基于N边DFS子图的轻量级无监督图表示学习方法及装置与流程
本发明属于图形处理
技术领域:
,尤其涉及一种基于n边dfs子图的轻量级无监督图表示学习方法及装置。
背景技术:
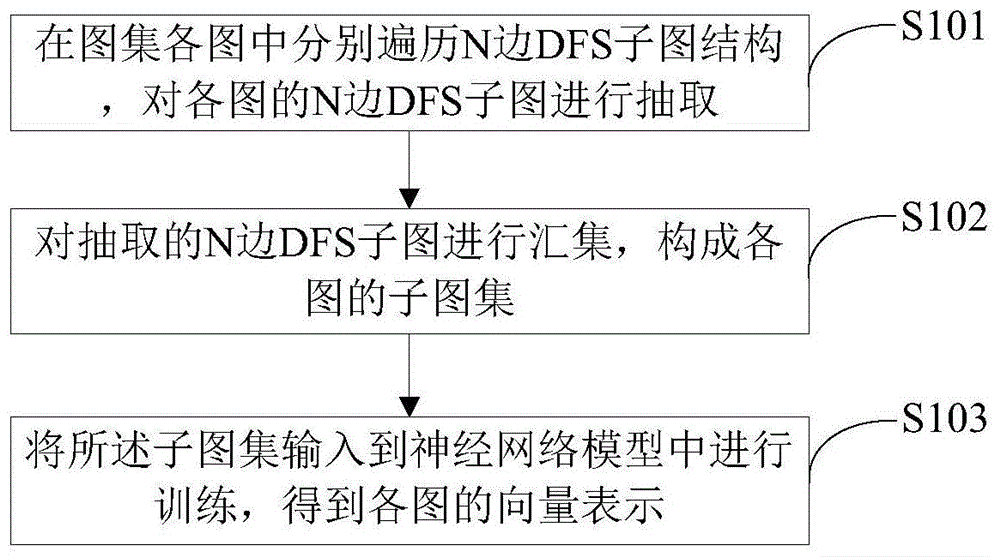
:在现实生活中,图是一种普遍存在的数据结构,它可以模拟几乎所有事物之间的联系,例如通信网络中用户之间的通联关系、网络拓扑图中计算机与计算机之间的联系、社交网络中用户与用户之间的关系等。通常系统中的每个实体都映射到了图中的一个节点,而实体之间的联系则被映射为图中的一条边,图结构可以很方便地反映现实生活中事物之间的联系。其中图与图之间的相似性计算是一个热门的研究领域,比较图与图之间的相似性在现实生活中有较为广泛的应用,可用于恶意代码检测、蛋白质相互作用网络属性分类、用户评论情感分类等。然而,随着图数据集规模的不断扩大,传统的图相似性计算基于节点和边的统计、图的同构测试,上述方法不能很好的捕捉图中的内在结构变化,已不能满足需求。而通过在图数据集上引入图表示学习模型,可以方便地对图数据集进行分类,同时通过将图转化为向量表示可以方便地进行图的相似性计算。为了反映图的结构变化、对图集按照结构相似性进行分类,学者们已经提出了许多图表示学习方法,较为典型的有edge-conditionedconvolution(ecc)、pathchy-san(pscn)、graph2vec、ge-fsg等算法,在上述算法中ecc、pscn算法属于有监督的图表示学习算法,在数据集的分类上效果良好,而有监督的图表示学习算法其特性决定了其不能直接用于其他类似聚类、社团检测等任务中。graph2vec、ge-fsg算法属于无监督的图表示学习算法,用来学习整个图的向量表示,可以方便对图之间的相似性进行度量,其适用性较有监督的图表示学习算法有较大的提升,可用于图分类、聚类、链接预测及社团检测等方面的任务。在无监督的图表示学习邻域,graph2vec算法基于根子图抽取,而根子图抽取过程中忽略了根子图内部的子结构相似性,即不管两个根子图有多相似,只要其不完全相同则视为两个不同的结构,同时graph2vec算法是在节点邻域内而不是在整个图的范围内抽取结构特征,因此其存在着图结构学习不全面的问题,进而直接影响其图分类任务的准确度。ge-fsg算法基于频繁子图挖掘,然而频繁子图挖掘时间复杂度较高,不适用于规模较大的图数据集。图在进行表示学习后可以将图结构转化为向量形式,进而可以快速方便地度量图之间的相似性,现有的图表示学习方法主要是基于根子图和频繁子图抽取,之后调用神经网络模型获得图的向量表示。这些方法存在下列问题:一是部分算法在子图抽取时较为复杂,通用性不高;二是在图表示学习时因未能较全面地抽取子图导致最终生成的向量无法较好地表示原始图形,进而导致图分类效果不够理想。技术实现要素:本发明针对现有图表示学习方法不能全面地抽取图的结构信息、且不适用于规模较大的图数据集的问题,提出一种基于n边dfs子图的轻量级无监督图表示学习方法及装置。为了实现上述目的,本发明采用以下技术方案:一种基于n边dfs子图的轻量级无监督图表示学习方法,包括:步骤1:在图集各图中分别遍历n边dfs子图结构,对各图的n边dfs子图进行抽取;步骤2:对抽取的n边dfs子图进行汇集,构成各图的子图集;步骤3:将所述子图集输入到神经网络模型中进行训练,得到各图的向量表示。