一种基于深度强化学习调整电力系统潮流的方法及系统与流程
本发明涉及大电网潮流自动调整领域,并且更具体地,涉及一种基于深度强化学习调整电力系统潮流的方法及系统。
背景技术:
电力系统运行方式是电力系统调度部门编制的指导电力系统运行的总体技术方案,是整个电网稳定安全运行基础,对电网安全经济运行起着举足轻重的作用。随着我国电网建设的迅猛发展和电网规模的显著扩大,特别是特高压交直流混连大电网格局的逐步形成,电力系统安全稳定特性与机理日趋复杂,电网运行控制难度不断加大,电网运行方式的计算量和调整内容也呈规模性地增长。其中,潮流计算是核心工作,因为电力系统静态稳定、暂态稳定等计算都要以各种运行方式下的潮流计算结果为基础。但是各种潮流方式的调整也是整个电力系统运行方式计算中最为耗时的一个环节,目前仍主要由人工来完成。大量方式人员手动将基础潮流调整至目标运行方式,然后进行暂态稳定分析。此项工作过于依赖方式人员的工作经验,且调整的结果受方式人员的主观影响较大,不同人员调整出的结果不唯一;对于缺乏经验的新手来说,需要花费更长的时间才能得出需要的潮流结果,工作效率低下。
鉴于人工调整潮流存在效率低下和过于依赖人员经验等缺点,迫切需要开发一种能够依靠规则来自动实现潮流调整的算法,众多学者和电力工作人员已经开始了相关算法的研究。潮流调整的过程可看成是一个连续的状态转移概率未知的马尔科夫决策过程,而人工智能算法正擅长于求解这类问题,因此可以使用人工智能算法来实现潮流调整的自动化。
技术实现要素:
针对上述问题,本发明提供了一种基于深度强化学习调整电力系统潮流的方法,包括:
获取待调整电力系统目标断面集合,对每个目标断面进行编号,确定每个目标断面的待调整有功功率范围并作为训练目标的输入信息;
记录任意一个目标断面m的初始功率为
随机获取目标断面m编号及目标断面m的传输功率;
针对目标断面m的传输功率确定可调发电机的精细筛选策略,并实时补偿有功功率的变化;
使用基于actor-critic架构的确定性策略梯度算法,以电力系统潮流的状态、目标断面m编号和目标断面m的传输功率作为输入,以精细筛选后的发电机的调整策略作为输出,并对其中的actor网络和critic网络进行训练,训练生成预设调整策略;
训练完成后,对预设调整策略的actor网络输入断面编号值m、目标传输功率值
可选的,初步筛选包括:
获取可调发电机i的有功功率为最大值和最小值时目标断面m的断面功率的正方向调整量
将
可选的,针对目标断面m的传输功率确定可调发电机的精细筛选策略,并实时补偿有功功率的变化,包括:
针对断面m在
引入参数
可选的,当因调整断面有功功率而引起全电网有功功率不平衡时,按照
可选的,生成预设调整策略,具体步骤包括:
s51.针对actor-critic构架,分别为actor和critic构建结构相同且包括n层的深度全连接神经网络,定义actor的输入为状态量s,输出为动作量a,critic的输入为状态量和动作量(s,a),输出为状态动作值q;
所述的状态量s由所有归一化后的可调发电机的有功功率、归一化后的目标断面功率及目标断面编号组成的列向量,动作量a为一个连续的有界的实数并与精细筛选出待调整发电机的可调功率范围按比例映射,状态动作值q为一实数;
s52.随机初始化actor网络的网络参数θμ与critic网络的网络参数θq,用actor网络的网络参数θμ初始化目标actor网络的网络参数θμ’←θμ,用critic网络的网络参数θq初始化目标critic网络的网络参数θq’←θq;
s53.初始化一个预设值为d经验池r,初始化一个ornstein-uhlenbeck过程作为动作噪声noise;
s54.actor根据当前状态s及随机生成的目标信息选择基于当前策略的动作并添加上噪声noise得到动作at,在at的作用下,根据公式:
