一种资源不均衡Spark环境下的任务调度优化方法与流程
本发明涉及大数据处理领域,尤其涉及一种资源不均衡spark环境下的任务调度优化方法。
背景技术:
随着各大数据中心、超算中心和互联网公司等机构设备的更新换代和高性能部件(如gpu等)的引入,集群中各节点逐步变得异构,计算节点在cpu、内存和io等方面不同的性能导致它们的处理能力出现差异。因而各节点的综合计算能力出现较大的差异,整个集群处于资源不均衡的状态。由于集群中各节点的能力不同,相同任务分配到不同节点将对节点负载产生不同的影响。spark默认的任务调度是基于集群节点同构的理想化设计,并未考虑集群异构性及节点资源利用和负载变化的情况,因此无法满足资源异构模式下系统的效率和负载均衡等要求。
目前并行框架下的任务调度研究主要集中于hadoop平台,对于资源不均衡的spark环境下任务调度算法研究相对较少。一种自适应任务调度方法是通过检测节点负载和资源利用率来提高集群的运行性能。但是该算法考虑资源影响因素不够全面,权值过于依赖设定的阈值,主观性较强。一些基于人工智能及生物信息的任务调度优化算法,如蚁群算法、遗传算法等,虽能够进行多目标优化,但是这些算法原理比较复杂,实现起来计算量较大,因而调度效率较低。因此,为提高资源不均衡环境下spark的性能,需要提出高效的任务调度算法。
技术实现要素:
本发明为克服上述的不足之处,目的在于提供一种资源不均衡spark环境下的任务调度优化方法,本发明通过分析集群中每个节点的计算能力,对spark的底层调度算法进行优化,提出了基于节点优先级的spark动态自适应调度算法(sparkdynamicadaptiveschedulingalgorithm,sdasa)。sdasa充分考虑节点的异构性、资源利用和负载等情况,能够提高spark系统的运行效率,缩短作业执行时间。
本发明是通过以下技术方案达到上述目的:一种资源不均衡spark环境下的任务调度优化方法,包括如下步骤:
(1)筛选影响节点优先级的静态因素和动态因素,建立节点优先级评价指标体系,并计算出各指标的权值;
(2)在集群中部署分布式集群资源监控系统ganglia,集群启动时,触发监控启动心跳;
(3)当集群建立或有新节点加入集群时,master节点计算各个slave节点的静态性能指标值或新加入节点的静态性能指标值;
(4)master节点计算各个slave节点的动态性能指标值;
(5)master节点计算每个slave节点的优先级;
(6)master节点读取各slave节点的优先级,并根据各slave节点优先级的值对节点进行排序;
(7)master节点根据排序结果选择slave节点,对所选择的节点进行遍历,将需要运行的任务分配给本地化程度最高的slave节点;
(8)若任务执行完毕,返回任务执行结果;否则返回步骤(3)。
作为优选,所述步骤(1)具体如下:
(1.1)使用主成分分析法确定节点的静态因素为节点的cpu速度、cpu核数、内存大小和磁盘容量;
(1.2)使用主成分分析法确定节点的动态因素为节点的cpu剩余率、内存剩余率、磁盘容量剩余率以及cpu负载;
(1.3)基于步骤(1.1)和(1.2)的分析结果建立节点优先级评价指标体系,并对各指标的重要性进行评估;
(1.4)使用层次分析法得到各静态因素、动态因素的权值。
作为优选,所述步骤(3)具体如下:
(3.1)各个slave节点使用ganglia集群资源监控系统获取自己的静态因素值,包括cpu速度scpu_speed、cpu核数scpu_num、内存大小smem和磁盘容量sdisk;
