一种基于深卷积神经网络的自然场景图像文本检测方法与流程
本发明涉及一种文本检测方法,具体为一种基于深卷积神经网络的自然场景图像文本检测方法,属于防护装置应用技术领域。
背景技术:
随着多媒体信息技术的发展,从大数据中获取有用信息的技术具有广阔的前景。文本中包含的信息是直接有效的。文本信息的数字化对提高多媒体检索、工业自动化和场景理解能力具有重要意义。目前,传统的文档检测技术已经取得了很大的成就。然而,复杂自然场景图像的检测具有更大的探索空间和应用前景。与传统文献图像相比,自然图像与传统文献图像的最大区别在于自然场景图像背景复杂多变,图像存在失真、不完整、模糊、断裂等现象。也会有噪音,图像中的照明、低分辨率和角度干扰。自然场景图像中的文本检测与识别是计算机视觉领域的重要组成部分。在自然场景中,特征提取是字符检测和识别的关键和难点。虽然已经做了大量的工作来定义一组好的文本特性,但是实际应用中使用的大多数特性并不是通用的。在极端情况下,许多特征几乎是无效的,甚至是无法提取的,例如笔划、形状特征等。另一方面,定义和提取人工特征是一项费时费力的工作。因此,对复杂自然图像的文本检测和识别具有很大的压力和挑战。
在east模型中,利用全卷积网络(fcn)生成多尺度融合特征图,直接进行像素级文本块预测。在该模型中,文本区域标记分为旋转矩形框和任意四边形两种。该模型对英语单词的检测效果较好,对中文长文本行的检测效果较差。融合文本分割网络(ftsn)模型利用分割网络支持倾斜文本检测,它以resnet-101为基本网络,采用多尺度融合特征图。注释数据包括像素掩模和文本实例的边界,并采用像素预测和边界检测的联合训练。
技术实现要素:
本发明的目的就在于为了解决上述的问题,而提出一种基于深卷积神经网络的自然场景图像文本检测方法。
本发明的目的可以通过以下技术方案实现:一种基于深卷积神经网络的自然场景图像文本检测方法,该方法具体包括以下步骤:
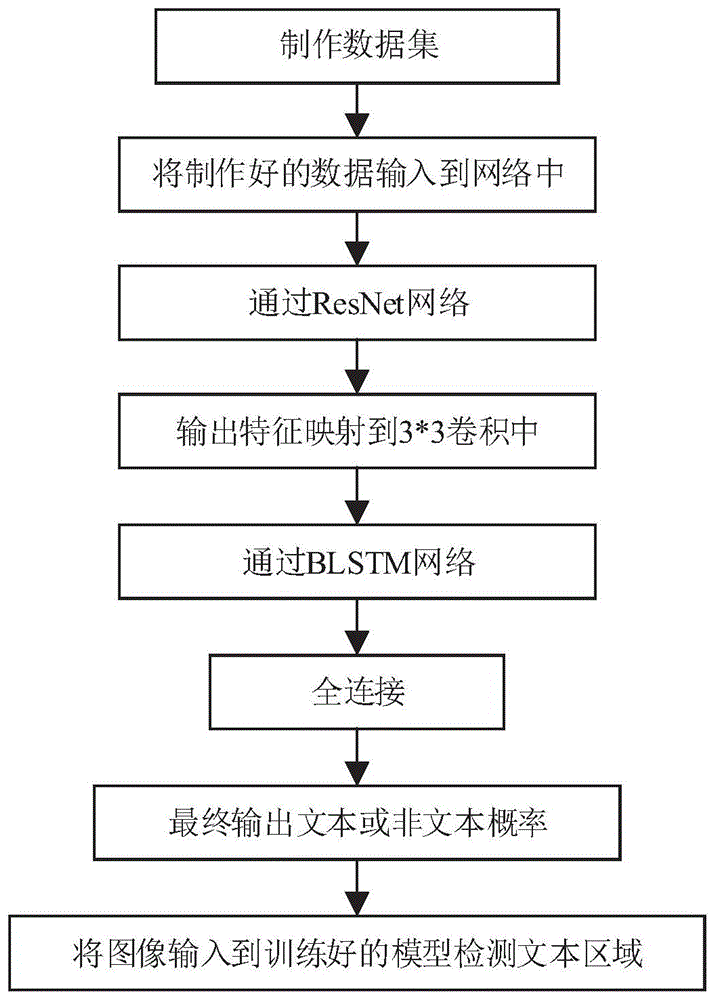
步骤一:制作数据集,将所有图片按照voc格式制作成数据集,建立文件夹annotation、imagesets和jpeglmages;
其中,文件夹annotation用于存放xml文件,每一个xml文件对应一张图像,并且每个xml文件中存放的是标记的各个目标的位置和类别信息,命名通常与对应的原始图像一样;
所述imagesets中的main文件夹用于存放文本文件,所述文本文件为train.txt或test.txt,文本文件里面的内容是用于训练或测试的图像的名字,imagesets我们只需要用到main文件夹,这里面存放的是一些文本文件,通常为train.txt、test.txt等,该文本文件里面的内容是需要用来训练或测试的图像的名字(无后缀无路径);jpeglmages文件夹中放已按统一规则命名好的原始图像;
所述jpeglmages中用于存放已按统一规则命名好的原始图像;
步骤二:训练网络,把制作好的数据集输入到网络中进行训练,迭代50epoch,每次输入30张图片(batch_size=30),每完成一次迭代进行一起验证,最后保存最好的模型作为检测模型,训练步骤如下:
a.首先经过resnet网络从底层像素点获取更多的高级特征;
b.将结果映射到3*3的卷积中,3*3是最小的能够捕获像素八邻域信息的尺寸;
c.然后利用blstm层提取字符序列的上下文特征,引入了fasterr-cnn垂直定位点的思想,找到检测文本的边界框;
d.全接连;
e.输出文本或非文本的概率;
步骤三:将图像输入到已经训练好的模型中用来检测图像中的文本区域。
与现有技术相比,本发明的有益效果是:
1、本发明通过使用自动学习,结合上下文特征替换人工定义的特征。
2、本发明避免字符分割问题,实现端到端的无约束字符检测,提高了检测效率和精度,实现了对自然场景图像的文本检测。
附图说明
为了便于本领域技术人员理解,下面结合附图对本发明作进一步的说明。
图1为本发明整体工作流程图。
具体实施方式