获取出奖励值rt,状态从st转移到st+1,将st,at,rt,st+1组合为一条经验(st,at,rt,st+1),并将其存放在经验池r中,并为其初始化一个采样概率;
s55.从经验池中依概率抽取n条经验数据,对该n条经验计算总的损失
s56.根据损失l,利用adam算法按梯度下降方向更新critic网络参数θq;
s57.根据公式(4)计算该n条经验计算总的梯度;
s58.根据总梯度,利用adam算法按梯度上升方向更新actor网络的参数θμ;
s59.更新目标critic网络参数θq’←τθq+(1-τ)θq’,更新目标actor网络参数θμ’←τθμ+(1-τ)θμ’;
s510.确定当前所有随机目标的训练回合下电力系统待调整断面功率以预设的精度达到目标值或达到当前训练回合的最大迭代步数t,生成预设调整策略。
本发明还提供了一种基于深度强化学习调整电力系统潮流的系统,包括:
信息获取模块,获取待调整电力系统目标断面集合,对每个目标断面进行编号,确定每个目标断面的待调整有功功率范围并作为训练目标的输入信息;
第一筛选模块,记录任意一个目标断面m的初始功率为
训练目标确定模块,随机获取目标断面m编号及目标断面m的传输功率;
第二筛选模块,针对目标断面m的传输功率确定可调发电机的精细筛选策略,并实时补偿有功功率的变化;
策略生成模块,使用基于actor-critic架构的确定性策略梯度算法,以电力系统潮流的状态、目标断面m编号和目标断面m的传输功率作为输入,以精细筛选后的发电机的调整策略作为输出,并对其中的actor网络和critic网络进行训练,训练生成预设调整策略;
调整模块,训练完成后,对预设调整策略的actor网络输入断面编号值m、目标传输功率值
可选的,初步筛选包括:
获取可调发电机i的有功功率为最大值和最小值时目标断面m的断面功率的正方向调整量
将
可选的,针对目标断面m的传输功率确定可调发电机的精细筛选策略,并实时补偿有功功率的变化,包括:
针对断面m在
引入参数
可选的,当因调整断面有功功率而引起全电网有功功率不平衡时,按照
可选的,生成预设调整策略,具体步骤包括:
s51.针对actor-critic构架,分别为actor和critic构建结构相同且包括n层的深度全连接神经网络,定义actor的输入为状态量s,输出为动作量a,critic的输入为状态量和动作量(s,a),输出为状态动作值q;
所述的状态量s由所有归一化后的可调发电机的有功功率、归一化后的目标断面功率及目标断面编号组成的列向量,动作量a为一个连续的有界的实数并与精细筛选出待调整发电机的可调功率范围按比例映射,状态动作值q为一实数;
s52.随机初始化actor网络的网络参数θμ与critic网络的网络参数θq,用actor网络的网络参数θμ初始化目标actor网络的网络参数θμ’←θμ,用critic网络的网络参数θq初始化目标critic网络的网络参数θq’←θq;
s53.初始化一个预设值为d经验池r,初始化一个ornstein-uhlenbeck过程作为动作噪声noise;
s54.actor根据当前状态s及随机生成的目标信息选择基于当前策略的动作并添加上噪声noise得到动作at,在at的作用下,根据公式:
获取出奖励值rt,状态从st转移到st+1,将st,at,rt,st+1组合为一条经验(st,at,rt,st+1),并将其存放在经验池r中,并为其初始化一个采样概率;
s55.从经验池中依概率抽取n条经验数据,对该n条经验计算总的损失
s56.根据损失l,利用adam算法按梯度下降方向更新critic网络参数θq;
s57.根据公式(4)计算该n条经验计算总的梯度;
s58.根据总梯度,利用adam算法按梯度上升方向更新actor网络的参数θμ;
s59.更新目标critic网络参数θq’←τθq+(1-τ)θq’,更新目标actor网络参数θμ’←τθμ+(1-τ)θμ’;
