基于对抗样本的抗成员推理攻击的AI模型隐私保护方法与流程
本发明属于计算机信息安全、人工智能安全领域,具体涉及一种基于对抗样本的抗成员推理攻击的ai模型隐私保护方法。
背景技术:
当今,机器学习模型已被广泛应用于图像处理、自然语言处理、音频识别、无人驾驶汽车、智慧医疗、数据分析等各类领域。以数据分析领域为例,许多企业都在使用机器学习模型来分析其大规模的用户数据,或者把训练的机器学习模型发布在互联网上为他人提供服务。用户可以用自身的数据来对模型进行查询,即将数据输入模型来观察模型的输出。同时,一些企业(如google、microsoft等)也提供了机器学习服务平台(machinelearningasaservice)。数据的持有者可以通过这种平台来训练自己的机器学习模型,也可以以黑盒的形式公布训练完成后的模型。他人能使用平台提供的api对模型进行查询,但对模型的内部参数一无所知。这种作为服务平台的机器学习模型往往需要在大规模的数据上进行训练才能得到,而这些训练数据中可能会涉及到许多用户的隐私数据,如:患病记录、照片或生活习惯等。
在现实的场景中,攻击者可以通过对模型进行查询来判定一条给定的数据是否属于该机器学习模型的训练集数据集,这种隐私窃取的方式被称为成员推理攻击。假设攻击者拥有一定的背景知识,他可以通过比较目标模型对给定数据的输出和对不属于训练集的数据的输出的差异来判断该给定数据是否属于目标模型的训练集。一个过拟合的机器学习模型(在训练集上具有很高的准确率,但是在测试集上的准确率却很低)对属于训练集的数据的输出和不属于训练集的数据的输出差异十分明显,这便给了攻击者窃取数据隐私提供了可乘之机。
现有的成员推理攻击的防御方法大多是在目标模型的训练过程中添加防御措施。例如对抗正则化,这种方法是防御者在训练目标模型时,让目标模型与成员推理模型交互训练,训练过程中既要提高目标模型对成员推理模型的防御能力,也要减小成员推理模型的推理准确率。但是这种方法的缺点在于修改目标模型的损失函数改变了目标模型的训练过程,使得目标模型的训练不易收敛,且对训练完成后目标模型的性能造成了较大的影响。同时,与成员推理模型的交互训练加长了目标模型的训练时间。
技术实现要素:
发明目的:本发明的目的是提供一种基于对抗样本的抗成员推理攻击的ai模型隐私保护方法。
技术实现要素:
本发明所述的一种基于对抗样本的抗成员推理攻击的ai模型隐私保护方法,包括以下步骤:
(1)用普通无防御方式训练目标模型;
(2)将成员推理模型与目标模型进行交互训练得到训练好的成员推理模型;训练成员推理模型的方式为,将数据输入到目标模型中得到目标模型输出的预测标签向量,将目标模型输出的预测标量向量和数据原始标签输入到成员推理模型中得到成员推理模型的输出,以梯度下降的方式调整成员推理模型的参数,迭代训练成员推理模型直到达到设置的迭代步数为止;
(3)当目标模型接收到数据输入时,将目标模型输出的预测标签向量和该预测标签向量经过独热编码转换后的独热标签输入到步骤(2)训练好的成员推理模型中,再利用成员推理模型的输出使用快速梯度符号法对目标模型输出的预测标签向量进行扰动,即构造出针对成员推理模型的对抗样本;以50%的概率将对抗样本作为目标模型的最终输出,否则保持原输出不变。
步骤(1)所述的目标模型为分类模型,即f:x→y,其中x表示数据的特征集合,y表示数据的标签集合,该标签为经过独热编码后形成的向量,即:若该数据属于第k类,则向量的第k个分量为1,其余的所有分量为0;将数据的特征输入目标模型,目标模型的输出即为对输入数据标签的预测,这个预测标签是一个多维向量lpredicted=[l1,l2,…,lm],其中m为整个数据集中包含的类别数,向量的每个分量li,(i=1,2,…,m)可以看作该数据属于第i类的置信度。
