基于社区结构的跨社交网络用户身份识别方法与流程
本发明属于社交网络用户识别技术领域,尤其涉及基于社区结构的跨社交网络用户身份识别方法。
背景技术:
随着互联网的快速发展和移动设备的逐渐普及,在线社交网络已经变得越来越流行,给人们之间的交流带来了极大的便利。不同的社交网络提供不同类型的服务,人们通常根据工作与生活的需要加入到不同的社交网络中,社交网络已经成为连接虚拟网络空间和现实物理世界的桥梁。例如,人们通常在foursquare上与朋友分享当前所处的地理位置;在twitter或者facebook上分享图片或文章等。因此,通常情况下每一个用户在多个不同的社交网络中拥有账户,但是这些账户之间常常是相互独立的。
用户身份识别旨在发现同一个用户的多个不同账户之间的对应关系,也称为锚链接预测问题(anchorlinking)、网络对齐问题(networkalignment)。用户身份识别问题的研究是许多有趣互联网应用的前提,例如跨平台好友推荐、用户行为预测、跨网络信息传播等。用户身份识别问题一出现就引起了研究人员的高度重视。
早期的研究通过利用网络用户自身的属性特征和统计特征来解决该问题,例如账户名、性别、年龄等,或者从用户产生的内容中抽取特征,例如推文、博客、帖子、评论等。gona等人(o.goga,d.perito,h.lei,r.teixeira,andr.sommer,″large-scalecorrelationofaccountsacrosssocialnetworks,″technicalreport,2013)仅根据用户公开资料信息将属于同一用户的账户联系在一起。zafarani等人(r.zafaraniandh.liu,“connectingusersacrosssocialmediasites:abehavioral-modelingapproach,”inproceedingsofthe19thacmsigkddinternationalconferenceonknowledgediscoveryanddatamining,2013)将社会学和心理学理论应用于模拟用户行为模式,并在此基础上实现跨社交网络的用户身份识别。
然而,社交网络中存在大量在不同社交网站使用不同用户名的用户。此外,不同社交网站的用户统计信息很可能是不平衡的,不能保证用户信息的丰富性和正确性。因此仅仅依靠用户的属性信息解决身份识别问题的方法的应用范围十分有限。相反的是,社交网络用户之间的连接关系是相对可靠且丰富的,并且网络的结构信息可以直接用于解决用户身份识别问题,于是基于网络结构的用户身份识别问题受到越来越多的关注。cosnet(y.t.zhang,j.tang,z.l.yang,j.pei,andp.s.yu,“cosnet:connectingheterogeneoussocialnetworkswithlocalandglobalconsistency,”inkdd,2015,pp.1485-1494)综合考虑社交网络的局部一致性和全局一致性,基于频率加权的共同邻居特征计算adamic/adar指数,衡量邻域的相似性。man等人(t.man,h.w.shen,s.h.liu,x.l.jin,andx.q.cheng,“predictanchorlinksacrosssocialnetworksviaanembeddingapproach,”inijcai,2016,pp.1823-1829)基于社交网络的潜在特征,开发了基于网络嵌入的锚链接预测模型pale。liu等人(l.liu,w.k.cheung,x.li,andl.j.liao,“aligningusersacrosssocialnetworksusingnetworkembedding,”inijcai,2016)针对有向社交网络提出ione模型,基于网络嵌入从用户的关注关系和被关注关系抽取特征,从而实现用户身份识别。
