一种生成式对话系统解码器训练方法及解码方法与流程
本发明涉及一种基于双向递归神经网络的生成式对话系统解码器训练方法及解码方法,属于计算机软件技术领域。
背景技术:
传统解码器通常会根据编码端所生成的问句的向量表示,使用lstm等神经网络结构逐字的生成问题对应的回复。其中当前单词的生成主要依赖于句子中位于其前面的历史信息,它的主要特点是单向解码。
传统的解码器已经能够很好的根据问题的向量表示生成对应的答案,然而因为该编码器是单向的,因此在生成第t个单词时只能够参考到前面的历史信息。然而通常情况下,单词的后文也是有助于当前单词的预测的,比如“天空是()的,大海也是蓝色的”,如果能够参考句子括号后面的信息,解码器就容易知道句中所缺失的单词应该是“蓝色”。而如果仅仅使用单向解码的方式对编码器生成的编码向量进行解码,则解码器容易生成错误的单词。因此如何在解码的时候能够将当前单词的前后文信息引入到解码过程中,也就是进行双向解码,是一件非常有意义的工作。
技术实现要素:
本发明针对传统编码器的缺陷,提出了一种基于双向递归神经网络的生成式对话系统解码器训练方法及解码方法。使得解码器在生成单词时不仅考虑到单词的前文,也能充分的利用句子的后文信息,从而提高生成式对话系统生成回复的质量。
本发明的技术关键点在于:
1)本发明提出一种使用双向解码器来对编码器产生的向量进行解码的方法,该方法在解码时不仅可以借鉴句子的前文信息,也可以对句子的未来信息进行展望,从而使得生成式对话系统的解码质量得到极大的提高。
2)本文提出两种惩罚函数来对生成式对话系统模型进行优化。首先,通过计算每一步的前向神经网络和后向神经网络的隐藏层状态编码差的f范数以及二者预测结果的交叉熵损失函数之和作为预测当前单词的差异性的度量,从而帮助前向神经网络与后向神经网络进行信息的同步。
局部惩罚项函数计算如下:
其中,
此外,我们还提出了一种整体损失函数。该函数首先使用注意力机制计算两个神经网络所生成回复的句子向量表示,然后利用f范式来衡量二者的整体差异性,并进行权重约束,从而防止句子过度关注于局部差异。
通过注意力机制计算前向神经网络回复句子的向量表示如下:
其中,k表示k时刻,n表示最后时刻,t表示t时刻,z为对话系统中问题的编码表示,hf为前向神经网络的整体向量表示,α为一个全连接神经网络,atf为第t个单词对于hf的重要程度。
因此,整体损失函数表示为:
loss=-∑logpf(xt|x≤t)-∑logpf(xt|x≥t)+γ(∑lt+||hf-hb||f)(2)
其中hb为后向神经网络的整体表示,其计算方法与前向神经网络的计算方法相同;
本发明采用的技术方案如下:
一种生成式对话系统解码器训练方法,其步骤包括:
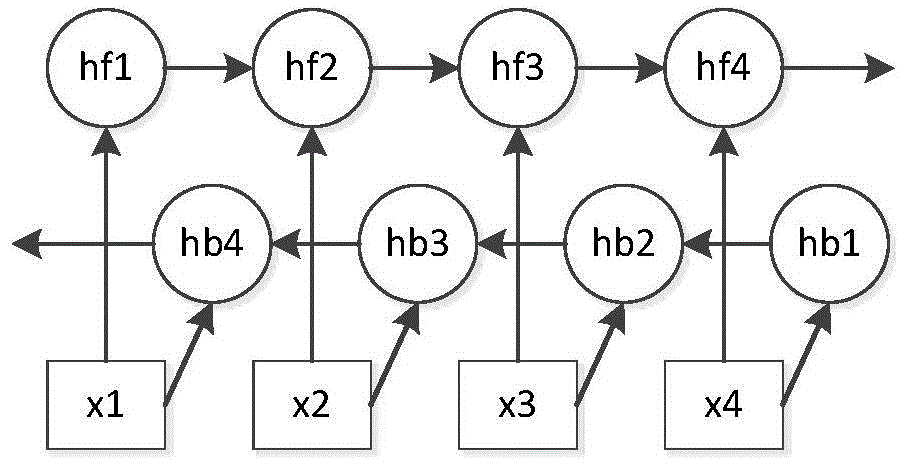
11)对于问句编码集合中的每一问句编码,使用前向神经网络对该问句编码从前向后进行预测得到一向量表示结果,使用后向神经网络对该问句编码从后向前进行预测得到另一向量表示结果;
12)计算前向神经网络和后向神经网络每一步的预测结果的差异,作为生成式对话系统编码器的损失函数;
13)计算前向神经网络和后向神经网络每一步状态的差异,作为二者的局部差异;
14)计算前向神经网络与后向神经网络所生成向量表示结果的句子向量表示,并计算两句子向量表示的差异,作为二者的整体性差异;
15)将步骤13)得到的局部差异和步骤14)得到的整体性差异作为惩罚项函数加入步骤12)得到的损失函数中,得到整体惩罚函数作为生成式对话系统编码器的损失函数;
16)通过最小化该整体损失函数,达到前向神经网络和后向神经网络预测结果同步时结束训练。
进一步的,前向神经网络和后向神经网络分别为一递归神经网络,两递归神经网络的维度相同,但参数不共享。
进一步的,整体损失函数loss=-∑logpf(xt|x≤t)-∑logpf(xt|x≥t)+γ(∑lt+||hf-hb||f);其中,
进一步的,使用注意力机制计算前向神经网络所生成回复的句子向量表示hf、后向神经网络所生成回复的句子向量表示hb。
进一步的,步骤12)中,使用交叉熵损失函数来计算前向神经网络和后向神经网络每一步的预测结果的差异,作为生成式对话系统编码器的损失函数。
一种基于双向递归神经网络的生成式对话系统解码方法,其特征在于,采用训练后的解码器中的前向神经网络对生成式对话系统编码器所传过来的问句编码进行预测,生成回复内容。
本发明主要包括以下步骤:
