多存储节点系统和多存储节点系统的容量管理方法与流程
本发明涉及多存储节点系统和多存储节点系统的容量管理方法。
背景技术:
近年来,用软件管理在多个节点中分布的存储装置而将整体定义为大的存储装置、提高使用效率的技术即软件定义存储(softwaredefinedstorage(sds))正在普及。
在这样的存储区域分布在多个节点中的系统中,系统整体的空闲容量的管理非常重要。作为管理在多个节点中分布的系统的空闲容量的技术,有专利文献1。
专利文献1中,公开了将在多个节点中分布的存储区域连结来作为一个存储区域供主机计算机访问的技术。
现有技术文献
专利文献
专利文献1:日本特开2005-165702号公报
技术实现要素:
发明要解决的课题
sds这样的由多个节点构成的多存储系统中,通过应用在多个节点的驱动器中保存数据的mirroring和erasure-coding技术,而使数据冗余化。
一般的sds中,在节点或节点中搭载的驱动器故障时、节点或驱动器减少设置时、检测到驱动器故障的征兆时,为了恢复保存的数据的冗余性而进行数据的重建(rebuild)。例如,通过在驱动器故障时使发生了故障的驱动器中保存的数据在多存储系统的其他驱动器中重建,而在多存储系统中确保数据的冗余性。
为了进行恢复数据冗余性的数据重建,在发生了驱动器或节点故障的情况、和进行节点或驱动器减少设置的情况下,冗余数据需要存在于由多个节点构成的系统中,需要用冗余数据将数据重建并保存的物理容量。
但是,专利文献1中,虽然公开了将在多个节点中分布的存储区域连结来作为1个存储区域管理空闲区域的技术,但这是为了对于逻辑设备,在分配物理设备时判断存储适配器(sa)内是否存在空闲区域的,关于得知用于数据重建的空闲容量并未提及。
另外,关于在sds环境中为了数据重建而按节点中搭载的驱动器单位、节点单位、将多个节点定义为故障集的故障集单位管理容量并未提及。
于是,本发明的目的在于提供一种在多存储节点系统中,为了确保数据的冗余性,而确保用于数据重建的容量的多存储节点系统、多存储节点系统的容量管理方法。
用于解决课题的技术方案
为了达成上述目的,本发明的多存储节点系统的一个方式由多个存储节点构成。多个存储节点具有用于存储数据的多个驱动器和控制对多个驱动器写入数据的控制部。控制部通过将多个驱动器的存储区域分割为多个物理块并将分割出的物理块分配给逻辑块来保存数据。多个存储节点被分为因单个故障而受到影响的故障集,管理多存储节点系统的、多个存储节点中的一个主节点的控制部包括数据库,该数据库按每个驱动器、每个存储节点、每个故障集管理多个存储节点的物理块对逻辑块的分配。
发明效果
根据本发明,在多存储节点系统中,即使在驱动器或节点故障、驱动器或节点减少设置时,也能够按驱动器、节点、故障集单位管理为了确保数据冗余性而进行数据重建用的容量管理。
附图说明
图1是表示本实施例的系统结构图的一例的图。
图2是表示本实施例的存储节点的硬件结构图的一例的图。
图3是表示本实施例的控制部与存储节点之间的卷的定位的一例的系统框图。
图4是表示本实施例的各种管理表的一例的图。
图5是表示本实施例的存储节点管理表的一例的图。
图6是表示本实施例的驱动器管理表的一例的图。
图7是表示本实施例的物理块管理表的一例的图。
图8是表示本实施例的逻辑块管理表的一例的图。
图9是表示本实施例的已分配物理块(节点)管理表的一例的图。
图10是表示本实施例的空闲物理块(节点)管理表的一例的图。
图11是表示本实施例的已分配物理块(故障集)管理表的一例的图。
图12是表示本实施例的空闲物理块(故障集)管理表的一例的图。
图13是表示本实施例的集群控制的处理流程的流程图。
图14是表示本实施例的通知条件(1)的确认处理流程的流程图。
图15是表示本实施例的通知条件(2)的确认处理流程的流程图。
图16是表示本实施例的通知条件(3)的确认处理流程的流程图。
图17a是表示本实施例的基于通知条件(1)的警报(1)的一例的图。
图17b是表示本实施例的基于通知条件(2)的警报(2)的一例的图。
图17c是表示本实施例的基于通知条件(3)的警报(3)的一例的图。
图18是表示本实施例的节点内优先分配处理的流程图。
图19是表示本实施例的对dp池的物理块分配处理的流程图。
