一种基于轨迹划分与优先队列的轨迹简化方法与流程
本发明涉及移动计算技术领域,特别涉及一种基于轨迹划分与优先队列的轨迹简化方法。
背景技术:
2019年巴塞罗那大会上阿拉伯联合酋长国的阿联酋电信(etisalat),豪掷千金直接签下了国家级5g部署大单。日本软银(softbank))futurestride实验室实现了三车组编组单人驾驶,充分展示了5g通讯的优势。5g通信具有高速度低延时的特性。这些特性在无人驾驶等方面有重要的作用。但是,无论是5g还是传统卫星通信,它们的成本都很高。而通用采样的方法是在移动对象上安装传感器,并且利用现有的卫星或地面基站配合电子地图技术等,在一定时间内发送目标所在的位置信息与时间信息。由于技术条件限制,所获得的位置和时间信息是离散的。而精确的轨迹,采样率往往较高(每5秒一个采样点),造成轨迹数据集非常庞大,给轨迹数据的传输、存储、分析挖掘有效信息等方面带来极大的困难。因此,有必要在给定的误差情况下对原始轨迹数据进行简化。
移动对象轨迹数据的存储与挖掘分析是移动计算领域中的重要课题。在自动驾驶及智能交通中有广泛应用。其中,移动对象轨迹简化是该技术领域中的重要组成部分。尽管人们已提出了许许多多的轨迹简化算法,但这些算法都存在一定的局限性。其中一个经典轨迹简化算法是squish算法。算法squish如下所示:
输入:原始轨迹traw,优先队列大小size;
输出:简化后的轨迹tsim;
1、初始化一个长度为size的优先队列buffer,同时记录点与权值;
2、forpiintraw://遍历整个原始轨迹;
3、将pi压入buffer最后一个点并且置π(pi)=∞//π(pj)轨迹点的冗余度,权值。
4、π(pi-1)=sed(pi-2pi-1pi)//将缓冲区中的倒数第二个点赋初值为该点与其前驱后继
//点形成的同步欧几里得距离;
5、iflen(buffer)>size://缓冲区已满,len()为序列的长度;
6、找出π(pj)0<j<size最小的点;
7、del(pj);
8、将π(pj)0<j<size的值直接加到π(pred(pj))andπ(succ(pj));
9、returntsim=buffer;
squish算法是一个在线算法,将轨迹中的点逐个实时输入。另外需要输入的是缓冲区(优先队列大小)size,这个缓冲区被称为优先队列。最初,所有采集的轨迹点都存入缓冲区中,直到缓冲区充满。一旦数据量超出缓冲区,向缓冲区中存入任何一个点都需要删除缓冲区内已有的一个点。选出的被删除的点是包含“信息”很少或不包含“信息”的点。即信息高度冗余的点。原始的基于优先队列的轨迹压缩算法,当一个点从优先队列中移除时,增加它的邻近点的优先度。这种方法是一种很好的近似。统计上来讲运动轨迹可视为一个马尔科夫链,所以一个点只受其前驱影响,只会影响它的后继。但是实际情况复杂度远比假设情况严重,随着越来越多的点从缓冲区中移除,会不可避免的出现误差传播。所以该算法缺陷也是十分明显的。过于粗糙的冗余度分配方式导致系统性的误差持续积累。实际使用中在较高的简化比时该算法的性能可能相当差。更加突出的一个问题是一般的简化算法都会让用户自己定义容差范围,来给最终的结果一个指导性的误差范围而本算法则没有。不符合通常的使用习惯,使得用户自由程度相对较低。
