一种基于支持向量机的泵站故障分类方法与流程
本发明涉及泵站故障分析
技术领域:
,具体为一种基于支持向量机的泵站故障分类方法。
背景技术:
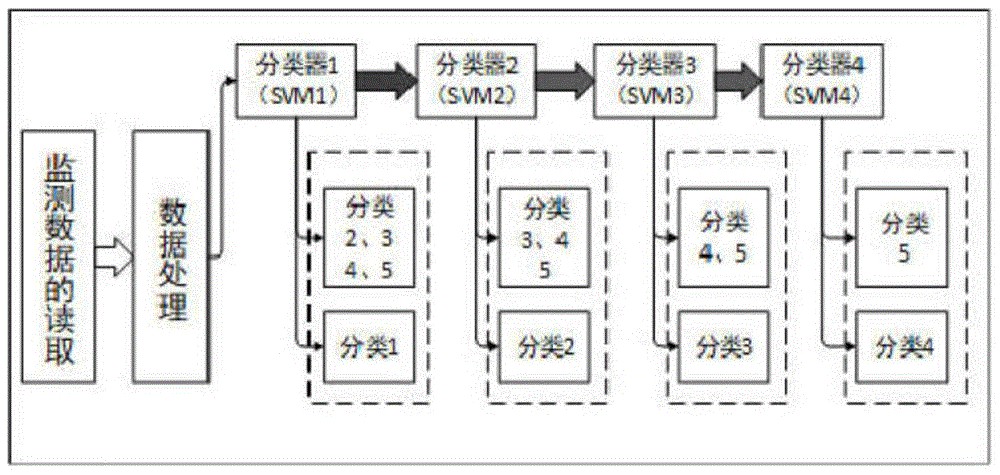
:泵是用来输送或提升液体的机器,它能把原动机的机械能(如电机的电能)转化为被输送液体的动能或势能。由于泵的品系种类繁多且在工农业各部门领域中应用很广,因此分类方法多种多样,按其作用原理和结构可分为以下三类:(1)叶片式泵:根据离心力甩水原理设计出来的,靠装有叶片的叶轮的高速旋转来带动液体液体的输送的泵。常见的叶片式泵有离心泵、轴流泵、混流泵、旋涡泵等,其中离心泵中分支分类最多,使用范围也最广。(2)容积式泵:它对液体的压送是靠泵内部工作室容积的改变来完成的,按照工作容积变化的方式的不同又可分为往复试泵和回转式泵。常用的往复式泵有活塞式泵和柱塞式泵两种。常用的回转式泵有转子泵等。(3)其他类型泵:指的是除了叶片式泵和容积式泵以外的,主要靠螺旋推进或利用高速液流或气流的能量来押送液体的特殊泵。其中常见有螺旋泵、射流泵、水锤泵、水轮泵以及气升泵(又称空气扬水机)等。随着现代自动化技术的迅猛发展,泵站机组早已实现大型化和复杂化,其自动化程度也得到了巨大的提升。泵站机组的关键作用使得其非计划停机所带来的经济损失也在成倍的增加。因此,对于泵站的故障分类的研究具有十分重要的意义,可以概括为以下几点:(1)通过计算机对监测数据处理直接输出故障类别信息,分类的同时也直接将故障定位在实际的故障组件,大幅的缩减了泵站工作人员寻找排查故障位置的时间与工作量。(2)在实验建模过程中,建立监测所得数据与不同故障类别间的简单对应,进而分析可通过数据更加直观的了解各个部分性能的劣化情况和机械性能的发展趋势。(3)通过分析实验与分析数据可以掌握不同类型故障的早期征兆,工作人员可采取相应的措施进行针对性的检修维护,将故障消灭在萌芽状态,大幅减少非计划性停机等事故发生的概率,从而提高泵站管理水平。支持向量机(supportvectormachine,简称svm)是在统计学习理论基础上发展而来,由v.vapnik及其合作者于at&bell实验室共同创造和发展起来的一种针对分类和回归问题的机器学习方法。支持向量机的核心理论在1992-1995年才被陆续提出,最初来自于对数据分类问题的处理,但由于其能有效地避免经典学习方法中过学习、维度灾难和局部极小值等传统分类存在的问题,在小样本的情况下仍然具有良好的推广泛化能力,因此受到了该领域广泛的关注。近年来。支持向量机方法已经被成功的应用到了文本分类、复杂信号处理、生物特征识别、手写字体分析等多种领域。支持向量机实现分类的过程实际上就是寻找一个满足分类要求的最优超平面的过程,其通过对训练数据集即特征向量和目标类别的对应关系不断学习、在学习对比中得到一个合理的分类判别规则,即产生分类模型。然后将需要进行分类的特征数据输入进已经训练好的分类模型,完成所需的分类任务。技术实现要素:本发明提出一种基于支持向量机的泵站故障分类方法,其能较好的解决高维度的非线性问题,能够适用于泵站系统这种复杂的大型非线性系统。并且通过实验在样本数一定的环境下验证了该方法的可行性。本发明的技术方案:在泵站的故障分类中,先是使用hu不变矩理论进行泵站轴心轨迹的识别,然后在此基础上进行故障分类。发明以山西大禹渡水泵机组监测与故障分类数据展开介绍泵站的故障分类的实验过程,所用数据为泵站现场所监测到的摆度信号和通过数据模拟得到的。然而现场监测到的原始摆度信号不能直接用于支持向量机的训练,需要通过变换得到满足hu不变矩理论的特征数据。其中一共提取了48组数据,每组训练数据的七个特征向量分别代表信号经过处理后得到的七个不变矩。分析结果可知,支持向量机的泵站故障分类方法的分类正确率要好于神经网络方法,且神经网络方法存在训练时间长,存在过拟合的问题。本发明基于支持向量机的泵站故障分类方法要整体优于基于神经网络的分类方法。一种基于支持向量机的泵站故障分类方法,所述方法的具体步骤如下:步骤1:数据提取;步骤2:分层训练svm;将多类泵站故障类型两两可分的特点与支持向量机理论相结合,构造出四层的svm分类器,对泵站的五种典型故障进行分类;步骤3:输出结果,进行分析。具体地,步骤1中在泵站的故障分类中,先使用hu不变矩理论进行泵站轴心轨迹的识别,然后在此基础上进行故障分类。