基于网络结构的现有方法都是从网络中单个用户节点的角度出发,基于节点的上下文信息,提取节点的邻近性特征用于解决用户身份识别问题。但是仅考虑节点的邻近结构,提取的网络特征是十分有限。我们知道,社交网络并不是随机网络,而是具有一定组织特性的结构,社交网络中节点也呈现出集群特性,这被称为社区结构特性。社区结构广泛存在于社交网络中,一个社区可能代表具有共同兴趣、爱好、目标的群体。不妨可以这样理解,facebook中的两个用户由于共同的兴趣,联系紧密,存在于同一个网络社区中,如果他们也都使用twitter,那么他们也很可能通过twitter中的某个社区联系在一起。
技术实现要素:
本发明针对基于网络结构的现有方法从网络中单个用户节点的角度出发,仅考虑节点的邻近结构,提取的网络特征十分有限的问题,提出一种基于社区结构的跨社交网络用户身份识别方法,融合节点的邻近性特征和社区结构特征,最大程度的保留社交网络的结构特征,提高了用户身份识别准确度。
为了实现上述目的,本发明采用以下技术方案:
与现有技术相比,本发明具有的有益效果:
一种基于社区结构的跨社交网络用户身份识别方法,包括:
步骤a、采用网络嵌入的方式分别将源网络和目标网络映射到低维向量空间;
步骤b、基于所述向量空间,通过有监督的方式训练bp神经网络,得到实现从源网络到目标网络映射的bp神经网络模型,在目标网络中通过所述bp神经网络模型对源网络用户身份进行识别。
进一步地,在所述步骤a之前,还包括:
步骤c、对源网络和目标网络进行扩展。
进一步地,所述步骤c包括:
给定源网络gs=(vs,es)和目标网络gt=(vt,et),锚链接的集合t,源网络gs的扩展网络
其中,
用同样的方法,对目标网络gt进行扩展,得到
进一步地,所述步骤b还包括:
基于所述向量空间,通过有监督的方式训练bp神经网络,得到实现从目标网络到源网络映射的bp神经网络模型,在源网络中通过所述bp神经网络模型对目标网络用户身份进行识别。
进一步地,所述网络嵌入的方式包括:m-nmf算法。
进一步地,所述步骤a包括:
步骤a1、社区结构建模,包括:
构造第一目标函数:
q=tr(htbh),s.t.tr(hth)=n(3)
其中q为模块度,
步骤a2、邻近性结构建模,包括:
构造第二目标函数:
其中,
步骤a3、统一网络表示模型构建,包括:
构造第三目标函数:
其中,
结合第一目标函数、第二目标函数及第三目标函数,得到网络嵌入过程的总体目标函数:
s.t.m≥0,u≥0,h≥0,c≥0,tr(htbh)=n,α>0,β>0(8)
其中,α和β为控制各项损失在总的目标函数中所占的比重。
进一步地,所述步骤b包括:
步骤b1、对所述总体目标函数求最优解,得出对应的向量空间;
步骤b2、对于锚节点对
步骤b3、基于所述向量空间及所述损失函数,通过有监督的方式训练bp神经网络,构建第四目标函数:
其中,
步骤b4、最小化第四目标函数,得到实现从源网络到目标网络映射的bp神经网络模型;
步骤b5、针对源网络中的非锚节点
与现有技术相比,本发明具有的有益效果:
本发明研究了跨社交网络的用户身份识别问题,并提出了一个新颖的解决方法。网络结构作为社交网络的一个重要特征,有效地利用网络结构有助于解决用户身份识别问题。之前的许多研究都是从社交网络中单个节点的角度出发,从节点的上下文中提取网络的邻近性结构特征,忽略了社交网络的社区结构这个重要的结构特征。本发明在学习社交网络节点的特征向量表示的过程中,同时融合社交网络的邻近性结构特征和社区结构特征,最大程度的保留社交网络的结构特征;然后基于已标记的锚节点,应用反向传播算法训练多层神经网络,得到一个稳定的跨社交网络的映射函数,提高了用户身份识别准确度。
附图说明
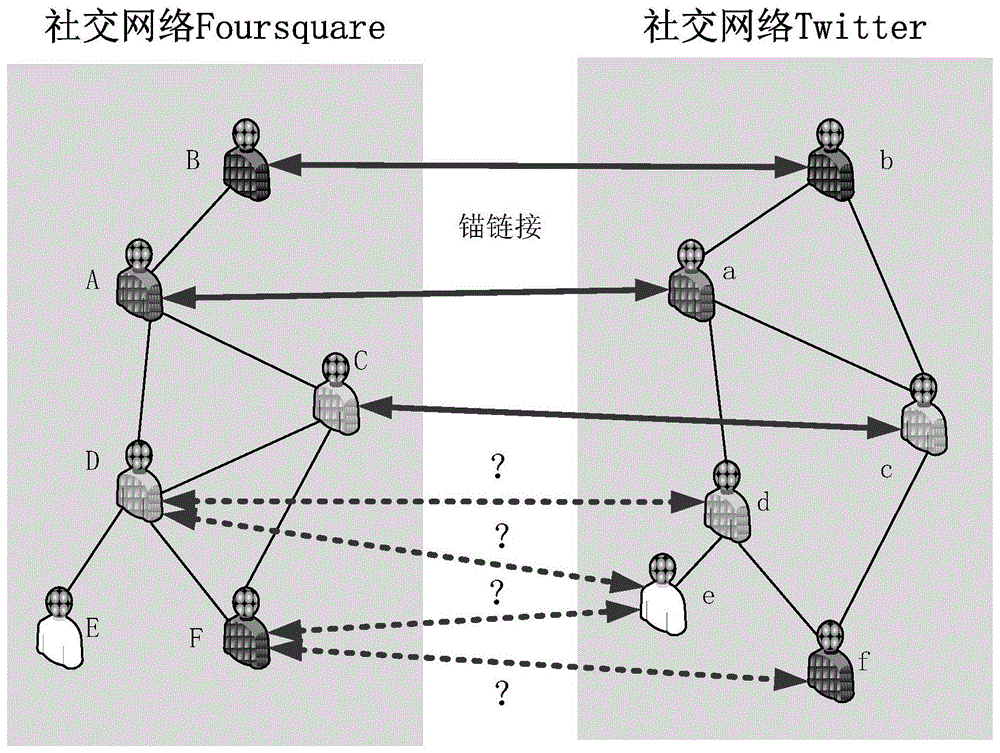
图1为跨社交网络用户身份识别问题实例图;其中,(a,a)为锚链接,表示a和a是同一用户在foursquare和twitter两个社交网络中的账户;
图2为一种基于社区结构的跨社交网络用户身份识别方法的基本流程图;
图3为一种基于社区结构的跨社交网络用户身份识别方法的流程示意图;其中,带符号‘▲’的实线(如a-a和b-b)表示锚链接;带符号‘■’的虚线(如b-c和d-c)表示缺失的边;
图4为twitter-foursquare数据集上的实验结果对比图;其中,(a)为不同匹配度k值下的实验结果;(b)为不同锚节点训练比例r下的precision@30;(c)为不同训练迭代次数i下的precision@30;(d)为不同向量维度d下的precision@30;
图5为网络的重叠抽样实例图;其中,虚线表示锚链接;
图6为合成网络数据集上的实验结果对比图;其中,(a)为不同interop下的precision@5;(b)为不同互通性(interop)下precision@1、precision@5、precision@10、precision@15、precision@30的比较。
具体实施方式
下面结合附图和具体的实施例对本发明做进一步的解释说明:
1、术语定义
本发明研究的对象是无向无权图,所以将社交网络表示为g=(v,e),其中v是社交网络中用户节点的集合,e是社交网络中用户连接关系的集合。由于本发明中以两个社交网络为例,所以用gs=(vs,es)表示源网络(sourcenetwork),用gt=(vt,et)表示目标网络(targetnetwork)。
以源网络gs为例,表1总结了本发明中的表示方法,目标网络gt表示类似。后续当其他符号或者定义首次出现时,再对其进行解释。
表1:符号表示
为了描述方便,有以下定义,图1给出了示例,其中,foursquarenetwork为源网络,twitternetwork为目标网络。
定义1:用户和账户。用户是社交网络应用的使用者参与者,其对应于现实世界中的个人实体;账户是用户在使用社交网络应用时用于表示身份的载体。
定义2:锚链接。对于一个链接
定义3:锚节点。如果链接
定义4:候选锚链接。网络gs中的非锚节点
2、问题陈述
基于以上的术语定义,提出跨社交网络的身份识别问题。假设有两个在线社交网络gs和gt,已知一部分锚链接的集合t。源网络、目标网络、仅包含锚节点的源网络和仅包含锚节点的目标网络,对应的向量表示空间分别为us、ut、
但是,实际上各个网络的潜在表示空间是相互独立的,一个网络潜在表示空间对于其他网络是未知的,所以想要获得一个理想的函数φu十分困难。在实际的应用中,大多数算法试图将身份识别问题转化为优化问题。本发明引入从源网络gs到目标网络gt的映射函数φ,定义如下:
φ(us)=ut′
这样可以通过最小化向量空间ut与ut′之间的距离,得到映射函数φ。
同理,可以利用同样的方法得到从目标网络gt向源网络gs的映射函数φ-1。
值得说明的是,在实际的社交网络环境下,有些用户在同一社交网络中拥有多个账户,但经常假设这些多个账户是独立的并且属于不同的个人。即是,对于每个用户,只确定了其中一个账户。因此后叙不再详细地区分用户、账户与节点的概念。
