx为不同样本数据下的维度1组成的特征向量[a1,b1,……,x1],p代表预测值组成的向量[pa,pb,……,px],其中p1为样本数据a在五个不同维度下的预测值,p2为样本数据b在五个不同维度下的预测值,px为样本数据x在五个不同维度下的预测值,同理可计算出特征向量中维度2、维度3、维度4、维度5与预测目标之间的关联性,如方差大于1且特征向量与预测目标之间的关联性高,则该特征向量为最优特征向量,反之,则被排除,选择当前代数种群中准确率在前90%的机器学习模型作为下一代种群中机器学习模型,从机器学习模型中随机选出两个,将得到的最优特征向量与机器中选择的两个学习模型通过遗传算法进行交叉和变异,进行迭代,最终得到一个最优的诊断模型,将最优的诊断模型分成5份,依次选择其中的1份作为诊断模型测试样本,剩下4份作为诊断模型训练样本,这样会对诊断模型进行5次训练并得到对应的5个诊断模型测试结果,以这5次测试结果的平均值作为最终的诊断模型测试结果,以最终的诊断模型测试结果与真实的故障结果进行比较,形成误差函数,将误差函数指导诊断模型的训练,将需要测试的样本故障通过诊断模型进行诊断,得出的诊断结果与实际样本故障的结果进行比较,当最终的模型测试效果(即准确率)高于最低效果80%时,机器利用最终的模型测试对泵站机组故障进行诊断,反之,则返回特征提取,当返回特征提取后再次进行特征选择、最优特征提取和训练模型,反复计算3次后,如测试效果仍低于所需阈值,则返回步骤一,进行原始数据的收集。
汽蚀故障:收集水泵进水口附近的运行噪音作为故障数据,采集y个样本故障数据,由于噪音是一段音频信号,故采用提取信号的梅尔频率倒谱系数作为特征向量,该特征向量一共有26维度:12维倒谱系数、12维倒谱系数差分、1维能量和1维能量差分,对获取的特征向量计算出自身的方差,计算公式为v1=var(a1,b1,……,x1),式中:v1为维度1的方差,a1为样本数据a的维度1、b1为样本数据b的维度1、x1为样本数据x的维度1,同理可计算出维度2、维度3、……、维度26的方差,同时计算特征向量中维度1与预测目标之间的关联性corr1,比较公式为corr1=mi(vx,p),式中:mi代表两个变量vx和p之间的互信息,vx为不同样本数据下的维度1组成的特征向量[a1,b1,……,x1],p代表预测值组成的向量[pa,pb,……,px],其中p1为样本数据a在26个不同维度下的预测值,p2为样本数据b在26个不同维度下的预测值,px为样本数据x在26个不同维度下的预测值,同理可计算出特征向量中维度2、维度3、……、维度26与预测目标之间的关联性,如方差大于1且特征向量与预测目标之间的关联性高,则该特征向量为最优特征向量,反之,则被排除,选择当前代数种群中准确率在前90%的机器学习模型作为下一代种群中机器学习模型,从机器学习模型中随机选出两个,将得到的最优特征向量与机器中选择的两个学习模型通过遗传算法进行交叉和变异,进行迭代,最终得到一个最优的诊断模型,将最优的诊断模型分成5份,依次选择其中的1份作为模型测试样本,剩下4份作为训练样本,这样会对模型进行5次训练并得到对应的5个模型测试结果,以这5次测试结果的平均值作为最终的诊断模型测试结果,以最终的诊断模型测试结果与真实的故障结果进行比较,形成误差函数,将误差函数指导诊断模型的训练,将需要测试的样本故障通过诊断模型进行诊断,得出的诊断结果与实际样本故障的结果进行比较,当最终的模型测试效果(即准确率)高于最低效果80%时,机器利用最终的模型测试对泵站机组故障进行诊断,反之,则返回特征提取,当返回特征提取后再次进行特征选择、最优特征提取和训练模型,反复计算3次后,如测试效果仍低于所需阈值,则返回步骤一,进行原始数据的收集。
以上所述实施方式仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明的权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!