具体地,步骤2中所述五种典型故障包括:第1类故障为轴承不对中,该故障指的是轴承位置偏高或者左右位置高度不平;第2类故障表示由内部转动部件不平衡或大轴轴线不直引起的摆度过大故障,第3类故障表示油膜的楔形按油的平均流速绕轴瓦中心运动所导致的油膜涡动故障;第4类故障表示为对中不良引起的振动,第5类故障表示为出水管涡动引起的故障。具体地,第一层的svm分类器将所有故障样本数据中的第1类故障标记为1,其余4类故障标记为0,由此训练得到第一层分类模型;第二层svm分类器对剩下四种故障数据进行训练和分类,将第2类故障标记为1,其余剩下的3类故障标记为0,由此得到第二层分类模型;与svm2同理,将剩余三类故障数据输入到第三层svm分类器中,svm3将第3类故障标记为1,剩下类型4,5标记为0。在最后一层svm分类器中,对故障类型4和5进行训练和分类,输出将故障类型4标记为1,故障类型5标记为0;最后通过标记分析,完成四层支持向量机的训练模型的全部过程。一种基于支持向量机的泵站故障分类方法,其基本思想是:寻找一个满足分类要求的最优超平面,其通过对训练数据集即特征向量和目标类别的对应关系不断学习、在学习对比中得到一个合理的分类判别规则,即产生分类模型。然后将需要进行分类的特征数据输入进已经训练好的分类模型,完成所需的分类任务。具体思想如下:在线性可分情况下寻找最优超平面的问题可以转化二次规划问题,并且可以通过引入拉格朗日函数转化成对偶问题,处理此二次规划问题即可得到最优超平面的分类函数。对于线性不可分情况,通过对松弛项ξi≥0和惩罚因子c>0的调节控制,同时考虑最少错分样本数和最大分类间隔,再带入多元函数极值存在的必要条件即可得到该问题的对偶形式。对于非线性情况,需要把训练数据经过特定核函数映射到高维特征空间,然后在高维特征空间中,通过计算核函数的方法就能求得最优分类超平面。此时选取不同核函数和不同的参数可以得到不同的支持向量机算法。为了更好的理解本发明所涉及的技术和方法,在此对本发明涉及的理论进行介绍。1、泵站故障原因泵站故障通常分为电气设备故障和机械设备故障两大部分。离心泵常见的故障类型以及部分产生原因见下表:2、最优分类超平面在用神经网络方法解决分类问题时,通常会引入超平面的概念:要求神经网络通过训练找到一个可移动的超平面,该超平面最终能使训练集中属于不同类别的点位于该平面的左右两侧。但该方法最大的缺点就是所得的超平面可能与其中一个类别的距离更近,不满足最优超平面。支持向量机方法同样要求寻找一个超平面,与神经网络方法所不同的是,该超平面不仅要求能正确划分不同类别的样本,而且需要各个类别与超平面之间的最近距离都能取最大,即用最大的间隔将样本分开的最优分类超平面(optimalseparatinghyper-plane)。我们以两类线性司分的样本为例展开分析,设有样本:(x1,y1),(x2,y2),l,(xl,yl),x∈rn,y∈{-1,+1}(1)其中x,y为样本参数,rn表示n维实数空间。可用超平面(w为权值、b为偏置)w·x+b=0(2)进行分类,即存在(w,b)使得:当yl=1时,(w·x1)+b>0当yl=-1时,(w·x1)+b<0此时参数w,b约束于min|w·x+b=0|=1(3)其中min为取最小值。超平面约束于ylg(w·x1)+b≥1,i=1,2,l,l.(4)其中i为下标,l为样本数据量。样本到超平面的距离d:在此基础上进行判别函数的归一化,让离分类平面最近的样本刚好满足(w·x1)+b=1。由线段距离公式可知分类间隔为2/||w||,要使取得间隔最大值,即相当于使||w||(或||w||2)取最小值。因此要求分类超平面满足上述条件(4),并且使||w||(或||w||2)最小,得到的分类面就叫最优分类面,如图4所示。图中黑点和白点表示两种不同类别的样本,h为分类线即二维的分类平面,h1、h2分别为过不同类中离分类线最近的样本点,且平行于h分类线的直线。这两条直线的间距就是分类间隔或者分类间隙(margin),h1、h2上的点就是所说的支持向量(supportvector)。所谓最优超平面,要求分类面不仅能将两类样本正确分开,而且两种类别的margin取最大。将该直线的约束条件推广到高维空间,最优分类线也成为我们说的最优分类超平面。