一种基于自注意力机制的深度学习人脸识别系统及方法与流程
本发明属于计算机视觉与模式识别领域,更具体地,涉及一种基于自注意力机制的深度学习人脸识别系统及方法。
背景技术:
近些年来,随着计算机并行计算处理能力的高速发展,计算机视觉这一技术领域在深度学习的热潮推动下得到了长足的进步,并且在各个领域都有了一定的应用需求。人脸识别,作为视觉算法中让计算机能够自动识别监控数据中相关人员身份的技术,更是被广泛的应用到智能安防、人员考勤、社区巡查、自助服务等各种领域。例如,我国“平安城市智慧社区”计划中的天眼监控系统就是利用人脸识别技术来对嫌疑犯进行追踪与搜捕;在我们平时的生活工作中,也经常会利用到人脸识别技术,如校园实验室,企业办公室中安装的人脸识别系统,可以完成相关工作人员的考勤功能,同时也能阻止外来人员的侵入;另外,在金融支付领域,人脸识别技术也得到了充分的利用,如银行的atm机安装人脸识别系统防止他人的欺诈刷卡,以及移动支付中采用的刷脸支付等都是对安全的进一步保障。人脸识别技术在实际的部署环境中一般仅仅需要一个普通的摄像头即可完成识别认证操作,具有动态性、无需配合等优点,相比于传统的虹膜识别、指纹识别等生物特征有更加方便的优势,这些因素的存在也使得人脸识别技术的应用变得越来越广泛。
自2012年以来,得益于深度学习的理论发展以及gpu加速的技术进步,计算机对人脸图像的理解和分析有了质的飞跃。人脸识别技术也因为搭上卷积神经网络这一高速列车已经在非配合条件下达到了商业化应用的程度。特别是目前的基于监控视频的人员实时布控系统能够在解析监控视频流的同时自动检测分析抓取出视频中的人脸图像区域,并上传到后台服务器完成实时的人脸布控比对,同时进行异常人脸图像的报警,为当前“平安城市”的建设节省了大量的人力物力以及财力。
凭借着深度卷积神经网络(deepconvolutionalneuralnetwork,简称dcnn)对图像的解析能力,基于卷积神经网络的深度特征逐渐取代了传统手工特征在人脸识别中的地位。相比于传统的手工浅层特征,深度特征具有更强的区分能力与鲁棒性。目前基于卷积神经网络的人脸识别算法主要通过对损失函数的修改来实现特征空间的约束,如cosface、arcface等,但没有对网络结构上进行针对性研究。它通过通用的分类卷积神经网络进行特征提取,然后再最后的分类层上进行特征空间的约束,实现增大类间距离缩小类内距离的目的。这种针对损失函数的修改确实在很大的程度上增强了特征的区分能力,但是这些方法却都忽略了卷积神经网络结构本身在人脸识别特征提取中存在的一些问题。现有的卷积神经网络结构过于单一,导致了在前向传播的特征提取中存在信息冗余等问题,灵活性较弱,泛化能力略差。
目前的人脸识别算法中,使用的大多都是通用的图像分类的主干网络,这样的网络在实际的人脸应用中存在两个弊端。首先,通过标准的cnn网络提取出来的特征图经常具有很大的通道数,如resnet网络在后面阶段的通道数达到了2048,这样数量巨大的通道数在很大程度上带来了一定的信息冗余,甚至有可能存在网络过拟合的风险。尽管目前存在着一些诸如dropout的正则化方式来有效缓解这一问题,但结果仍然是不尽如人意的;其次,基于我们对现实世界的认知,人脸图像中的不同部位在实际的识别中应该是具有不同的重要性的,但是卷积神经网络中卷积核参数共享的机制却赋予了所有图像像素相同的权重,没能很好的对于不同的位置给出不同的处理方式。
技术实现要素:
针对现有技术通用卷积神经网络存在的特征图通道数较高导致过拟合以及卷积核权重共享机制导致的人脸不同位置没有被区分对待等缺陷和改进需求,本发明提供了一种基于自注意力机制的深度学习人脸识别方法。它的目的是首先通过一个通道自注意力模块学习特征图通道之间的互相关信息,得到通道之间的矩阵关系,给予不同通道赋予不同的重要性;然后再通过空间自注意力模块学习特征图位置之间的互相关信息,得到位置之间的矩阵关系,给予特征图空间位置不同的权重来学习人脸不同位置的重要性。该方法既能保留原卷积神经网络的优越性能,又能在神经网络的前向传输过程中对人脸图像特征进行优化,降低了图像通道间的信息冗余并且让卷积核集中在人脸图像中更重要的位置上,在提高人脸识别精确度的同时,又能增强模型的灵活性和泛化能力。