具体实施方式
对于实施方式,参考附图进行说明。另外,以下说明的实施方式并不限定与权利要求书相关的发明,并且实施方式中说明的各要素及其组合的全部对于发明的解决方案并不一定是必需的。
以下说明中,有时用[aaa表]的表达说明信息,但信息可以用任意的数据结构表达。即,为了表示信息不依赖于数据结构,能够将[aaa表]改为[aaa信息]。
另外,以下说明中,[cpu]是包括1个以上处理器的centralprocessingunit(中央处理器)。处理器可以包括进行处理的一部分或全部的硬件电路。
另外,以下说明中,有时以[程序]为动作主体说明处理,但程序通过由cpu执行而适当使用存储资源(例如存储器)等进行规定的处理,所以实际的处理主体是cpu。从而,以程序为动作主体说明的处理也可以视为处理器进行处理。另外,也可以包括进行处理器进行的处理的一部分或全部的硬件电路。计算机程序可以从程序源安装在装置中。程序源例如可以是程序发布服务器、或者计算机可读取的存储介质。
<概要>
本技术中,在多存储节点系统中,即使在发生了将多个节点作为单位的故障集、节点、各节点中搭载的驱动器单位的故障、和节点或驱动器的减少设置的情况下,在softwaredefinedstorage(sds)中,也必须预先在适当场所(故障集、节点)中确保用于数据重建的容量。另外,sds需要减小数据重建时对i/o性能的影响。此处,故障集例如指的是将从同一电源系统接受电源供给的节点合并而成的组或将用同一交换机与网络连接的节点合并而成的组,是因单个故障而受到影响的节点的组。即,故障集是以即使在电源故障或交换机故障时、冗余数据也能够存在于多存储节点系统中的方式将节点分组而成的。
这样,在多个节点被按故障集这一概念分组的多存储节点系统中,管理者非常难以判断用于将数据重建的适当场所(故障集、节点),即在何处确保用于保存重建数据的物理容量。
本技术涉及在多存储节点系统中,对于为了即使在驱动器或节点故障、驱动器或节点减少设置时也确保数据冗余性而进行数据重建用的容量管理,按驱动器、节点、故障集单位进行管理,能够按驱动器、节点、故障集得知重建数据的保存位置的多存储节点系统、多存储节点系统的容量管理方法。
<用语的说明>
sc(storagecluster):存储集群相当于多存储节点系统整体。
fs(faultset):故障集是存储集群的子集,是因单个故障而受到影响的存储节点的组。例如,是共享电源系统或网络交换机的节点的组,是因电源故障或网络交换机的故障而受到影响的节点的组。为了在这些单个的电源故障时等也确保数据的冗余性,存储集群中冗余数据需要存在于其他故障集中。
sn(storagenode):存储节点。
cm(p)(clustermaster(primary)):集群主(首要)是管理多存储节点系统整体的存储节点,在多存储节点系统中存在一个。称为主节点。
cm(s)(clustermaster(secondary)):集群主(次要)是集群主(首要)的待机系统节点,在集群主(首要)中发生了故障的情况下,晋升为集群主(首要)。
cw(clusterworker):集群工作节点,集群主(首要、次要)以外的存储节点。
cn(computenode):计算节点。运行对存储节点中保存的数据进行访问的应用程序的计算节点。
mn(managementnode):管理节点。管理存储集群的节点。
<系统结构>
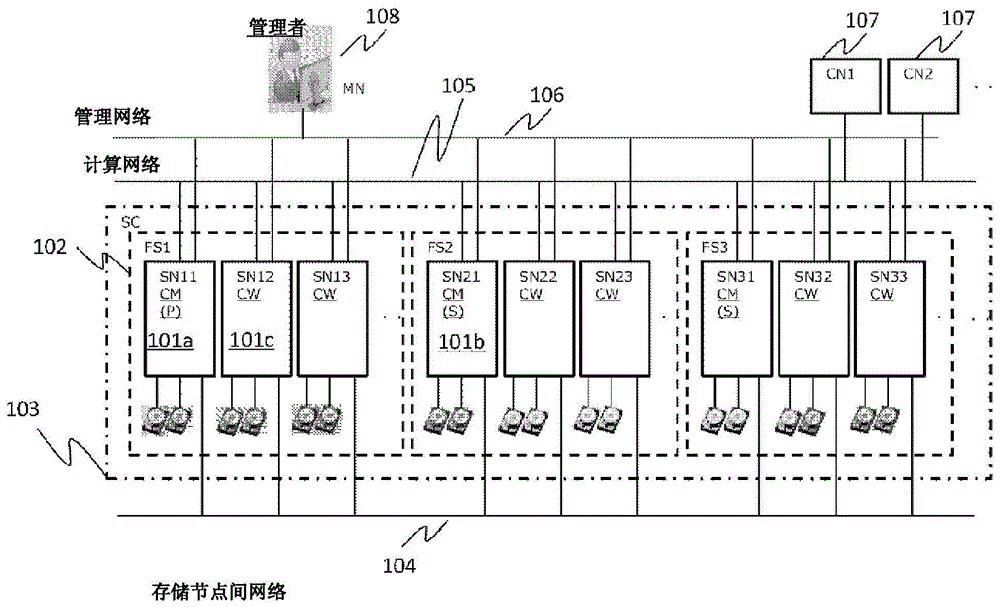
首先,对于本发明的一个实施方式的多存储节点系统进行说明。
图1是一个实施方式的系统结构图。
多个存储节点(sn)101a、101b、101c具有保存数据的驱动器,经由存储节点间网络104彼此连接。
一个以上的计算节点(cn)107运行应用程序,经由计算网络105与多个存储节点101连接。多个存储节点101从计算节点107接收io请求,在驱动器中保存数据或者读取数据并对计算节点发送。
多个存储节点101与管理多个存储节点101的管理节点(mn)108经由管理网络106连接。
多个存储节点101构成存储集群(sc)103,存储集群103相当于多存储节点系统,将共享电源系统或网络交换机的存储节点的组即故障集102构成为子集。
