一种基于知识图谱的学术圈构建方法与流程
本发明涉及学术社交网络技术领域,具体是指一种基于知识图谱的学术圈构建方法。
背景技术:
随着计算机网络技术的发展,学术社交网络的平台化与网络化也得到了迅速发展,为学者提供了良好的学术交流平台。目前,国内外较著名的学术社交网络有researchgate、academia、科学网以及小木虫。随着学术活动和科学研究的开展,每天都会有新的学者和科研人员的加入,这样将导致学者数量的猛烈剧增和学者用户类型的多样化,因此,一个良好的学术社交网络将成为各个领域学者科研成果研讨和学术交流的重要平台。研究人员可以在学术社交网络上进行合作,参与同行评审,分享他们的研究,甚至分享研究数据。因此,它受到了大量学者的青睐,尤其是年轻学者。可以说,学术社交网络正在逐渐改变我们的研究方式。学术社交网络的研究价值已经引起了学者们的密切关注。研究人员对学术社交网络进行了大量的研究,发现学术社交网络在促进科学交流与合作,以及进行替代计量方面发挥着积极的作用。
早在2000年,国外学术界就尝试建立起专门针对研究人员的专业性社交网络,如scilinks、scientistso-lutions、naturenetwork等,为研究人员的在线交流提供基本服务。随着面向大众的社交网络不断发展,face-book、twitter等知名社交网站也开始尝试为研究人员搭建学术交流平台,但其学术服务的专业性受到了一些学者的质疑。直到2008年,国外出现了以researchgate、mendeley为代表的在线学术交流平台,融入了开放获取与社交网络的理念,不仅可以帮助研究人员发现相同领域的学者并为他们提供在线服务,还能为研究人员提供获取大量有价值知识资源的渠道。随后,国内也出现了一批具备相似功能的网站,其中有代表性的包括学者网、天玑学术圈、百度学术、科学网、cnki学者圈等。这些致力于促进学术交流与合作的网站推动了学术社交网络的兴起与发展。学术社交网络是以促进知识交流和扩散为目的,能够帮助研究者建立和维护他们的人际关系网络,同时能够支持他们在研究过程中从事各项活动的服务或者平台。
而目前学术社交网络存在以下问题:现有的学术社交网络为其用户提供良好合作平台的功能,但是真正在上面建立起来的合作关系却非常少。其原因为,现有的学术社交网络为学者提供多个群组,可供学者根据自己的专业背景和兴趣爱好加入不同学科和主题的群组中,导致大部分群组都是来自不同学科背景的成员组成,进而使得群组存在明显的交叉现象,使得现有学术信息数据存储零散,使得以存储零散的学术信息数据为基础建立的学术圈数据不精确。
技术实现要素:
针对现有学术信息数据存储零散和构建的学术圈数据不精确的问题,本发明提出一种基于知识图谱的学术圈构建方法,可以提高学术圈数据的精确度。
为实现上述技术目的,本发明采用如下技术方案:
一种基于知识图谱的学术圈构建方法,包括以下步骤:
步骤1,获取所有学术论文信息和所有学术期刊信息,并作为初始数据源;
步骤2,从初始数据源中抽取预选实体类型的实体信息,构成实体数据集;所述预选实体类型包括作者、论文和期刊;
步骤3,对实体数据集中同名的作者实体,基于相互之间的相似度进行同名消歧处理;
步骤4,将同名消歧处理后得到的实体数据集存储在neo4j图数据库中,形成实体节点;基于不同实体间的公共属性特征,为不同实体节点间建立关系边,最终得到基于知识图谱的学术圈。
本发明通过从初始数据源中抽取作者、论文和期刊3种类型的实体,并利用neo4j图数据库构建实体节点;然后在neo4j图数据库中利用不同实体间的公共属性特征为不同实体节点建立关系边,得到基于知识图谱的学术圈。相当于将论文、作者和期刊三种不同类型的实体以及实体间关系连接到一张关系网络中,构成相互关联的学术圈,进而用户可以通过该具有逻辑关系的学术圈,迅速有效地获取到所需知识以及所需知识间的逻辑关系,可以全面地了解相关领域信息,为用户提供精确有效寻找潜在合作伙伴提供支撑,还可以为科技评审专家的遴选提供辅助决策等。
