基于适应性卷积的RGB-D图像高质量网格生成方法与流程
本发明涉及高质量三维网格生成的技术领域,尤其是指一种基于适应性卷积的rgb-d图像高质量网格生成方法。
背景技术:
随着深度传感器在自动驾驶、增强现实、室内导航、安全支付以及场景重建等领域的大量应用,对于高精度的深度信息的获取以及后续高质量三维重建结果的需求变得愈发重要。尽管最近在深度感应技术上已经取得很大的进展,但在一方面商品级rgb-d相机比如microsoftkinect,intelrealsense和googletango等设备仍然存在当被采集表面过于光滑,高光,太过纤细,太过靠近或者远离相机等因素影响下,采集到的深度图像会经常出现深度数据的缺失。而这些情况又在较大的房间,条状物体和强光照射的场景下频繁出现。即使在家中,深度图像也通常缺少超过50%的像素。在另一方面,受限于深度摄像机较低的分辨率,通过传感器数据重建出的点云太过稀疏。这些深度传感器扫描所得到的原始数据可能不太适合上述如三维重建应用的使用。
高质量网格数据快速生成主要有两个关键部分:首先,数据补全,即恢复出因各种不利因素带来的深度数据的缺失。然后,数据超分辨率,即从上一步的到的低分辨率的完整的点云数据生成高分辨率的点云数据。最后,进一步由点云数据生成网格数据。
许多基于传统方法的室内rgb-d数据补全以及超分辨率的方法效果都不尽人意,而最近,少数基于深度学习的方法有一定的效果,但有以下几个主要缺点:1)非端到端的学习导致方法不能做到实时;2)卷积较大的感受野造成边缘信息的破坏。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提出了一种基于适应性卷积的rgb-d图像高质量网格生成方法,该方法利用深度学习策略,构建卷积神经网络,将局部特征以及全局特征结合,并在学习的过程中引入适应性卷积,避免了边缘信息被破坏的情况下有效实现高质量室内网格数据的快速生成。
为实现上述目的,本发明所提供的技术方案为:基于适应性卷积的rgb-d图像高质量网格生成方法,包括以下步骤:
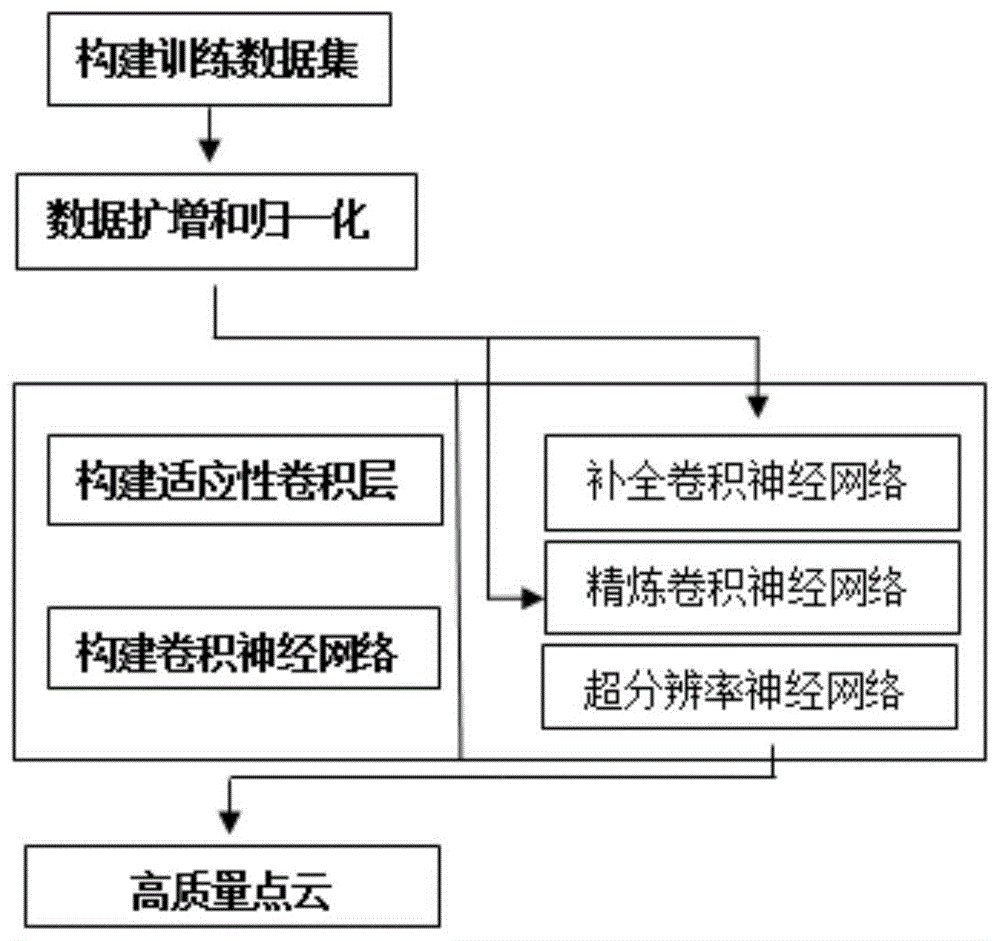
1)构建训练数据集;
2)数据扩增和归一化;
3)构建适应性卷积层;
4)构建深度图像补全网络和超分辨率网络并进行训练;
5)将测试数据依次输入两个训练好的网络中,输出修补好的高分辨率图片并进一步转化成高质量网格。
在步骤1)中,获取基础数据,包括rgbd数据集nyu-dataset和rgbd-scene-dataset,nyu-dataset、rgbd-scene-dataset两个数据包含用kinectv1获取到的室内场景彩色图像irgb和与之对应的带缺失的深度图像idinc,并用基于泊松方程和稀疏矩阵的方法对带缺失的深度图像做修复,得到完整的深度图像idc用于训练。
在步骤2)中,数据扩增包括水平翻转和对深度图像缺失区域进行膨胀操作,以得到不同缺失比例的训练数据;数据归一化是指对彩色图像,将所有图像像素值缩放到0-1之间,对深度图像,作如下处理:
其中,
在步骤3)中,构建适应性卷积层,其适应性卷积的操作如下:
其中,xi为张量中的某个点,xj为xi的邻域点,mj为xj对应的掩码,ω为标准卷积操作,b为偏差,⊙代表按元素想乘操作,ψ(mi)为权值正则项;
适应性卷积层给予图像不同区域不同的权重,能让深度网络更好的学习到图像中的有效特征;对于语义填充网络netfill、边缘增强网络netrefine以及超分辨率网络netsr,mj的计算方式各不相同,具体如下:
对于语义填充网络netfill:
其中,判断xj是否有效的依据是在当前特征中,xj的值是否为0;
对于边缘增强网络netrefine:
其中,判断xj是否有效的依据是在当前rgb图像中,xj与相应滑动窗口中心的像素差异是否小于5个像素值;
对于超分辨率网络netsr:
在步骤4)中,分别构建用于补全任务的深度图像补全网络和用于超分辨率任务的超分辨率网络并进行训练,具体如下:
a、深度图像补全网络
补全网络采用了多尺度编码解码网络进行构建,由语义填充网络netfill以及边缘增强网络netrefine两部分组成并依次顺序连接,其中,除最后一层之外所有的标准卷积由适应性卷积替换;
对于语义填充网络netfill,输入带缺失的深度图像idinc,其张量形式为h*w*1,其中,h为图像的高度,w为图像的宽度;经过netfill语义补全之后得到完整深度图像idout,然后将idout以及彩色图像irgb一并输入边缘增强网络netrefine进行精炼调整,最终得到缺失修复结果irepair,输出张量形式与输入图像尺寸相同;网络损失函数分别由缺失区域的损失和非缺失区域损失两部分构成,权值比例为10:1;
语义填充网络netfill采用u型神经网络(u-net)作为基础结构,网络包括编码器及解码器两部分,编码器用于对图像信息进行编码和特征空间的转换,解码器用于高位信息的解码,两部分均采用5层卷积神经网络架构;
编码器采用五层结构,每层分别包含适应性卷积以及批量正则化两个操作,并采用leaky-relu作为激活函数,卷积核尺寸分别为7*7、5*5、3*3、3*3、3*3,卷积步长全部为2,每经过一层特征高和宽都降为原来一半,并在输入图像的边界做补0处理;卷积核个数分别为16,32,64,128,128;通过不断地在不同尺寸提取特征以对缺失区域进行填补,最终所有的缺失区域都将被修复;
解码器同样为5层结构,每层包含上采样、特征拼接、适应性卷积以及批量正则化四个操作,采用leakyrelu作为激活函数,编码器和解码器之间进行跨层连接,即每个编码器的输出都与解码器上采样后相同尺寸的特征图输出进行复制拼接,并作为解码器的输入,具体是:每个解码器层先将上一层的输入做上采样以后,和与之对应的尺寸相同的编码器特征进行拼接之后,输入当前适应性卷积进行特征学习,卷积核尺寸全部为3*3,步长全部为1*1,卷积核个数分别为128,64,32,16,1;
网络最后一层为卷积核尺寸为1*1的卷积层,用于特征的通道变换以及数值区间映射;
b、构建超分辨率网络
超分辨率任务采用了全局特征和局部特征相融合的方法,并使用曼哈顿距离作为损失函数进行优化;
对于超分辨率网络netsr,采用密集连接块(denseblock)为基础结构,通过亚像素卷积进行上采样,将所有标准卷积替换为适应性卷积,网络最后一层使用1*1卷积用于通道调整;网络使用五个密集连接块进行特征的提取,每个密集连接块都使用两次适应性卷积,卷积核的大小都为3*3,步长为1,并对输入四周进行补0以保持输入和输出的特征尺寸一致,卷积核的个数都为64;将密集连接块的输入与输出进行跨层连接,即把密集连接块的输入与输出进行特征维度的拼接之后作为下一个密集连接块的输入;通过不断融合从低维到高维的特征来使网络学习到更丰富的信息;亚像素卷积的上采样因子为4,在网络最后,有一个卷积核尺寸为1*1的标准卷积并以relu为激活函数;
c、对构建好的网络进行训练
对构建好的网络设计相应的损失函数,使用adam方法对损失函数进行优化,最终得到训练完成的网络。
在步骤5)中,将经过神经网络修补好的高分辨率的点云数据,用滚球法ballpivoting方法生成高质量的室内场景网格数据。
本发明与现有技术相比,具有如下优点与有益效果:
1、针对目前缺失公开高质量rgb-d数据集的情况,提出构建“高-低”质量的室内场景rgb-d图像数据集的方法。