进一步地,所述步骤1包括:步骤1.1:采用深度优先子图搜索算法,利用最小dfscode对子图进行唯一标识,将子图转化为文本形式表示;步骤1.2:对于图集中的每一个图依次执行n边dfs子图抽取,首先生成初始1边子图集,之后在生成初始1边子图集上依次进行n边dfs子图挖掘:生成初始边集,由每一条初始边开始逐步扩展,扩展时首先判断当前子图是否dfscode最小,若是则进行该子图的扩展,直到扩展的子图边数达到设定的阈值n,此时停止该子图的扩展,若否则不进行该子图的扩展;由k边子图生成k+1边子图的过程中遵循最右路径扩展原则,首先构造子图的最右路径,之后在最右路径的各节点上分别生成前向边和后向边,将所有新生成的边分别添加到k边子图上构成多个k+1边子图,其中,k+1≤n。进一步地,所述步骤2包括:步骤2.1:根据子图实例的数量确定该子图的最小dfscode在相应子图集中出现的次数;不考虑子图重叠问题,同一子图的实例中只要有一个节点不同则视为不同的实例;步骤2.2:按照子图的最小dfscode在相应子图集中出现的次数对子图进行排序,构成相应子图集。进一步地,所述步骤3包括:将dfscode格式的子图集视为一篇文档,子图集中的每一个子图视为一个单词,通过doc2vec模型训练得到对应图的向量表示。一种基于n边dfs子图的轻量级无监督图表示学习装置,包括:子图抽取模块,用于在图集各图中分别遍历n边dfs子图结构,对各图的n边dfs子图进行抽取;子图汇集模块,用于对抽取的n边dfs子图进行汇集,构成各图的子图集;图向量表示模块,用于将所述子图集输入到神经网络模型中进行训练,得到各图的向量表示。进一步地,所述子图抽取模块包括:最小dfscode标识子模块,用于采用深度优先子图搜索算法,利用最小dfscode对子图进行唯一标识,将子图转化为文本形式表示;子图抽取子模块,用于对于图集中的每一个图依次执行n边dfs子图抽取,首先生成初始1边子图集,之后在生成初始1边子图集上依次进行n边dfs子图挖掘:生成初始边集,由每一条初始边开始逐步扩展,扩展时首先判断当前子图是否dfscode最小,若是则进行该子图的扩展,直到扩展的子图边数达到设定的阈值n,此时停止该子图的扩展,若否则不进行该子图的扩展;由k边子图生成k+1边子图的过程中遵循最右路径扩展原则,首先构造子图的最右路径,之后在最右路径的各节点上分别生成前向边和后向边,将所有新生成的边分别添加到k边子图上构成多个k+1边子图,其中,k+1≤n。进一步地,所述子图汇集模块包括:子图频度统计子模块,用于根据子图实例的数量确定该子图的最小dfscode在相应子图集中出现的次数;不考虑子图重叠问题,同一子图的实例中只要有一个节点不同则视为不同的实例;子图排序子模块,用于按照子图的最小dfscode在相应子图集中出现的次数对子图进行排序,构成相应子图集。进一步地,所述图向量表示模块具体用于:将dfscode格式的子图集视为一篇文档,子图集中的每一个子图视为一个单词,通过doc2vec模型训练得到对应图的向量表示。与现有技术相比,本发明具有的有益效果:本发明通过在图中遍历n边dfs子图结构,使用dfscode对子图进行唯一标识,通过限定遍历子图的最大边数n来降低子图抽取的时间复杂度,同时由于在整个图范围内抽取n边dfs子图克服了基于节点根子图抽取的片面性,在生成每个图的子图集后将其输入到神经网络模型中得到图的向量表示,可以较全面地抽取子图结构。本发明具有下列特点:1.本发明没有采用高时间复杂度的频繁子图挖掘算法,而是采用了较低时间复杂度的指定大小的n边dfs子图遍历,进而可以在较快的时间内生成子图集,可适用于规模较大的图数据集。2.本发明是完全的无监督的网络表示学习方法,其模型训练过程不依赖类的标签。这也符合现实情况,在现实中需要分类的对象其类别标签往往难以获取,相较于有监督的网络表示学习算法无监督的网络表示学习算法可以更好地适应现实情况。3.不同于基于节点、路径、子图的网络表示学习算法,本发明可以直接学习到整个图的向量表示,从而可以直接应用于分类、聚类等任务中。