为了解决原始基于优先队列的轨迹压缩算法中,可能出现的误差积累,在较高的简化率或面对较大的轨迹时,可能出现的性能急剧衰减,以及缺少具有指导意义的容差指定,用户的自由度较低,研发一种基于轨迹划分与优先队列的轨迹简化算法实为必要。
技术实现要素:
本发明的目的在提供一种基于轨迹划分与优先队列的轨迹简化方法,它是针对squish算法存在的不足加以改良,首先对于输入的轨迹按照其每个轨迹段的平均速度进行聚类,将原始轨迹中的速度特征,集中地反应出来,对原始轨迹的运动状态进行大致分类,得到速度范围表。再依据这张表对原始轨迹中的轨迹段进行标定,形成一条已经标定好的轨迹,然后对这个标定好的轨迹依据,依据分类回归树进行子轨迹划分。对于划分好的子轨迹进行压缩,再经合并后成为压缩结果。本发明采用了k-means聚类算法,分类回归树算法,自适应参数生成,得到更有效的基于优先队列的轨迹压缩算法。
为了达到上述目的,本发明通过以下技术方案实现:
一种基于轨迹划分与优先队列的轨迹简化方法,该方法包含以下步骤:
s1、输入的原始轨迹经过预处理后,对原始轨迹中的每个轨迹段进行求取平均速度的操作;
s2、对步骤s1的整个轨迹的平均速度进行聚类划分,生成类名与速度范围表;
s3、基于所述类名与速度范围表,对原始轨迹中的所有轨迹段的平均速度进行标定,形成由标签组成的轨迹段集合;
s4、将标定后的轨迹段集合进行子轨迹的划分,直至划分的每个子段的基尼指数符合预先设定的阈值;
s5、基于所述步骤s4中划分好的子轨迹,生成简化率及相应的容差;
s6、将所述步骤s5中自适应生成的简化率和容差参数与子轨迹段一同传入基于优先队列的轨迹简化算法中进行简化处理;
s7、将每个子轨迹的简化结果进行合并,得到最终的结果。
优选地,所述步骤s1中,预处理的过程包含:
将原始轨迹的数据采用pi=(xi,yi,ti)的统一形式,其中i表示原始轨迹的第i个轨迹点,pi表示第i个轨迹点的空间位置坐标,xi,yi分别表示pi经过投影到二维平面上的横、纵坐标,ti表示该坐标点的采集时刻即时间戳;
输入的原始轨迹表示为:
其中,n为轨迹所含轨迹点的个数,即len(traw),
优选地,所述步骤s2中,每段轨迹的平均速度为:
其中,
整个轨迹的所有轨迹段的平均速度velocity_tab记为:
优选地,所述步骤s2中,将整个轨迹的所有轨迹段的平均速度
velocity_tab采用k-means算法进行聚类划分,包含:
通过遍历一定阈值范围内的数值,当作聚类系数k值,分别计算轮廓系数,将其中轮廓系数最小的k值作为实际划分时使用的k值,在随着k值的修正,k-means算法的结果将不断修正至最优解。
优选地,所述步骤s2中,依据所述类名与速度范围表,对整个轨迹的所有轨迹段的平均速度velocity_tab进行标记生成lable_tab,形成由标签组成的轨迹段集合。
优选地,所述步骤s4中,将标定后的所述轨迹段集合采用分类回归树的方法进行子轨迹的划分,包含:通过遍历整个轨迹,基于轨迹段集合依次在每一处进行二分划分,并计算在划分前后的基尼指数的变化,选择基尼指数减小程度最大的划分方式为最佳的划分方式;
其中,基尼指数计算公式如下:
式中,tsample表示示例轨迹;split(i)表示在i点处划分;t1-i表示轨迹中第1个点到第i个点组成的轨迹,ti-n表示第i个点到第n个点组成的轨迹;gini(t1-i)以及gini(ti-n)为对应轨迹的基尼指数;