步骤(2)所述的成员推理模型为一个映射i:y×y→[0,1];成员推理模型的架构如图2所示,其中预测层为一个4层的全连接神经网络,预测层的输入为目标模型接收某个数据后输出的预测标签向量,预测层的输出为一个m3维的向量;标签层为一个3层的全连接神经网络,标签层的输入为该数据的标签,标签层的输出为一个m3维的向量;连接层为一个3层的全连接神经网络,连接层的输入为一个2m3维向量,由预测层和标签层所输出的两个m3维向量拼接而成,连接层的输出为数据属于目标模型训练集的概率,是一个在[0,1]内取值的数;通常用3个指标accuracy,precision,recall来衡量成员推理模型的效果;accuracy为成员推理模型对所有数据的判断正确率;假设用于测试成员推理模型的数据个数为a1,成员推理模型判断正确的数据个数为b1,则accuracy=b1/a1;precision为成员推理模型判断为属于目标模型训练集的数据中真正属于训练集数据的比例;假设成员推理模型判断为属于训练集的数据个数为a2,在这些数据中真正属于训练集的个数为b2,则precision=b2/a2;recall为成员推理模型对目标模型训练集的召回率;假设目标模型训练集中数据个数为a3,在这些数据中,成员推理模型判断为属于训练集的数据个数为b3,则recall=b3/a3。
所述步骤(3)包括以下步骤:
(31)当目标模型f接收到给定输入x*时,得到初始输出f(x*);
(32)将初始输出f(x*)经过独热编码转换为标签
(33)将目标模型的输入x*、目标模型的初始输出f(x*)和由f(x*)经过独热编码转化后的标签
(34)若
若
其中,f(x*)为目标模型原始输出,f(x*)adv为目标模型输出的对抗样本,ε为构造对抗样本的步长,
(36)当目标模型被投入使用时,防御者并不知道自己的模型受到的交互是正常的还是恶意的,所以目标模型以50%的概率输出对抗样本f(x*)adv,否则保持原输出f(x*)不变。
步骤(34)所述的构造针对成员推理模型对抗样本的方式还可以为:
其中,f(x*)为目标模型原始输出,f(x*)adv为目标模型输出的对抗样本,ε为构造对抗样本的步长,
有益效果:与现有技术相比,本发明的有益效果:1、无需改变模型的训练方式,并消除了传统防御方式所带来的梯度不稳定、训练不收敛、收敛速度慢等问题;2、以对抗样本作为输出干扰成员推理模型,只对目标模型的原始输出添加细微的扰动,便能明显干扰成员推理模型的输出,在达到防御成员推理攻击效果的同时,并不会对目标模型的性能造成显著的影响。
传统防御方式,以对抗正则化为例,需要进行目标模型和成员推理模型的交互训练,这种交互训练意味着将目标模型和成员推理模型共同训练,增加了目标模型的训练时间。而本方法不修改模型的训练方式,只在模型的输出上加以扰动,所使用的快速梯度符号法(fgsm)可以快速地生成对抗样本,对目标模型施加这一防御方式所增加的时间成本较低。以实验数据进行说明,该实验在colab中进行,使用一块teslat4gpu,深度学习框架为pytorch,以vgg-16模型作为目标模型,数据集为cifar-10。以普通(无防御)的方式训练目标模型,gpu运算20分钟即可达到正常效果;使用对抗正则化方式进行防御,交替训练目标模型与成员推理模型时,目标模型每迭代1轮,成员推理模型迭代7轮,这种方法需要经过106分钟的gpu运算才能将模型训练完毕;在同样的实验环境下,使用本发明中基于对抗样本的方法只需要单独训练目标模型和成员推理模型,训练目标模型大约需要20分钟的gpu运算,训练成员推理模型需5分钟gpu运算,时间总和大约为25分钟。