同时,在抽取实体时,相当于将初始数据源中的无效信息剔除掉,保留有效信息以建立各类型的实体,可以提高实体数据的有效性,进而提高所构建的学术圈数据的精确度。
而且,通过对实体数据集中同名的作者实体进行消歧处理,也可以提高实体数据的准确性,进而提高学术圈数据的精确度。
进一步地,所述步骤3的具体过程为:
步骤3.1,将作者实体表示为由其属性值构成的特征向量;
步骤3.2,取所有同名的作者实体,通过计算任意两个同名的作者实体之间的相似度,并与相似度阈值比较,取大于相似度阈值的最大相似度值,将最大相似度值所对应的两个同名的作者实体聚类为一簇,得到一个作者实体集;
其中,任意两个同名的作者之间的相似度计算公式为:
sij表示两个同名的作者实体ai与作者实体aj之间的相似度,simattr()表示相似度计算函数;
步骤3.3,取与上一步骤得到的作者实体集同名的其他任一作者实体,若与作者实体集中任一个作者实体之间的相似度大于相似度阈值,则将该作者实体加入上一步骤得到的作者实体集中;
步骤3.4,将剩余的同名作者实体,重新按步骤3.2至步骤3.3进行处理,直到对所有同名作者实体匹配到相应的作者实体集;
步骤3.5,将同一作者实体集中的所有作者实体合并为同一个作者实体,并为得到的作者实体设置作者id;且所有不同作者实体集中的作者实体的作者id设置为不同。
进一步地,将作者实体表示为由以下属性值所组成的特征向量,所述以下属性值包括:作者名、科研领域、所属单位和合著者。
进一步地,所述学术论文信息通过采用爬虫技术从webofscience文献数据库中获取得到,所述学术期刊信息通过采用爬虫技术从letpub网页中获取得到,且学术论文信息和学术期刊信息分别保存于相同csv格式的不同文件中。
采用爬虫技术获取分布广泛且关联度低的学术论文信息和学术期刊信息,以构建实体并基于公共属性建立实体关系,可以精简学术圈的数据架构,使得学术圈的可用性更高。
进一步地,步骤2中从初始数据源中抽取预选实体类型的实体信息,构成实体数据集的具体过程为:
步骤2.1,将初始数据源导入数据库中;
步骤2.2,从初始数据源提取数据:
在数据库中从初始数据源的学术论文信息中提取数据:论文名、论文关键字、科研领域、作者、年份、期刊名、期刊id;在数据库中从初始数据源的学术期刊信息中提取数据:期刊名、期刊id、影响因子、分区;
步骤2.3,从步骤2.2提取的数据中抽取所有的论文实体、作者实体和期刊实体,构成实体数据集;
其中,得到的论文实体包括属性:论文名、论文id、作者、年份、期刊名,期刊id;得到的作者实体包括属性:作者名、合著者、科研领域、所属单位;得到的期刊实体包括属性:期刊名、期刊id、影响因子、分区;所述合著者是从学术论文信息中提取作者实体时,抽取论文的通讯作者和第一作者得到;
每个实体的每个属性均按照三元组形式保存为:(实体,属性名,属性值)。
进一步地,所述步骤4的具体过程为:
步骤4.1,将实体数据集中的所有实体从数据库中导出为csv格式的文件,然后导入到neo4j图数据库中,每个id对应的实体在neo4j图数据库中均形成一个实体节点;
步骤4.2,利用不同实体之间公共的属性特征,提取不同实体之间的关系:不同作者实体之间为合作关系、作者实体与论文实体之间为发表关系、期刊实体与论文实体之间为收录关系;
步骤4.3,在neo4j图数据库中,将具有关系的实体节点之间使用相应关系类型的边进行连接。
有益效果
本方案通过从初始数据源中抽取作者、论文和期刊3种类型的实体,并利用neo4j图数据库构建实体节点;然后在neo4j图数据库中利用不同实体间的公共属性特征为不同实体节点建立关系边,得到基于知识图谱的学术圈。相当于将论文、作者和期刊三种不同类型的实体以及实体间关系连接到一张关系网络中,构成相互关联的学术圈,进而用户可以通过该具有逻辑关系的学术圈,迅速有效地获取到所需知识以及所需知识间的逻辑关系,可以全面地了解相关领域信息,为用户提供精确有效寻找潜在合作伙伴提供支撑,还可以为科技评审专家的遴选提供辅助决策等。