公式(4)是一个递归式,递归地进行子轨迹的划分,直至每个子轨迹段的基尼指数小于所述预先设定的阈值时,结束递归过程。
优选地,所述步骤s5中,基于所述步骤s4中划分好的子轨迹,依据最小描述长度原则,生成适配的参数简化率sizeε与容差errorε;其中,sizeε表示简化轨迹的轨迹点数,errorε表示最大同步欧式距离。
优选地,所述步骤s5中,进一步包含:
s51、构建简化轨迹,其中,初始的简化轨迹为轨迹的起始点至终点组成的直线段;
s52、寻找输入的原始轨迹中与简化轨迹存在最大同步欧式距离的寻找点,该最大同步欧式距离记为errorε,其中,初始值的最大同步欧式距离记法为errormax;
s53、将步骤s52中的所述寻找点加入简化轨迹中,并计算平衡参数fix:
式中,sizeε为简化轨迹的轨迹点数,sizemax为输入的原始轨迹的轨迹点数;
s54、遍历整个原始轨迹,记录得到平衡参数fix的最小值min(fix),此时对应的sizeε与errorε为生成的轨迹最佳参数。
优选地,所述步骤s6中,所述基于优先队列的轨迹简化算法包含以下过程:
s61、初始化,构造长度为输入参数sizeε的优先队列,同时存储轨迹点与优先度,优先队列起始点与终点的优先度始终为无穷大;
s62、将轨迹点不断地压入优先队列中,每加入一个点,当前的点成为优先队列的新的终点,原先终点通过计算其与相邻的前后两个点组成的轨迹段的同步欧氏距离作为原先终点优先度;
s63、判断步骤s62中计算的原先终点的优先度是否小于输入的参数errorε,若是,则直接在优先队列中删掉该原先终点,否则,保留该原先终点;
s64、在添加新的点之后,若此时优先队列的长度大于size,则在该优先队列中寻找最小优先度的点并将其删除,同时将该点的优先度依照与其前驱点与后继点的距离的反比分配给其前驱点与后继点的优先度;
s65、重复上述步骤s63和s64添加点的过程,直至处理到输入的原始轨迹的结尾;
s66、对得到的新的优先队列再次计算每个点的同步欧氏距离并与最大同步欧式距离errorε比较,删除小于errorε的点,剩余点组成的轨迹为最终的简化轨迹。
所述步骤s64中,进一步包含:
对于轨迹点pi、pj、pk,如果delpj且i<j<k:
其中,π(pi)为pi的优先度,π(pj)是pj的优先度,π(pk)是pk的优先度;
与现有技术相比,本发明的有益效果为:原始的简化算法的初始参数与数学信息紧密相连是优先队列的大小,需要使用者在一定的经验积累之后才能较为准确的提出;而本发明新的算法所需的初始参数是基尼指数阈值这是一个对轨迹划分零散程度的感性描述;本发明只要对轨迹有初步的了解便可以直接给出;此外在压缩结果的方面,本发明的atns算法一定程度上避免了原始算法的在较大的轨迹集上性能衰减的问题,同时算法在空间误差、同步欧氏距离误差方面也有较好的表现;总体而言,本发明所提出的基于轨迹划分与优先队列的简化算法使用效果较好,具有很高的实用价值。
附图说明
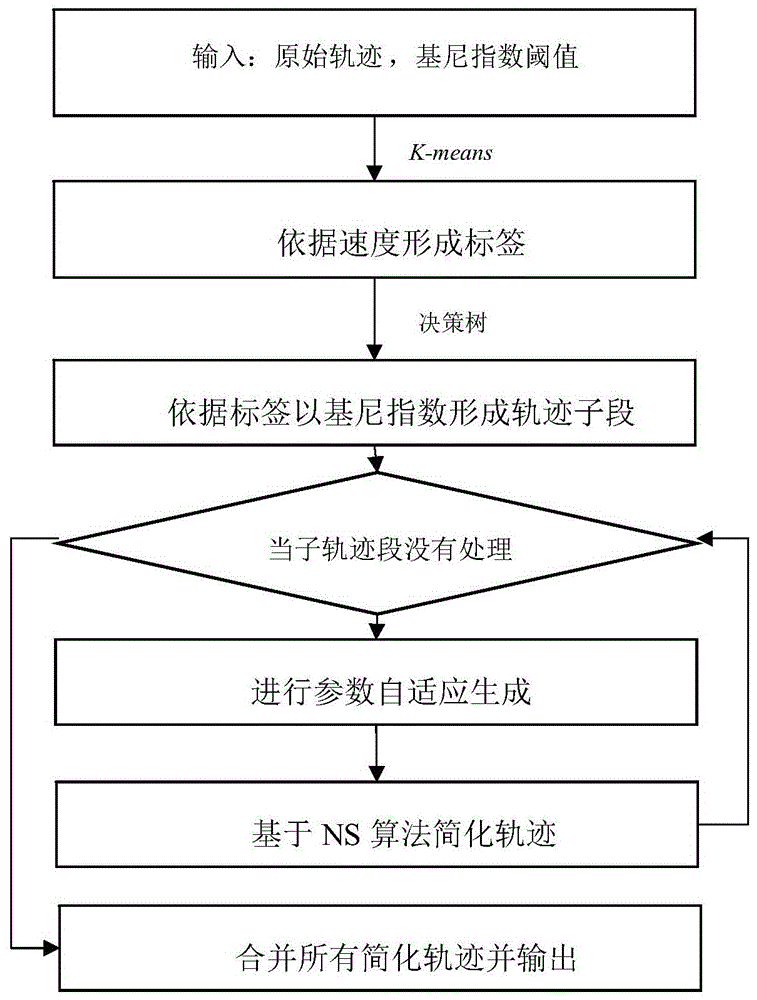
图1为本发明的基于轨迹划分与优先队列的轨迹简化方法atns流程图;
图2为本发明的改进算法(atns)与原始算法(squish)的运行时间的比较示意图;
图3为本发明的改进算法(atns)与原始算法(squish)的同步欧式距离误(sed)差的比较示意图;
图4为本发明的改进算法(atns)与原始算法(squish)的空间误差(ped)的比较示意图;
