一种用于LU分解的脉动阵列结构的实现方法与流程
本发明涉及矩阵计算技术领域,具体涉及一种用于lu分解的脉动阵列结构的实现方法。
背景技术:
lu分解是一种矩阵分解的方法,其原理是将方阵分解为一个上三角矩阵和一个下三角矩阵。矩阵分解通常用于图像处理、信号处理等诸多科学领域。
目前大部分图像处理、信号处理等算法还是在pc端基于软件运行,其中包含的大量的矩阵分解需要占用了整体算法的大部分运算时间,而随着算法的复杂度和矩阵维度的增加,基于软件运行的算法执行速度远远不能满足需求。
目前亟待开展基于硬件的矩阵运算结构的研究,基于硬件的矩阵运算结构可以大幅提高算法的执行速度和吞吐量。
技术实现要素:
本发明的目的是为了解决现有技术中的上述缺陷,提供一种用于lu分解的脉动阵列结构的实现方法。
本发明的目的可以通过采取如下技术方案达到:
一种用于lu分解的脉动阵列结构的实现方法,用于对n×n的输入矩阵a进行分解,包括以下步骤:
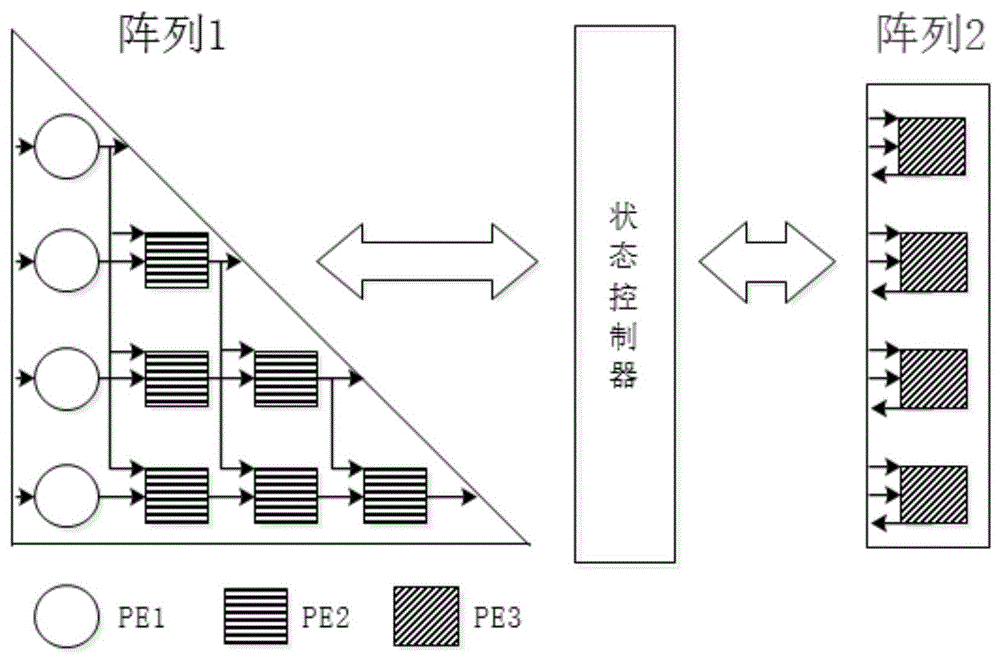
s1、根据输入矩阵a的最大可能维数确定脉动阵列的维数及总体结构,总体结构包括阵列1模块、阵列2模块和状态控制器模块,其中,所述的阵列1模块用于计算上三角矩阵u,所述的阵列2模块用于计算下三角矩阵l,所述的状态控制器模块用于控制阵列1模块和阵列2模块的中间数据交换,以确保运算过程的正确性。
s2、设计阵列1模块,当输入矩阵a是n×n维,则阵列1模块是一个n行n列的三角阵列,即第n列的处理单元比第n-1列在第n-1行处少一个,n=1,2…,n,其中第1列处理单元记为pe(processingelement)1,为延时单元,其输入为
s3、设计阵列2模块,当输入矩阵a是n×n维,则阵列2模块是一个n行1列的条形阵列,其处理单元为除法器,记为pe3,每个pe3的输入参数
s4、设计状态控制器模块,状态控制器模块根据阵列1模块中各列pe1和pe2的输出状态控制下一列pe工作与否,同时将阵列1模块的中间数据选择输入到阵列2模块的输入端口。
进一步地,所述的步骤s2、设计阵列1模块的过程如下:
s21、设计阵列1模块的输入输出端口;
s22、设计阵列1模块的pe1;
s23、设计阵列1模块的pe2。
进一步地,所述的步骤s21中,每个阵列1模块有n个输入端口,每个输入端口有1个输入参数xin,n个输出端口,每个输出端口有1个输出参数xout,每个输入输出端口对应矩阵各行,其实现过程如下:
当输入使能信号线置高后的第二个时钟开始,第一个时钟每个xin对应输入a11、a21、...、an1,第二个时钟每个xin对应输入a12、a22、...、an2,以此类推,直至整个矩阵输入完成。
从数据开始输入开始,第一个时钟第1个xout输出u11,第二个时钟第1、2个xout输出u12、u21,第三个时钟第1、2、3个xout输出u13、u22、u31,以此类推,直至整个上三角矩阵u输出完成。
进一步地,所述的步骤s22中,阵列1模块的pe1将输入参数
先判断输入使能信号是否有效,若有效,则每个时钟输出
进一步地,所述的步骤s23中,阵列1模块的pe2将输入参数
在工作使能信号上升沿时:
下降沿时:
进一步地,所述的步骤s3、设计阵列2模块的过程如下:
s31、设计阵列2模块的输入输出端口;
s32、设计阵列2模块的pe3。
进一步地,所述的步骤s31中,每个阵列2模块有n个输入端口,每个输入端口有2个输入参数
在阵列1模块数据输入的第1个时钟,
输出
进一步地,所述的步骤s32中,阵列2模块的pe3根据输入参数
对于输入参数
进一步地,所述的步骤s4、设计状态控制器模块的过程如下:
判断工作使能是否有效,若有效,进入状态1,若无效,
进入状态1,使能第1列处理单元,即pe1;