2、针对消费级别或移动设备的深度相机获取的缺失的深度信息图,提出一个利用rgb彩色图像特征结合融合卷积操作的深度信息图修复算法。
3、针对低质量、高噪音的深度图像,提出一个利用rgb彩色图像语义信息来进行去噪和增强特征的方法。
4、提出一个融合rgb彩色图像语义特征、基于点云的卷积网络进行深度图像超分辨率重建的方法。
附图说明
图1为本发明逻辑流程示意图。
图2为语义填充网络的架构图。
具体实施方式
下面结合具体实施例对本发明作进一步说明。
如图1所示,本实施例所提供的基于适应性卷积的rgb-d图像高质量的网格生成方法,包含以下步骤:
步骤1、构建训练数据集
1.1构建室内场景补全数据集databasecompletion
采用的纽约大学的开放数据集里有着超过十万组室内场景的rgbd图像,从https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html网站中收集rgbd图像,9000≤nrgbd≤10000,其分辨率为640*480,其rgbd图像包含彩色图像irgb、残缺的深度图像idinc并用anatlevin's的colorization方法对带缺失的深度图像做修复得到完整的深度图像idc。首先对将深度图像和rgb图像对齐以及降噪之后对rgbd数据的四周进行裁切,得到557*423分辨率的图像。随后,对数据集内所有数据提取掩码构建掩码图像集maskdepth:
式中,
上述生成的idinc并与对应的irgb以及idc组成新的训练数据,进而构建起补全任务训练数据集。
1.2构建室内场景超分辨率数据集databasesr
从http://rgbd-dataset.cs.washington.edu/dataset/rgbd-scenes-v2/采集两组内容相同的深度图m对,每队图像的下采样因子为4x。一组位低分辨率深度图ilr,另一组为高分辨率深度图ihr,并对图片对水平翻转已进行数据扩增,最终得到24000~25000对数据对。
步骤2、数据扩增和归一化
数据扩增包括水平翻转和对深度图像缺失区域进行膨胀操作,以得到不同缺失比例的训练数据。
对于彩色图像irgb,统一作除以255处理,将像素值缩放到0~1之间。而对于深度图像idin,首先作降噪处理,将深度值在200以下以及40000以上的置零。对每张图像单独计算最小值minidinc以及最大值maxidinc,然后作以下处理:
步骤3、构建适应性卷积
本文核心为构建合适的适应性卷积来替换标准卷积以更好的服务于本任务。适应性卷积的流程如下:
其中,xi为张量中的某个点,xj为xi的邻域点,mj为xj对应的掩码,ω为标准卷积操作,b为偏差,⊙代表按元素想乘操作,ψ(mi)为权值正则项。适应性卷积给与不同区域不同的权重,相比传统卷积让网络更好的学习到有效特征。对于语义填充网络netfill,边缘增强网络netrefine以及超分辨率网络netsr,mj的计算方式各不相同。计算方式如下。
对于语义填充网络netfill:
其中,判断xj是否有效的依据是在当前特征中,xj的值是否为0。
对于边缘增强网络netrefine:
其中,判断xj是否有效的依据是在当前rgb图像中中,xj与相应滑动窗口中心的像素差异是否小于5个像素值。
对于超分辨率网络netsr:
步骤4、构建深度图像补全网络和超分辨率网络并进行训练
a、构建深度图像补全网络
深度图像补全网络采用了多尺度的编码解码结构网络进行构建,由语义填充网络netfill以及边缘增强网络netrefine两部分组成并依次顺序连接,其中,除最后一层之外所有的标准卷积由适应性卷积替换。
