一种基于时刻关联网络的PM2.5浓度值预测方法与流程
本发明涉及空气颗粒物pm2.5浓度值的预测技术领域,尤其涉及一种基于时刻关联网络的pm2.5浓度值预测方法。
背景技术:
pm2.5是指大气中直径小于或等于2.5微米的颗粒物,富含大量的有毒、有害物质且在大气中的停留时间长、输送距离远,因而对人体健康和大气环境质量的影响更大,pm2.5超标还带来了另外一个影响——灰霾天气。空气污染如今已经成为人们关注的焦点,而在空气污染指标中,pm2.5浓度值已经成为衡量空气质量的标志性检测指标。现如今,根据历史数据对未来时间段pm2.5浓度值的预测已经成为具有较强学术意义和应用价值的研究问题。
为了解决上述问题,王敏等人在论文《基于bp人工神经网络的城市pm2.5浓度空间预测》中,运用bp神经网络模型对pm2.5浓度进行预测。阳其凯等人在论文《基于遗传算法与bp神经网络的pm2.5发生演化模型》中,利用遗传算法对bp神经网络加以改进并对pm2.5浓度的发生及预测进行了模拟。李翔等人在专利《一种基于集成学习的pm2.5预报方法》中,通过选择不同类型和结构的神经网络构造多个弱学习机,然后使用集成学习adaboost算法将多个弱学习机组合成强学习机,完成pm2.5预报工作。乔俊飞等人在论文《基于t-s模糊神经网络的pm2.5预测研究》中,提出了基于t-s模糊神经网络的pm2.5预测方法。苏盈盈等人在专利《基于无迹卡尔曼神经网络的pm2.5浓度预测方法》中,针对pm2.5浓度非线性动态变化的特点,提出了一种提供了一种基于无迹卡尔曼神经网络的pm2.5浓度预测方法。侯俊雄等人在论文《门限重复单元的pm2.5浓度预报方法》中,提出了一种基于长短期记忆神经网络的pm2.5浓度实时预报方法。白盛楠等人在论文《基于lstm循环神经网络的pm2.5预测》中,提出了基于lstm循环神经网络的pm2.5预测模型。
经文献调研分析,目前已提出的pm2.5浓度值预测方法均以神经网络为核心架构,对pm2.5浓度值以及其他相关指标(比如aqi、pm10、no2、co、so2、o3)进行非线性回归分析。神经网络模型包含ann,dnn,fnn和bpnn等,以及结合遗传算法、随机森林等优化算法优化后的混合方法。并且,逐渐开始有学者使用循环神经网络等方法对pm2.5浓度数据的时序特性进行学习。但是,经文献调研,现有的pm2.5浓度值神经网络预测方法在对pm2.5浓度数据的时序特性进行学习时,仅仅基于pm2.5浓度历史数据以及历史天气数据等进行的训练学习只是基于非线性关系的挖掘,而无法针对相同时刻下周期数据的时序特性进行针对性学习,从而导致的预测精度不足以及收敛速度过慢。
技术实现要素:
为了克服已有pm2.5浓度值预测方式在对pm2.5浓度数据的时序特性进行学习时,无法针对相同时刻下周期数据的时序特性进行针对性学习,从而导致的预测精度不足以及收敛速度过慢等问题,本发明在对pm2.5浓度值历史数据、pm2.5浓度值相关指标历史数据和气象历史数据之外,还引入月份、日期和时刻标签数据,根据提出的编码方式进行无差别量化,然后利用一种时刻关联网络进行学习训练,可以准确描述pm2.5浓度值时间变化规律。
本发明解决其技术问题所采用的技术方案是:
一种基于时刻关联网络的pm2.5浓度值预测方法,所述方法包括如下步骤:
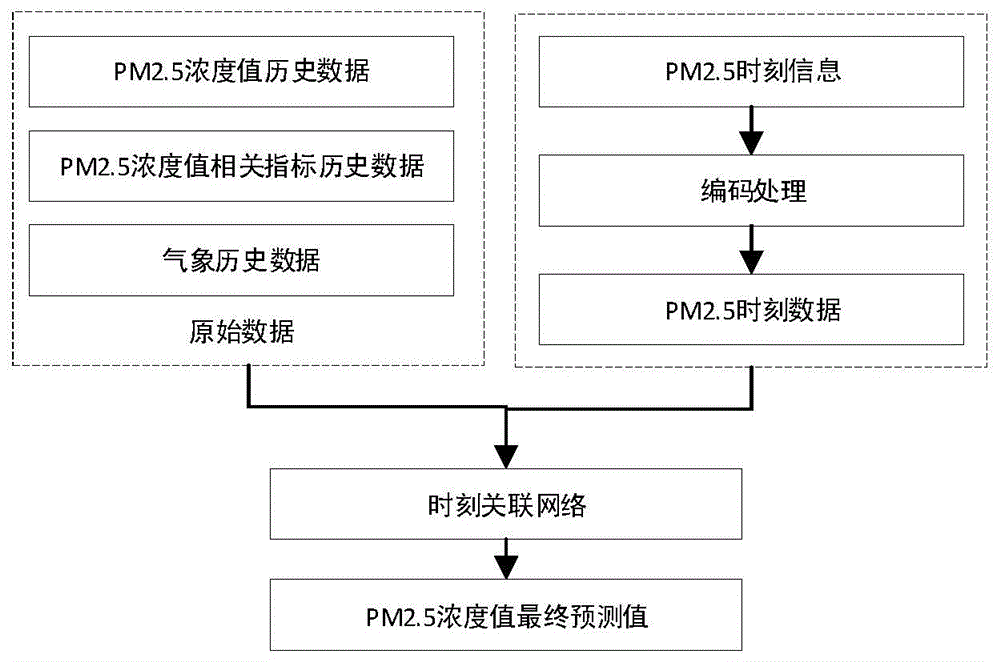
步骤1、原始数据采集,原始数据包括pm2.5浓度值历史数据、pm2.5浓度值指标历史数据和气象历史数据以及月份、日期和时刻数据;
步骤2、采用编码方式对月份、日期和时刻数据进行无差别量化处理,过程如下:
步骤2.1、对于12个月份,采用12个编码来表示12个特征值:1月=(0,0,0,0,0,0,0,0,0,0,0,1),2月=(0,0,0,0,0,0,0,0,0,0,1,0),3月=(0,0,0,0,0,0,0,0,0,1,0,0),依此类推;
步骤2.2、如步骤2.1所示,对于31个日期和24个时刻,分别采用31个编码和24个编码来各自的特征值;
步骤3、采用时刻关联网络进行训练,过程如下:
步骤3.1、创建一个包含输入层、隐含层和输出层的三层神经网络,设定隐含层和输出层的节点个数,所述隐含层的节点个数采用经验公式给出估计值,所述经验公式如下:
上式中,a和b分别为输入层和输出层的神经元个数,c是[0,10]之间的常数;
步骤3.2、分别设定隐含层、连接层和输出层的训练函数、连接函数和输出函数:
h(1,2,...,n)=σ(z)=σ(ux(1,2,...,n)+wh(0,1,...,n-1)+b)(2)
o(2,...,n+1)=vh(1,2,...,n)+c(3)
其中,t=0,1,2,…,n+1代表时刻,x(t)代表t时刻训练样本的输入;h(t)代表t时刻模型的隐藏状态,h(t)由x(t)和h(t-1)共同决定;o(t)代表t时刻模型的输出,o(t)只由模型当前的隐藏状态h(t)决定;y(t)代表t时刻训练样本序列的真实输出;u,w,v这三个矩阵是模型的线性关系参数;
步骤3.3、设定网络的期望误差最小值、最大迭代次数和学习率;
步骤3.4、训练循环神经网络,计算损失函数:
步骤3.5、根据误差调整循环神经网络的各层权值,其中v,c的梯度计算如下:
在反向传播时,在某一序列位置n的梯度损失由当前位置的输出对应的梯度损失和序列索引位置n+1时的梯度损失两部分共同决定,对于w在某一序列位置n的梯度损失需要反向传播一步步地计算,定义序列索引n+1位置的隐藏状态的梯度为:
w,u,b的梯度计算表达式:
c,b为偏置值;
步骤3.6、判断循环网络是否收敛,当误差小于期望误差最小值时,算法收敛,在达到最大迭代次数时结束算法,所述时刻关联网络训练完成;
步骤3.7、将所述采集数据和时刻数据输入到所述训练完成的时刻关联网络中,输出pm2.5浓度值的最终预测值。
进一步,所述pm2.5浓度值指标包括aqi、pm10、no2、co、so2和o3浓度,所述时刻数据包括月份,日期和时刻。
本发明中,所述步骤2中,通过编码方式对时刻信息进行了无差别量化处理。
所述步骤3中,通过对输入维度和输出维度的关联处理构建了时刻关联网络,对数据进行了时序训练和预测。
本发明的技术构思为:在对pm2.5浓度值历史数据,pm2.5浓度值相关指标的历史数据(aqi、pm10、no2、co、so2、o3)和气象历史数据(气温、相对湿度、气压、风速、降水量等)数据进行非线性相关分析之外,月份、日期和时刻标签数据,根据提出的编码方式进行无差别量化,并通过构建时序关联的输入层和输出层,提供一种针对周期采样的序列数据时刻特性的,可以准确描述pm2.5浓度值时间变化规律的基于时刻关联网络的pm2.5浓度值预测方法。
本发明的有益效果主要表现在:本发明的技术方案不仅可以充分学习pm2.5浓度数据的时序特性,还可以深度挖掘采集数据周期上的时刻特征,有效地提高当前pm2.5浓度值的预测精度与训练速度,拓宽了神经网络预测的局限性,能够实现周期性采集的长时序数据精准预测。
附图说明
图1是一种基于时刻关联网络的pm2.5浓度值预测方法示意图。