为实现上述目的,按照本发明的一个方面,提供了一种基于自注意力机制的深度学习人脸识别系统,所述系统包括:
输入模块,用于选择人脸图片训练集和输入待识别人脸图片;
基于自注意力的深度学习模块,所述基于自注意力的深度学习模块以resnet为基干网络,其包括多个残差块和多个注意力模块,所述注意力模块包括一个通道注意力模块和/或一个空间注意力模块,在每个残差块的末尾串行所述通道注意力模块和/或所述空间注意力模块,最后一层为全连接层,所述残差块用于对输入的人脸图片或者特征图进行特征图的进一步提取,所述通道注意力模块用于在前向传播过程中学习特征图通道之间的互相关关系矩阵,得到通道优化后的特征图,所述空间注意力模块用于在前向传播过程中学习特征图空间位置之间的互相关关系矩阵,得到空间位置优化后的特征图;所述全连接层用于将最终优化的特征图转化为特征;
训练模块,用于采用所述人脸图片训练集对所述基于自注意力的深度学习模块进行训练,得到训练好的基于自注意力的深度学习模块;
人脸识别模块,用于将所述待识别人脸图片输入所述训练好的基于自注意力的深度学习模块,输出人脸识别结果。
具体地,所述通道注意力模块通过以下步骤实现:
将输入特征图fi∈rc×h×w分别经过两个并行卷积,得到特征图θ(fi)∈rc×h×w、
特征图θ(fi)、φ(fi)分别经过并联的最大池化和平均池化操作,得到特征图
特征图pool(fi)1经过维度转换,得到特征图
由按行操作的softmax激活函数,得到通道自注意力矩阵
特征图fi经过卷积,得到特征图
对ac和ρ′(fi)进行矩阵相乘和维度转换,再对维度转换后的结果和fi逐位相加,得到最后通道优化的维度为c×h×w的特征图
其中,c、h、w分别表示原始特征图的通道维度、高、宽,θ、φ、ρ表示通道卷积操作,
具体地,通道自注意力矩阵ac展开如下:
其中,
具体地,所述空间注意力模块通过以下步骤实现:
将输入特征图fc∈rc×h×w分别经过两个并行卷积,得到特征图
特征图θ(fc)经过并联的最大池化和平均池化操作,得到特征图
分别对特征图φ(fc)和pool(fc)1维度转换,得到特征图
对特征图φ′(fc)t和pool′(fc)1进行矩阵相乘和softmax非线性激活计算,得到空间自注意力矩阵
特征图fc经过卷积,得到特征图ρ(fc)∈rc×h×w,经过并联的最大池化和平均池化操作,得到特征图
通过矩阵相乘和逐位相加,得到空间位置优化后的维度为c×h×w的特征图
其中,c、h、w分别表示原始特征图的通道维度、高、宽,θ、φ、ρ表示通道卷积操作,
具体地,损失函数l的计算公式如下:
其中,n和n分别表示当前批次的样本数量以及总共的类别个数,超参数s表示尺度缩放因子,
为实现上述目的,按照本发明的另一个方面,提供了一种基于自注意力机制的深度学习人脸识别方法,所述方法包括以下步骤:
采用人脸图片训练集对基于自注意力的深度学习网络进行训练,得到训练好的基于自注意力的深度学习网络;
将待识别人脸图片输入所述训练好的基于自注意力的深度学习网络,输出人脸识别结果;
其中,所述基于自注意力的深度学习网络以resnet为基干网络,其包括多个残差块和多个注意力模块,所述注意力模块包括一个通道注意力模块和/或一个空间注意力模块,在每个残差块的末尾串行所述通道注意力模块和/或所述空间注意力模块,最后一层为全连接层,所述残差块用于对输入的人脸图片或者特征图进行特征图的进一步提取,所述通道注意力模块用于在前向传播过程中学习特征图通道之间的互相关关系矩阵,得到通道优化后的特征图,所述空间注意力模块用于在前向传播过程中学习特征图空间位置之间的互相关关系矩阵,得到空间位置优化后的特征图;所述全连接层用于将最终优化的特征图转化为特征。
