基于引文网络的论文文本相似性的检测方法与流程
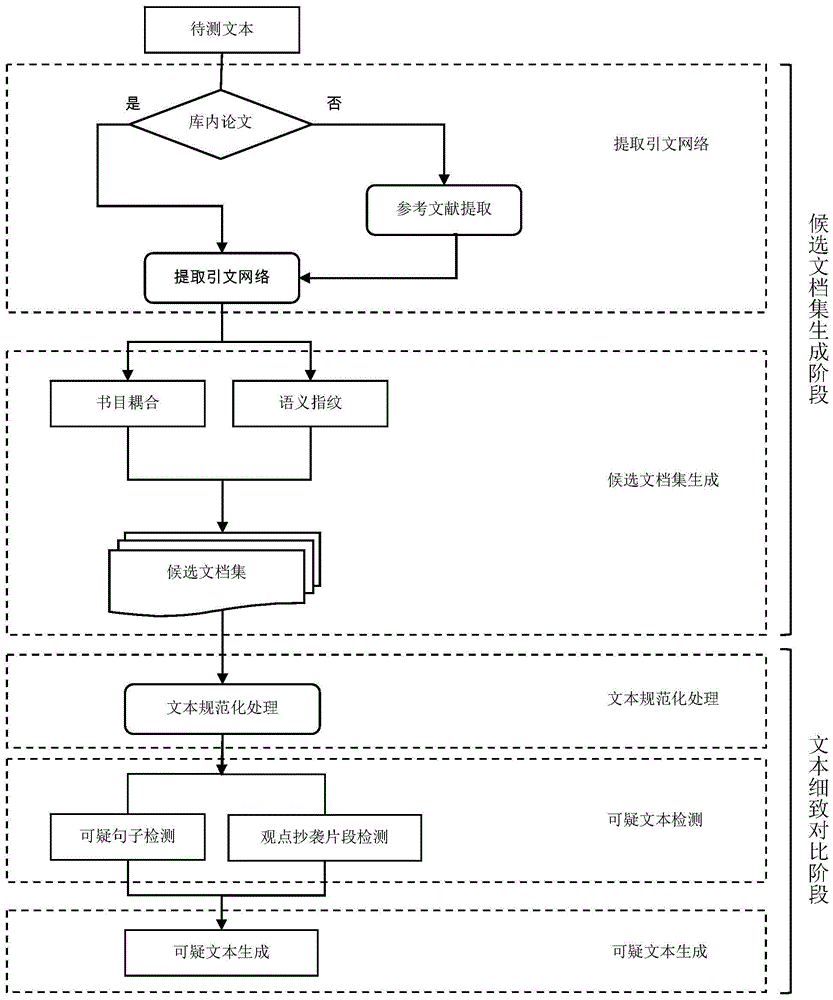
本发明提供一种论文文本相似性的检测方法,具体涉及一种基于引文网络的论文文本相似性的检测方法,属于文本检测领域。
背景技术:
论文抄袭不仅有违科研基本精神,而且严重损害了科研的公平性及其他人员的权益。随着信息社会的进一步发展,在线博客、数据库等使人们获取信息的成本越来越低,同时使抄袭变得越来越便利。论文抄袭主要指将他人的语言文字、图表公式或研究观点,经过编辑、拼凑、修改后加入到自己的论文当中,并当作自己的成果而不加引用的公开发表。因此需要有效的文本相似性的检测方法来应对论文抄袭。
目前论文文本相似性的检测方法主要有两种方法,一种是基于字符匹配的方法,一种是基于指纹的比对方法。基于字符匹配的方法通过计算句子之间相同的字符数或不同的字符数计算句子的相似性,基于指纹的匹配方法采用哈希函数将词、短语或片段转化后的哈希值(或哈希值的和),通过比对指纹间的重合程度衡量文本之间的相似性。两种方法在计算相似性的基础上设定一个相似性阈值,将相似性大于阈值的句子(片段)视为疑似抄袭的句子(片段)。最后通过计算文本复制比来判断论文文本是否相似。但是论文文本相似除了简单的复制文本外,还包括同义词替换、句子浓缩与组合、对文本进行摘要等方式修改原文档。因此,目前现有的论文文本相近性检测方法无法检出智能抄袭,存在效率不高、识别率低的问题。
技术实现要素:
本发明的目的是提供一种高效、高识别率的基于引文网络的论文文本相似性的检测方法,以解决目前论文文本相似性检测的不足。
本发明的技术方案,具体方案如下:
基于引文网络的论文文本相似性的检测方法,其步骤包括:
1)提取或构建引文网络;
2)通过计算书目耦合度bcs和语义相似性fd过滤引文网络中的文档,生成候选文档集;
3)对待检文档进行规范化处理;
4)在候选文档集上基于词建立句子级别的倒排索引,进行相似句子检测与观点片段检测,生成相似文本,通过计算待检文档的复制比得到相似性的判断。
进一步,步骤2)中,计算书目耦合度bcs的公式如下:
其中rd表示d文档的参考文献,|rd1∩rd2|表示d1文档与d2文档参考文献的重复数,|rd1∪rd2|表示文档d1和文档d2的总引文数。
步骤2)中,计算语义相似性fd,具体步骤如下:
2.1)对引文网络的每篇文本进行切词,去除停用词处理,基于tf提取其前50个关键词,并对关键词进行统一替换;
2.2)采用hash函数获得每个词的64位hash码;
2.3)将每篇文档的50个关键词,生成50*64个数字,然后将这些数字对应位置相加得到64个求和数,表示为(s1,s2,s3......s64),对每一个数如si>0则置1,否则si置0,生成每篇文档的64位语义指纹;
2.4)计算待测文档与引文网络中每篇文档语义指纹的汉明距离hd;
2.5)基于汉明距离计算文本语义相似性fd=1-hd/64。
步骤2)中,首先计算待测文档与引文网络中每篇文档的相似性r=(bcs+fd)/2,基于相似性r对引文网络中的文档进行排序,取前10--100篇作为候选文档集。