(3.2)slave节点使用单播将数据汇集到master节点;
(3.3)master节点使用公式(1)计算出第i个slave节点的静态性能指标si,i=1toh,h为集群中slave节点的个数;
其中n1,n2,n3,n4分别为cpu速度、cpu核数、内存大小和磁盘容量等静态因素的权值,并且n1+n2+n3+n4=1;n1,n2,n3,n4的值使用层次分析法计算得到。
作为优选,所述步骤(4)具体如下:
(4.1)各个slave节点按照ganglia集群资源监控系统配置文件给定的周期定时获取自己的动态因素值,包括节点cpu剩余率dcpu、内存剩余率dmem、磁盘容量剩余率ddisk以及cpu负载dlength;
(4.2)slave节点使用单播将数据汇集到master节点;
(4.3)master节点使用公式(2)计算出第i个slave节点的动态性能指标di,i=1toh,h为集群中slave节点的个数;
其中,m1,m2,m3,m4分别表示cpu剩余率、内存剩余率、磁盘容量剩余率以及cpu负载等动态因素的权值,并且m1+m2+m3+m4=1;m1,m2,m3,m4的值使用层次分析法计算得到。
作为优选,所述步骤(5)具体为:master节点使用步骤(3)和(4)得到的各slave节点的静态指标值si和动态指标值di,使用公式(3)计算各个节点的优先级:
pi=αdi+βsi(3)
其中α和β分别是di和si的权值,使用层次分析法计算得到。
作为优选,所述步骤(7)具体如下:
(7.1)master节点依次遍历按节点优先级大小排序的节点集合workeroffer;
(7.2)在每个节点轮流遍历任务集合中的每个任务,循环执行步骤(7.3);
(7.3)获取任务在当前节点上的本地化参数;如果参数是最大的,则执行步骤(7.4),否则执行步骤(7.2);
(7.4)分配该task给该节点。
本发明的有益效果在于:本发明使用优先级描述资源不均衡的异构集群中节点的计算能力,并根据节点的优先级进行任务调度。在集群运行过程中,实时获取各slave节点的动态因素值,并更新节点的优先级值。提出的算法能够根据节点的当前性能完成任务调度,有效地提高了集群的性能,缩短了任务的执行时间。
附图说明
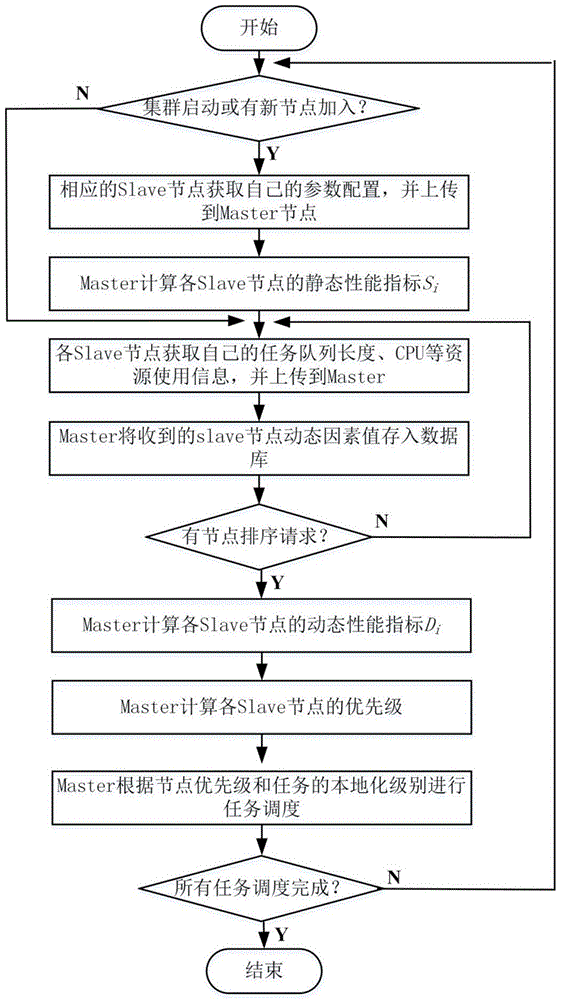
图1是本发明的方法流程示意图;
图2是本发明的节点优先级评价指标体系示意图;
图3是本发明的sdasa算法实施架构图;
图4是本发明的sdasa算法和spark默认算法执行不同数据量的同种任务完成时间比较示意图;
图5是本发明的sdasa算法和spark默认算法执行不同种任务完成时间比较示意图。
具体实施方式
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
实施例:本发明针对spark默认的任务调度是基于集群节点同构的理想化设计这一问题,本发明通过分析集群中每个节点的计算能力,对spark的底层调度算法进行优化,提出了基于节点优先级的spark动态自适应调度算法(sparkdynamicadaptiveschedulingalgorithm,sdasa)。sdasa充分考虑节点的异构性、资源利用和负载等情况,能够提高spark系统的运行效率,缩短作业执行时间。
节点的计算能力用节点优先级表示,优先级越高代表节点计算能力越强,被选中执行任务的概率越大。节点优先级由一组描述节点性能的指标(即节点性能指标)计算得到。节点性能指标包括静态性能指标和动态性能指标。静态性能指标指与任务执行状态无关的指标,其值由多个静态因素决定。节点动态性能指标则是指取值会随着任务执行状态而变化的指标,其值由多个动态因素决定。