4.在多个数据集上就分类任务进行实验对比,本发明在大多数数据集上分类准确率有2%-90%的提升。附图说明图1为本发明实施例一种基于n边dfs子图的轻量级无监督图表示学习方法的基本流程图;图2为本发明实施例一种基于n边dfs子图的轻量级无监督图表示学习方法的子图扩展策略示意图;图3为本发明实施例一种基于n边dfs子图的轻量级无监督图表示学习方法的子图频度计算示意图;图4为本发明实施例一种基于n边dfs子图的轻量级无监督图表示学习方法图表示学习模型结构示意图;图5为本发明实施例一种基于n边dfs子图的轻量级无监督图表示学习方法的子图最大边数与分类准确率关系图;图6为本发明实施例一种基于n边dfs子图的轻量级无监督图表示学习方法的向量表示维度与分类准确率关系图;图7为本发明实施例一种基于n边dfs子图的轻量级无监督图表示学习方法的子图生成时间对比图;图8为本发明实施例一种基于n边dfs子图的轻量级无监督图表示学习装置的结构示意图。具体实施方式下面结合附图和具体的实施例对本发明做进一步的解释说明:1.相关定义(1)标签图:标签图为带有节点标签和边标签的图,其表示为:g=(v,e,l),其中,v是图g中的顶点的集合,e是图g中边的集合,l是边和节点的标签映射函数。(2)子图:已知标签图g=(v,e,l),现在有一个图s=(vs,es,ls),对于任意当且仅当ls(v)=l(v)对于每个v∈vs,ls(u,v)=l(u,v)对于每个(u,v)∈es都成立时,则称图s为图g的子图。(3)图表示学习:给定一个图g=(v,e,l),图表示学习的目的是学习一个映射函数f将图映射到一个低维向量中:g→y∈rd,其中d为预期的图表示的维度。算法最终得到图g的低维稠密的向量表示,这种表示形式在处理大规模图集时非常有效。(4)dfsedge(depth-firstsearchedge):dfsedge是图中边的表示形式,图中一条边称作一个dfsedge,一个dfsedge是一个五元组(frm,to,v1,elb,v2),其中frm和to是这条边两个端点在dfscode里的序号,v1和v2是这条边两个端点的标签,elb是这条边的标签。(5)dfscode:dfscode由一系列dfsedge组合而成的,一个n边图的dfscode为{dfsedge1,dfsedge2,...,dfsedgen},一个图可以用多个不同的dfscode(dfs编码)表示。(6)dfs字典序(depth-firstsearchlexicographicorder):为了比较dfsedge之间大小关系,定义五元组(frm,to,v1,elb,v2)优先级依次降低,dfsedge之间通过依次比较各级别标识的字典序来确定大小关系。(7)最小dfscode:一个图可以用多个不同的dfscode表示,基于dfs字典序,取最小的dfscode来唯一的标识一个图,此时的编码称为最小dfscode。(8)子图频度:特定结构的子图在图中可能会出现多次,将子图在原始图中出现的总次数称为子图的频度。(9)图的相似性:图的相似性是指两图之间的相似程度。判断两图是否相似属于图的相似性匹配问题,该问题已经被证明为np完全问题,算法复杂度是图规模大小的指数函数。在对图进行表示学习后,图向量之间的距离即为图之间的相似性度量指标,距离越近代表相似性越高,距离越远代表相似性越低。(10)n边dfs子图:已知图g=(v,e,l),图s=(vs,es,ls),图s为图g基于深度优先遍历获得的一个子图,若图s的边数|es|≤n,n∈r,则称图s为图g的n边dfs子图。2.