以对抗样本作为输出干扰成员推理模型,只对目标模型的原始输出添加细微的扰动,便能明显干扰成员推理模型的输出,在达到防御成员推理攻击效果的同时,并不会对目标模型的性能造成较大的影响。而传统方法,以对抗正则化为例,修改了目标模型的损失函数,影响了目标模型的训练进程,训练后的目标模型虽具有一定的防御效果,但是模型的性能受到了很大的影响。以实验数据进行说明,该实验在colab中进行,使用一块teslat4gpu,深度学习框架为pytorch,目标模型为vgg-16,数据集为cifar-10。以无防御的方式训练目标模型,能在训练集和测试集上分别达到89%和63%的准确率;在经过本发明所提出的对目标模型的输出添加对抗样本处理后(构造对抗样本的步长ε=1),目标模型在训练集和测试集上的准确率分别为84%和60%;而使用正则化系数λ=1的对抗正则化防御方法后,目标模型在训练集和测试集上的准确率分别降至68%和62%。
实验结果如表1所示(表中的推理模型即成员推理模型):
表1对抗正则化与本发明(生成对抗样本)的实验效果对比
附图说明
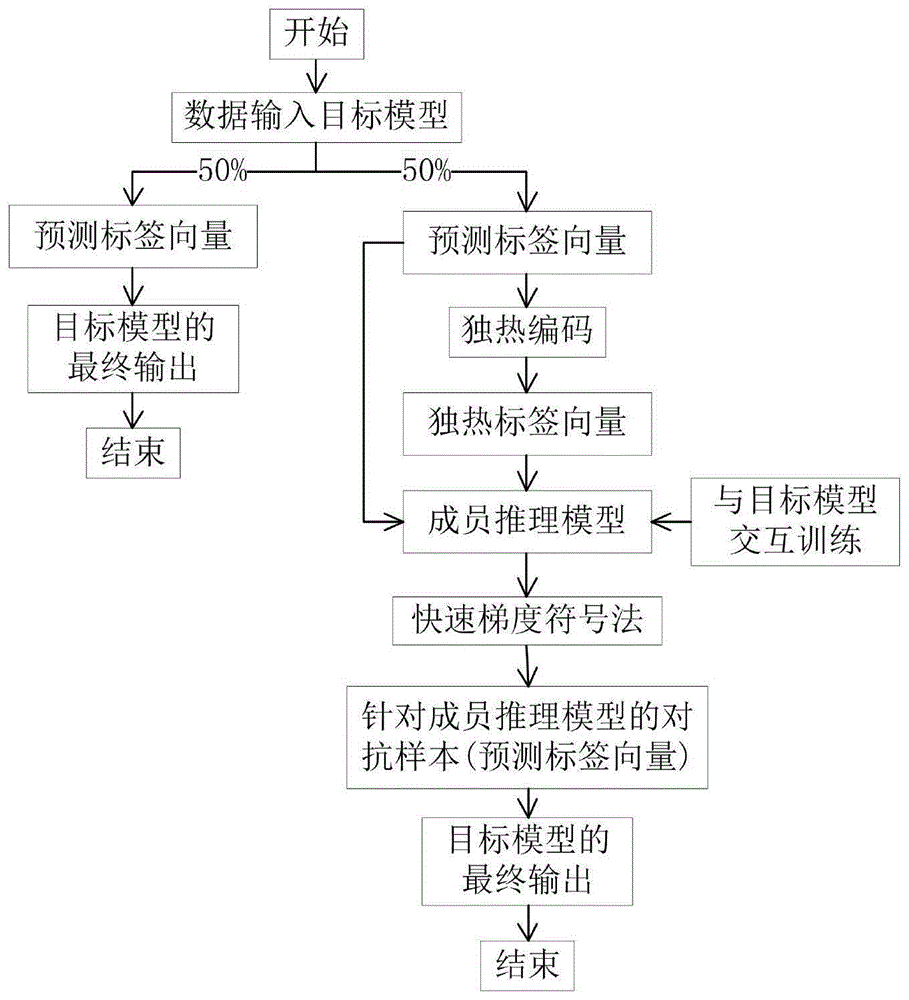
图1为本发明的流程图;
图2成员推理模型的架构图;
图3为成员推理模型的训练方式框图;
图4为对目标模型输出构造对抗样本的流程图;
图5为成员推理模型的评估指标随对抗样本步长的变化图。
具体实施方式
如图1所示,本发明的具体实施方式可分为如下步骤:
1、选择数据集和目标模型,该目标模型为分类器,将数据集划分为训练集和测试集,选择合适的损失函数、学习率、优化方式和迭代步数等训练目标模型。
2、选用如图2所示的成员推理模型架构,设置架构中的参数m、m1、m2、m3、m4、m5,其中m设置为数据集中所含的类别数,m1、m2、m3设置在[m,1.5m]范围内,m4=2m3,m5设置在[m4,1.5m4]范围内。将目标模型测试集按数据量对半划分为两个数据集
其中,|t|和
成员推理模型的训练方式如图3所示,在每一轮训练中成员推理模型接收训练数据(x,y)∈t和
3、每当目标模型接收到输入x时,将初始输出f(x)经过独热编码转化为标签
第1种:
第2种:
以下用3个具体的实例来说明上述步骤。
实例一:
该实例在colab中进行,所用深度学习框架为pytorch。以resnet-34作为目标模型;数据集为cifar-10,该数据集中有60000张32×32的3通道(rgb)图片,分为10个类别,其中50000张作为训练集,10000张作为测试集。在训练目标模型时,设置损失函数为交叉熵函数(crossentropyloss),使用adam优化方式,学习率设置为0.0005,迭代步数为20轮。训练完成后,目标模型在训练集上的准确率为99%,在测试集上的准确率为56%。
用于构造对抗样本的成员推理模型架构如图2所示,它有两个输入,分别为目标模型对某个数据的输出、该数据的标签,其中预测层、标签层、连接层三个子网络网络每层的维度参数设置为m=10、m1=1024、m2=512、m3=64、m4=258、m5=64。
在训练用于构造对抗样本的成员推理模型时,使用目标模型测试集的前5000张图片作为非训练集数据
接下来对目标模型的输出构造对抗样本,构造流程如图4所示,目标模型每次接收到输入x*,首先将预测向量转化为独热编码后的标签向量,再将预测向量(即原输出)和标签向量输入到训练好的成员推理模型中,得到成员推理模型的输出
其中步长ε设置为2.25。目标模型在接收到输入时以50%的概率输出对抗样本,否则保持原输出不变。
