一种自学习属性权重的K-means聚类方法与流程
本发明涉及机器学习领域,即通过对各个簇内属性赋予不同的权重提高k_means聚类算法的适用性。
背景技术:
k-means算法早在1967年就由macqueen提出,该算法是基于划分的聚类算法中的一个典型算法,有操作简单、采用误差平方和准则函数、对大数据集的处理上有较高的伸缩性和可压缩性的优点。目前广泛应用在图像分割、数据压缩、数据挖掘等领域。但是该算法也存在一定的局限性:1、对聚类中心较敏感,聚类中心的不同往往会导致聚类结果的不同。2、易受异常值的影响。3、对k值的选择没有准则可依等。针对以上不足之处,目前许多学者已经提出的很多改进方法。如dhillon等人通过迭代调整过程重新计算聚类中心的方法使其性能得到提高。曹志宇等人提出了快速查找聚类质心的k_means算法,对uci里面的数据进行试验结果表明改进后的k_means算法能产生质量较高的聚类结果。rajini,n.hema,bhavani,r.在对k均值和核化模糊c均值聚类进行研究时,提出了一种新的中心初始化算法来测量聚类算法的初始中心。lee,wonhee等人提出了通过计算选择簇的初始中心选择,该方法最大限度地提高了聚类初始中心之间的距离。与随机选取的初始聚类中心相比,中心分布均匀,计算结果更准确。duanyanling等人提出了一种基于较大距离和较高密度的中心点初始化方法。利用距离加权平均值的倒数表示样本密度,选取距离越大、密度越大的数据样本作为初始聚类中心,对聚类结果进行优化。
本发明在已有的研究成果上提出了一种基于权重自学习的k_means聚类算法,通过为各个簇内各个属性赋予不同的权重,体现属性对聚类的贡献。相比传统的聚类算法(各个属性具有相同的权重),该算法更能体现簇内相似性与簇间相异性。
技术实现要素:
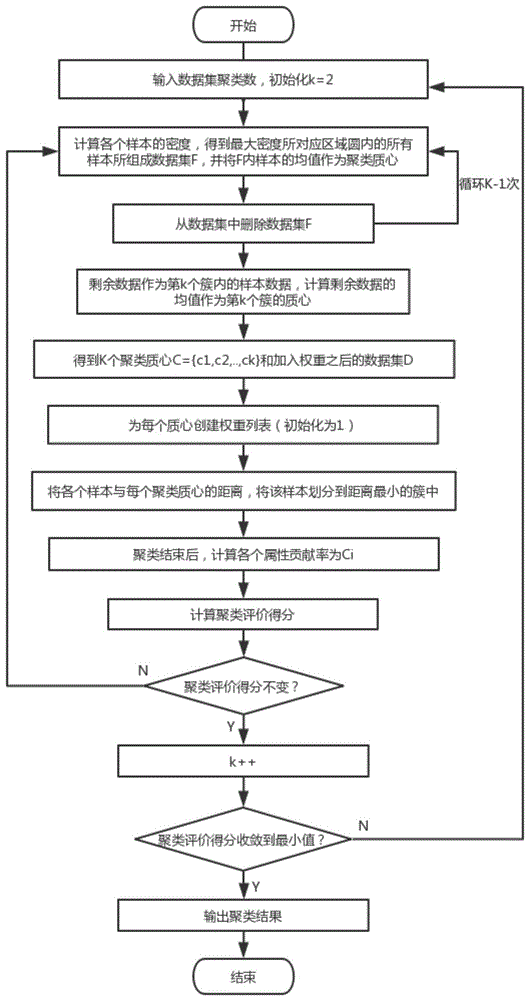
本发明提出了一种自学习属性权重的k-means聚类方法,对传统的k-means聚类算法进行优化并扩展其功能,使其更能满足聚类的需要,包含以下步骤:
步骤1:计算数据集对应的差异矩阵,根据数据集的差异矩阵计算各个样本的样本密度。
步骤2:通过计算各个样本的邻域密度,得到k-1个密度最大的样本集,以这些样本集的均值作为聚类质心,得到k-1个聚类质心,然后取剩余数据的均值作为第k聚类质心,其中k为聚类个数,k取0<k<n内的整数,n为样本总数,在第一次循环时令k=2。
步骤3:为每个质心创建权重列表。
步骤4:将各个样本的属性与每个聚类质心的权重列表对应相乘,然后计算每个样本到各个质心的欧式距离,并将各个样本匹配到距离最近的质心所在类内。
步骤5:计算各个类内的各个属性对聚类的贡献率,然后根据贡献率更新各个类内的属性权重列表。
步骤6:计算聚类模型评分。
步骤7:循环步骤1至步骤6,取模型评分不变时的聚类结果作为将数据集聚为k个类的聚类结果。
步骤8:k加1,循环步骤1至步骤7,直到聚类模型评分不变。
与现有技术相比,本发明具有以下明显优势:
1、本发明提出了一种基于权重自学习的聚类算法,是对k_means聚类算法的改进,聚类结果允许簇与簇之间的属性权重不同。相比传统的聚类算法(各个属性具有相同的权重),该算法更能体现簇内相似性与簇间相异性。
