一种基于皮尔逊相关系数的语义视觉词典优化方法与流程
本发明涉及视觉词典优化技术领域,特别是涉及一种基于皮尔逊相关系数的语义视觉词典优化方法。
背景技术:
一直以来图像分类技术备受国内外众多学者的关注,其市场与社会应用价值也得到了人们的肯定。和文本信息不同的是,图像与视频信息具有更大的信息量和更难以理解的内容,要想使计算机像人类一样去理解一幅图像和一段视频还具有较大的难度。在现实生活中,人们通过眼睛去获得图像所包含的信息,然后将获取到的信息经过大脑来进行处理,人类大脑会去除掉那些噪声或者无用的信息,保留相应的图像信息。当下一次碰见同种类别的图像时,大脑就会做出相应的反应,对图像进行准确的识别。在人工智能领域,对一幅图像进行识别与分类,就要通过计算机对其进行相应的训练。在训练过程中,第一步就是要将获取到的图像信息输入到计算机中;然后计算机和人脑一样会对图像信息进行相应的处理,当下一次有同种类别的图像再次输入时,计算机就会根据先验知识对其进行识别。然而人脑的复杂程度是人难以想象的,让计算机去模拟人脑还有相当长的路要走。
在图像分类中,要获取视觉短语,首先必须对图像进行特征的提取,然后通过对提取到的图像特征进行相应算法的处理,比如聚类算法、高斯混合模型等,最后才能得到视觉短语。然而过大的视觉词典会使得图像分类的时间复杂度增加,而且对一幅图像进行分类或者识别,难免会有一些图像噪声对分类或者识别效率产生影响。这些图像噪声不仅会使图像的分类精度下降,而且会使视觉词典的规模变得较大,过大的视觉词典会增加计算机分类的时间代价。
本发明主要是基于机器视觉和数字图像处理技术,通过提取图像的颜色、形状和纹理特征,并使用加速鲁棒特征算法(surf)提取图像动态特征,使用精确欧式局部敏感哈希聚类算法(e2lsh)对获取的动态特征聚类,引入皮尔逊相关系数优化视觉词典。优化后构建的语义视觉词典对图像进行分类提高了图像的分类性能,减小了运算的复杂度,缩短运算时间,同时提高了分类的准确性。
技术实现要素:
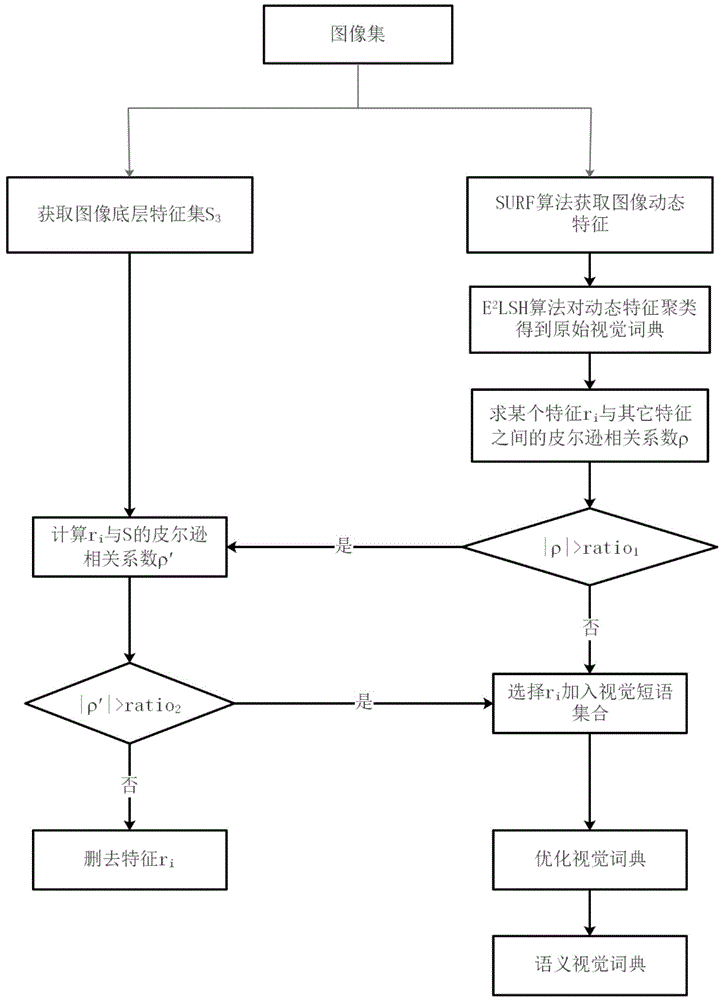
本发明的目的是提供一种基于皮尔逊相关系数的语义视觉词典构建方法。本发明首先是通过提取图像的颜色、形状和纹理特征和用surf算法来提取图像的动态特征,再通过e2lsh聚类算法对获取的图像动态特征聚类,提取相关描述视觉短语,从而构建原始视觉词典,引用皮尔逊相关系数优化视觉词典。
一种基于皮尔逊相关系数的语义视觉词典构建方法,其特征在于包括以下步骤:
步骤a、使用加速鲁棒特征算法提取图像动态特征r={r1,r2,…,ri,…,rn-1,rn},同时提取基于图像颜色、形状和纹理的图像底层特征集s={s1,s2,s3},s1,s2,s3分别为图像颜色、形状和纹理特征;