如图2-3所示,一种基于社区结构的跨社交网络用户身份识别方法,包括:
步骤s101、采用网络嵌入的方式分别将源网络和目标网络映射到低维向量空间;
步骤s102、基于所述向量空间,通过有监督的方式训练bp神经网络,得到实现从源网络到目标网络映射的bp神经网络模型,在目标网络中通过所述bp神经网络模型对源网络用户身份进行识别。
作为一种可实施方式,在所述步骤s101之前,还包括:
对源网络和目标网络进行扩展:
给定源网络gs=(vs,es)和目标网络gt=(vt,et),锚链接的集合t,源网络gs的扩展网络
其中,
用同样的方法,对目标网络gt进行扩展,得到
具体地,所述步骤s101还包括:
基于所述向量空间,通过有监督的方式训练bp神经网络,得到实现从目标网络到源网络映射的bp神经网络模型,在源网络中通过所述bp神经网络模型对目标网络用户身份进行识别。
具体地,所述网络嵌入的方式包括:m-nmf算法。
具体地,所述步骤s101包括:
在得到两个扩展网络之后,使用网络嵌入的方法分别将它们映射到低维向量空间。利用节点表示和社区结构之间的一致关系,在一个统一的框架中联合优化基于非负矩阵分解的表示模型和基于模块化的社区检测模型,使得节点的向量表示能够保留邻近性结构特征和社区结构特征。本发明在网络嵌入阶段,使用m-nmf算法完成由网络空间到向量空间的映射。
为了方便叙述,步骤s101中不区分源网络和目标网络,使用g=(v,e),vi∈v,eij∈e表示网络,用a=[aij]为网络g的邻接矩阵。
s1011、社区结构建模,包括:
社区结构是复杂网络的重要特征之一,可以用来表达网络的一些功能和特征。使用模块度对社团结构进行建模。
定义:模块度(modularity)。模块度也称模块化度量值,是目前常用的一种衡量网络社团结构强度的方法。假设网络g被分成两个社团,则模块度定义成:
如果节点vi属于社团1,那么hi=1;如果节点vi属于社团2,那么hi=-1。ki表示节点vi的度,
定义模块度矩阵
当将网络划分为k(k>2)个社团时,使用矩阵
q=tr(htbh),s.t.tr(hth)=n(3)
其中tr(hth)表示矩阵hth的迹。
步骤s1012、邻近性结构建模,包括:
定义:一阶邻近性。一阶邻近性表征了的两个直接相连节点间的相似程度。例如,对于节点对(vi,vj),如果aij>0,那么节点vi和节点vj之间存在(正的)一阶邻近性。否则,定义节点vi和节点vj之间的一阶邻近性为0。一阶邻近性的形式化表达如下:
对于节点vi和vj,
一阶邻近性是对网络结构的直接表达,如果两个节点是相互连接的,那么这两个节点在低维向量空间中应该是相近的。但是在实际的社交网络中,节点之间的连接关系是十分稀疏的。对于没有直接连接关系的两个节点,并不意味着这两个节点没有相似性。
事实上,在社交网络中,拥有许多共同朋友的人很可能分享相同的兴趣关注共同的话题,并且成为朋友。因此如果两个节点拥有许多共同邻居,尽管它们没有直接的连接关系,那么也可以认为这两个节点是相似的。为了能充分地利用社交网络的邻近性特征,利用丰富的二阶邻近关系来弥补一阶邻近的稀疏问题。
定义:二阶邻近性。一对节点的二阶邻近性就是它们邻域网络结构之间的相似性。用
对于节点vi和vj,
为了同时保存网络结构的一阶邻近性和二阶邻近性,使用相似性矩阵s表示网络的邻近性结构特征,s=s(1)+ηs(2),其中η>0表示二阶邻近性在邻近性结构特征中的权重。为了近似性地表示相似性矩阵s,引入非负基矩阵
其中,
步骤s1013、统一网络表示模型构建,包括:
上述对网络结构建模的最终目的是将社交网络的邻近性结构特征和社区结构特征融合在一个统一的框架中。为了达到这个目的,引入社区表示矩阵