具体地,所述通道注意力模块通过以下步骤实现:
将输入特征图fi∈rc×h×w分别经过两个并行卷积,得到特征图θ(fi)∈rc×h×w、
特征图θ(fi)、φ(fi)分别经过并联的最大池化和平均池化操作,得到特征图
特征图pool(fi)1经过维度转换,得到特征图
由按行操作的softmax激活函数,得到通道自注意力矩阵
特征图fi经过卷积,得到特征图
对ac和ρ′(fi)进行矩阵相乘和维度转换,再对维度转换后的结果和fi逐位相加,得到最后通道优化的维度为c×h×w的特征图
其中,c、h、w分别表示原始特征图的通道维度、高、宽,θ、φ、ρ表示通道卷积操作,
具体地,通道自注意力矩阵ac展开如下:
其中,
具体地,所述空间注意力模块通过以下步骤实现:
将输入特征图fc∈rc×h×w分别经过两个并行卷积,得到特征图
特征图θ(fc)经过并联的最大池化和平均池化操作,得到特征图
分别对特征图φ(fc)和pool(fc)1维度转换,得到特征图
对特征图φ′(fc)t和pool′(fc)1进行矩阵相乘和softmax非线性激活计算,得到空间自注意力矩阵
特征图fc经过卷积,得到特征图ρ(fc)∈rc×h×w,经过并联的最大池化和平均池化操作,得到特征图
通过矩阵相乘和逐位相加,得到空间位置优化后的维度为c×h×w的特征图
其中,c、h、w分别表示原始特征图的通道维度、高、宽,θ、φ、ρ表示通道卷积操作,
具体地,损失函数l的计算公式如下:
其中,n和n分别表示当前批次的样本数量以及总共的类别个数,超参数s表示尺度缩放因子,
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
1、本发明依据注意力机制的原理,构建了一个通道自注意力模块,该模块通过对特征图的三维数据进行维度转换转置等操作,学习一个通道间的互相关关系矩阵,该矩阵表示不同通道间的相对关系,最后再通过跟原特征的计算得到通道优化后的特征,最终学习到不同通道间的互相关关系,对不同通道进行不同权重赋值,实现了通道过滤的选择,降低特征通道冗余信息。
2、本发明依据注意力机制以及全局特征表达等原理,构建了一个空间自注意力模块,该模块对三维特征图的空间信息进行建模,学习一个特征图空间位置间的互相关关系矩阵,该矩阵表示不同位置间的相对关系,最后再通过跟输入的特征进行计算得到空间位置优化后的特征,最终学习到不同空间位置间的互相关关系,对人脸特征图的不同位置赋予不同的权重,实现了人脸重要特征区域的选择,不同部位被区分处理,将特征集中在人脸最重要的区域。
附图说明
图1为本发明实施例提供的一种基于自注意力机制的深度学习人脸识别系统总体框架图;
图2为本发明实施例提供的通道自注意力模块结构图;
图3为本发明实施例提供的空间自注意力模块结构图;
图4为本发明实施例提供的通道自注意力和空间自注意力的模型结合示意图;
图5为本发明实施例提供的基于自注意力机制的人脸识别方法效果图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
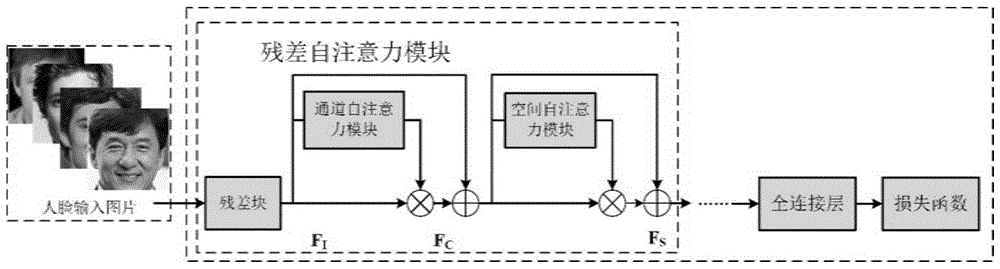
如图1所示,本发明实施例提供的一种基于自注意力机制的深度学习人脸识别系统中,残差自注意力网络模型(selfresidualattentionnetwork,sranet),在标准resnet的基础上进行改进。具体地,本发明在每一个标准残差块的末尾增加了一个串行的通道注意力模块和空间注意力模块,来计算通道注意力关系矩阵和空间注意力关系矩阵,然后通过矩阵相乘的形式获得最终的优化特征。另外,本发明移除了原始resnet结构中最后一层平均池化层,替换成一个固定大小为512维的全连接层,进行最后的特征提取。与平均池化的单通道平均相比,全连接层同时考虑通道与空间信息,配合通道与空间注意力模块,设计更为合理。