故障集在存储集群103中能够构成2个以上,本实施例中设想为3个程度。各故障集中,存储节点能够由1个以上构成。本实施例中,设想为最大16个程度。另外,各节点101中搭载的驱动器的数量是2个以上,本实施例中,设想为最大26个程度。这些个数的数量不限于举例示出的,可以在不脱离本发明的主旨的范围内设想为适当的数量。
多个存储节点101包括管理存储集群、存在于存储集群中的一个集群主(首要)(cm(p))101a、作为集群主(首要)的待机系统的集群主(次要)(cm(s))101b、除此以外的集群工作节点(cw)101c。
图2是表示一个实施方式的存储节点的硬件结构图的一例的图。
存储节点101相当于图1的存储节点101a、1011b等,对来自服务器等计算机的i/o请求进行处理,进行在驱动器119中保存数据、或者从驱动器119读取数据并对计算节点107发送的处理。驱动器119由nvme驱动器119a、sas驱动器119b、sata驱动器119c等各种驱动器构成。
存储节点101具有用于与存储节点间网络104、计算网络105、管理网络106连接的网络接口203、一个以上的中央处理部(cpu)201、存储器202、将它们连接的总线205。存储器202由sram、dram等易失性存储器构成。
在存储器202中,保存用于由多个存储节点构成集群的集群控制程序111、进行存储节点的控制的节点控制程序112、对来自计算节点107的io请求进行处理并控制对驱动器119的数据写入且从驱动器119的数据读取的io控制活动程序113。另外,存储器202保存其它存储节点是集群主(首要)、与该节点的io控制活动程序对应的待机系统的io控制待机程序114,以及图4所示的各种表的sodb(scaleoutdatabase)112。
cpu201通过执行存储器202中保存的程序来作为控制部实现各种功能。
在存储器202中,在图示的程序之外,也保存快照和远程功能等的各种程序,实现存储节点的功能。另外,存储器202中,具有作为暂时性地存储关于io请求的数据的缓存存储器的缓存区域。
集群控制程序111、节点控制程序112、io控制活动程序113、io控制待机程序114也可以是被保存在驱动器119中,由cpu201读取至存储器202并运行的方式。有时将执行该各种程序而实现的功能称为集群控制部111、节点控制部112、io控制部活动113、io控制部待机114。
网络接口nwi/f303为了方便而图示为一个接口,但可以用不同的2个以上接口构成与用于连接其他存储节点的存储节点间网络104、用于连接计算节点107的计算网络105、用于连接管理节点107的管理网络106的连接用的接口。
存储节点的结构在集群主(首要)(cm(p))101a、集群主(次要)(cm(s))101b、和除此以外的集群工作节点(cw)101c中是共通的。
图3是表示一个实施方式的用cpu201实现的控制部与存储节点之间的卷的定位的一例的系统框图。
存储节点101a是作为集群首要主节点(主节点)工作的节点,存储节点101b是作为集群次要主节点工作的节点,存储节点101c是作为集群工作节点工作的节点。各存储节点101保存了如图2所示的程序,但图3中仅图示在动作的说明上必要的程序进行说明。另外,图3为了使说明简化,而示出了各故障集中、存储节点由1台构成的例子,但1个故障集中有时包括多台存储节点。
各存储节点以驱动器119的一定大小的存储区域为管理单位,管理多个物理块(physicalchunk)118a、118b。主节点101a从各存储节点将多个物理块118、118b分配至逻辑块lc1(logicalchunk,lc)117a。主节点的控制部构成包括多个逻辑块lc117的存储池120。
主节点的控制部201通过将存储池120的包括逻辑块117a的多个逻辑块分配至dp池116,而构成dp池。控制部201对于计算节点107,提供一个以上dp卷115作为存储区域。控制部201对于dp卷115从dp池116进行存储区域的分配。
图3示意性地示出了驱动器119与物理块118的关系、物理块118与逻辑块117的关系、逻辑块117与存储池120的关系、逻辑块、存储池120、dp池116的关系、dp池116与dp卷115的关系。