最后,结合公式(3)、(6)、(7),可以得到网络嵌入过程的总体目标函数:
s.t.m≥0,u≥0,h≥0,c≥0,tr(htbh)=n,α>0,β>0(8)
其中,α和β为控制各项损失在总的目标函数中所占的比重。
从总体目标函数可以看出,使用社团表示矩阵c将基于网络表示学习得到的向量空间u映射到社团指示矩阵h,这样就建立了u和h之间的联系。节点表示矩阵u受到邻近性特征s和社团特征h的约束,所以能够保存原始网络更多的结构信息。
具体地,所述步骤s102包括:
步骤s1021、对所述总体目标函数求最优解,得出对应的向量空间;
步骤s1022、在获得每个社交网络的向量空间后,将已知锚节点组成的向量空间作为先验知识,通过有监督的方式训练神经网络,旨在得到从源网络gs到目标网络gt的映射函数。给定任意一个锚节点对
其中cos(·)表示两个向量之间的余弦相似性,范围为[-1,+1],值越大说明两个向量差异性越小。
步骤s1023、假设源网络和目标网络中有l个锚节点对,它们对应的向量空间分别用
其中,w、b分别表示通过有监督的方式训练bp神经网络后得到的权重参数和偏置参数;
步骤s1024、最小化第四目标函数,得到实现从源网络到目标网络映射的bp神经网络模型;
步骤s1025、针对源网络中的非锚节点
值得说明的是:
(1)虽然在本发明中以两个社交网络为例,但是可以很方便地扩展到多个社交网络。例如可以采取“链式策略”实现跨多个社交网络的用户身份识别,g1→g2→g3...。
(2)在本发明中,网络扩展阶段并不是必要的。这个阶段主要是利用已知的锚链接信息,丰富网络的连接关系,保证在网络嵌入阶段能尽可能地保留网络的结构特征。
(3)虽然本发明基于网络结构进行用户身份识别,但是可以很方便地与网络中用户的属性信息相结合,提高身份识别的准确性,例如用户名、用户地理位置等用户属性。
为了验证本发明的有效性,进行如下实验:
将本发明方法与现有的方法分别在真实的社交网络数据集和合成数据集上进行实验,为表述方便,将本发明方法简称为cuil(communitystructure-baseduseridentitylinkage)。真实的社交网络数据集由提供,包含了twitter和foursquare两个社交网络。合成数据集从斯坦福网络分析项目(stanfordnetworkanalysisproject,snap)中的ca-astroph数据集通过抽取子网的方式得到。
1、实验设置、基准方法和评估指标
(1)实验设置
在方法cuil中,在网络表示阶段,使用m-nmf方法分别对源网络和目标网络进行表示,选用300作为节点向量的维度。在通过神经网络进行映射学习阶段,使用了四层bp神经网络:输入层(300维)、隐藏层一(500维)、隐藏层二(800维)、输出层(300维),学习率设置为0.0001。
(2)基准方法
本发明主要研究基于社交网络结构的用户身份识别,将cuil方法与当前使用网络结构进行用户身份识别的最新方法进行比较分析。
mag:基于传统图的流形对齐方法(mag),通过计算用户对(vi,vj)之间的权重w(vi,vj),为每个社交网络构建一个社交图。每个用户的相似性排序通过流形对齐方法得到。其中权重由公式
mah:基于超图的流形对齐方法(mah),使用超图模拟网络的高阶关系,例如关注相同的兴趣组或者参与相同的活动。mah应用网络嵌入的方法将两个网络的节点表示到同一个低维向量空间,通过比较低维向量空间中两个向量的距离推断用户之间的关联性。对于源网络中的一个用户,mah通过计算这个用户与目标网络中的用户是同一个用户的概率得到相似性排序。
