一种基于试卷的英语作文自动评阅的方法与流程
本发明涉及nlp自然语言处理领域,具体为一种基于试卷的英语作文自动评阅的方法。
背景技术:
随着社会的发展,考试的形式也在跟着发生改变,从形式到内容,各个方面。在传统的考试模式中,一场考试的组织流程周期是很长的,从确定考试、命题、制卷、保卷、分配考场、考试、评卷、公布成绩等环节来看,流程相当繁琐复杂,而且如果任何一个环节出现问题的话,都会让考试周期变得更加漫长。与此同时,对阅卷教师要求也较高,其工作量也很大,并且纸质版试卷的批阅还会带来物理上的负重甚至是批阅地点的限制。因此,网上阅卷系统的出现,极大地缓解了老师们的批阅压力。
传统的英语考试一般都是纸质版的,主要包括以下几个流程:学生纸质试卷考试、教师集中纸质试卷批阅、分数教研,最终分数会通知到学生本人,但是试卷并不一定发还,而且即使发还给学生,他们也只会看到分数。对于客观题学生可以根据标准答案进行比对、改正和学习,但是对于主观题目,比如本发明中提到的英语作文,学生就看不到所谓的“正确答案”了,只能看到作文的最终得分。
随着技术发展,现有的网上阅卷在很大程度上减轻了老师们的批阅负担。网上阅卷会自动扫描考试试卷,切片,然后分发给老师们去批阅。这样一来,在deadline前,老师们可以自由选择批阅时间和地点。与此同时,针对客观题已经实现了自动批阅,这样更是大大的减轻了老师们的批阅工作量,只剩主观题祖耀老师批阅。作为主观题的英语作文,也是这样,即使网上阅卷,老师们也只会对作文进行打分,因为批改所有作文是非常耗费时间和人力的。如果能不需要人工批改,学生就能发现自己作文的一些语法错误同时学习一些比较高级闪光的英语表达,那么就可以辅助学生复习巩固语法点的同时,学习下高分作文的闪光表达。相比较于一个单调的综合得分,自动评阅系统的批阅结果可以起到辅助学生提升英语写作水平和巩固语法点的作用。因此,采用一些计算机技术来实现英语作文的自动批阅是非常有必要的。
近年来,机器学习技术已经被应用于很多领域中,比如图像识别、个性推荐、机器翻译,模式识别、自然语言处理等。本发明针对的就是自然语言处理领域。利用机器学习算法和nlpparser,分析作文语句的结构和依赖关系,然后借助机器学习算法xgboostmodel和languagemodel,自动批阅作文语法问题,并且在一些错误点给出正确的修改推荐。本发明中的方法实现了英语作文的自动批阅,无论是对教学还是学生,都是有很大裨益的。
技术实现要素:
本发明所要达到的目标是:实现一种基于试卷的英语作文自动评阅的方法,辅助提升学生的英语写作水平和语法点的掌握。
本发明所要解决的技术问题采用以下的技术方案来实现:
英语作文的自动评阅的重点在于自动批阅的过程,利用人工智能技术,对权利要求书2中的英语作文进行自动批改。先利用英文parser(standfordcorenlp+nltk)对英语作文进行split、postag、parsetree、dependency等数据处理和校正,然后采用机器学习算法xgboost,根据不同的语法点进行featureselection,然后对parser后的数据进行featureextract,最后通过xgboostmodel确定trueorfalse。若为true,则直接输出批阅结果;如果为false,则将分类词典中的备选词对sentence进行替换,再过语言模型lmmodel,最后得到语法点的批阅结果。
其中,基于试卷的英语作文自动评阅的方法,主要包括以下步骤:
言表达和后期的训练。两个结合起来就可以构成训练数据了;骤二、解析数据:数据在进行训练前,需要做解析和预处理。利用stanfordcorenlp对数据进行sen_split、pos_tag、parse_tree、dependency等,同时调用nltk进行辅助解析,两个解析结果根据词典以及相似度计算,调整pos_tag、word_tokenizze等dataitems,最后得到解析结果,并传送给步骤三用于模型的训练;
步骤三、构建feature:这是自动批阅方法的重点之一。在接收到来自于步骤二的训练数据后,在模型训练开始前,还有非常重要的一个步骤,那就是feature的构建。feature的数据来自于步骤二,主要包括以目标词为中心词的len=n+m字段的pos、tag、ifnn等feature数据。对所有的sentence的feature数据进行结构打包,即可发送给步骤四作为模型的最终训练数据了;
步骤四、训练xgboost模型:该步骤是自动批阅方法的重中之重。在接收到来自于步骤三的训练数据后,接下来就是构建xgboost模型并完成训练。训练初始需要设置一些相关参数:
1)learning_rate:学习率,初始值设为0.3;
2)alpha:权重的l1正则化项,初值设为0.01;
3)subsample:每次训练使用数据所占比重,初值设为0.8;
4)其他:n_estimators、max_depth、lambda等系统参数和训练参数,可根据需要进行一些设置和选择训练过程中,系统可以每次保存当前性能最好的model。当训练完毕后,就可以直接获取到best_model。它可以直接接收来自步骤三的feature。
步骤五、结果输出:加载训练好的model,作文在经过步骤一、二、三后,直接调用model进行分类输出,trueorfalse。若为true,则直接输出批阅结果;如果为false,则将分类词典中的备选词对sentence进行替换,再过语言模型lmmodel,最后得到语法点的批阅结果。
综上所述,本发明的有益效果表现为:在不增加教师现有的阅卷负担的前提下,实现了一种基于试卷的英语作文自动评阅方法。该方法可以合理的“利用”学生的考试作文。采用standfordcorenlp+nltk对英语作文进行解析,再通过采用机器学习算法xgboost,来实现英语语法的自动检测。这不仅有助于辅助促进学生对英语知识点的学习和拓展,还能间接地帮助学生提升他们的英语作文写作水平和习惯。本发明设计合理,使用方便,效果良好。
附图说明
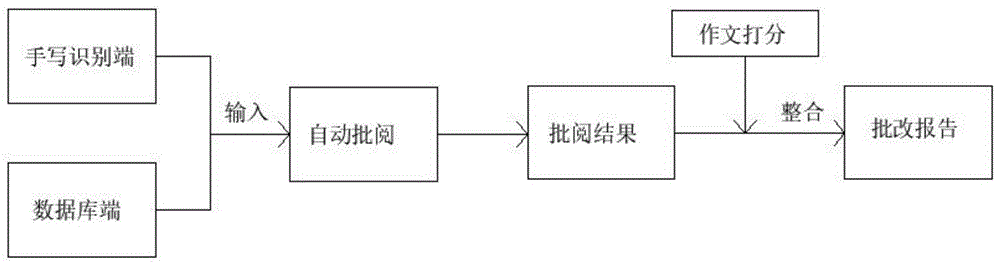
图1为本发明的系统功能结构图;
图2为本发明的算法结构图;
图3为本发明的xgboost分类结构图算法结构图;
图4为本发明的结果示意图;
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面进一步阐述本发明。
一种基于试卷的英语作文自动评阅的方法,主要包括以下步骤,
步骤一、收集训练数据:由于英语作文有自己的写作要求手法,而教研英语作文有需要耗费大量的人力和物力,而英语的语法表达从系统上来说又都是统一的。因此,为了减轻训练数据的收集负担,同时尽量保证数据的准确性和广泛性,训练语料主要有两个来源:其一,是来自于第三方,比如维基百科的英文语料,数据量足够大,且表达相对自由,不会像期刊、论文这种学术性太强;其二,从数据库中抽取1000篇英语作文,人工再进行校验,以便得到表达无误的全部作文。作文尽可能涵盖多种题目,这样可以丰富语言表达和后期的训练。两个结合起来就可以构成训练数据了;
步骤二、解析数据:数据在进行训练前,需要做解析和预处理。利用stanfordcorenlp对数据进行sen_split、pos_tag、parse_tree、dependency等,同时调用nltk进行辅助解析,两个解析结果根据词典以及相似度计算,调整pos_tag、word_tokenizze等dataitems,最后得到解析结果,并传送给步骤三用于模型的训练;
步骤三、构建feature:这是自动批阅方法的重点之一。在接收到来自于步骤二的训练数据后,在模型训练开始前,还有非常重要的一个步骤,那就是feature的构建。feature的数据来自于步骤二,主要包括以目标词为中心词的len=n+m字段的pos、tag、ifnn等feature数据。对所有的sentence的feature数据进行结构打包,即可发送给步骤四作为模型的最终训练数据了;
步骤四、训练xgboost模型:该步骤是自动批阅方法的重中之重。在接收到来自于步骤三的训练数据后,接下来就是构建xgboost模型并完成训练。训练初始需要设置一些相关参数:
1)learning_rate:学习率,初始值设为0.3;
2)alpha:权重的l1正则化项,初值设为0.01;
3)subsample:每次训练使用数据所占比重,初值设为0.8;
4)其他:n_estimators、max_depth、lambda等系统参数和训练参数,可根据需要进行一些设置和选择训练过程中,系统可以每次保存当前性能最好的model。当训练完毕后,可以直接获取到best_model。它可以直接接收来自步骤三的feature。
步骤五、结果输出:加载训练好的model,作文在经过步骤一、二、三后,直接调用model进行分类输出,trueorfalse。若为true,则直接输出批阅结果;如果为false,则将分类词典中的备选词对sentence进行替换,再过语言模型lmmodel,最后得到语法点的批阅结果。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!