问题描述给定一组图数据集gs={g1,g2,...,gn}和预期的图表示的维度d,目标是学习每个图gi∈gs的d维向量表示。在由g→rd的d维向量学习过程中,若g1和g2中有越多的子结构相同,则g1和g2向量之间的距离也越近,反之亦然。在发明中,假设图中所有的节点都有标签,对于没有标签的图可以使用节点的度来作为其标签。实施例1:如图1所示,一种基于n边dfs子图的轻量级无监督图表示学习方法,为表述方便,简称为substructure2vec,包括:步骤s101:在图集各图中分别遍历n边dfs子图结构,对各图的n边dfs子图进行抽取;包括:步骤s1011:采用深度优先子图搜索算法,利用最小dfscode对子图进行唯一标识,将子图转化为文本形式表示;步骤s1012:对于图集中的每一个图依次执行n边dfs子图抽取,首先生成初始1边子图集,之后在生成初始1边子图集上依次进行n边dfs子图挖掘:生成初始边集,由每一条初始边开始逐步扩展,扩展时首先判断当前子图是否dfscode最小,若是则进行该子图的扩展,直到扩展的子图边数达到设定的阈值n,此时停止该子图的扩展,若否则不进行该子图的扩展;由k边子图生成k+1边子图的过程中遵循最右路径扩展原则,首先构造子图的最右路径,之后在最右路径的各节点上分别生成前向边和后向边,将所有新生成的边分别添加到k边子图上构成多个k+1边子图,其中,k+1≤n。步骤s101具体包括:借鉴gspan算法原理,采用深度优先子图搜索算法,利用最小dfscode对图进行唯一标识,以防止同一子图的多次生成。该算法首先生成初始边集,由每一条初始边开始逐步扩展,直到扩展的子图边数达到设定的阈值n,此时停止该子图的扩展。由k边子图生成k+1边子图的过程中遵循最右路径扩展原则,即首先构造子图的最右路径,之后在最右路径的各节点上分别生成前向边和后向边,将所有新生成的边分别添加到k边子图上构成多个k+1边子图。具体子图扩展方式见图2,s0为当前子图,首先生成当前子图的最右路径,即s0中黑色的路径,之后在最右路径上进行扩展,其中s1、s2、s3为前向边扩展,s4为后向边扩展。需要注意的是,在gspan频繁子图挖掘算法中是在整个图集上同时进行子图遍历,之后再通过子图同构测试、支持度计算判断是否为频繁子图。而本发明的任务是遍历图集中所有图的n边dfs子图结构,不需要在整个图集范围内进行子图同构测试、支持度计算,因此只需要在各个图中依次进行n边dfs子图遍历即可。将gspan算法进行修改以适应n边dfs子图遍历,在遍历子图后使用最小dfscode来唯一标识子图,将子图转化为文本形式表示。关于最小dfscode示例如下,图2中待扩展子图s0,其dfscode有多种表达方式,如表1所示,表1中列举了子图s0的3种dfs编码,此时根据dfs字典序α<β<γ,实际上α即为子图s0的最小dfs编码,对于子图s0可以将其转化为文本表示{(0,1,a,1,b),(0,2,a,1,b),(2,3,b,1,c)}。表1子图s0的部分dfscode表示αβγ(0,1,a,1,b)(0,1,a,1,b)(0,1,b,1,a)(0,2,a,1,b)(1,2,b,1,c)(1,2,a,1,b)(2,3,b,1,c)(0,3,a,1,b)(2,3,b,1,c)将n边dfs子图抽取算法命名为structureextract,具体流程见算法1,对于图集中的每一个图依次执行n边dfs子图抽取,该算法首先生成初始1边子图集(算法1第2-4行),之后在生成初始子图集上依次进行n边dfs子图挖掘(算法1第5-8行)。算法1第7行subgraphmining函数是子图挖掘函数,其具体流程见算法2,该算法主要进行子图遍历,在达到指定最大边数n后停止遍历,在扩展子图时首先判断当前子图是否dfscode最小(算法2第2-4行),用来防止同一子图多次生成,之后扩展子图并迭代进行子图挖掘(算法2第5-11行)。