图5为本发明例举的一种类名与速度范围表。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明公开了一种基于轨迹划分与优先队列的轨迹简化方法atns,该方法包含以下步骤:
s1、输入原始轨迹以及基尼指数阈值,并对经过预处理的原始轨迹进行轨迹段的平均速度的计算;
s2、对于上述计算结果进行基于k-means算法的聚类划分处理,生成类名与速度范围表;
s3、基于步骤s2中产生的类名与速度范围表,对原始轨迹中的轨迹段的平均速度进行标定,形成一组由标签组成的轨迹段集合;
s4、对于标定后的轨迹段集合,采用分类回归树的方法进行子轨迹的划分,直至划分的每个子段的基尼指数符合事先规定好的阈值;
s5、对于步骤s4中划分好的子轨迹,依据最小描述长度原则,生成合适的参数sizeε与errorε;其中,sizeε为简化轨迹的轨迹点数(也称简化率),errorε为最大同步欧式距离(也称容差)。
s6、将步骤s5自适应生成的参数与子轨迹段一同传入基于优先队列的轨迹简化算法中,进行简化处理;
s7、将每个子轨迹的简化结果进行合并,形成结果。
所述步骤s1中,数据预处理包含以下:
对于原始轨迹的数据往往没有一种统一的形式,但是为了方便计算,本算法推荐采用形如pi=(xi,yi,ti)的形式表示,i表示原始轨迹的第i个关键点,pi表示第i个关键点的空间位置坐标,xi,yi分别表示pi经过投影到二维平面上的横、纵坐标;位置信息xi,yi可以依照地理知识或规定的电子地图直接得到;最后一项ti表示该坐标点的采集时刻即时间戳;由于数据采集往往源于gps传感器本算法推荐以世界标准时间的1980年1月6日零时作为零点,之后的时间戳均是在该零点上累加而成,自此采用统一的格式才能作为算法的输入。
所述步骤s2中,所述k-means算法(k均值聚类算法)具体包含以下:通过遍历一定阈值范围(即原始轨迹中可能包含的运动方式如:步行、跑步、乘车等的数目)内的数值,当作聚类系数k值,分别计算轮廓系数,将其中轮廓系数最小的k值作为实际划分时使用的k值(即最佳聚类系数);而在随着k值的修正,k-means算法的结果也将不断修正至最优解。
对于输入的原始轨迹traw可以表述为:
其中,n为轨迹所含轨迹点的个数即len(traw),
其中,
则对于整个轨迹的平均速度有:
本实施例中,对于整个轨迹的平均速度velocity_tab使用聚类方法,无论是k-means算法还是轮廓系数的计算、选优,均可简单直接地使用tensorflow与python的包来实现,经过这个步骤处理之后生成类似速度范围-类名的表格,如图5所示的速度值与误差阈值的表格;依照这个表格对velocity_tab进行标记生成lable_tab,形如(000111333...),即各个轨迹段标签的组合,其中的数字均为类名。
所述s4的划分子轨迹的算法具体为:
通过遍历整个轨迹,基于lable_tab(即步骤s3中通过标定之后的由标签组成的轨迹段集合),依次在每一处进行二分划分,并计算在划分前后的基尼指数的变化,选择基尼指数减小程度最大的划分方式为最佳的划分方式。
基尼指数计算公式如下:
式中,tsample表示示例轨迹;split(i)为在i点处划分;t1-i表示轨迹中第1个点到第i个点组成的轨迹,ti-n同理,表示第i个点到第n个点组成的轨迹;gini(t1-i)以及gini(ti-n)为对应轨迹的基尼指数;
