一种基于序列学习的车牌识别方法与流程
本发明涉及智能交通技术领域,具体设计一种基于序列学习的车牌识别方法。
背景技术:
自动车牌识别是一项融合图像处理、机器学习和模式识别等多项任务的技术。经过数十年的发展,车牌识别技术已经步入大规模商用阶段,其应用领域包括公共场所门禁、交通卡口监控和交通路口监控等。
随着智慧交通技术的发展,商用车牌识别系统已将深度学习运用到了实际问题的解决方案中,并且宣布其车牌识别率高达99%。文献(y.zhao,z.yu,andx.li,“evaluationmethodologyforlicenseplaterecognitionsystemsandexperimentalresults,”ietintell.transp.syst.,vol.12,no.5,pp.375-385,may2018.)测试了五款商用车牌识别系统,而实际测试结果显示车牌识别率仅在75%-92%。显然,测试结果与所宣传的指标有所出入反映出车牌识别技术仍有其研究价值,而多种多样的车牌制式是相关研究面临的主要挑战之一。
传统的车牌识别方法将车牌识别分为车牌定位、字符分割和字符识别三个阶段。然而,对于不同制式的车牌,需要制定不同的字符分割方案,而分割时选择错误的字符分割方案意味着字符分割失败。尽管遍历所有的分割方案后再选出最优的分割方案是一个优化选择,但是这带来了极大的资源浪费。此外,字符分割方法受诸多因素的影响,如环境、定位情况、车牌清晰度等。
基于深度学习的车牌识别方法克服了部分传统三阶段车牌识别的缺陷。虽然部分研究着力于用深度学习技术提高各分阶段的效果,但是该类方法忽略了三阶段之间存在的联系。文献(q.guo,f.wang,j.lei,d.tu,andg.li,“convolutionalfeaturelearningandhybridcnn-hmmforscenenumberrecognition,”neurocomputing,vol.184,pp.78–90,apr.2016.)提出一种混合cnn-hmm模型,将车牌识别视为序列处理问题,首先对车牌字符进行过分割,然后将各分割部分输入到cnn进行识别,得到冗余的识别序列,最后采用传统的hmm处理冗余序列,得到最终的识别结果。文献(h.li,p.wang,andc.shen,“towardsend-to-endcarlicenseplatesdetectionandrecognitionwithdeepneuralnetworks,”ieeetrans.intell.transp.syst.,tobepublished,doi:10.1109/tits.2018.2847291.)融合了stn、cnn、brnn和ctc来识别倾斜车牌,其中stn用于矫正倾斜车牌,cnn用于提取特征以辅助车牌检测,brnn与ctc则将车牌图像作为序列进行识别。然而,大多数端到端车牌识别方法所研究的对象仅限于单行车牌,而实际场景中十分普遍的双行车牌超过了可识别范畴。发明专利(公开号:cn109165643a,名称:一种基于深度学习的车牌识别方法)用定位车牌字符代替定位车牌作为起始步骤,将传统的车牌识别三阶段相互关联,减小误差累积所带来的影响。该方法通过检测车牌字符本身,配合后续的字符筛选和排列组合操作完成车牌识别,不限制所能识别的车牌字符长度,适用于多种车牌制式的车牌,对车牌定位的准确率要求不高。但是,所有检测到的候选字符需要用过人工启发式方法进行后续处理,而不同制式的车牌需要设置不同的人工启发式规则,鲁棒性不够高。
综上所述,目前车牌识别方法面临如下问题:1)多种多样的车牌制式是相关研究面临的主要挑战之一;2)基于字符检测的车牌识别方法存在漏检与多检情况;3)人工启发式方法虽然高效准确,但是启发式规则的设计繁杂,且需要对不同制式的车牌采用不同的策略。
技术实现要素:
为克服现有技术的上述缺点,本发明提出一种基于序列学习的车牌识别方法。首先使用深度学习训练一个车牌字符检测模型,再使用深度学习训练得到一个sequence-to-sequence模型,然后将待识别的车牌图像编码成由候选车牌字符构成的序列,接着使用训练的序列转换模型将编码序列转换为字符索引序列,最后按解码序列翻译得到车牌识别结果。
本发明的技术方案如下:
一种基于序列学习的车牌识别方法,其特征在于,包括如下步骤:
步骤1:首先准备车牌字符检测数据集,在每一张车牌上标注每一车牌字符的位置矩形框r与类别标签c,c∈d,d为字符索引表;然后基于准备的数据集训练用于车牌字符检测的深度卷积神经网络模型mc;
步骤2:训练用于序列转换的sequence-to-sequence模型ms,具体步骤为:
步骤2.1:将待训练的图像i输入到用于车牌字符检测的深度卷积神经网络模型mc,编码得到候选车牌字符构成的序列x={x1,x2,…,xt},其中xi表示编码序列的第i个字符,1≤i≤t,t表示编码序列的长度,xi是由
步骤2.2:首先构造索引字典v={0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19};然后为编码序列x标注目标解码序列y={y1,y2,…,yl},其中yi表示解码序列的第i个元素,1≤i≤l,l表示解码序列的长度,l=t,yi是xi在实际车牌号码s中的索引值,yi∈v,若
步骤2.3:首先在编码序列x末尾加上结束字符e<eos>=(0,0,0,0,0),在解码序列y末尾加上结束字符d<eos>=0;然后将x加入训练样本集xt,将y加入训练样本集yt;
步骤2.4:对所有的训练图像重复步骤2.1至步骤2.3;
步骤2.5:首先设计一个两层的lstm模型,其中每层设置128个隐藏单元;该两层的lstm模型分为编码器和解码器两部分,将上一步骤得到的训练样本集ψ=<xt,yt>按公式(1)训练sequence-to-sequence模型;
其中,o为编码器学习到的单一序列样本x的规则化表示,p(yi|o,y1,...,yi-1)为解码器得到的特定序列元素yi的概率,yi∈v,p(y1,...,yl|x1,...,xt)为将序列x转换为序列y的概率,θ为所训练sequence-to-sequence模型ms的模型参数;
步骤3:将待识别的图像g输入到车牌字符检测网络mc,编码得到候选车牌字符构成的序列xg={u1,u2,…,unx},其中ui表示序列xg的第i个字符,1≤i≤nx,nx表示序列xg的长度;
步骤4:将步骤3得到的序列xg输入步骤2得到的sequence-to-sequence模型ms,得到转换序列yg={v1,v2,…,vny},其中vi表示序列yg的第i个字符,1≤i≤ny,ny表示序列yg的长度;
步骤5:参照字符索引表d、序列索引字典v和步骤3得到的序列xg,将步骤5得到的转换序列yg进行翻译,具体步骤为:
步骤5.1:构建车牌识别字符串占位集合s,并补充与xg相同元素个数的空字符cnull,使得s={sj|j=1,2,…,nx,sj=cnull},其中sj表示字符集合s的第j个字符,初始化为cnull;
步骤5.2:遍历序列xg和yg,对j=1,2,…,nx,若kj<ny,kj<nx且kj≠19,,则在字符字典d中查找gj所代表的字符a,并用a替换集合s中的第kj位元素;其中,gi为序列xg的第j个元素,kj为序列yg的第j个元素;
步骤5.3:删去集合s中所有的cnull后,将集合所有元素按需组成字符串z;
步骤6:返回由步骤5得到车牌识别结果z。
本发明的有益效果是:1)基于深度学习技术,通过训练序列模型使机器自主学习车牌字符的取舍与排列组合规则,减轻了人工设计启发式规则的压力;2)通过大量的数据样本学习,序列模型在多制式车牌的识别问题上更加灵活;3)相比于传统的序列处理方法,诸如隐马尔科夫,本发明能在更长时的依赖中找到序列元素的联系,取得更好的序列转换结果。
附图说明
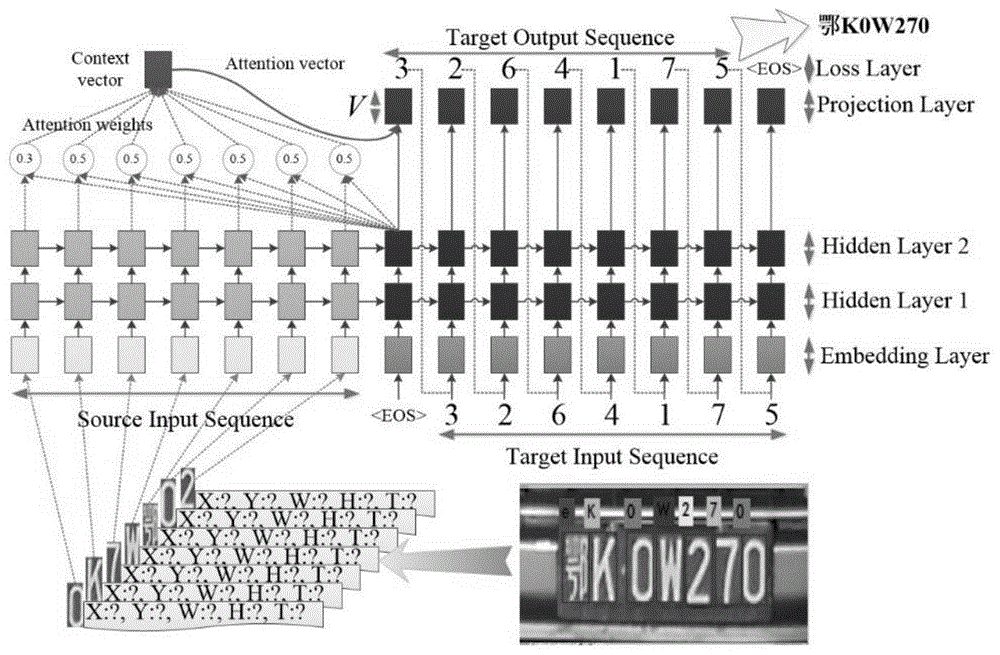
