一种基于双层注意力机制与双向GRU的文本关系抽取方法与流程
本发明涉及一种文本关系抽取方法,具体涉及一种基于双层注意力机制与双向gru的文本关系抽取方法。
背景技术:
随着信息技术飞速发展,信息量急速增长,怎样高效的从非结构化文本信息中提取出有效信息成为人们关注的热点。文本信息抽取包含实体抽取、关系抽取及事件抽取等。关系抽取是自然语言处理的基础任务之一,用于识别文本信息中存在的两个命名实体的相互关系。通过关系抽取可以形成实体1、关系、实体2的三元组结构。这对后续中文信息内容检索、知识图谱构建等应用具有重要作用。
关系抽取主要包括有监督的实体关系抽取方法、半监督的实体关系抽取方法、无监督的实体关系抽取方法:
无监督的实体关系抽取方法包括实体聚类和关系类型词选择两部分,但存在特征提取不准、聚类结果不合理、关系结果准确率较低等问题。
半监督的实体关系抽取方法,例如bootstrapping,该方法从包含关系种子的文本中总结实体关系序列模式,然后以此去发现更多的关系种子实例。但存在迭代过程中混入噪声,造成语义漂移的问题。
有监督的实体关系抽取方法主要思想是在已标注的数据上面训练机器学习模型,对测试数据进行关系识别。有监督的实体关系抽取方法分为基于规则的关系抽取方法,基于特征的关系抽取方法。基于规则的关系抽取方法根据语料和领域通过总结归纳规则或模板,通过模板匹配进行实体关系抽取。此类方法在依赖于命名实体识别系统与距离计算等,容易增加额外的传播错误与耗时。
基于特征的关系抽取方法主要利用机器学习方法自动提取文本特征,不需要构建复杂的特征。socher等提出了矩阵—递归神经网络模型mv-rnn,通过解析文本的句法结构实现实体关系识别,但其准确率通常受限于文本的句法分析准确率;liu等利用卷积神经网络(cnn)实现关系抽取任务,但由于卷积神经网络无法长句进行建模,因而存在两个实体的远距离依赖问题。xu等将lstm(longshorttermmemory)引入实体关系抽取任务重,以解决两个实体的远距离依赖问题,同时利用文本的词向量、词性标注、句法依存等信息学习实体之间的最短依存路径。然而,rnn、cnn和lstm都无法充分利用文本信息的局部特征与全局特征。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,提供一种基于双层注意力机制与双向gru的文本关系抽取方法,其能够有效地提高中文文本关系抽取准确率。
技术方案:为实现上述目的,本发明提供一种基于双层注意力机制与双向gru的文本关系抽取方法(bigru-2att),包括如下步骤:
s1:对文本语料进行实体标注和关系标注;
s2:对标注数据进行预处理,生成实体抽取模型和关系抽取模型的训练集和测试集;
s3:构建bigru-2att关系抽取网络;
s4:分别进行latticelstm实体抽取模型训练和bigru-2att关系抽取模型训练;
s5:将测试集数据首先输入latticelstm实体抽取模型,得到实体识别结果;
s6:实体识别结果和测试集数据输入bigru-2att关系抽取模型,得到关系抽取结果。
进一步的,所述步骤s1中采用人工方式进行实体标注和关系标注。
进一步的,所述实体标注具体为:将实体标注数据转换为bmes实体标注体系,b表示实体的起始位置,m表示实体的中间部分,e表示实体的结束位置,s表示实体是一个单字实体;
所述关系标注具体为:将关系抽取数据转化为{实体1,实体2,实体1起始位置,实体1结束位置,实体1标签,实体2起始位置,实体2结束位置,实体2标签,文本段落}的形式。
进一步的,所述步骤s3具体为:
s3-1:将实体位置信息(包括起始位置、结束位置)和实体标签信息扩充字向量特征,实现文本信息的向量化,作为模型输入;
s3-2:模型网络第一层为双向gru:
每个gru单元分别包含包括一个重置门(resetgate)和一个更新门(updategate),更新门zt用于控制前一时刻输出ht-1与当前时刻输入xt中所含信息的保留程度,将其作为t时刻门控单元的输出ht,数值越大保留程度越高;而重置门rt通过xt决定前一时刻ht-1中信息的遗忘程度,重置门数值越小忽略程度越高。计算得到当前时刻的记忆