另外,图3中,主节点101a的io控制活动113和集群次要主节点101b的io控制待机对于某一dp卷构成当前使用系统和待机系统。另一方面,示出了对于其他dp卷,存储节点101b是io控制活动,对于存储节点101c是io控制待机的关系。
<各种表>
图4是表示本实施例的各种管理表的一例的图。
在sodb110中,保存存储节点管理表401、驱动器管理表402、物理块管理表403、逻辑块管理表404、已分配物理块(节点)管理表405、空闲物理块(节点)管理表406、已分配物理块(故障集)管理表407、空闲物理块(故障集)管理表408等各种表。
在图5中示出存储节点管理表401的详情,在图6中示出驱动器管理表402的详情,在图7中示出物理块管理表403的详情,在图8中示出逻辑块管理表404的详情,在图9中示出已分配物理块(节点)管理表405的详情,在图10中示出空闲物理块(节点)管理表406的详情,在图11中示出已分配物理块(故障集)管理表407的详情,在图12中示出空闲物理块(故障集)管理表408的详情。
另外,为了便于说明而使用表这一表达进行说明,但不限于表,也能够用指针或关系数据库等其他数据结构实现。
图5是表示本实施例的存储节点管理表的一例的图。
存储节点管理表401被保存在sodb110中。存储节点管理表401的节点编号501是用于在存储集群内唯一确定各存储节点的识别符。故障集编号是用于在存储集群内唯一确定各故障集的识别符。例如,示出了用节点编号501“1”确定的存储节点(以下有时也简称为节点)是属于故障集编号502“1”的节点。同样地,示出了节点编号501“3”的节点属于故障集编号“2”。
图6是表示本实施例的驱动器管理表的一例的图。
驱动器管理表402被保存在sodb110中。驱动器编号601是用于在存储集群内唯一确定各驱动器119的识别符。节点编号602是用于在存储集群内唯一确定各存储节点的识别符,相当于图5的节点编号501。物理块数(合计值)603表示用驱动器编号确定的驱动器中包括的物理块的数量。物理块数(已分配)604表示用驱动器编号确定的驱动器中包括的物理块中的、已对逻辑块分配的已分配的块数。物理块数(空闲)605表示用驱动器编号确定的驱动器中包括的物理块中的、尚未对逻辑块分配的块数。介质类型606是表示用驱动器编号确定的驱动器的种类的信息。
例如,示出了驱动器编号601“2”属于节点编号602“1”,物理块数(合计值)603是“20”,物理块数(已分配)604是“5”,物理块数(空闲)605是“15”,介质类型606是“sas”。介质类型用作在数据重建时、用于将与数据保存在的介质同一类型的介质选择为重建的数据的保存位置的信息。
图7是表示本实施例的物理块管理表的一例的图。
物理块管理表403被保存在sodb110中。物理块管理表403的物理块编号701是用于在存储集群102内唯一确定各物理块118的识别符。驱动器编号702是用于在存储集群102内唯一确定各驱动器119的识别符,相当于图6的驱动器编号601。驱动器内偏移量703表示用各物理块编号确定的物理块的、用驱动器编号确定的驱动器内的地址。状态704表示用物理块编号701确定的物理块是否已对逻辑设备分配。另外,状态704在对逻辑设备分配之外,有时也保存表示处于预约状态(reserved)或表示该物理块处于不可使用的状态的(blockade)的状态的信息。
例如,示出了物理块编号701“2”的物理块属于驱动器编号702“1”的驱动器,从“0x10000”的位置开始,处于已分配的“已分配(allocated)”状态。
图8是表示本实施例的逻辑块管理表的一例的图。
逻辑块管理表404被保存在sodb110中。逻辑块管理表404的逻辑块编号801是用于在存储集群102内唯一确定各逻辑块117的识别符。dp池编号802是用于识别逻辑块分配至的dp池的识别符。物理块编号(正本)803是识别对逻辑块分配的物理块中的、作为正本的物理块的识别符,物理块编号(镜像)804是识别对逻辑块分配的物理块中的、作为镜像的物理块的识别符。
例如,示出了逻辑块编号801“2”被分配至dp池编号802“1”,分别在物理块编号803“2”中保存正本数据、在物理块编号804“6”中保存镜像数据。