算法1:structureextractinput:算法2:subgraphmininginput:下面就structureextract算法的时间复杂度进行分析,n边dfs子图抽取算法改编自频繁子图挖掘算法gspan,gspan算法子图扩展时间复杂度为o(2m),其中m为图中边数,如果限定子图扩展的最大边数为n,则structureextract算法时间复杂为o(mn),其时间复杂度远远低于频繁子图挖掘的时间复杂度,因此其可适用于规模较大的图数据集。步骤s102:对抽取的n边dfs子图进行汇集,构成各图的子图集;包括:步骤s1021:根据子图实例的数量确定该子图的最小dfscode在相应子图集中出现的次数;不考虑子图重叠问题,同一子图的实例中只要有一个节点不同则视为不同的实例;步骤s1022:按照子图的最小dfscode在相应子图集中出现的次数对子图进行排序,构成相应子图集。步骤s102具体包括:在抽取n边dfs子图后,为了生成整个图的n边dfs子图集,还需要汇集一个图的n边dfs子图。在汇集子图时需要考虑子图的频度和子图之间的顺序关系。在图中进行子图遍历时,不可避免的会出现同一子图的多个实例,在汇集n边dfs子图集时需要根据子图实例的数量来确定该子图的dfscode在相应汇集子图集中出现的次数。为简便起见,此处不考虑子图重叠问题,同一子图的实例中只要有一个节点不同则视为不同的实例。如图3所示,图3的s中子图a-b-c共有两个实例。对于同一子图的多个实例,认为子图实例的数量与整个图的结构相关,图3中假设最大边数n=2,图3的s和t中2边子图相同,共有a-b-c、b-a-b子图两种,然而图3的s和t的结构并不相同,图3的s中2边子图a-b-c共出现了两次,图3的t中2边子图a-b-c共出现了1次,为了在生成的n边dfs子图集上对二者进行区分,在汇集图3的s的2边dfs子图集时子图a-b-c需要出现两次。本发明采用doc2vec模型来学习图的向量表示,而doc2vec神经网络模型在进行训练时依赖于单词之间的顺序关系,因此在汇集n边dfs子图构成子图集的过程中需要谨慎处理子图之间的顺序关系。在doc2vec模型中基于通过目标单词和其上下文单词彼此预测最终求得向量表示,因此目标单词与其上下文的向量表示会比较接近。同时具体到子图集上认为拥有相似结构的子图也应该拥有比较接近的向量表示,因此按照子图的dfscode对子图集进行排序,这样拥有相似结构的子图在语料库中也会比较接近,与某一子图相似的子图集也会出现该子图的上下文中,在最终的向量表示中相似结构子图在向量空间中的距离也相应的会比较接近。步骤s103:将所述子图集输入到神经网络模型中进行训练,得到各图的向量表示;包括:将dfscode格式的子图集视为一篇文档,子图集中的每一个子图视为一个单词,通过doc2vec模型训练得到对应图的向量表示。步骤s103具体包括:doc2vec模型在自然语言处理领域取得了广泛应用,被用于计算文档的向量表示,其原理为将文档id引入语料库中,在训练过程中结合上下文、单词顺序和段落特征,最终得到单词和文档的向量表示。在substructure2vec算法中dfscode格式的子图集被视为一篇文档,子图集中的每一个子图被视为一个单词,最终通过doc2vec模型训练得到整个图的向量表示。采用图4中的pv-dbow模型(distributedbagofwordsversionofparagraphvector)来学习图的表示,pv-dbow模型是doc2vec的一种模型,是skip-gram模型(continuousskip-grammodel)的扩展,其训练方法是忽略输入的上下文,直接让模型去预测文档中的随机单词。