同时,在抽取实体时,相当于将初始数据源中的无效信息剔除掉,保留有效信息以建立各类型的实体,可以提高实体数据的有效性,进而提高所构建的学术圈数据的精确度。
而且,通过对实体数据集中同名的作者实体进行消歧处理,也可以提高实体数据的准确性,进而提高学术圈数据的精确度。
附图说明
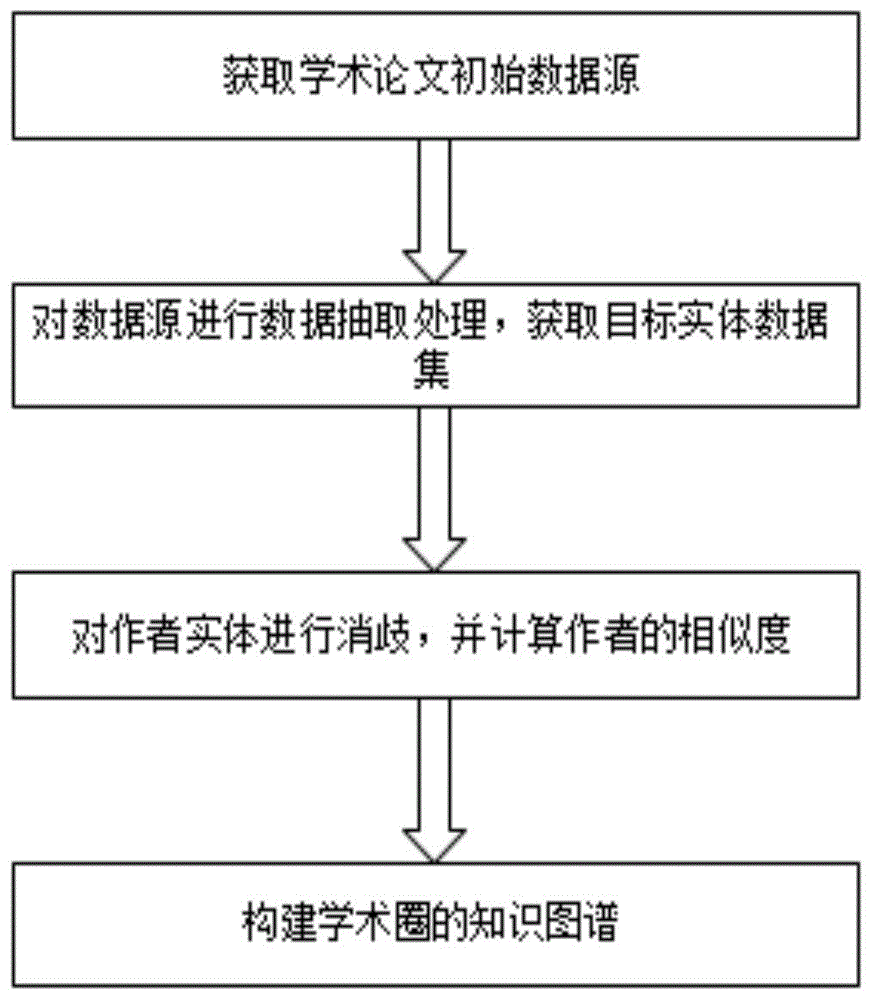
图1为本发明所述方法的流程图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例以本发明的技术方案为依据开展,给出了详细的实施方式和具体的操作过程,对本发明的技术方案作进一步解释说明。
本发明提供的一种基于知识图谱的学术圈构建方法,通过提取数据、抽取实体、建立实体关系,将论文、作者和期刊三种不同类型的实体以及实体间关系连接到一张关系网络中,构成相互关联的学术圈,进而用户可以通过该具有逻辑关系的学术圈,迅速有效地获取到所需知识以及所需知识间的逻辑关系,可以全面地了解相关领域信息。
本发明基于知识图谱的学术圈构建方法,如图1所示,包括以下步骤:
步骤1,获取所有学术论文信息和所有学术期刊信息,并作为初始数据源;
为了数据的真实性,本实施例采用爬虫技术从webofscience文献数据库中进行数据的爬取获取学术论文信息,从letpub网页中进行数据的爬取获取学术期刊信息,且学术论文信息和学术期刊信息分别保存于不同的excel表格中。
学术论文信息包括论文名、作者、期刊名和科研领域等。在爬取学术论文信息读取论文txt文件时,如果读取文件没问题则继续,如果读取文件有遗漏则重新读取该论文文件。且webofscience文献数据库只支持一次下载500条信息,因此需要循环每500条信息下载一次,每次下载点击导出即可获得以csv表格文件为格式的学术论文信息列表,将爬取的数据写入到csv格式文件中,并通过选择制表符分隔关键字段,并隔断时间进行刷新。然后将爬取的数据放入excel表格里面,每一行代表一篇学术论文的相关信息。分析具体字段信息,并将每一列中有多个数据的字段进行分离,得到最终的与学术论文信息对应的excel表格文件。
学术期刊信息包括期刊名、影响因子、分区等,其中,影响因子和分区是评判期刊水平的指标。对学术期刊信息的爬取与保存方法,与学术论文信息相同,在此不再赘述。
步骤2,从初始数据源中抽取预选实体类型的实体信息,构成实体数据集;
数据量庞大的初始数据源中,有较多信息是没有实际使用价值的数据,将其构建于学术圈中不但构建工作量大,而且使得到的学术圈数据繁杂影响使用,因此本发明有针对性地对其中的数据进行预处理和清洗,将不需要的数据去除掉,留下重要的数据。比如将文章类型、语种和特刊等数据处理掉,而留下作者名、科研领域、论文关键字等有用信息。
步骤2.1,利用数据库的管理软件,将excel表中的学术论文信息和学术期刊信息导入到数据库中;
步骤2.2,从初始数据源提取数据:
在数据库中从初始数据源的学术论文信息中提取数据:论文名、论文id、科研领域、作者、作者所属单位、年份、期刊名、期刊id;在数据库中从初始数据源的学术期刊信息中提取数据:期刊名、期刊id、影响因子、分区;
步骤2.3,从步骤2.2提取的数据中抽取所有的论文实体、作者实体和期刊实体,构成实体数据集;
其中,得到的论文实体包括属性:论文名、论文id、作者、年份、期刊名、期刊id;得到的作者实体包括属性:作者名、合著者、科研领域、所属单位;得到的期刊实体包括属性:期刊名、期刊id、影响因子、分区;所述合著者是从学术论文信息中提取作者实体时,抽取论文的通讯作者和第一作者得到;
每个实体的每个属性均按照三元组形式保存为:实体-属性名-属性值。例如,张三-单位-中南大学构成了一个(实体,属性名,属性值)的三元组样例。