1)使用前向解码器(即前向神经网络)对生成式对话系统编码器传来的问句编码的历史信息进行预测得到一向量表示结果,使用后向解码器(即后向神经网络)对生成式对话系统编码器传来的问句编码的未来信息进行预测得到另一向量表示结果。
2)对前向神经网络和后向神经网络分别预测的结果进行同步。
3)计算前向神经网络与后向神经网络的局部差异损失:
4)计算前向神经网络与后向神经网络的整体差异损失:||hf-hb||f。
5)将3)与4)计算出来的结果加入损失函数,在训练过程中,通过最小化损失函数,从而使得3)和4)中局部差异损失和整体差异损失最小化,达到前向神经网络和后向神经网络预测结果同步的效果,即帮助生成式对话模型进行结果同步,优化解码器的生成回复效果,损失函数公式见公式(2)。
进一步地,步骤1)中,我们根据编码器传来的问句编码分别使用两个递归神经网络分别从前向和后向两个方向来对答案进行预测,其中两个递归神经网络的维度完全相同,但参数不共享。
进一步地,步骤2)中,我们使用交叉熵函数作为局部损失函数来对两个神经网络的预测结果进行差异衡量,从而对前向和后向两个神经网络的预测结果进行同步,从而使得前向神经网络在预测时能在一定程度上考虑到未来信息,提高问句的解码质量。
进一步地,步骤3)中,为了帮助前向神经网络与后向神经网络的预测,我们通过f范数来计算前向神经网络与后向神经网络每一步隐藏层状态的不同,并将其累加作为局部损失函数的惩罚项,从而使得二者的同步效果更好更快。
进一步地,步骤4)中,为了防止生成式对话系统模型关注于局部差异,从而导致回复生成效果下降,我们首先使用注意力机制提取出前向神经网络与后向神经网络所生成的句子的重要信息并生成其句子向量表示,通过f范式来计算二者的差异性作为二者生成句子的整体性差异,并加入到损失函数中。
进一步地,步骤5)中,我们将步骤3)以及步骤4)计算的惩罚项分别乘以不同系数放入到该生成式对话系统编码器的损失函数中。
与现有技术相比,本发明的积极效果为:
1)本发明在使用前向神经网络从前到后预测句子时,同时使用后向神经网络从后往前预测单词序列,从而使得生成式对话系统模型能够同时对历史信息进行总结和对未来信息展望,在生成回复的每一步都有一个更整体的考虑,随后,为了促进前向lstm网络和后向lstm网络的同步,我们通过在损失函数添加两个预测网络的差值,从而激励两个神经网络更好更快的生成尽可能相同的序列,从而提高了解码器的回复生成质量。
2)在开放领域的问答系统中,对比于传统的端到端生成式对话系统,本发明在bleu和perplexity等指标下均取得了一定程度上的提升。
附图说明
图1是本发明方法的总体流程示意图。
图2是本发明的局部损失函数计算流程图。
图3是本发明的整体损失函数计算流程图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明。
下面提供一个采用本发明方法的具体实例:
1)使用编码器所传过来的问句编码,分别使用两个神经网络从前往后和从后往前两个方向来对回复内容进行预测,得到两个回复,其中从前往后的回复生成主要依赖于回复的历史信息,而从后往前的回复生成主要依赖于回复的未来信息;
2)使用交叉熵损失函数来计算前向神经网络和后向神经网络每一步的预测结果的差异,作为生成式对话系统解码器的损失函数;
3)计算两个神经网络每一步状态的差异,作为二者的局部差异,具体计算方法为将二者每一步对应的隐藏层状态进行相减,然后求取对应的f范数;
4)使用注意力机制分别得到前向神经网络与后向神经网络所生成回复的句子向量表示,具体做法为,首先使用双向lstm对回复进行编码,然后使用最后一次迭代的神经网络的隐藏层状态作为句子的整体表示,使用该表示分别与句子中每一步的神经网络状态计算相关度得分,最后将句子所有的状态进行加权求和,从而得到了所生成回复的句子向量表示;
5)使用神经网络计算4)中得到的两个神经网络的句子向量表示的差异,作为二者的整体性差异,并将步骤3)得到的局部差异和该整体性差异作为惩罚项函数加入损失函数中进行生成式对话系统编码器训练;
6)训练结束,只使用前向神经网络对编码器所传过来的问句编码进行预测。
尽管为说明目的公开了本发明的具体内容、实施算法以及附图,其目的在于帮助理解本发明的内容并据以实施,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书最佳实施例和附图所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!