2、本方法中通过迭代循环,使得各个聚类簇具有本簇内特征权重,该权重能够体现本簇内样本的共同特征,以及本簇内各个属性对聚类的影响大小。
附图说明:
图1为本发明所涉及方法的总体流程图;
图2聚类质心选择流程图;
图3基于权重自学习的聚类算法流程图;
具体实施方式:
以下结合具体实施例,并参照附图,对本发明进一步详细说明。
本发明所用到的硬件设备有pc机1台;
如图1所示,为本发明所提出的基于属性权重自学习的k_means聚类算法,该算法包括聚类质心的选择和聚类过程两个阶段。
(1)选择聚类质心阶段
如图2所示,为聚类质心选择流程图。在传统聚类算法中聚类结果对质心的选择很敏感,往往不同的质心,会导致不同的聚类结果。由于聚类是根据样本间的相异性进行,而密度较高的样本之间具有较高的相似性,密度较低的样本间具有较大的差异性。因此聚类质心更可能位于密度较高的区域。
1.相关定义
1)将n个m维待聚类对象组成的数据集d表示成如下形式:
d={xi|l=1,2,...,n}
xl={xi1,xi2,...,xlm}
其中n为样本总数,样本xl由m个属性共同表示。
2)差异矩阵
差异矩阵用于描述数据对象集合d(包括n个样本)中任意两点之间的相似程度,表示方式是n*n的矩阵,如下所示:
在以上矩阵中,d(i,j)描述的是数据对象集合中样本i与样本j的差异度,在此使用数据点之间的欧式距离来度量样本之间的差异度。d(i,j)=d(j,i)且d(i,j)>0,样本i和样本j的差异越大,d(i,j)的值越大,反之亦然。
样本i与样本j之间的欧式距离计算公式如下:
其中,m为样本属性的数量。
3)设将上述n个样本所组成的数据集d划分为k个聚类,聚类质心为c={c1,c2,......,ck}
各个样本的密度计算公式为:
density(i)={j∈d|d(i,j)≤r}(2)
在上述公式中,d(i,j)表示样本i和样本j之间的欧式距离,density(i)表示样本i的密度,即数据集d中到样本i的欧式距离小于等于半径r的样本的数目。
差异矩阵反映的是样本之间的差异度,差异越大说明样本被划分为同一个类的可能性越小。因此可以通过样本间的最大差异值得到质心搜索区域圆半径,计算公式为:
其中,max_d(i,j)表示差异矩阵中d(i,j)的最大值,分母取k+1是为了防止r取值过大,导致圆与圆之间有重叠。
2.具体步骤如下
输入:n*m规模的数据集(n表示样本数量,m表示数据集的属性数量)
输出:聚类的k个质心:c={c1,c2......,ck}
步骤1:根据公式(1)计算数据集的差异矩阵。
步骤2:从差异矩阵中得到max_d(i,j),并根据公式(3),计算出质心搜索半径r。
步骤3:根据公式(2)计算出各个样本的密度,得到最大密度所对应的区域圆内所有样本组成数据集f。
步骤4:计算数据集f内样本的均值,并以此作为聚类质心。
步骤5:在数据集中删除数据集f内的所有样本后得到新的数据集。
步骤6:将步骤5所得到的新的数据集循环执行k-1次步骤1至步骤4,得到k-1个质心。
步骤7:以上步骤执行完成后,将剩余数据作为第k个簇内的样本数据,将剩余数据的均值作为第k个簇的质心。
(2)聚类阶段
如图3所示,为聚类阶段流程图,传统k-means聚类算法中未考虑各个属性对聚类的贡献,因此会导致将空间中在某个属性上距离很近在其他无关属性上距离较远的点划分到不同的簇内,此外类与类的差异在属性上也无法体现出来。为解决以上问题,可以对不同的类内的属性赋予不同的权重,通过属性权重体现类与类之间的差异性。具体包括以下步骤:
1.相关定义
1)各个样本到各个聚类质心的距离计算公式
第t个样本到第i质心的距离公式如下:
其中,m为样本属性的数量,xtj表示第t个样本数据的第j个属性值,cij表示第i个质心的第j个属性值。
2)第j个属性对第i个类的贡献率qj计算公式
设聚类完成后,每个类中的样本个数为:
n1,n2,...ni,...,nk,0<i<k。设第i个类内的样本为{x1,x2...xni}。由于聚类是根据样本间相异度进行的,所以可以认为离散程度越大的属性对聚类的贡献越大。因此可以采用属性标来确定属性对聚类的贡献。第j个属性对第i个类的贡献率为:
其中,δj表示第j个属性在第i个类内的标准差,m为样本属性数量,ni表示第i个类内的样本数量,xtj表示第t个样本数据的第j个属性值。
3)第j个属性对类间距离的贡献率pj计算公式如下
在第j个属性上的所有类的类间距离之和为:
其中,k为聚类个数,
则第j个属性对类间距离的贡献率为:
4)聚类模型得分计算公式
所有类的类内距离计算公式如下:
其中,m为属性数量,k为聚类个数,ni表示第i个类内样本数量。xit表示第i个类内第t个样本数据,μi为第i个类内数据的均值。
类间距离计算公式:
其中,k为聚类个数,μi表示第i个类样本数据的均值,μ表示全部数据集的均值。
模型得分:
一般来说,聚类算法所追求的最优结果是:类内紧凑,类间离散。对于上文所述的模型来说,in_clu越小意味着类内紧凑,out_clu取值越大意味着类间离散。因此可以通过二者比值定量的衡量权重对聚类结果的贡献,即贡献越大score取值越大;贡献越小score取值越小。
5)权重更新计算公式
设第一次循环后第i个类内各个属性所对应的权重为:wi1=[w1,w2,w3,......,wm],m为属性数量,第二次循环中第i个类内各个属性对聚类的贡献率为v=[v1,v2,v3,......,vm],则第二次循环结束后第i个类内各个属性的权重计算公式如下:
wi2=wi1×v(11)
2.聚类过程
输入:聚类质心c={c1,c2,......,ck},n*m规模的数据集
输出:聚类个数为k的聚类结果和相应的权重列表
步骤1:为每个质心创建权重列表,权重列表初始化为1。
步骤2:将各个样本的属性与每个聚类质心的权重列表对应相乘,得到加权后的各属性数据。由于距离越小,二者相似度越大,因此可以通过公式(4)计算每个样本到各个质心的距离,并将各个样本匹配到距离最近的质心所在类内。
步骤3:通过公式(5)计算出各个属性对本类的贡献率qj(0<j<m,m为属性数量),通过公式(6)、(7)可以得到各个属性对类间距离的贡献率pj,最后得到各个属性对聚类的贡献率vj=qj×pj。
步骤4:根据公式(8)、(9)、(10)可以得到聚类模型得分。
步骤5:循环执行步骤1至3,其中步骤1内不执行初始化操作,若第二次循环模型评分score大于第一次循环所得评分,则根据公式(11)更新各个聚类质心的权重列表,以及score值,否则,不更新二者。
步骤6:迭代循环步骤1至5直至score不发生变化。
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!