图8示出了对于一个逻辑块、分配正本和镜像这两个物理块的基于镜像的冗余化,但在应用erasure-coding的冗余化的情况下,需要与数据块对应地示出多个物理块编号作为物理块编号803的列,另外也需要表示保存奇偶校验的物理块的物理块编号的列。
图9是表示本实施例的已分配物理块(节点)管理表的一例的图。物理块(节点)管理表405被保存在sodb110中。物理块(节点)管理表405的节点编号901是用于在存储集群102内唯一确定各存储节点101的识别符,相当于图5的节点编号501、图6的节点编号602。配对目标故障集编号902是确定与各节点构成配对的节点所属的故障集的识别符。故障集是以在电源故障时、冗余数据也能够存在于多存储节点系统中的方式将节点分组而成的,将在电源故障时等保存冗余数据的故障集作为配对目标故障集编号902保存。
已分配块数(合计值)903表示该节点中已分配的物理块数的合计值。已分配块数(ssd)904表示该节点的ssd驱动器中已分配的物理块数。已分配块数(sas)905表示该节点的sas驱动器中已分配的物理块数。已分配块数(sata)906表示该节点的sata驱动器中已分配的物理块数。从而,已分配块数(合计值)903的值是将各驱动器的已分配块数904、905、906合计得到的值。
例如,示出了节点编号901“1”的配对目标故障集编号902是“2”和“3”,在配对目标故障集编号902是“2”的情况下,已分配块数(合计值)903是“20”,已分配块数(ssd)904是“10”,已分配块数(sas)905是“5”,已分配块数(sata)906是“5”。
图10是表示本实施例的空闲物理块(节点)管理表的一例的图。
空闲物理块(节点)管理表406被保存在sodb110中。空闲物理块(节点)管理表406的节点编号1001是用于在存储集群102内唯一确定各存储节点101的识别符,相当于图5的节点编号501、图6的节点编号602、图9的节点编号901。
空闲物理块数(合计值)1002表示用节点编号确定的节点中包括的物理块中的、尚未分配的物理块数的合计值。空闲物理块数(ssd)1003表示该节点的ssd驱动器中尚未用于分配的物理块数。空闲物理块数(sas)1004表示该节点的sas驱动器中尚未用于分配的物理块数。空闲物理块数(sata)1005表示该节点的sata驱动器中尚未用于分配的物理块数。从而,空闲物理块数(合计值)1002的值是将各驱动器的空闲物理块数1003、1004、1005合计得到的值。
例如,示出了节点编号1001“1”中,空闲物理块数(合计值)1002是“30”,空闲物理块数(ssd)1003是“10”,空闲物理块数(sas)1004是“10”,空闲物理块数(sata)1005是“10”。
图11是表示本实施例的已分配物理块(故障集)管理表的一例的图。已分配物理块(故障集)管理表407被保存在sodb110中。
已分配物理块(故障集)管理表407的故障集编号1101是用于在存储集群102内唯一确定各故障集102的识别符。配对目标故障集编号1102是确定与用故障集编号1101表示的故障集成为配对、保存冗余数据的故障集的识别符。
已分配块数(合计值)1103表示故障集内已分配的物理块数的合计值。已分配块数(ssd)1104表示该故障集内的ssd驱动器中已分配的物理块数。已分配块数(sas)1105表示该故障集内的sas驱动器中已分配的物理块数。已分配块数(sata)1106表示该故障集内的sata驱动器中已分配的物理块数。从而,已分配块数(合计值)1103的值是将各驱动器的已分配块数1104、1105、1106合计得到的值。
例如,示出了故障集编号1101“1”的配对目标故障集编号1102是“2”和“3”。配对目标故障集编号1102是“2”的情况下,已分配块数(合计值)1103是“20”,已分配块数(ssd)1104是“10”,已分配块数(sas)1105是“5”,已分配块数(sata)1106是“5”。
图12是表示本实施例的空闲物理块(故障集)管理表的一例的图。空闲物理块(故障集)管理表408被保存在sodb110中。