上述公式(4)是一个递归式,则递归地进行子轨迹的划分,直至每个子轨迹段的基尼指数小于规定的阈值(即算法开始时输入的基尼指数阈值,该阈值通过对原始轨迹想要的切分程度选取0-1范围内的数字)时,结束递归过程。
所述步骤s5中,自适应参数的生成步骤如下:
s51、构建简化轨迹;其中,初始的简化轨迹为轨迹的起始点至终点组成的直线段;
s52、寻找输入的原始轨迹中与简化轨迹有着最大同步欧式距离的点,这个最大同步欧式距离记为errorε(也称容差),其中,初始值的最大同步欧式距离记法为errormax;
s65、将步骤s52中寻找的这个点加入简化轨迹中,计算平衡参数fix:
其中,sizeε为简化轨迹的轨迹点数,sizemax为输入的原始轨迹的轨迹点数。
s54、遍历整个原始轨迹,记录得到平衡参数fix的最小值min(fix),此时对应的sizeε与errorε为生成的轨迹最佳参数。
所述步骤s6中,所述基于优先队列的轨迹简化算法如下:
s61、初始化,构造长度为输入参数sizeε的优先队列,可以同时存储轨迹点与优先度,该优先队列起始点与终点的优先度始终为无穷大;
s62、将轨迹点不断地压入优先队列中,每加入一个点,该当前的点成为优先队列的新的终点,原先终点通过计算它与紧邻的前后两个点组成的轨迹段的同步欧氏距离作为原先终点优先度;
s63、判断步骤s62中计算的原先终点的优先度是否小于输入的参数errorε,若是,则直接在优先队列中删掉原先的终点,否则,保留这个点。
s64、若在添加新的点之后优先队列的长度大于参数sizeε,则在优先队列中寻找最小优先度的点将它删除,同时将该点的优先度依照与其前驱点与后继点的距离的反比分配给其前驱点与后继点的优先度。
所述步骤s64中,对于轨迹点pi、pj、pk,如果delpj且i<j<k:
其中,此处的π(pi)为pi的优先度,π(pj)是pj的优先度,π(pk)是pk的优先度;
s65、重复上述步骤s63和s64添加点的过程,直至处理到输入的原始轨迹的结尾;
s66、对得到的新的优先队列再次计算每个点的同步欧氏距离与最大同步欧式距离errorε比较,删除小于errorε的点,剩余点组成的轨迹为最终的简化轨迹。
如图2所示为本发明的改进算法(atns)与原始算法(squish)的运行时间的比较示意图,横坐标为轨迹,纵坐标为运行时间。由图可见,在运行时间的数量级上两者差异并不大而改进算法相对有优势。
如图3所示为本发明的改进算法(atns)与原始算法(squish)的同步欧式距离误差(sed)的比较示意图,横坐标为轨迹,纵坐标为同步欧式距离误差。由图可见,两个算法随数据集的增大,误差积累也在增大但是改进算法表现更优。
如图4所示为本发明的改进算法(atns)与原始算法(squish)的空间误差(ped)的比较示意图,横坐标为轨迹,纵坐标为空间误差。由图可见,两个算法随数据集的增大,误差积累也在增大但是改进算法表现更优。
综上所述,本发明的atns算法一定程度上避免了原始算法的在较大的轨迹集上性能衰减的问题,同时算法在空间误差、同步欧氏距离误差方面也有较好的表现;总体而言,本发明所提出的基于轨迹划分与优先队列的简化算法使用效果较好,具有很高的实用价值。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!