3、支持向量机算法在线性可分情况下寻找最优超平面的问题可以转化二次规划问题,并且可以通过引入拉格朗日函数转化成对偶问题,处理此二次规划问题即可得到最优超平面的分类函数。对于线性不可分情况,通过对松弛项和惩罚因子的调节控制,同时考虑最少错分样本数和最大分类间隔,再带入多元函数极值存在的必要条件即可得到该问题的对偶形式。对于非线性情况,需要把训练数据经过特定核函数映射到高维特征空间,然后在高维特征空间中,通过计算核函数的方法就能求得最优分类超平面。此时选取不同核函数和不同的参数可以得到不同的支持向量机算法。4、与二叉树结合的svm对于多分类问题,支持向量机中一般有直接和间接两种处理方法。前者是直接通过大量的运算计算出用于多分类的分类函数,有很明显的学习训练耗费时间长,计算过程复杂等特点,因此在实际问题中并不适用。后者主要是通过多个二分类支持向量机的组合来实现支持向量机的多分类。其常用的有一对一和一对多两种方法。因此对于n分类问题(n>2),最后都用分解为多个二分类的方法来解决。对于n类可分的问题,那么这n类之间一定两两可分,由此可得,对于n分类的问题,在知道其中不同类别间是两两可分的情况下,可以通过二分类的相互组合,去完成n分类的问题。用一个基本二叉树来代表n项不同分类的问题,该二叉树中每个二叉树的叶结点代表样本中的一个类别,每个度为2的非叶结点代表一个分类过程中所用的svm分类器。因此整体统计下来,该分类二叉树共有2n-1个结点,其中有叶结点的数目为n,svm分类器的数目为2n-1。将多分类的复杂问题转化为多项一对一分类的基础问题,能有效的降低错误率,且能有较快的训练速度。本发明的技术效果在于:本发明基于支持向量机的分类方法对比于其他方法来说分类的正确率较高,能在较短的时间内训练得到分类模型,实时性好。对训练样本集要求低,不存在过拟合和局部极小值的问题。附图说明图1为基于支持向量机的泵站故障分类原理图;图2为各层svm预测输出与实际对比图;其中,2a为第一层svm预测输出与实际对比;2b为第二层svm预测输出与实际对比;2c为第三层svm预测输出与实际对比;2d为第四层svm预测输出与实际对比。图3为最终svm预测输出与实际对比图;图4为最优分类面示意图。具体实施方式下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。一种基于支持向量机的泵站故障分类方法,具体包括如下步骤:步骤1:数据提取。在泵站的故障分类中,先是使用hu不变矩理论进行泵站轴心轨迹的识别,然后在此基础上进行故障分类。步骤2:分层训练svm。将多类泵站故障类型两两可分的特点与支持向量机理论相结合,构造出四层的svm分类器对泵站的五种典型故障进行分类。步骤3:输出结果,进行分析。取山西大禹渡水泵机组监测与故障分类所得且经过hu不变矩变换所得的48组数据作为数据集,每组数据包含7个特征向量,共涉及五种故障类型,将需要分类的监测数据输入到该分类模型,得到预测的分类结果。仿真实验结果分析:1.实验数据在泵站的故障分类中,先是使用hu不变矩理论进行泵站轴心轨迹的识别,然后在此基础上进行故障分类。发明以山西大禹渡水泵机组监测与故障分类数据展开介绍泵站的故障分类的实验过程,所用数据为泵站现场所监测到的摆度信号和通过数据模拟得到的。然而现场监测到的原始摆度信号不能直接用于支持向量机的训练,需要通过变换得到满足hu不变矩理论的特征数据。其中一共提取了48组数据,每组训练数据的七个特征向量分别代表信号经过处理后得到的七个不变矩。取前22组数据作为训练样本(见表1),取后26组作为测试样本(见表2)表1训练数据样本集not1t2t3t4t5t6t7类别11.17570.62050.45140.0156-0.0004-0.0116-0.0009120.61150.31710.00460.005200.00280130.6090.20520.05260.00630-0.0160141.16960.98770.51240.12670.02610.12040.0102550.94690.56520.11040.11040.02060.0779-0.0058561.21520.63120.12910.12910.01170.10250.0036371.15230.89440.04880.08420.00520.06230381.15230.6141.13020.11720.03110