空闲物理块(故障集)管理表408的故障集编号1201是用于在存储集群102内唯一确定各故障集102的识别符,相当于图11的故障集编号1101。
空闲物理块数(合计值)1202表示用故障集编号1201确定的故障集中包括的物理块中的、尚未分配的物理块数的合计值。空闲物理块数(ssd)1203表示该故障集内的ssd驱动器中尚未用于分配的物理块数。空闲物理块数(sas)1204表示该故障集内的sas驱动器中尚未用于分配的物理块数。空闲物理块数(sata)1205表示该故障集内的sata驱动器中尚未用于分配的物理块数。从而,空闲物理块数(合计值)1202的值是将各驱动器的空闲物理块数1203、1204、1205合计得到的值。
例如,示出了故障集编号1201“1”中,空闲物理块数(合计值)1202是“30”,空闲物理块数(ssd)1203是“10”,空闲物理块数(sas)1204是“10”,空闲物理块数(sata)1205是“10”。
用图5至图12所示的节点编号等编号表示的识别符不限于数字,也可以是符号或字符等其他信息。
此处,使用图19,用sodb110中保存的各种管理表说明图3中说明的物理块118、逻辑块117、dp池116的分配的处理。
图19是表示由控制部201执行的、对dp池的物理块分配处理的流程图。在步骤s1901中,检测dp池116的容量的耗尽。例如,已对dp卷115分配了dp池的容量的80%的情况下,判断为耗尽状态。但是,80%只是例子,也可以设定除此以外的值。
在步骤s1902中更新sodb。具体而言,将物理块管理表403的未分配(nonallocated)的物理块的状态704从未分配(nonallocated)变更为保留(reserved)。
在步骤s1903中,节点控制部112在sodb110的逻辑块管理表404中,将状态被变更为保留(reserved)的物理块分配至逻辑块。将被分配了物理块的逻辑块分配至dp池。
在步骤s1904中,节点控制部接收到进程的完成通知时,将sodb更新。也可以由集群控制部111进行sodb的管理和更新。该情况下,从节点控制部接收了进程的完成通知的集群控制部111将sodb更新。
例如,使驱动器管理表402的物理块数(已分配)604的数量增加,使物理块数(空闲)605的值减少。空闲物理块(节点)管理表406、已分配物理块(节点)管理表405、空闲物理块(故障集)管理表408、已分配物理块(故障集)管理表407也同样地更新。
即,本实施例中,物理块的分配指的是对于对应的逻辑块的分配、或对dp池的分配、或其双方。
<控制流程>
图13是表示本实施例的集群控制部的处理流程的流程图。存储集群的结构中发生了变更的情况下,sodb110中的各种管理表被更新(步骤s1301)。
sodb110中的各种管理表被更新的情况中,包括因dp池使用量增加或重新平衡而新分配物理块的情况、检测出故障集的故障、节点的故障、设备的故障、物理块变得不可用的情况、从各存储节点减设驱动器、或从存储集群减设存储节点的情况。
控制部201(例如用集群控制程序实现的功能)以进行图14所示的通知条件(1)的确认(步骤s1302),进行图15所示的通知条件(2)的确认(步骤s1303),进行图16所示的通知条件(3)的确认(步骤s1303),满足各通知条件的情况下通知警报(1)-(3)的方式进行控制。虽然详细流程中并未示出,但集群控制部111在因管理者的应对(物理空闲容量的增强)等而不再满足条件的情况下,通知警报解除。另外,虽然详细流程中并未示出,但考虑驱动器的tier、即ssd、sas、sata等驱动器种类的情况下,在条件中追加“介质类型一致”。
图14是表示本实施例的通知条件(1)的确认处理流程的流程图。图14所示的处理由集群控制部111执行,是在各驱动器的已分配物理容量超过同一节点内的其他驱动器的空闲物理容量的合计值的情况下、满足通知条件(1)、用于发出警报(1)的处理。
sodb110中各种管理信息被更新时,开始处理。在步骤s1401中,设节点编号n=1,对于步骤s1401至步骤1408进行相当于存储节点数的循环处理。
在步骤s1402中,从空闲物理块(节点)管理表406取得节点编号n的空闲物理块数(合计值)a。即,节点编号是1的情况下,从物理块数(合计值)1002取得物理块数(合计值)a“30”。