对于语义填充网络netfill,输入带缺失的深度图像idinc,其张量形式为h*w*1,其中,h为图像的高度,w为图像的宽度;经过netfill语义补全之后得到完整深度图像idout。然后再将idout以及彩色图像irgb一并输入netrefine进行精炼调整,最终得到空洞填充结果ifill,输出张量形式同样为h*w*1。网络损失函数分别由缺失区域的损失和非缺失区域损失两部分构成,权值比例为1:10。
如图2所示,netfill采用u-net作为基础结构,编码器及解码器均采用5层卷积神经网络架构;
编码器采用五层结构,每层分别包含适应性卷积以及批量正则化两个操作,并用leaky-relu作为激活函数,卷积核尺寸分别为7*7,5*5,3*3,3*3,3*3,卷积步长全部为2,每经过一个编码层特征高和宽都降为原来一半,并在输入图像的边界做补0处理。卷积核个数分别为16,32,64,128,128。通过不断的在不同尺寸提取特征以对缺失区域进行填补,最终所有的缺失区域都将被修复。
解码器同样为5层结构,每层包含上采样、特征拼接,适应性卷积以及正则化四个操作,同样采用leakyrelu作为激活函数。每个解码器层先将上一层的输入做上采样以后和与之对应的尺寸相同的编码器中的特征进行拼接之后输入当前适应性卷积进行特征学习。卷积核尺寸全部为3*3,步长全部为1*1,卷积核个数分别为128,64,32,16,1。
网络最后一层为卷积核尺寸为1*1的普通卷积层,同于特征的通道变换以及数值区间映射。
c、构建超分辨率网络
超分辨率任务采用了全局特征和局部特征相融合的方法并使用曼哈顿距离作为损失函数进行优化。
对于超分辨率网络netsr,输入补全网络得到的结果ifill,经过密集连接块的语义提取和亚像素卷积的上采样,得到高分辨率的完整的深度图像,并最终转化为网格。
超分辨率网络netsr采用密集连接块为基础结构,通过亚像素卷积进行上采样。同样的,将所有标准卷积替换为适应性卷积。类似的,网络最后一层使用1*1卷积用于通道调整。模型使用五个密集连接块进行特征的提取,每个密集连接块都包含两次适应性卷积,卷积核的尺寸都为3*3,步长为1,并对输入四周进行补0以保持输入和输出的特征尺寸一致,卷积核的个数都为64。并将密集连接块的输入与输出进行跨层连接,即把密集连接块的输入与输出进行特征维度的拼接之后作为下一个密集连接块的输入。通过不断的融合从低维到高维的特征来使网络学习到更丰富的信息。亚像素卷积的上采样因子为4,特征经过此层之后高和宽都变为原来的4倍。在网络最后,有一个卷积核尺寸为1*1的标准卷积并以relu为激活函数。
训练神经网络:将数据集按7:2:1的比例划分为训练集、验证集和测试集,分别对补全网络以及超分辨率网络进行训练。利用验证集,对模型实时进行评估并计算评价指标,利用测试集对训练完毕的网络进行性能测试。所用设备处理器为英特尔i7-7700,显卡为英伟达1080ti;
针对补全任务,netfill输入为深度图iin,以批大小4和学习率0.001先训练一天,之后把学习率降为0.0001继续训练,整个过程耗时三天。训练过程以网络输出和真值之间的均方差为损失函数。netrefine将输入irgb提取的权值和netfill对应的输入做对应元素想乘,并以固定参数的标准卷积核进行卷积,无可训练参数,执行较快。
针对超分辨率任务,netsr的输入为ilr,以批大小为8进行训练,学习率为0.0001。训练耗费200个批次模型达到收敛。
步骤5、将测试数据依次输入两个训练好的网络中,输出修补好的高分辨率图片并进一步转化成高质量网格,具体如下:
将经过神经网络修补好的高分辨率的点云数据,用ballpivoting方法生成高质量的室内场景网格数据。
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!