图1为本发明的车牌识别效果示意图;
图2为本发明的部分序列模型训练样本示意图;
图3为本发明的待测试的车牌图像;
图4为本发明的经过步骤3处理的编码序列;
图5为本发明的经过步骤4处理的解码序列。
具体实施方式
本发明示意图如图1所示,下面结合实施例来详细阐述本发明的基于再识别策略的车牌识别方法的具体实施方式。
步骤1:首先准备车牌字符检测数据集,在每一张车牌上标注每一车牌字符的位置矩形框r与类别标签c,c∈d,d为字符索引表;然后基于准备的数据集训练用于车牌字符检测的深度卷积神经网络模型mc;在本实例中,选择官方的yolov3神经网络结构训练得到模型mc;
步骤2:训练用于序列转换的sequence-to-sequence模型ms,具体步骤为:
步骤2.1:将待训练的图像i输入到车牌字符检测网络mc,编码得到候选车牌字符构成的序列x={x1,x2,…,xt},其中xi表示编码序列的第i个字符,1≤i≤t,t表示编码序列的长度,xi是由
步骤2.2:首先构造索引字典v={0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19};然后为编码序列x标注目标解码序列y={y1,y2,…,yl},其中yi表示解码序列的第i个元素,1≤i≤l,l表示解码序列的长度,l=t,yi是xi在实际车牌号码s中的索引值,yi∈v,若
步骤2.3:首先在编码序列x末尾加上结束字符e<eos>=(0,0,0,0,0),在解码序列y末尾加上结束字符d<eos>=0;然后将x加入训练样本集xt,将y加入训练样本集yt;
步骤2.4:对所有的训练图像重复步骤2.1至步骤2.3;在本实例中,序列模型的部分训练样本如图2所示;
步骤2.5:首先设计一个两层的lstm模型,其中每层设置128个隐藏单元;该两层的lstm模型分为编码器和解码器两部分,将上一步骤得到的训练样本集ψ=<xt,yt>按公式(1)训练sequence-to-sequence模型;
其中,o为编码器学习到的单一序列样本x的规则化表示,p(yi|o,y1,...,yi-1)为解码器得到的特定序列元素yi的概率,yi∈v,p(y1,...,yl|x1,...,xt)为将序列x转换为序列y的概率,θ为所训练sequence-to-sequence模型ms的模型参数;
步骤3:将待识别的图像g输入到车牌字符检测网络mc,编码得到候选车牌字符构成的序列xg={u1,u2,…,unx},其中ui表示序列xg的第i个字符,1≤i≤nx,nx表示序列xg的长度;在本实例中,待识别车牌图像如图3所示,得到的编码序列如图4所示;
步骤4:将步骤3得到的序列xg输入步骤2得到的sequence-to-sequence模型ms,得到转换序列yg={v1,v2,…,vny},其中vi表示序列yg的第i个字符,1≤i≤ny,ny表示序列yg的长度;在本实例中,转换序列如图5所示;
步骤5:参照字符索引表d、序列索引字典v和步骤3得到的序列xg,将步骤5得到的转换序列yg进行翻译,具体步骤为:
步骤5.1:构建车牌识别字符串占位集合s,并补充与xg相同元素个数的空字符cnull,使得s={sj|j=1,2,…,nx,sj=cnull},其中sj表示字符集合s的第j个字符,初始化为cnull;在本实例中,cnull=‘-’,s={‘-’,‘-’,‘-’,‘-’,‘-’,‘-’};
步骤5.2:遍历序列xg和yg,对j=1,2,…,nx,若kj<ny,kj<nx且kj≠19,,则在字符字典d中查找gj所代表的字符a,并用a替换集合s中的第kj位元素;其中,gi为序列xg的第j个元素,kj为序列yg的第j个元素;
步骤5.3:删去集合s中所有的cnull后,将集合所有元素按需组成字符串z;在本实例中,z=“0321er”;
步骤6:返回由步骤5得到车牌识别结果z。
- 还没有人留言评论。精彩留言会获得点赞!