在步骤s1403中,从驱动器管理表402取得与节点编号n连接的驱动器编号d。即,根据驱动器管理表402的节点编号“1”,取得驱动器编号“1,2,3”。进行使步骤s1403至步骤s1407的处理与驱动器相应地反复的循环处理。
在步骤s1404中,从驱动器管理表402取得驱动器d的物理块数(已分配)b、物理块数(空闲)c。例如,对步骤s1403中取得的驱动器编号“1,2,3”中的驱动器编号“1”的处理进行说明,对于驱动器编号“1”的物理块数(已分配)b从驱动器管理表402的列604取得“5”,对于物理块数(空闲)c从驱动器管理表402的列605取得“5”。
在步骤s1405中,判断a-c<b。即,判断从步骤s1402中取得的节点编号n的空闲物理块数(合计值)a中减去步骤s1404中取得的驱动器的物理块数(空闲)c得到的值是否小于步骤s1404中取得的驱动器的物理块数(已分配)。这表示判断各驱动器的已分配物理容量是否超过同一节点内的其他驱动器的空闲物理容量的合计值。即,判断属于多个存储节点中的特定的存储节点的特定的驱动器的已分配物理块的数量(物理容量)是否超过该特定的存储节点的其他驱动器的尚未对逻辑块分配的空闲物理块的数量(物理容量)的合计值。因为物理块是规定的大小,所以物理块的数量能够置换为物理容量。
步骤s1405的判断的结果如果是否定的则前进至步骤s1407,如果是肯定的则前进至步骤s1406。在步骤s1406中,发出警报(1)。关于警报(1)的内容,在图17a中详细说明,但如果简单说明,则包括表示对于系统的管理者、因为该节点的物理块不足、所以提示追加驱动器的警告的内容。
该驱动器的处理结束时,选择下一个驱动器,反复从步骤s1403起的处理。此处,驱动器编号“1,2,3”中、驱动器编号“1”的处理结束时,选择驱动器编号“2”,反复进行直到驱动器编号“3”的处理。对于全部驱动器处理结束时,前进至步骤s1408,选择下一个节点,反复从步骤s1401起的处理。
图15是表示本实施例的通知条件(2)的确认处理流程的流程图。图15所示的处理由集群控制部111执行,是在各节点的已分配物理容量超过其他节点的空闲物理容量的合计值的情况下、满足通知条件(2)、用于发出警报(2)的处理。
在步骤s1501中,设节点编号n=1,开始与存储节点数相应地反复步骤s1501至步骤s1512的处理的循环。
在步骤s1502中,从存储节点管理表401取得节点编号n的故障集编号f。例如,节点编号n=1的情况下,从存储节点管理表401的故障集编号502取得故障集编号“1”。
在步骤s1503中,从已分配物理块(节点)管理表405取得节点编号n的已分配物理块数(合计值)的合计值a。节点编号n=1的情况下,从物理块(节点)管理表405的已分配物理块数(合计值)903取得。
在步骤s1504中,从空闲物理块(节点)管理表406取得节点编号n的空闲物理块数(合计值)的合计值b。节点编号n=1的情况下,从空闲物理块(节点)管理表406的空闲物理块数(合计值)1002取得作为空闲物理块数(合计值)的合计值b。
在步骤s1505中,从空闲物理块(故障集)管理表408取得故障集编号f的空闲物理块数(合计值)的合计值c。例如,故障集编号是“1”的情况下,从空闲物理块(故障集)管理表408的空闲物理块合计值1202取得空闲物理块数(合计值)的合计值c。
在步骤s1506中,根据步骤s1503中取得的a、步骤s1504中取得的b、和步骤s1505中取得的c判断是否满足a>c-b的条件。这是判断属于某一故障集的节点的已分配物理容量是否超过其他节点的空闲物理容量的合计值。即,判断属于某一故障集的第一存储节点的已分配物理块的数量是否超过属于某一故障集、第一存储节点以外的存储节点中的、尚未分配给逻辑块的物理块的数量(空闲物理容量)的合计值。因为物理块是规定的大小,所以物理块的数量能够置换为物理容量。
对于步骤s1506的条件是否定的情况下,前进至步骤s1512,选择下一个节点并反复从步骤s1501起的处理。对于步骤s1506的条件是肯定的情况下,前进至步骤s1507。