以图1中数据为例,假设卷积神经网络中某一残差块的原始输出为fi,基于自注意力机制的sranet,首先将fi输入到一个通道自注意力模块中进行通道注意力矩阵的计算,得到不同通道之间的互相关矩阵信息以后,将fi与通道自注意力矩阵进行矩阵相乘运算,然后再与原始输入进行逐位相加的操作最终得到经过通道优化后的特征fc;同理,使用相同的方式还可以得到空间位置优化后的特征fs,最终,fs将作为本残差结构的输出输入到下一个残差结构中去,图中的省略号表示有多个这样的结构。
本发明将人脸识别分为四个阶段:人脸图像预处理阶段、自注意力模型构建阶段、损失函数计算阶段、特征提取与检索比对阶段。
人脸图像预处理阶段
人脸图像预处理阶段包括:对人脸数据集的选择、对人脸数据的预处理。其中,人脸数据预处理主要分为两个部分:人脸检测和关键点对齐、图像数据归一化。
对于人脸检测和人脸关键点对齐,本发明使用业界常用的级联的多任务卷积神经网络mtcnn,同时进行人脸位置和人脸关键点的预测。在实际训练中,预测出4个坐标位置和5个关键点位置,然后通过相似性变换,将检测出来的原始人脸裁切成固定大小的112×112的人脸图片。
对于图像数据归一化,本发明将原始的rgb图像中的像素值都先减去127.5,然后再除以128,从而归一化到[-1,1]。另外在训练时候对归一化后的训练集采取50%的概率进行水平翻转,达到数据集扩充的效果,提升整体系统精度。
自注意力模型构建阶段
(2.1)选择基干网络
本发明采用resnet-50/resnet-100作为自注意力模型的基干网络,进行人脸识别模型的训练,在resnet残差块的设计中,选取的是3×3的卷积核大小。
(2.2)通道自注意力模块的设计与实现
在主干网络的每一个残差块后面添加一个通道自注意力模块,来学习卷积神经网络前向传输过程中特征图通道间的互相关关系。
通道自注意力模块的结构如图2所示。输入特征图fi∈rc×h×w,先将输入特征图输入到两个并行的1×1的卷积层中,它们的空间尺度保持不变,其中一个通道数量减半,得到特征图
其中,
接着,对两个特征图pool(fi)1、pool(fi)2进行维度转换和/或转置操作。特征图pool(fi)1经过维度转换,将
最后再由按行操作的softmax激活函数得到通道自注意力矩阵ac。
将公式展开:
其中,
在以上的所有公式中,c、h、w分别表示输入特征图的通道维度、高、宽,θ、φ、ρ表示通道卷积操作,
(2.3)空间自注意力模块的设计与实现
在通道自注意力模块的后面,紧接着的是一个串行的空间自注意力模块,进行特征图位置之间关系的学习,其中,所有参数通过神经网络反向传播技术训练,自适应学习。
如图3所示,输入特征图fc∈rc×h×w,空间自注意力模块首先将输入特征fc输入到两个并行的1×1的卷积层中,它们的空间尺度保持不变,但是进行一定程度的通道降维,得到特征图
然后分别将φ(fc)和pool(fc)1维度转换成
像通道自注意力一样展开,可以得到:
在这个公式中,
接着,计算空间自注意力关系矩阵以后,也同样给输入特征fc一个卷积,得到ρ(fc)∈rc×h×w,经过池化变为
在以上的所有公式中,θ,φ,ρ表示的是卷积操作,
(2.4)特征优化与特征提取设置
如图4所示,本发明为了充分对三维特征图进行全面的优化,分别将通道自注意力模块和空间自注意力模块以串联的方式连接在主干网络resnet残差块的后面,以此来对前向传播过程中的特征图进行优化。图4的拓扑结构包含点乘与点加操作,箭头指引输入向输出流动的方向。