.0089-0.0173491.0460.75730.2540.14550.02720.1250.00154101.52880.2962000002111.0690.6096000002121.15520.3618000002131.34650.6904000002140.01920.0002000002150.02550.0002000002160.0360.0005000002170.96430.53740.05310.11470.0066-0.0414-0.00234181.29591.26580.69890.05840.0081-0.0088-0.00021191.15630.94530.48530.08830.01280.07920.00835201.23740.66710.00940.02130.00020.01740.00023210.57820.23420.01870.000900.000104221.13440.76090.07860.13990.01410.10720.00133表1中最后一项表示该组特征数据所对应的故障类别。其中第1类表示故障为轴承不对中,该故障指的是轴承位置偏高或者左右位置高度不平;第2类表示由内部转动部件不平衡或大轴轴线不直引起的摆度过大故障,第3类表示油膜的楔形按油的平均流速绕轴瓦中心运动所导致的油膜涡动故障;第4类表示故障为对中不良引起的振动,第5类表示故障为出水管涡动引起的故障。表2测试数据2.分层训练svm本发明以山西大禹渡水泵机组检测与故障分类数据为数据集,将多类泵站故障类型两两可分的特点与支持向量机理论相结合,构造出四层的svm分类器对泵站的五种典型故障进行分类。基于支持向量机的泵站故障分类的基本原理框图如图1所示。图中第一层的svm分类器将所有故障样本数据中的第1类故障标记为1,其余4类故障标记为0,由此训练得到第一层分类模型;第二层svm分类器对剩下四种故障数据进行训练和分类,将第2类故障标记为1,其余剩下的3类故障标记为0,由此得到第二层分类模型;与svm2同理,将剩余三类故障数据输入到第三层svm分类器中,svm3将第3类故障标记为1,剩下类型4,5标记为0。在最后一层svm分类器中,对故障类型4和5进行训练和分类,输出将故障类型4标记为1,故障类型5标记为0。最后通过标记分析,完成四层支持向量机的训练模型的全部过程。3、实验结果分析对比取山西大禹渡水泵机组监测与故障分类所得且经过hu不变矩变换所得的48组数据作为数据集,每组数据包含7个特征向量,共涉及五种故障类型。取前21组(表1)数据作为svm训练样本集,后27组(表2)数据作为测试数据。按照图1所示原理,将40组数据输入到分类器中进行训练得出分类模型,在将测试数据输入到训练所得的分类模型中,所得到的结果输出如表3所示。表3基于支持向量机的泵站故障分类结果表中结果分析一项的y代表故障分类器输出结果与实际故障类型一致,即故障分类结果正确,n表示该分类器的输出结果与实际类型不符,即故障分类结果错误。由表3中结果分析一栏可知,对于26组测试数据,该分类的输出结果中只有1组存在问题,其余25均被正确分类在对应的故障类别当中,有着较高的分类精度。为便于分析每一层支持向量机的输出情况,现将每层支持向量机分类的输出结果与该层实际结果做对比,对比如图2所示。通过图2可以发现,每层的实际输出与理论输出高度一致,仅有个别点产生误差。通过图3的最终svm预测输出与实际对比可知,理论曲线与实际曲线基本重合,由22组数据训练得出的支持向量机分类模型,将26组数据中的25组成功进行了分类。很直观的体现出基于向量机泵站故障分类方法分类精度高的特点。表4神经网络与多级支持向量机分类器分类结果对比通过与当前使用较多的通过神经网络的故障诊断方法相对比,能够更加全面的比较出基于支持支持向量机的分类方法的优缺点。由表4可知,与本次分类器采用相同的数据处理方法和相同的数据集,输入到包含7个输入、46个隐藏和5个输出节点的某bp神经网络中。通过输出结果可知,支持向量机的泵站故障分类方法的分类正确率要好于神经网络方法,且神经网络方法存在训练时间长,存在过拟合的问题。综上所述,基于支持向量机的泵站故障分类方法要整体优于基于神经网络的分类方法。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1