为测试本发明在该实例中的效果,本实例重新训练一个成员推理模型,该成员推理模型在训练中与添加了对抗样本输出的目标模型交互,除此之外,所用训练数据、测试数据、损失函数、优化方式、学习率、迭代步数等与本实例中用于构造对抗样本的成员推理模型均相同。重新训练后的成员推理模型在测试集上的3个评估指标分别下降为accuracy=63%,precision=61%,recall=75%。同时目标模型在训练集和测试集上的准确率分别为93%和49%。图5展示了设置不同对抗样本步长ε(步长越大对抗样本的强度越大)所对应的成员推理模型的精度变化,结果表明步长越大成员推理模型的精度越低。
实验结果如表2所示(表中的推理模型即成员推理模型),目标模型为resnet-34,步长ε=2.25:
表2实例一的实验结果
实例二:
该实例在colab环境下进行,深度学习框架为pytorch,该实例使用只包含输入输出层的线性神经网络作为目标模型,所用数据集为at&t人脸图片集,该数据集含有400张112×92的灰度单通道图片,分为40类,每一类有10张图片,随机选取其中300张图片作为训练集,100张图片作为测试集。目标模型的损失函数为交叉熵函数,优化方式为sgd,学习率为0.001,迭代30轮。训练完成后,目标模型在训练集上的准确率为100%,在测试集上的准确率为95%。
在该实例中,用于构造对抗样本的成员推理模型的架构如图一所示,与实例一中用于构造对抗样本的成员推理模型架构相同。选取目标模型训练集中前100张图片作为训练集数据t,选用目标模型测试集作为非训练集数据
在对抗样本构造中,每当目标模型接收到输入时,构造对抗样本的步长ε设置为在[0,0.5]范围内随机选取,选用第1种构造对抗样本的方式:
除步长的选取不同之外,其他流程与实例一中构造对抗样本的流程相同。
为测试本发明在该实例中的效果,重新训练一个成员推理模型,该成员推理模型在训练时与输出中添加了对抗样本的目标模型交互,除此之外,该模型所用训练数据、测试数据、损失函数、优化方式、学习率、迭代步数等均与本实例中用于构造对抗样本的成员推理模型相同。该成员推理模型在测试集上的3个评估指标分别下降为accuracy=72%,precision=64%,recall=99%。同时目标模型在训练集和测试集上的准确率分别为100%和94%。实验结果如表3所示(表中的推理模型即成员推理模型),其中目标模型为只含输入输出层的线性神经网络,步长ε在[0,0.5]内随机选取:
表3实例二的实验结果
实例三:
该实例在colab环境下进行,深度学习框架为pytorch,所用目标模型为vgg-16,数据集为cifar-10,该数据集包含60000张32×32的3通道(rgb)图片,分为10类,其中训练集含有50000张图片,测试集含有10000张图片。在训练目标模型时,设置损失函数为交叉熵函数(crossentropyloss),使用adam优化方式,其中学习率设置为0.0001,迭代步数为20轮。训练完成后,目标模型在训练集上的准确率为89%,在测试集上的准确率为63%。
在训练用于构造对抗样本的成员推理模型时,使用目标模型的测试集的前5000张图片作为非训练集数据
在构造对抗样本的过程中,选用第2种构造对抗样本的方式:
构造对抗样本的步长ε设定为[1,5]内的随机值,其他步骤与设置均与实例一中构造对抗样本的流程相同。
为测试本发明的效果,除在原目标模型上施加防御以外,使用与构造对抗样本模型相同训练数据、测试数据、损失函数、优化方式、学习率、迭代步数重新训练一个成员推理模型。该成员推理模型在测试集上的3个评估指标分别下降为accuracy=49%,precision=50%,recall=46%。同时目标模型在训练集和测试集上的准确率分别为88%和67%。实验结果如表4所示(表中的推理模型即成员推理模型),其中目标模型为vgg-16,步长ε设定为[1,5]间的随机值:
表4实例三的实验结果
- 还没有人留言评论。精彩留言会获得点赞!