如图1所示,一种资源不均衡spark环境下的任务调度优化方法,包括如下步骤:
(1)筛选影响节点优先级的静态因素和动态因素,建立节点优先级评价指标体系并计算出各指标的权值。
(1.1)对影响节点性能的因素进行分析,建立节点的优先级评价指标体系,如附图2所示;其中,进行分析包括使用主成分分析法确定节点的静态因素为节点的cpu速度、cpu核数、内存大小和磁盘容量。使用主成分分析法确定节点的动态因素为节点的cpu剩余率、内存剩余率、磁盘容量剩余率以及cpu负载(即cpu使用队列的长度)。
(1.2)领域专家对各指标的重要性进行评估;
(1.3)使用层次分析法计算各静态性能指标和动态性能指标的权值。
(2)在集群中部署分布式集群资源监控系统ganglia,以完成对集群中各个slave节点的内存、cpu、硬盘、网络流量等信息的监控。集群启动时,触发监控启动心跳。
(3)当集群建立或有新节点加入集群时,master节点计算各个slave节点的静态性能指标值或新加入节点的静态性能指标值。(3.1)当集群建立或有新节点加入集群时,各slave节点(或新加入的slave节点)使用ganglia获取自己的静态因素值,包括cpu速度scpu_speed、cpu核数scpu_num、内存大小smem和磁盘容量sdisk;
(3.2)各个slave节点使用单播将数据汇集到master节点;
(3.3)master节点使用公式(1)计算出第i个slave节点的静态性能指标si,i=1toh,h为集群中slave节点的个数。
(4)master节点计算各个slave节点的动态性能指标值。
(4.1)、各个slave节点按照ganglia系统配置文件给定的周期定时获取自己的动态因素值,包括节点cpu剩余率dcpu、内存剩余率dmem、磁盘容量剩余率ddisk以及cpu负载dlength;
(4.2)、slave节点使用单播将数据汇集到master节点;
(4.3)、master节点使用公式(2)计算出第i个slave节点的动态性能指标di,i=1toh,h为集群中slave节点的个数。
(5)master节点计算每个节点的优先级。
当出现节点排序请求时,master节点从数据库中读取各节点的静态指标值si和动态指标值di,使用公式(3)计算出各个节点的优先级。
(6)master节点读取各slave节点的优先级,并根据优先级的值对节点进行排序。
(7)master节点根据优先级大小选择slave节点,然后再对所选择出的节点进行遍历,将需要运行的任务分配给本地化程度最高的slave节点。
(8)若任务执行完毕,返回任务执行结果;否则返回步骤(3)。
其中上述方法是基于图3的架构实施的,本发明方法与默认的spark任务调度算法的实验结果对比如图4和图5所示。
综上所述,本发明在建立节点优先级评价指标体系的基础上,使用层次分析法确定各个静态因素和动态因素的权值。sdasa算法实时获取各slave节点的动态指标值,进行节点优先级的计算,并根据各个节点的优先级完成任务的分配。实验表明,相比spark的默认调度算法,本发明提出的算法能够有效提高集群系统的性能。当执行不同数据量的同种任务时,使用sdasa算法集群性能平均提升6.99%;当执行不同种任务时,使用sdasa算法集群性能平均提升6.32%。
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!