ione:输入-输出网络嵌入(ione),将用户的关注关系和被关注关系用输入向量、节点向量、输出向量三个向量表示,利用负采样和基于已知锚节点的约束得到低维向量空间,并通过梯度下降算法进行训练,达到对齐网络的目的。
deeplink:基于深度神经网络的用户身份识别算法(deeplink),通过随机游走对网络结构进行采样,通过网络嵌入将节点用低维向量表示,保存网络的局部和全局结构特征,并通过对偶式学习的方式训练深层神经网络模型,实现用户身份识别。与之前的方法相比,deeplink达到了最好效果。
puil:基于邻近结构的用户身份链接(puil)只基于邻近结构,而不考虑社区结构。将puil作为一个基准方法,以便直观地与cuil进行比较。
(3)评估指标
使用precision@k(p@k)作为评价指标,其中,k为匹配度。在用户身份识别问题中,precision@k(p@k)与传统的评估指标recall@k和f1@k是相同的。precision@k(p@k)的值越高,说明方法的性能越好。
其中n表示测试集中锚节点的数量,
2、在真实数据集上的实验
在进行实验之前介绍互通性的概念。在真实的社交网络环境中,不同的社交网络之间在用户和连接关系上是重叠的,用户重叠是所有用户身份识别算法的基本假设,而连接关系重叠为基于网络结构进行用户身份识别的算法奠定了基础。考虑到不同的社交网络具有不同的网络结构,为了表示两个网络之间连接关系的重叠程度,引入互通性(interoperability,简写为interop):
(1)真实数据集选择
第一个数据集由twitter和foursquare两个社交网络的真实数据组成,表2描述了数据集的具体信息。
表2真实社交网络数据集
在实验中,分别将twitter和foursquare作为源网络gs和目标网络gt,经过“网络扩展”阶段,twitter和foursquare两个社交网络的连接关系数量分别是170476和95402,互通性interop为0.2236。
(2)结果分析
针对数据集中的1609对锚节点,随机选取1300对锚节点作为训练集,进行300k次的迭代训练。在进行比较分析时,分别选取p@1、p@5、p@9、p@13、p@21、p@30作为比较指标,将cuil方法与基准方法进行比较分析,表3列举了详细的结果信息。
表3:存twitter-foursquare数据集上的实验结果对比
为了直观地进行分析比较,将结果展示在折线图中,如图4中(a)。ione方法在进行网络嵌入的过程中考虑了社交网络中的关注关系与被关注关系,比mag、puil方法和mah方法表现得好。deeplink方法作为当前最好的方法,它的表现优于其他基准方法。与ione和deeplink方法相比,cuil方法不仅考虑了社交网络的邻近性结构特征,而且还在网络嵌入的过程中融合了社区结构特征,保留了社交网络更多的原始结构信息,从结果上可以看出,cuil方法表现得最好。
同时也考虑了用于训练的锚节点比例r、训练迭代次数i以及向量维度d等实验参数对实验结果的影响,图4中(b)、(c)、(d)分别列举了实验结果随参数r、i和d的变化。
如图4中(b)所示,将用于训练的锚节点比例从0.1逐渐增加到0.9,cuil方法的表现都优于其他基准方法,甚至当训练样例的比例仅为0.1或者0.2时,cuil表现得也是十分出色。
算法达到收敛条件所需的迭代次数也是一个重要参数。从图4中(c)可以看出,与ione相比,cuil、puil和deeplink都没有出现过拟合的问题。同时与puil、deeplink相比,cuil能够更快地达到收敛,并且达到更好的效果。