下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实施例1
请参阅图1所示,一种基于深卷积神经网络的自然场景图像文本检测方法,该方法具体包括以下步骤:
步骤一:制作数据集,将所有图片按照voc格式制作成数据集,建立文件夹annotation、imagesets和jpeglmages:
其中,文件夹annotation用于存放xml文件,每一个xml文件对应一张图像,并且每个xml文件中存放的是标记的各个目标的位置和类别信息,命名通常与对应的原始图像一样;
所述imagesets中的main文件夹用于存放文本文件,所述文本文件为train.txt或test.txt,文本文件里面的内容是用于训练或测试的图像的名字,imagesets我们只需要用到main文件夹,这里面存放的是一些文本文件,通常为train.txt、test.txt等,该文本文件里面的内容是需要用来训练或测试的图像的名字(无后缀无路径);jpeglmages文件夹中放已按统一规则命名好的原始图像;
所述jpeglmages中用于存放已按统一规则命名好的原始图像;
步骤二:训练网络,把制作好的数据集输入到网络中进行训练,迭代50epoch(1个epoch等于使用训练集中的全部样本训练一次),每次输入30张图片(batch_size=30,代表批量大小,将决定我们一次训练的样本数目),每完成一次迭代进行一起验证,最后保存最好的模型作为检测模型,训练步骤如下:
a.首先经过resnet网络从底层像素点获取更多的高级特征;
b.将结果映射到3*3的卷积中,3*3是最小的能够捕获像素八邻域信息的尺寸;
c.然后利用blstm层提取字符序列的上下文特征,引入了fasterr-cnn垂直定位点的思想(一种经典的深度学习目标检测算法),找到检测文本的边界框;
d.全接连;
e.输出文本或非文本的概率;
步骤三:将图像输入到已经训练好的模型中用来检测图像中的文本区域。
实施例2
一种基于深卷积神经网络的自然场景图像文本检测方法,该方法具体包括以下步骤:
步骤一:制作数据集。我们把所有图片按照voc格式制作成数据集,这里面用到文件夹annotation、imagesets和jpeglmages。其中文件夹annotation中主要存放xml文件,每一个xml对应一张图像,并且每个xml中存放的是标记的各个目标的位置和类别信息,命名通常与对应的原始图像一样;而imagesets我们只需要用到main文件夹,这里面存放的是一些文本文件,通常为train.txt、test.txt等,该文本文件里面的内容是需要用来训练或测试的图像的名字(无后缀无路径);jpeglmages文件夹中放我们已按统一规则命名好的原始图像。
步骤二:训练网络,把制作好的数据集输入到网络中进行训练,迭代50epoch(1个epoch等于使用训练集中的全部样本训练一次),每次输入30张图片(batch_size=30,代表批量大小,将决定我们一次训练的样本数目),每完成一次迭代进行一起验证,最后保存最好的模型作为检测模型,训练步骤如下:
a.首先经过resnet网络从底层像素点获取更多的高级特征;
b.将结果映射到3*3的卷积中;
c.然后利用blstm层提取字符序列的上下文特征,引入了fasterr-cnn垂直定位点的思想(一种经典的深度学习目标检测算法),找到检测文本的边界框。
全接连。
输出文本或非文本的概率。
(3)将图像输入到已经训练好的模型中用来检测图像中的文本区域。
下表为两种公共数据集(icdar2011和icdar2013)的对比结果:
上表中,是icdar2011和icdar2013两种数据集的最新成果。p代表精度,r代表召回,f代表f度量。最佳性能用粗体和红色表示。本发明的方法优于其他方法,特别是在icdar2013数据集上,本发明比方法textflow从p值0.85增加到0.91,并且在r/f值方面取得了巨大进展。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!