s510.确定当前所有随机目标的训练回合下电力系统待调整断面功率以预设的精度达到目标值或达到当前训练回合的最大迭代步数t,生成预设调整策略。
本发明可不依赖方式人员的经验,依据目标和既定规则从零开始自动学习潮流调整方案,并且能够实现在一定范围内,以较高的精度连续调整断面的功率。
本发明可以使电力系统运行方式计算的自动化进行成为可能,具有较大的工程应用价值和推广前景。
附图说明
图1为本发明一种基于深度强化学习调整电力系统潮流的方法流程图;
图2为本发明一种基于深度强化学习调整电力系统潮流的系统结构图。
具体实施方式
现在参考附图介绍本发明的示例性实施方式,然而,本发明可以用许多不同的形式来实施,并且不局限于此处描述的实施例,提供这些实施例是为了详尽地且完全地公开本发明,并且向所属技术领域的技术人员充分传达本发明的范围。对于表示在附图中的示例性实施方式中的术语并不是对本发明的限定。在附图中,相同的单元/元件使用相同的附图标记。
除非另有说明,此处使用的术语(包括科技术语)对所属技术领域的技术人员具有通常的理解含义。另外,可以理解的是,以通常使用的词典限定的术语,应当被理解为与其相关领域的语境具有一致的含义,而不应该被理解为理想化的或过于正式的意义。
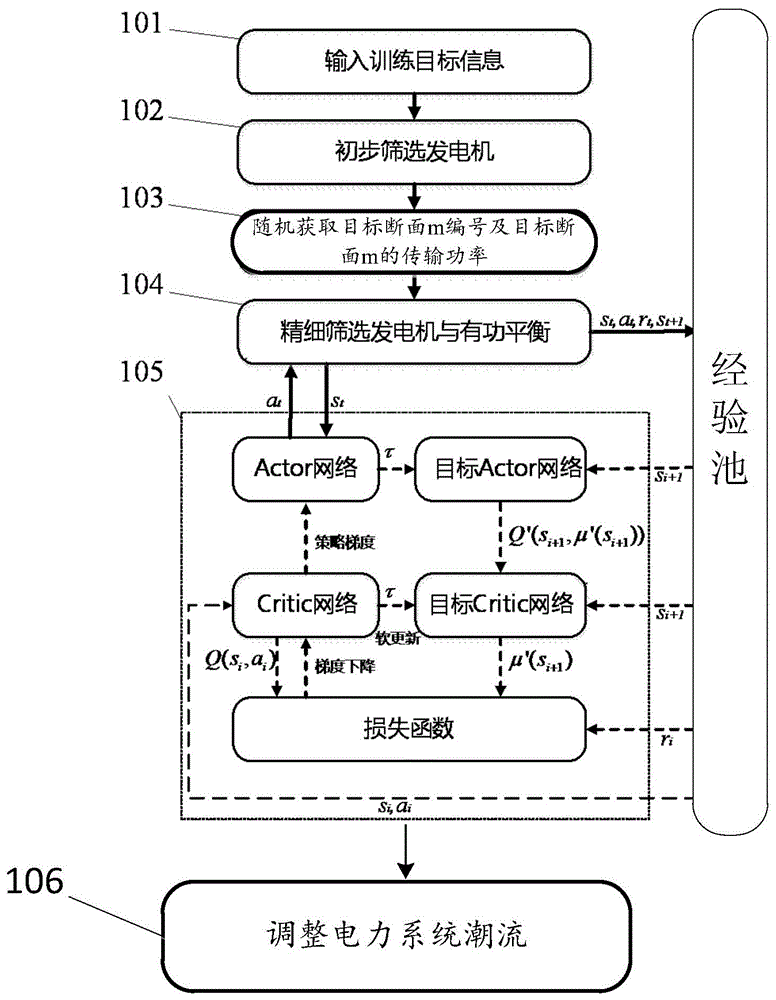
本发明提供了一种基于深度强化学习调整电力系统潮流的方法,如图1所示,包括:
步骤101,获取待调整电力系统目标断面集合,对每个目标断面进行编号,确定每个目标断面的待调整有功功率范围并作为训练目标的输入信息;
步骤102,记录任意一个目标断面m的初始功率为
初步筛选包括:
获取可调发电机i的有功功率为最大值和最小值时目标断面m的断面功率的正方向调整量
将
步骤103,随机获取目标断面m编号及目标断面m的传输功率;
步骤104,针对目标断面m的传输功率确定可调发电机的精细筛选策略,并实时补偿有功功率的变化,包括:
针对断面m在
引入参数
当因调整断面有功功率而引起全电网有功功率不平衡时,按照
步骤105,使用基于actor-critic架构的确定性策略梯度算法,以电力系统潮流的状态、目标断面m编号和目标断面m的传输功率作为输入,以精细筛选后的发电机的调整策略作为输出,并对其中的actor网络和critic网络进行训练,训练生成预设调整策略,具体包括:
s51.针对actor-critic构架,分别为actor和critic构建结构相同且包括n层的深度全连接神经网络,定义actor的输入为状态量s,输出为动作量a,critic的输入为状态量和动作量(s,a),输出为状态动作值q;
所述的状态量s由所有归一化后的可调发电机的有功功率、归一化后的目标断面功率及目标断面编号组成的列向量,动作量a为一个连续的有界的实数并与精细筛选出待调整发电机的可调功率范围按比例映射,状态动作值q为一实数;
s52.随机初始化actor网络的网络参数θμ与critic网络的网络参数θq,用actor网络的网络参数θμ初始化目标actor网络的网络参数θμ’←θμ,用critic网络的网络参数θq初始化目标critic网络的网络参数θq’←θq;
s53.初始化一个预设值为d经验池r,初始化一个ornstein-uhlenbeck过程作为动作噪声noise;
s54.actor根据当前状态s及随机生成的目标信息选择基于当前策略的动作并添加上噪声noise得到动作at,在at的作用下,根据公式:
获取出奖励值rt,状态从st转移到st+1,将st,at,rt,st+1组合为一条经验(st,at,rt,st+1),并将其存放在经验池r中,并为其初始化一个采样概率;
s55.从经验池中依概率抽取n条经验数据,对该n条经验计算总的损失
s56.根据损失l,利用adam算法按梯度下降方向更新critic网络参数θq;
s57.根据公式(4)计算该n条经验计算总的梯度;
s58.根据总梯度,利用adam算法按梯度上升方向更新actor网络的参数θμ;