图4中(d)展示了实验结果随节点向量维度的变化。ione、deeplink、puil和cuil在低维度向量上表现都很好,其中当维度不高于100时,deeplink表现得最出色。但是当维度达到200时,cuil的表现明显高于其他方法。随着计算机性能的提升和机器学习算法的不断优化,向量的维度不再是制约算法性能的难题。因此对于cuil,为了得到更好的效果,向量维度达到200或者300也是可以接受的。
3、在合成数据集上的实验
不同的社交网络具有不同的网络结构,跨社交网络的用户身份识别的性能通常取决于两个网络的重叠程度。为了进一步分析cuil方法与ione、deeplink等基准方法的性能,通过从合作网络中抽取子网的方式构造数据集,在不同网络重叠程度的环境下进行实验,分析其对用户身份识别问题的影响。
(1)合成数据集选择
第二个数据集来自snap提供的ca-astroph数据集,包含了18772个用户节点,198110条无向边。将网络中的节点按照度数进行降序排列,选取前5000个节点作为节点集,最终可以得到一个5000个用户节点,118934条连接关系的网络,称它为原始网络。
这里引入αs和αc两个参数,αs表示从原始网络中抽取子网的稀疏程度,αc表示抽取得到的两个子网的重叠程度。采取如下的随机抽样策略从原始网络中抽取两个子网络:
对于网络中的任意一个节点,赋予一个概率值p,均匀分布在[0,1]上。如果p≤1-2αs+αsαc,那么将这个节点丢弃;如果1-2αs+αsαc<p≤1-αs,那么将这个节点添加到第一个子网中;如果1-αs<p≤1-αsαc,那么将这个节点添加到第二个子网中;如果1-αsαc<p≤1,那么将这个节点同时添加到两个子网中。图5展示了抽取子网时网络的重叠抽样示意图,表4描述了得到子网的详细信息。
表4:合成网络数据集
(2)结果分析
实验中,将两个子网subnet1和subnet2分别作为源网络gs和目标网络gt,从锚节点对中随机选取1000对锚节点作为训练集(当参数αs=0.6,αc=0.3时,用于训练的锚节点数量为500),进行300k次的迭代训练。
图6中(a)显示了puil、ione、deeplink和cull四种不同的方法在不同interop取值下的表现。我们可以观察到,随着interop取值的增加,各种方法的表现也在不断提升。从网络重叠程度的角度来讲,如果两个网络相同的边越多,那么用户身份识别的效果就越好。但是明显地,与puil、ione方法和deeplink方法相比,cuil方法表现得更好。
图6中(b)显示了在应用cuil方法下,评估指标precision@1/5/10/15/30随interop的变化情况。从图中可以看出,当interop仅为0.1左右时,cuil方法的表现十分出色;当interop达到0.2左右时,cuil方法的表现有了一个更加明显的提升。
本发明研究了跨社交网络的用户身份识别问题,并提出了一个新颖的解决方法。网络结构作为社交网络的一个重要特征,有效地利用网络结构有助于解决用户身份识别问题。之前的许多研究都是从社交网络中单个节点的角度出发,从节点的上下文中提取网络的邻近性结构特征,忽略了社交网络的社区结构这个重要的结构特征。本发明在学习社交网络节点的特征向量表示的过程中,同时融合社交网络的邻近性结构特征和社区结构特征,最大程度的保留社交网络的结构特征;然后基于已标记的锚节点,应用反向传播算法训练多层神经网络,得到一个稳定的跨社交网络的映射函数,提高了用户身份识别准确度。
以上所示仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!