图2是时刻关联网络的网络训练流程图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图2,一种基于时刻关联网络的pm2.5浓度值预测方法,所述方法包括如下步骤:
步骤1、原始数据采集,原始数据包括pm2.5浓度值历史数据、pm2.5浓度值指标历史数据和气象历史数据以及月份、日期和时刻数据;
步骤2、采用编码方式对月份、日期和时刻数据进行无差别量化处理,过程如下:
步骤2.1、对于12个月份,采用12个编码来表示12个特征值:1月=(0,0,0,0,0,0,0,0,0,0,0,1),2月=(0,0,0,0,0,0,0,0,0,0,1,0),3月=(0,0,0,0,0,0,0,0,0,1,0,0),4月=(0,0,0,0,0,0,0,0,1,0,0,0),5月=(0,0,0,0,0,0,0,1,0,0,0,0),6月=(0,0,0,0,0,0,1,0,0,0,0,0),7月=(0,0,0,0,0,1,0,0,0,0,0,0),8月=(0,0,0,0,1,0,0,0,0,0,0,0),9月=(0,0,0,1,0,0,0,0,0,0,0,0),10月=(0,0,1,0,0,0,0,0,0,0,0,0),11月=(0,1,0,0,0,0,0,0,0,0,0,0),12月=(1,0,0,0,0,0,0,0,0,0,0,0);
步骤2.2、如步骤2.1所示,对于31个日期和24个时刻,分别采用31个编码和24个编码来各自的特征值;
步骤3、采用时刻关联网络进行训练,过程如下:
步骤3.1、创建一个包含输入层、隐含层和输出层的三层神经网络,设定隐含层和输出层的节点个数,所述隐含层的节点个数采用经验公式给出估计值,所述经验公式如下:
上式中,a和b分别为输入层和输出层的神经元个数,c是[0,10]之间的常数;
步骤3.2、分别设定隐含层、连接层和输出层的训练函数、连接函数和输出函数:
h(1,2,...,n)=σ(z)=σ(ux(1,2,...,n)+wh(0,1,...,n-1)+b)(2)
o(2,...,n+1)=vh(1,2,...,n)+c(3)
其中,t=0,1,2,…,n+1代表时刻,x(t)代表t时刻训练样本的输入;h(t)代表t时刻模型的隐藏状态,h(t)由x(t)和h(t-1)共同决定;o(t)代表t时刻模型的输出,o(t)只由模型当前的隐藏状态h(t)决定;y(t)代表t时刻训练样本序列的真实输出;u,w,v这三个矩阵是模型的线性关系参数;
步骤3.3、设定网络的期望误差最小值、最大迭代次数和学习率。
步骤3.4、训练循环神经网络,计算损失函数:
步骤3.5、根据误差调整循环神经网络的各层权值,其中v,c的梯度计算如下:
在反向传播时,在某一序列位置n的梯度损失由当前位置的输出对应的梯度损失和序列索引位置n+1时的梯度损失两部分共同决定,对于w在某一序列位置n的梯度损失需要反向传播一步步地计算,定义序列索引n+1位置的隐藏状态的梯度为:
w,u,b的梯度计算表达式:
c,b为偏置值;
步骤3.6、判断循环网络是否收敛,当误差小于期望误差最小值时,算法收敛,在达到最大迭代次数时结束算法,所述时刻关联网络训练完成;
步骤3.7、将所述采集数据和时刻数据输入到所述训练完成的时刻关联网络中,输出pm2.5浓度值的最终预测值。
进一步,所述pm2.5浓度值指标包括aqi、pm10、no2、co、so2和o3浓度。所述时刻数据包括月份,日期和时刻。
本发明中,所述步骤2中,通过编码方式对时刻信息进行了无差别量化处理。
所述步骤3中,通过对输入维度和输出维度的关联处理构建了时刻关联网络,对数据进行了时序训练和预测。
- 还没有人留言评论。精彩留言会获得点赞!