zt=σ(wz·[ht-1,xt])
rt=σ(wr·[ht-1,xt])
其中,σ()为sigmoid非线性激活函数,用于增强模型对非线性数据的处理能力,σ(x)=1/(1+e-x)。*表示点乘,tanh(x)=(ex-e-x)/(ex+e-x),w、wr、wz是模型的权值矩阵,[]表示将两个向量连接。
s3-3:模型网络第二层为字级注意力层:
对于一个句子向量w={w1,w2,…,wt}将步骤s3-2中所得结果ht,通过下式进行处理,得到ut;
ut=tanh(ww·ht+bw)
s3-4:第三层为句级注意力层:
将字级注意力层的输出s组成的句子特征值作为句级注意力层的输入,加入随机初始化的字上下文向量us进行共同训练,v是所有句子的向量和,具体公式如下:
ui=tanh(ws·si+bs)
s3-5:第四层为softmax分类器:
softmax分类器将v映射到一组元素在[0,1]区间内的向量,向量和为1,如下式所示:
y=softmax(v),y=[y1,y2,…,yn]andyi∈[0,1]and∑yi=1
其中,n为关系标签数量,即关系抽取分类数量;
s3-6:经过上述四层网络最终生成分类结果。
进一步的,事实上,句子中的每个字对句子含义的表达产生不等的作用,在字级注意力层训练过程中加入随机初始化的字上下文向量uw进行共同训练。通过加入字级注意层计算字与关系的相关程度,形成字级注意力层句子向量。字级注意力层计算公式如下:
其中αt为该字ut与uw的归一化表示,s为当前时刻加权后的字向量表示。
进一步的,所述步骤s4中采用latticelstm算法进行实体抽取模型训练;关系抽取网络选用sigmoid函数作为激活函数,采用softmax作为分类器进行关系抽取模型训练。
进一步的,所述步骤s4的关系抽取模型训练当中,添加l2正则化方法对关系抽取网络进行约束,训练过程中引入dropout策略,设置压抑概率,采用批量的adam优化方法用于模型参数训练。
进一步的,所述步骤s6完成后,对步骤s6所得到的关系抽取结果进行性能评价,其性能评价指标采用精确率、召回率和f1值,计算公式如下:
其中,tp表示正确分类的数量,fp表示把负类判断为正类的数量,fn表示把正类预测为负类的数量。
本发明利用latticelstm,将关注的各类实体从文本中抽取出来,通过构建基于多层注意力机制与双向gru的文本关系抽取网络,实现实体之间的关系抽取。
本发明前期利用latticelstm实体抽取算法,将关注的各类实体从文本中抽取出来,作为后续关系抽取基础。通过构建基于多层注意力机制与双向gru的文本关系抽取网络,实现实体之间的关系抽取。首先,利用实体位置信息(包括起始位置、结束位置)和实体标签信息扩充字向量特征,实现文本信息的向量化。接着,构建文本向量输入双向gru网络中,并加入字级注意力层和句级注意力层提高双向gru模型输入信息与输出信息间的相关性。最后通过softmax分类器处理注意力层的输出数据,得到实体之间的关系。
有益效果:本发明与现有技术相比,具备如下优点:
1、本发明利用实体位置信息和实体标签信息扩充字向量特征,实现文本信息的向量化,为关系识别提供更多的特征信息。
2、在双向gru网络中加入字级注意力层和句级注意力层,提高双向gru模型输入信息与输出信息间的相关性,增强关键字对输出的影响力并提高抗噪声能力。
3、本发明能够有效地提高中文文本关系抽取的精确率、召回率和f1值。
附图说明
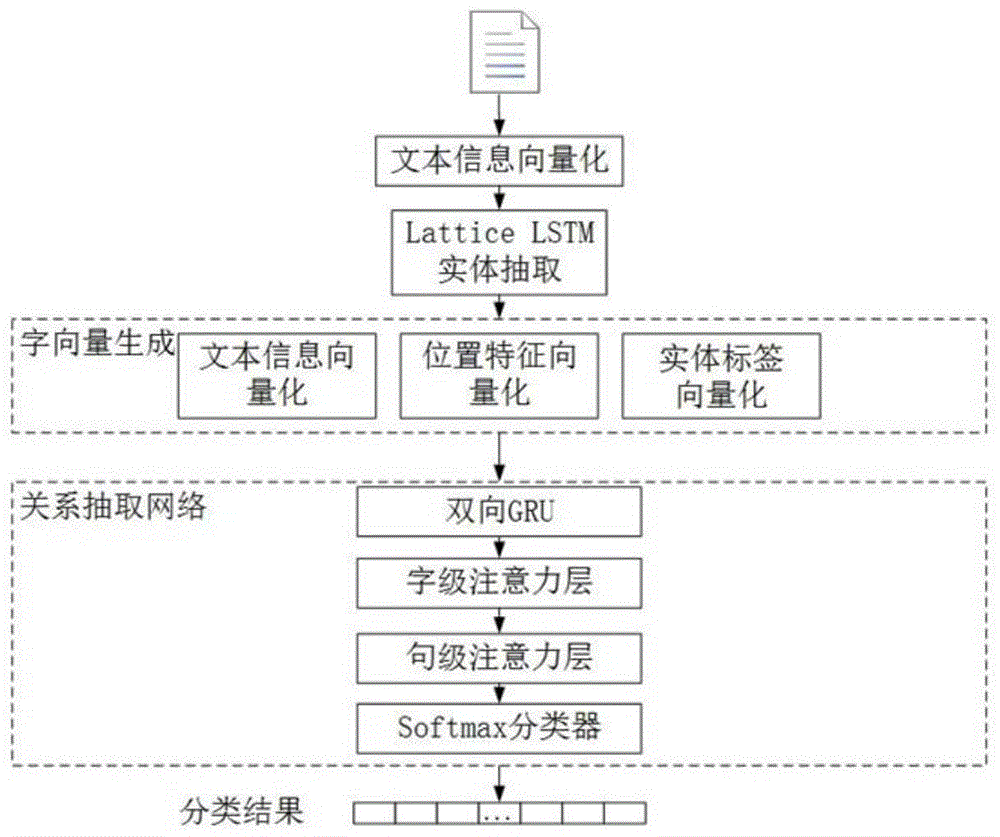
图1为关系抽取流程图;
图2为标注数据示意图;
图3为gru单元示意图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明。
本实施例通过具体的实验来验证本发明的效果,实验数据集以百度百科、互动百科军事语料为基础,经过人工标注生成。数据集中包括13940训练样本与2390测试样本,共包含24种关系。
如图1所示,关系抽取的具体步骤如下:
s1:进行实体和关系数据人工标注,具体如图2所示。
s2:对标注数据进行预处理,生成实体抽取模型和关系抽取模型的训练集和测试集:
将实体标注数据转换为bmes实体标注体系,b表示实体的起始位置,m表示实体的中间部分,e表示实体的结束位置,s表示实体是一个单字实体。将关系抽取数据转化为{实体1,实体2,实体1起始位置,实体1结束位置,实体1标签,实体2起始位置,实体2结束位置,实体2标签,文本段落}的形式。
s3:构建bigru-2att关系抽取网络,其具体步骤如下:
s3-1:将实体位置信息(包括起始位置、结束位置)和实体标签信息扩充字向量特征,实现文本信息的向量化,作为模型输入。
s3-2:模型网络第一层为双向gru:
每个gru单元分别包含包括一个重置门(resetgate)和一个更新门(updategate),具体如图3所示,更新门zt用于控制前一时刻输出ht-1与当前时刻输入xt中所含信息的保留程度,将其作为t时刻门控单元的输出ht,数值越大保留程度越高;而重置门rt通过xt决定前一时刻ht-1中信息的遗忘程度,重置门数值越小忽略程度越高。计算得到当前时刻的记忆
zt=σ(wz·[ht-1,xt])
rt=σ(wr·[ht-1,xt])
其中,σ()为sigmoid非线性激活函数,用于增强模型对非线性数据的处理能力,σ(x)=1/(1+e-x)。*表示点乘。tanh(x)=(ex-e-x)/(ex+e-x)。w、wr、wz是模型的权值矩阵。[]表示将两个向量连接。
s3-3:模型网络第二层为字级注意力层:
对于一个句子向量w={w1,w2,…,wt}将步骤s3-2中所得结果ht,通过下式进行处理,得到ut。
ut=tanh(ww·ht+bw)
事实上,句子中的每个字对句子含义的表达产生不等的作用,在字级注意力层训练过程中加入随机初始化的字上下文向量uw进行共同训练。通过加入字级注意层计算字与关系的相关程度,形成字级注意力层句子向量。字级注意力层计算公式如下:
αt为该字ut与uw的归一化表示,s为当前时刻加权后的字向量表示。
s3-4:第三层为句级注意力层:
将字级注意力层的输出s组成的句子特征值作为句级注意力层的输入。与字级注意力层相似,加入随机初始化的字上下文向量us进行共同训练,v是所有句子的向量和,具体公式如下:
ui=tanh(ws·si+bs)
s3-5:第四层为softmax分类器:
softmax分类器将v映射到一组元素在[0,1]区间内的向量,向量和为1,如下所示:
y=softmax(v),y=[y1,y2,…,yn]andyi∈[0,1]and∑yi=1
n为关系标签数量,即关系抽取分类数量。
s3-6:经过上述四层网络最终生成分类结果。
s4:分别进行latticelstm实体抽取模型训练和bigru-2att关系抽取模型训练:
s4-1:利用latticelstm算法进行模型训练。latticelstm将潜在词汇信息融入到基于字符的实体识别算法中,能更有效的利用文本信息。latticelstm具体实现过程请参考论文chinesenerusinglatticelstm(yuezhangandjieyang)。
s4-2:bigru-2att关系抽取网络选用sigmoid函数作为激活函数,采用softmax作为分类器。为了避免模型在训练过程中出现过拟合现象,添加l2正则化方法对bigru-2att网络进行约束。训练过程引入dropout策略,压抑概率设置为0.5,采用批量的adam优化方法用于模型参数训练。
s5:将测试集数据首先输入latticelstm实体抽取模型,得到实体识别结果。
s6:将实体识别结果和测试集数据输入bigru-2att关系抽取模型,得到关系抽取结果。
本实施例中对所得到的关系抽取结果进行性能评价,性能评价指标采用精确率(precision)、召回率(recall)和f1值,计算公式如下:
其中,tp表示正确分类的数量,fp表示把负类判断为正类的数量,fn表示把正类预测为负类的数量。
对测试样本进行识别后得到关系抽取的精确率、召回率和f1值为85.22%,87.57%,86.40%;同样的测试样本在传统lstm算法下,关系抽取的精确率、召回率和f1值为78.60%,80.32%,79.46%。由此可见,本发明方法能够有效的提升关系抽取的精确率、召回率和f1值。
- 还没有人留言评论。精彩留言会获得点赞!