具体而言,图被视为一个文档,而子图则被视为一个个单词,通过给定一组图集gs={g1,g2,...,gn},对于图集gs中的一个图gi,其子图集为c(gi)={sg1,sg2,...,sgn},最终的目标是最大化下式:其中sgj∈c(gi),为图gi中的一个子图;其中sgj为子图的向量表示,v为所有子结构的数量。经过网络表示学习后,具有相似子结构的图将具有相似的向量表示。为了优化计算,可以采用负采样技术,通过负采样技术构造一个新的目标函数,同时最大化正样本的似然,最小化负样本的似然,进一步提升了计算的效率。在完成图的表示学习后,如果图gj和gj拥有相似的子图集,则它们的向量表示也会比较接近。(一)实验设置(1)实验数据为了验证本发明的效果,分别在7个带标签数据集和6个无标签数据集上进行分类效果测试,数据集来自各个领域,包括生物信息学、化学及社交网络,其中带标签数据集节点、边统计信息见表2。分别采用mutag、ptc、proteins、nci1、nci109、enzymes及d&d数据集来进行实验验证,其中mutag是188化合物结构的数据集,根据其是否对特定细菌具有诱变效应来对数据进行标识。ptc数据集由344种化合物结构组成,根据其是否对鼠类具有致癌性进行标识。proteins数据集由1113个蛋白质结构组成。nci1、nci109这两个数据集则是与癌细胞研究相关的化合物集合,分别有4110、4127个样本。enzymes包含了6种酶,每种100个蛋白质结构。d&d是蛋白质结构数据集,被标识为酶或非酶两种类型。表2带标签数据集统计数据集样本数平均节点数平均边数图标签节点标签mutag18817.919.827ptc34425.626219proteins111339.172.823enzymes60032.662.163nci1411029.932.3237nci109412729.732.1238d&d1178284.3715.7282无标签数据集分别采用collab、imdb-b、imdb-m、reddit-binary、reddit-multi-5k、reddit-multi-12k数据集来进行实验验证,如表3,n/a表示无。collab是一个科研合作数据集,通过生成不同研究人员的合作网络,并将每个网络标识为研究者的领域,根据研究领域不同共分为高能物理学、凝聚态物理学及天体物理学。imdb-b是imdb收录的电影合作网络数据集,每一张图表示一部电影,节点表示演员,边表示他们之间是否在一部电影里存在合作关系,每部电影被分为动作和爱情两种类型。imdb-m是imdb-b的扩展,它有三张类型构成,分为喜剧、爱情和科幻。reddit-binary数据集采集自reddit网站,其中每个图对于与一个在线讨论,其中节点表示用户,如何两个用户之间存在着相互评论则它们之间存在着边。每个图按照是否是基于问题/答案模式还是讨论模式进行标识。reddit-multi-5k中每个图对于与一个在线讨论,用讨论所属的版块进行标识,共分为5个版块。reddit-multi-12k数据集是reddit-multi-5k数据集的扩充版本,共分为11个不同的版块。表3无标签数据集统计数据集样本数平均节点数平均边数图标签节点标签collab500074.52424.63n/aimdb-b100019.896.42n/aimdb-m15001365.83n/areddit-binary2000429.6497.82n/areddit-multi-5k4999508.5594.95n/areddit-multi-12k11929391.4456.911n/a(2)基线方法为了验证本发明方法的有效性,采用了9种当前最新基线方法:基于图核函数:采用gk、deepgk、weisfeiler-lehmankernal(wl)、deepwl图核函数。