进一步,步骤3)中,具体包括:
3.1)去除文档中的图片、表格、公式、乱码字符;
3.2)对文本进行分句,分句的符号为句号、感叹号、分号或问号;
3.3)对句子进行分词,并进行同义词替换,对待检测的句子分词后进行同义词替换,获得处理后的词集w。
进一步,步骤4)进行相似句子检测的具体过程如下:
4.1)假设待检测的句子同义词替换后的词集是w1,候选句子同义词替换后的词集为w2,计算两者的公共词集w3=w1∩w2;
4.2)计算待测句子集去除w3后的词集w4=w1-w3,计算候选句子词集去除w3后的词集w5=w2-w3;
4.3)获取词集w4的词向量矩阵v1,获取词集w5的词向量矩阵v2,并计算矩阵内积v3=(v1,v2.t),v2.t为v2的转置;
4.4)计算矩阵v3行方向上的最大值,并求和得m;
4.5)计算词集w1和w2的交集w6;
4.6)计算句子相似性r=(|w3|+m)/w6,r>0.65时,该句子构成可疑句子。
步骤4)中,对观点片段进行检测,其操作过程如下:
4.7)采用textrank方法计算出候选文档集和待测文档的核心句子,将包含核心句子的一段文本作为观点片段;
4.8)生成观点片段中每句的句向量表示,句向量的生成方式如下:
4.8.1)对每句进行切词,获得词集w,并计算每个词的tf-idf值;
4.8.2)基于词向量模型获得词的向量表示,基于tf-idf计算所有词向量的加权平均作为句向量;
4.9)基于句向量获得待测观点片段的句向量矩阵v1和候选文档观点片段的句向量矩阵v2;
4.10)计算两者的内积v=(v1,v2),并计算行方向上的最大值r;
4.11)计算s的平均值e,如e大于0.9,则判定观点片段构成相似。
步骤4)中,若相似句子相邻则直接合并成片段,若相似句子的字数小于30个,则过滤掉,相似句子片段与相似观点片段合并构成相似文本。
步骤4)中,复制比=相似文本的字符数/待检文档总字符数,得到待检文档的复制比,从而判断出论文文本的相似性。
本发明在引文网络的基础上提出了基于书目耦合与语义指纹相结合的候选文档集过滤方法。该方法在过滤候选文档时,既考虑了文档在引用模式上的相似性又考虑了文档在内容上的相似性。与传统的检索模型相比,在保证候选文档集质量的前提下,减少了候选文档集的生成时间;与基于引文分析的候选集生成方法相比,该方法考虑了文档内容相似性,生成的候选文档集更为全面。其次在文本细致比对阶段,为了解决字符串匹配无法检测词语替换、句子重组及观点抄袭等抄袭手段的问题,本发明提出基于词向量的句子比对与观点检测,将词向量与同义词引入到相似性中,提升了句子相似性的计算效果且具有计算速度快的优点。且本发明能够检测出文本中可能涉及观点抄袭的文本片段。
采用本发明对市场经济管理主题下的100篇论文进行了检测。检测发现本发明不仅速度快,而且对词语替换、句子重组等相似性检测具有好的效果,其中观点抄袭对小幅改动的观点内容有一定的效果。检测结果显示平均每篇用时约7-10s,平均每篇复制比为0.44%,与仅基于字符的方法相比高0.11%,并在检测中发现1篇论文涉嫌观点抄袭。
附图说明
图1是本发明基于引文网络的论文文本相似性的检测方法的流程图;