另外,在最后的特征提取方面,移除原始resnet的全局平均池化层,将前面经过优化后的特征输入到一个固定大小维度的全连接层中去,全连接层的维度固定设置为512,替换为一个512维的全连接层供最后的特征提取使用。
损失函数计算阶段
为了有效解决目前常用的损失函数不能比较全面的对特征空间的所有样本进行有效约束的问题,本发明提出了一种改进的基于多间隔约束的损失函数l。
该公式建立在权重归一化和特征归一化的基础上,即本发明首先需要
特征提取与检索比对阶段
待识别人脸图像被训练完成的模型处理后,获得一个固定大小维度的特征向量,使用该向量与库中已经线下提取好的特征进行实时对比,并根据计算得到的余弦相似度similarity和设定的阈值,判断是否是需要检索的人物。本实施例中通常阈值设定范围在0.6~0.7。
特征的提取与检索对比是线上进行实时人脸识别时的阶段,将给定待搜索的人脸按照相同的处理方式输入到已经训练好的模型中去,在最后一个全连接层提取固定大小为512维的特征向量,这个特征向量与库中已经线下提取好的特征进行余弦相似度对比,余弦相似度计算公式如下:
其中,ai、bi分别指待检索人脸图像的特征与搜索库中已经保存的人脸图像特征,取相似度最高且相似度大于设定阈值的若干张图像作为查询结果,并完成最终的人脸识别过程,p表示特征向量的维度,此处p=512。
实施例
为了证明基于自注意力机制的深度学习人脸识别方法在性能和适应性上都具有优势,本发明通过以下实验进行验证与分析:
a、实验数据集
训练集:casia-webface和ms-celeb-1m。casia-webface总共有10575个人共计49.4万张人脸图像。ms-celeb-1m的原始数据中共有100k的人共计10m的人脸图片,但由于错误样本较多,所以训练时采用的是清洗之后的样本,共计86876个人3.9m的图像。
测试集:lfw、agedb-30、cfp-fp以及megaface。其中,lfw、agedb-30和cfp-fp测试的是小规模的人脸验证精确度,而megaface则测试的是百万级别下的人脸识别精确度和百万分之一虚警率下的人脸验证精确度。
b、评价标准
本发明采用国内外人脸识别研究的主流评估标准,对于人脸验证测试而言,采用的是准确率来评价,假设测试的样本集共有k对图片,其中判断错误的有l对,那么人脸验证的精确度就是:
对于百万级别的megaface的识别精确度而言,采用的是累积匹配特征第一准确率cmc@1,也就是rank1识别率。对于我们假设一个人脸查询集的大小为q,对其中的每一张待查询图像qi,i=1,2,...,q分别进行相似度排序匹配工作,若每一张查询图像qi第一个正确匹配的图像位置是r(qi),那么cmc@k的计算公式为:
在cmc曲线中,k越大,识别的准确率也就越高,在本发明中的megaface测试协议中,将对rank1的识别结果进行分析,即cmc@1。
c、实验结果
实验表明,本发明在lfw、agedb-3、cfp-fp上的人脸验证精确度分别达到99.83%、98.67%和95.86%;另外,在百万级别的megaface上的rank1识别率为98.38%,虚警率为百万分之一的验证率为98.45%,均达到领先水平。同时,本发明将现有主流方案在几个数据集上都进行了实验比较,实验结果如下表所示:
表1lfw、agedb-30和cfp-fp的人脸验证精确度(%)
表2megaface测试结果(%)
从上面两个表格可以看出,在相同的实验环境下,本发明均表现出优越的性能,另外,本发明也对基于自注意力机制的人脸模型进行了可视化处理,结果如图5所示,可以看到带有注意力模块的人脸模型具有更清晰的人脸轮廓,使得该人物更加容易辨识,这充分证明了基于自注意力机制的模型可以有效地对卷积神经网络前向传输过程进行特征优化,增强了人脸特征的区分力和鲁棒性。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!