有监督的网络表示学习的方法:采用pscn、ecc两种有监督的图表示学习方法来做比对。非监督的网络表示学习方法:采用graph2vec、ge-fsg两种目前最新的无监督网络表示学习方法,这两种算法是主要比对算法,对于graph2vec算法将根子图的阶数设置为2,学习后向量的维度为1024。(3)评估指标为了评估substructure2ve算法的网络表示学习效果,采用支持向量机(supportvectormachine,svm)来对所学习到的图向量进行分类,在实验中选用线性核svm(linear-kernelsvm)来对图向量进行分类。将90%的数据用于训练模型,10%的数据用于预测分类效果,同时为了保证结果的客观性性,进行10次分类训练预测,并取这10次预测准确性的均值为最终的分类准确度。分类准确率为分类正确的样本数与样本总数之间的比值,其中t为分类正确的样本数,f为分类错误的样本数,其计算公式如下:(二)substructure2vec算法参数选择本发明方法在n边dfs子图遍历阶段有1个参数需要设置,该参数为待扩展的最大子图边数n。由图5可以看出,对大多数有标签数据集来说,最大子图边数n一般在2-5边范围内取得最佳分类效果,无标签数据集使用节点的度来作为节点标签,当最大子图边数n为1时获得最佳分类准确度。下面具体介绍最大子图边数n、向量表示的维度d对分类准确率的影响。当需要研究一个参数变化对分类准确率的影响时,需要保持另外参数不变。图5显示在待扩展子图最大边数对分类准确率的影响,此时固定向量表示的维度为512。由图5中可以看出,对于大多数数据集来说,首先分类的准确率随着子图最大边数的增长逐步提升,在达到峰值后又开始了下降,这反映出随着子图最大边数的增大,训练样本不断增多,抽取的子结构信息越发全面,因此分类准确率也会随之提升,同时随着边数的不断增多,噪音数据也不断的增加,在达到峰值后分类准确率也随之下降。图6显示图表示学习的维度与分类准确率之间的关系,固定最大子图边数n为5,可以发现在维度大于64后维度与分类准确率之间相关性较小,比较平稳。(三)分类结果分析(1)有标签数据集分类结果分析通过表4,可以看到,在有标签数据集上本发明方法在大多数数据集上分类效果上优于原有的算法,分别在ptc、nci109、nci1、enzymes、proteins数据集上取得较好效果。具体来说,与无监督算法graph2vec算法对比,本发明准确率提升了5%-90%,与ge-fsg算法相比较在d&d数据集上表现较差,在其它数据集上表现优于ge-fsg算法,分类准确率大致提升了2%-70%。表4有标签图分类结果统计(2)无标签数据集分类结果分析通过表5,可以看到在无标签数据集上本发明在大多数数据集上分类效果上优于原有的算法。具体来说,与gk、deepgk、graph2vec算法相比较,本发明准确率均有较大地提升,而与ge-fsg算法相比较在imdb_b及imdb_m数据上表现稍差,但因collab、reddit-binary、reddit-multi-5k及reddit-multi-12k数据集规模较大,频繁子图挖掘算法的高时间复杂度,已无法在可接受的时间范围内进行频繁子图挖掘,因此ge-fsg算法不适用于上述数据集。综上,在无标签数据集上本发明在分类准确率及适用性方面均取得了较好的效果。