图2是引文网络示意图。
具体实施方式
如图1所示,本发明基于引文网络的论文文本相似性的检测方法,具体步骤包括:
1.引文网络提取或构建,其具体操作如下:
首先,以论文标题和作者检索引文网络数据库,若该篇论文在数据库中则从引文网络库中直接提取其引文网络;若该篇论文不在库中,则解析其参考文献,然后通过参考文献构造其引文网络(如图2所示)。例如文献t、作者a,则以(t,a)问检索条件,检索其引文网络,若(t,a)不在引文网络库,则解析其参考文献,生产引文网络。如文献t的参考文献为(t1,a1)、(t2,a2)、(t3,a3),则分别以(t1,a1)、(t2,a2)、(t3,a3)为检索条件生成(t,a)的引文网络。其生成的结果为:参考文档集一级,共引文档集1,参考文档集二级,共引文档集2。
2.生成候选文档集,其生成操作如下。
2.1)计算引文网络中的每篇文档与待检文档的数目耦合度bcs,如论文a有参考文献a、b、c、d、b论文有a,c,d,e,则ab的文献耦合度为3/5。其计算公式如公式1:
其中rd表示d文档的参考文献,|rd1∩rd2|表示d1文档与d2文档参考文献的重复数,|rd1∪rd2|表示文档d1和文档d2的总引文数(去重)。
2.2)计算引文网络中每篇文档与待检文档的语义相似性fd。其操作如下。
2.2.1)对引文网络的每篇文档进行切词,去除停用词处理,基于tf提取其前50个关键词,并对关键词进行统一替换,如近义词a、b、c统一替换为a。
2.2.2)采用hash函数获得每个词的64位hash码,
如词“北京市”经hash函数后生产的64位hash码为“1000101010101101010001110000010011110000011011101111000010111010”,将hash码的0置为-1,1不变,乘以词的tf值,生成64个数字,表示为(a1,a2,a3……a64)。
2.2.3)将每篇文档的50个关键词,生成50*64个数字,然后将这些数字对应位置相加得到64个求和数,表示为(s1,s2,s3……s64),对每一个数如si>0则置1,否则si置0,生成每篇文档的64位语义指纹。
2.2.4)计算待测文档与引文网络中每篇文档语义指纹的汉明距离hd。如文档a的语义指纹为:
“0010000000000000000001110101111000010011100011001110000110000001”
文档b的语义指纹为:
“0010000000000000000001110101111000010011100011001110000110000001”
两者汉明距离为9。
2.2.5)基于汉明距离计算文本语义相似性fd=1-hd/64。
2.3)计算待测文档与引文网络中每篇文档的相似性r=(bcs+fd)/2。
2.4)基于相似性r对引文网络中的文档进行排序,取前100篇作为候选文档集。
3.在进行文本细致比对前需要对待测文档进行规范化处理,具体处理过程为:
3.1)去除待测文档中的图片、表格、公式、乱码字符。
3.2)对待测文本进行分句,分句的符号为句号(。)感叹号(!)分号(;)问号(?)