进入状态2,阵列2模块各
进入状态3,使能第2列处理单元,即pe2;
进入状态4,阵列2模块各
进入状态5,使能第3列处理单元,即pe2;
进入状态6,阵列2模块各
以此类推,直至第n列第n行处理完成,回到初始状态,等待工作使能信号。
本发明相对于现有技术具有如下的优点及效果:
1、本发明相较于传统的脉动阵列结构,将乘加器和除法器分离开,利用控制器控制数据交换,减少了硬件资源的使用,更方便数据的输出。
2、本发明设计的高维脉动阵列结构可兼容较低维的矩阵lu分解,可实现不同维数矩阵共用同一结构,避免重新设计结构。
3、本发明相较于传统的脉动阵列结构输入数据时不需进行特定排序,提高了并行化程度,减少控制器的复杂程度并缩短运算周期。
附图说明
图1是本发明中公开的脉动阵列总体结构示意图;
图2是本发明的输入输出时序示意图;
图3是本发明中脉动阵列结构阵列1模块的pe1示意图;
图4是本发明中脉动阵列结构阵列1模块的pe2示意图;
图5是本发明中脉动阵列结构阵列1模块的pe2内部结构简易图;
图6是本发明中脉动阵列结构阵列2模块的pe3示意图;
图7是本发明中状态控制器模块的控制逻辑顺序。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
如图1所示,本实施例公开了一种用于lu分解的脉动阵列结构的实现方法,其中,脉动阵列结构包括阵列1模块、阵列2模块和状态控制器模块,其中:
阵列1模块,用于计算上三角矩阵u。将待计算矩阵并行输入阵列1模块的输入接口,无需对数据进行特定排序,每个时钟读取一列数据,进过2n个时钟后即可计算出上三角矩阵u。
阵列2模块,用于计算下三角矩阵l。通过状态控制器模块将阵列1模块产生的中间数据送入阵列2模块,与阵列1模块同步计算出下三角矩阵l。
状态控制器模块,用于控制阵列1模块和阵列2模块的中间数据交换,将阵列1模块的中间数据送入阵列2模块计算下三角矩阵l,并将阵列2模块的计算结果送入阵列1模块的pe2用于计算上三角矩阵u。
本实施例中阵列1模块,若作为待计算矩阵的a矩阵是n×n维的,则阵列1模块是一个n行n列的三角阵列,即第n列的处理单元比第n-1列在第n-1行处少一个,其中第1列处理单元pe1为延时单元,第2列至第n列处理单元pe2为乘加处理单元。
阵列1模块的输入输出:如图1和图2所示,每个阵列1模块有n个输入端口,每个输入端口有1个输入参数xin,n个输出端口,每个输出端口有1个输出参数xout,每个输入输出端口对应矩阵各行,其具体如下:
(1)当输入使能信号线置高后的第二个时钟开始,第一个时钟每个xin对应输入a11、a21、...、an1,第二个时钟每个xin对应输入a12、a22、...、an2,以此类推,直至整个矩阵输入完成。
(2)从数据开始输入开始,第一个时钟第1个xout输出u11,第二个时钟第1、2个xout输出u12、u21,第三个时钟第1、2、3个xout输出u13、u22、u31,以此类推,直至整个上三角矩阵u输出完成。
阵列1模块pe1单元:如图3所示,pe1将输入参数
阵列1模块pe2单元:如图4和图5所示,pe2将输入参数
在工作使能信号上升沿时:
本实施例中阵列2模块,若a矩阵是n×n维的,则阵列2模块是一个n行1列的条形阵列,其处理单元pe3为除法器。
阵列2模块的输入输出:如图1和图2所示,每个阵列2模块有n个输入端口,每个输入端口有2个输入参数
(1)在阵列1模块数据输入的第1个时钟,
(2)输出
阵列2模块pe3单元:如图6所示,pe3根据输入参数
阵列1和阵列2之间的数据交换和处理单元工作控制由状态控制器模块控制,其控制逻辑如图7所示。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!