表5无标签图分类结果统计(3)子图抽取时间对比分析下面就无监督的图表示学习算法ge-fsg、graph2vec及subsructure2vec算法子图抽取时间进行对比,具体子图抽取时间对比见图7,此时使用ge-fsg算法中指定的支持度阈值,对于graph2vec算法统一将根子图的阶数设置为2,同样subsructure2vec算法也使用表4中指定的最大子图边数阈值n。从图7中可以发现,频繁子图抽取时间随着数据集不同挖掘时间波动较大,尤其是在大型数据集上频繁子图挖掘较耗时,而本发明在特征抽取上因限制了子图扩展最大边数,从而子图抽取较为快速,而graph2vec算法则只需要生成基于节点的根子图,因此其特征抽取时间要优于其它算法。本发明通过在图中遍历n边dfs子图结构,使用dfscode对子图进行唯一标识,通过限定遍历子图的最大边数n来降低子图抽取的时间复杂度,同时由于在整个图范围内抽取n边dfs子图克服了基于节点根子图抽取的片面性,在生成每个图的子图集后将其输入到神经网络模型中得到图的向量表示,可以较全面地抽取子图结构。本发明具有下列特点:1.本发明没有采用高时间复杂度的频繁子图挖掘算法,而是采用了较低时间复杂度的指定大小的n边dfs子图遍历,进而可以在较快的时间内生成子图集,可适用于规模较大的图数据集。2.本发明是完全的无监督的网络表示学习方法,其模型训练过程不依赖类的标签。这也符合现实情况,在现实中需要分类的对象其类别标签往往难以获取,相较于有监督的网络表示学习算法无监督的网络表示学习算法可以更好地适应现实情况。3.不同于基于节点、路径、子图的网络表示学习算法,本发明可以直接学习到整个图的向量表示,从而可以直接应用于分类、聚类等任务中。4.在多个数据集上就分类任务进行实验对比,本发明在大多数数据集上分类准确率有2%-90%的提升。实施例2:如图8所示,一种基于n边dfs子图的轻量级无监督图表示学习装置,包括:子图抽取模块201,用于在图集各图中分别遍历n边dfs子图结构,对各图的n边dfs子图进行抽取;子图汇集模块202,用于对抽取的n边dfs子图进行汇集,构成各图的子图集;图向量表示模块203,用于将所述子图集输入到神经网络模型中进行训练,得到各图的向量表示。具体地,所述子图抽取模块201包括:最小dfscode标识子模块2011,用于采用深度优先子图搜索算法,利用最小dfscode对子图进行唯一标识,将子图转化为文本形式表示;子图抽取子模块2012,用于对于图集中的每一个图依次执行n边dfs子图抽取,首先生成初始1边子图集,之后在生成初始1边子图集上依次进行n边dfs子图挖掘:生成初始边集,由每一条初始边开始逐步扩展,扩展时首先判断当前子图是否dfscode最小,若是则进行该子图的扩展,直到扩展的子图边数达到设定的阈值n,此时停止该子图的扩展,若否则不进行该子图的扩展;由k边子图生成k+1边子图的过程中遵循最右路径扩展原则,首先构造子图的最右路径,之后在最右路径的各节点上分别生成前向边和后向边,将所有新生成的边分别添加到k边子图上构成多个k+1边子图,其中,k+1≤n。进一步地,所述子图汇集模块202包括:子图频度统计子模块2021,用于根据子图实例的数量确定该子图的最小dfscode在相应子图集中出现的次数;不考虑子图重叠问题,同一子图的实例中只要有一个节点不同则视为不同的实例;子图排序子模块2022,用于按照子图的最小dfscode在相应子图集中出现的次数对子图进行排序,构成相应子图集。具体地,所述图向量表示模块203具体用于:将dfscode格式的子图集视为一篇文档,子图集中的每一个子图视为一个单词,通过doc2vec模型训练得到对应图的向量表示。以上所示仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1