3.3)对句子进行分词,并进行同义词替换,对待检测的句子分词后进行同义词替换,获得处理后的词集w。
4.在候选文档集上基于词建立句子级别的倒排索引,进行可疑的相似句子检测与观点抄袭片段检测,生成相似性高的可疑相似文本,计算得到待检文档的复制比,其检测过程操作如下:
4.1)基于词集w去检索候选文档集中的句子,并对检索到的句子频次进行统计,由高到低进行排序。选取前三个句子作为候选句子进行相似性计算,若其中一个相似性r的值大于0.65,则认为该句子可能抄袭。句子相似性的计算过程如下:
4.1.1)假设带检测的句子同义词替换后的词集是w1,候选句子同义词替换后的词集为w2,计算两者的公共词集w3=w1∩w2。
4.1.2)计算待测句子集去除w3后的词集w4=w1-w3,计算候选句子词集去除w3后的词集w5=w2-w3。
4.1.3)获取词集w4的词向量矩阵v1,获取词集w5的词向量矩阵v2,并计算矩阵内积v3=(v1,v2.t)(v2.t为v2的转置)。
4.1.4)计算矩阵v3行方向上的最大值,并求和的m
4.1.5)计算词集w1和w2的交集w6
4.1.6)计算句子相似性r=(|w3|+m)/w6.
4.2)在候选文档集上基于词建立句子级别的倒排索引,对观点抄袭片段进行检测,其操作过程如下:
4.2.1)采用textrank方法计算出候选文档集和待测文档的核心句子,这里核心句子数取3个。
4.2.2)以5为句子数窗口的大小,采用滑动窗口的方式构造包含文档观点的文本片段。如有句子集顺序为a,b,c,d,e,f,g,识别的核心句子为e,则生成的文档观点片段为(abcde)、(bcdef)、(cdefg)。
4.2.3)生成待检文档和候选文档集的文档观点片段集。
4.3)依次检测待检文档的每个文档观点片段是否涉嫌抄袭,其检测过程如下:
4.3.1)生成文档片段中每句的句向量表示,句向量的生成方式如下:
a)对每句进行切词,获得词集w,并计算每个词的tf-idf值。
b)基于词向量模型获得词的向量表示,基于tf-idf计算所有词向量的加权平均作为句向量。
4.3.2)基于句向量获得待测文档片段的句向量矩阵v1,获得候选文档片段的句向量矩阵v2
4.3.3)计算两者的内积v=(v1,v2),并计算行方向上的最大值s。
4.3.4)计算s的平均值e,如e大于0.9,则判定文档观点片段可能涉嫌抄袭。
对于判定为相似的句子,若相似句子相邻这合并成片段。如句子的字数小于30个字则过滤掉。生成的相似句子片段与观点片段合并构成可疑的相似文本。
最后计算待测文本的复制比,复制比=可疑的相似文本的字符数/待测文档总字符数。
上述说明仅对本方法的技术方案做了概述,为了能够更清楚的了解本发明的技术手段,并可依照说明书的内容予以实施,以下配合附图做详细说明。
- 还没有人留言评论。精彩留言会获得点赞!