s59.更新目标critic网络参数θq’←τθq+(1-τ)θq’,更新目标actor网络参数θμ’←τθμ+(1-τ)θμ’;
s510.确定当前所有随机目标的训练回合下电力系统待调整断面功率以预设的精度达到目标值或达到当前训练回合的最大迭代步数t,生成预设调整策略。
步骤106,训练完成后,对预设调整策略的actor网络输入断面编号值m、目标传输功率值
本发明还提供了一种基于深度强化学习调整电力系统潮流的系统200,如图2所示,包括:
信息获取模块201,获取待调整电力系统目标断面集合,对每个目标断面进行编号,确定每个目标断面的待调整有功功率范围并作为训练目标的输入信息;
第一筛选模块202,记录任意一个目标断面m的初始功率为
初步筛选包括:
获取可调发电机i的有功功率为最大值和最小值时目标断面m的断面功率的正方向调整量
将
训练目标确定模块203,随机获取目标断面m编号及目标断面m的传输功率;
第二筛选模块204,针对目标断面m的传输功率确定可调发电机的精细筛选策略,并实时补偿有功功率的变化,包括:
针对断面m在
引入参数
当因调整断面有功功率而引起全电网有功功率不平衡时,按照
策略生成模块205,使用基于actor-critic架构的确定性策略梯度算法,以电力系统潮流的状态、目标断面m编号和目标断面m的传输功率作为输入,以精细筛选后的发电机的调整策略作为输出,并对其中的actor网络和critic网络进行训练,训练生成预设调整策略,具体包括:
s51.针对actor-critic构架,分别为actor和critic构建结构相同且包括n层的深度全连接神经网络,定义actor的输入为状态量s,输出为动作量a,critic的输入为状态量和动作量(s,a),输出为状态动作值q;
所述的状态量s由所有归一化后的可调发电机的有功功率、归一化后的目标断面功率及目标断面编号组成的列向量,动作量a为一个连续的有界的实数并与精细筛选出待调整发电机的可调功率范围按比例映射,状态动作值q为一实数;
s52.随机初始化actor网络的网络参数θμ与critic网络的网络参数θq,用actor网络的网络参数θμ初始化目标actor网络的网络参数θμ’←θμ,用critic网络的网络参数θq初始化目标critic网络的网络参数θq’←θq;
s53.初始化一个预设值为d经验池r,初始化一个ornstein-uhlenbeck过程作为动作噪声noise;
s54.actor根据当前状态s及随机生成的目标信息选择基于当前策略的动作并添加上噪声noise得到动作at,在at的作用下,根据公式:
获取出奖励值rt,状态从st转移到st+1,将st,at,rt,st+1组合为一条经验(st,at,rt,st+1),并将其存放在经验池r中,并为其初始化一个采样概率;
s55.从经验池中依概率抽取n条经验数据,对该n条经验计算总的损失
s56.根据损失l,利用adam算法按梯度下降方向更新critic网络参数θq;
s57.根据公式(4)计算该n条经验计算总的梯度;
s58.根据总梯度,利用adam算法按梯度上升方向更新actor网络的参数θμ;
s59.更新目标critic网络参数θq’←τθq+(1-τ)θq’,更新目标actor网络参数θμ’←τθμ+(1-τ)θμ’;
s510.确定当前所有随机目标的训练回合下电力系统待调整断面功率以预设的精度达到目标值或达到当前训练回合的最大迭代步数t,生成预设调整策略。
调整模块206,训练完成后,对预设调整策略的actor网络输入断面编号值m、目标传输功率值
本发明可不依赖方式人员的经验,依据目标和既定规则从零开始自动学习潮流调整方案,并且能够实现在一定范围内,以较高的精度连续调整断面的功率。本发明可以使电力系统运行方式计算的自动化进行成为可能,具有较大的工程应用价值和推广前景。
- 还没有人留言评论。精彩留言会获得点赞!