步骤b、使用精确欧式局部敏感哈希聚类算法对获取的图像动态特征聚类,得到原始视觉词典;
步骤c、采用皮尔逊相关系数相关度求取原始视觉词典中视觉短语间相关度大小|ρn|,设定阈值ratio1,若|ρn|<ratio1,将此视觉短语加入新建的视觉短语集合;
步骤d、若|ρn|≥ratio1,再将此视觉短语对应的动态特征与图像底层特征——颜色、形状、纹理特征再求取皮尔逊相关度|ρ′n|,设定阈值ratio2,若|ρ′n|>ratio2,留下此视觉短语加入视觉短语集合,优化原始视觉词典中的视觉短语,构建新的语义视觉词典。
所述步骤b包括:
步骤b1、用加速鲁棒特征算法提取图像动态特征构成动态特征集r={r1,r2,…,ri,…,rn-1,rn},其中,ri是图像的一个动态特征,n为特征集r中特征个数;
步骤b2、从e2lsh聚类算法中的函数集g中随机选取一个位置敏感函数g;
步骤b3、用位置敏感函数g求取图像动态特征集r中图像特征ri对应的k维向量g(ri);
步骤b4、计算ri的主哈希值h1(g(ri))和次哈希值h2(g(ri)),将r中主、次哈希值都相同的动态特征放入同一个桶bk中,bk即是视觉短语;
步骤b5、求取所有图像动态特征的桶bk构成原始视觉词典tg={b1,b2,…,bk,…,bz}。
所述步骤c包括:
步骤c1、对原始视觉词典tg={b1,b2,…,bk,…,bz}中的任意一个视觉短语bk,根据公式
步骤c2、对相关系数矩阵hk降序排序;
步骤c3、设定阈值ratio1,对降序后的相关系数矩阵hk,搜索视觉短语,若|ρn|<ratio1,则将该视觉短语加入新建的视觉短语集合bg={b1,b2,…,bk,…,bm}中。
步骤c所述的设定阈值ratio1的值为(0.6,0.7)。
步骤d所述的设定阈值ratio2的值为(0.5,0.7)。
与现有技术相比,本发明考虑了使用surf算法考虑到图像的动态特征,利用皮尔逊相关系数度量了动态特征之间的相关度大小,从而降低计算图像表示的维度,更能准确表示图像特征的空间分布信息;同时将图像的底层特征和动态特征使用皮尔逊相关系数度量,避免将一些重要的特征被删去,构建维度小却描述更精准的语义视觉词典,解决了传统语义词典中语义鸿沟和冗余的问题,优化后的视觉词典能减小后续图像分类运算的复杂度,缩短运算时间,同时提高了分类的准确性。
附图说明
图1为基于皮尔逊相关系数的语义视觉词典构建方法流程图。
具体实施方式
下面结合附图对本发明进一步说明。
1、假设训练图像集为d=[d1,d2,…,di,…,dn],其中di表示第i幅图像。
2、使用surf算法提取图像动态特征集r={r1,r2,…,ri,…,rn-1,rn},其中,ri是图像的一个动态特征,n为动态特征集r中特征个数;