步骤3,对实体数据集中同名的作者实体,基于相互之间的相似度进行同名消歧处理,并设置作者id;
本发明将作者消歧问题转化为聚类问题来实现。
步骤3.1,将作者实体表示为由以作者名、科研领域、所属单位和合著者所组成的特征向量;
利用word2vec工具将作者实体的作者名、科研领域、所属单位和合著者这4个属性特征分别训练成为词向量,且将每个词向量均归一化为(0,1)之间的小数,再将4个归一化后的小数组成特征向量用来表示该作者实体;
步骤3.2,取所有同名的作者实体,通过计算任意两个同名的作者实体之间的相似度,并与相似度阈值比较,取大于相似度阈值的最大相似度值,将最大相似度值所对应的两个同名的作者实体聚类为一簇,得到一个作者实体集;
其中,任意两个同名的作者之间的相似度计算公式为:
sij表示两个同名的作者实体ai与作者实体aj之间的相似度,simattr()表示相似度计算函数;
步骤3.3,取与作者实体集同名的其他任一作者实体,若与作者实体集中任一个作者实体之间的相似度大于相似度阈值,则将该作者实体加入该作者实体集;
步骤3.4,将剩余的同名作者实体,按步骤3.2至步骤3.3进行处理,直到对所有同名作者实体匹配到相应的作者实体集;
步骤3.5,将同一作者实体集中的所有作者实体合并为同一个作者实体,并为得到的作者实体设置作者id;且所有不同作者实体集中的作者实体的作者id设置为不同。
特别地,如果是对两个同名的作者实体集之间的相似度计算,本发明定义其相似度函数为:从两个作者实体集均任意取一个作者实体,进行两两计算后,取其中的最大相似度值作为两个同名的作者实体集之间的相似度,公式表示为:
spq表示两个同名的作者实体集cp与作者实体集cq之间的相似度,ai和aj分别表示作者实体集cp和作者实体集cq中的作者实体。
步骤4,构建基于知识图谱的学术圈;
将同名消歧处理后得到的实体数据集存储在neo4j图数据库中,形成实体节点;基于不同实体间的公共属性特征,为不同实体节点间建立关系边,最终得到基于知识图谱的学术圈。具体为:
步骤4.1,将实体数据集中的所有实体从数据库中导出为csv格式的文件,然后导入到neo4j图数据库中,每个id对应的实体在neo4j图数据库中均形成一个实体节点。
neo4j是一个高性能的nosql图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的java持久化引擎。neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。利用neo4j可以将学术圈可视化,从而构建学术圈的知识图谱,而实体间的关系可以通过neo4j很方便的建立。
其中,上述将csv格式的文件导入到neo4j图数据库中的步骤,具体是利用neo4j自带的create语句,将csv格式文件中的实体数据导入到neo4j图数据库中,相应的实体形成实体节点。
步骤4.2,利用不同实体之间公共的属性特征,提取不同实体之间的关系:不同作者实体之间为合作关系、作者实体与论文实体之间为发表关系、期刊实体与论文实体之间为收录关系。
同一篇论文中几个作者之间为合作关系;论文被某个期刊收录,为收录与被收录的关系;论文与其作者之间为发表关系。例如,论文实体的属性中包含期刊名以及期刊id,因此可以利用这个属性来构建论文实体与相应的期刊实体之间的收录关系。具体的实体关系可通过neo4j的where语句来创建。
步骤4.3,在neo4j图数据库中,将具有关系的实体节点之间使用相应关系类型的边进行连接。
以上实施例为本申请的优选实施例,本领域的普通技术人员还可以在此基础上进行各种变换或改进,在不脱离本申请总的构思的前提下,这些变换或改进都应当属于本申请要求保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!