3、使用精确欧式局部敏感哈希聚类算法对获取的图像动态特征聚类,生成哈希表tg={b1,b2,…,bk,…,bz},其中bk表示哈希表中第k个桶,z表示哈希表中桶的总个数,哈希表tg完成对图像动态特征的一个特定划分,哈希表tg={b1,b2,…,bk,…,bz}就是原始视觉词典。具体步骤如下:
a、从e2lsh聚类算法中函数集g中随机选取一个位置敏感函数g;
b、用位置敏感函数g求取图像动态特征集r中动态特征ri对应的k维向量g(ri);
c、计算ri的主哈希值h1(g(ri))和次哈希值h2(g(ri)),将r中主、次哈希值都相同的动态特征放入同一个桶bk中,bk即是视觉短语;
d、求取所有图像动态特征的桶bk构成原始视觉词典tg={b1,b2,…,bk,…,bz}。
4、采用皮尔逊相关系数相关度作为原始视觉词典中视觉短语间相关度大小的判定方式,取原始视觉词典tg中的的任意一个视觉短语bk,求取该视觉短语与原始视觉词典中其它视觉短语之间的相关系数,在皮尔逊相关系数公式(1)中,
其中,ρ(x,y)代表的意义是两个不同的图像动态特征向量x和y的线性相关的强弱程度,其中包含-1≤ρ(x,y)≤1,若ρ(x,y)=0,表示两个特征向量非线性相关,ρ(x,y)的绝对值越大表明相关性越强,即相关度越大。设定一个阈值ratio1,作为判定依据,得到相关度比阈值小的其他视觉短语,新建视觉短语集合。具体步骤如下:
a、对原始视觉词典tg={b1,b2,…,bk,…,bz}中的任意一个视觉短语bk,根据公式(1)计算该特征与视觉短语集合中其它局部特征之间的相关系数|ρn|,得到相关系数矩阵hk=[|ρ1|,…,|ρn|,…,|ρz-1|];
b、对相关系数矩阵hk降序排序;
c、设定阈值ratio1=0.65,对降序后的相关系数矩阵hk,搜索视觉短语集合,若|ρn|<ratio1,则将该视觉短语加入新建的视觉短语集合bg={b1,b2,…,bk,…,bm}中;
5、为避免将一些重要的特征删去,若|ρn|≥ratio1,再将此视觉短语对应的动态特征与图像底层特征——颜色、形状、纹理特征再求取皮尔逊相关度|ρ′n|,设定阈值ratio2,若|ρ′n|>ratio2,留下此视觉短语加入视觉短语集合,优化原始视觉词典中的视觉短语,构建新的语义视觉词典。具体步骤如下:
a、求出图像底层特征集s={s1,s2,s3},s1,s2,s3分别为图像颜色、形状和纹理特征,计算ri与底层特征集s之间的皮尔逊相关系数|ρ′n|=[|ρ′1|,|ρ′2|,|ρ′3|];
b、设定阈值ratio2=0.6,若|ρ′n|>ratio2,则将该视觉短语加入视觉短语集合bg中,从而得到最终优化后的语义视觉词典。
- 还没有人留言评论。精彩留言会获得点赞!