在步骤s1507中,从已分配物理块(节点)管理表405取得节点编号n的配对目标故障集编号p和已分配块数合计值d。配对目标故障集编号p从已分配物理块(节点)管理表405的配对目标故障集编号902取得,已分配块数合计值d从已分配块数合计值903取得。开始相当于对应的配对目标故障集的循环(步骤s1507至步骤s1511)。
在步骤s1508中,从空闲物理块(故障集)管理表408取得故障集编号f、p以外的故障集编号的空闲物理块数(合计值)的合计值e。
在步骤s1509中,根据步骤s1507中取得的已分配块数合计值d、和步骤s1508中取得的故障集编号的空闲物理块数(合计值)的合计值e,判断是否满足d>e的条件。即,在步骤s1509中,判断配对目标故障集的各节点的已分配物理容量是否超过了其他节点的空闲物理容量的合计值。因为物理块是规定的大小,所以物理块的数量能够置换为物理容量。此处,其他节点中,除去了属于处理中的故障集和配对目标故障集的节点。
不满足步骤s1509的条件的情况下,前进至步骤s1511,对于节点编号n的下一个配对目标故障集,反复从步骤s1507起的处理。
满足步骤s1509的条件的情况下,前进至步骤s1510,进行警报(2)的发出。警报(2)的详情用图17b说明,但如果简单说明,则对于系统的管理者,通知因为该故障集的物理块不足所以提示增加物理容量的警告、和提示在与故障集组成配对的故障集以外的故障集中追加物理容量的警告。另外,物理容量的追加通过追加驱动器或节点而进行。进而,也通知应当追加的物理容量的最低容量。
接着,在步骤s1511中,对于步骤s1507中取得的、节点编号n的配对目标故障集编号p,处理结束时,选择下一个故障集(步骤s1508),反复循环处理。
节点编号n的全部配对目标故障集编号的处理结束时,在步骤s1512中选择下一个节点,反复循环处理。
图16是表示本实施例的通知条件(3)的确认处理流程的流程图。图16所示的处理由集群控制部111执行,是各故障集的已分配物理容量超过其他故障集的空闲物理容量的合计值的情况下满足通知条件(3)、用于发出警报(3)的处理。此处,其他故障集中,除去了处理中的故障集和配对目标故障集双方。
在步骤s1601中,选择故障集编号f=1,开始直到步骤s1607的相当于故障集数的循环处理。
在步骤s1602中,从已分配物理块(故障集)管理表407取得故障集编号f的配对目标故障集编号p和已分配块数合计值a。配对目标故障集编号p使用已分配物理块(故障集)管理表407的配对目标故障集编号1102的值,已分配块数合计值a使用已分配块数合计值1103的值。与对应的配对目标故障集相应地执行步骤s1602至步骤s1606的循环。
在步骤s1603中,从空闲物理块(故障集)管理表408取得故障集编号f、p以外的故障集编号的空闲物理块数(合计值)的合计值b。b的值使用空闲物理块(故障集)管理表408的1202的值。
在步骤s1604中,判断a>b。即,判断步骤s1602中取得的已分配块数合计值a是否比步骤s1603中取得的故障集编号f、p以外的故障集编号的空闲物理块数(合计值)的合计值b更多。该处理判断故障集的已分配物理容量是否超过了除数据的配对目标故障集以外的其他故障集的空闲物理容量的合计值。即,判断属于第二故障集的存储节点的已分配物理块的数量是否超过属于第二故障集和与第二故障集配对的故障集以外的故障集的存储节点下属的、尚未分配给逻辑块的物理块的数量(空闲物理容量)的合计值。此处,因为物理块是规定的大小,所以物理块的数量能够置换为物理容量。
步骤s1604的判断是否定的情况下,前进至步骤s1606,使配对目标故障集编号p增加,选择下一个配对目标故障集编号,执行循环处理。
步骤s1604的判断是肯定的情况下,前进至步骤s1605,进行警报(3)的发出。警报(3)的详情用图17c说明,但如果简单说明,则包括表示对于系统的管理者、因为其他故障集的物理块不足、所以提示追加驱动器的警告的内容。
图17a是表示本实施例的基于通知条件(1)的警报(1)的一例的图。
在各驱动器的已分配物理容量超过了同一节点内的其他驱动器的空闲物理容量的合计值的情况即满足通知条件(1)的情况下,对系统管理者通知如图17a所示的警报(1)。
警报(1)的内容是:
“·请在节点编号n的节点中增加设置物理容量的合计值在”b-(a-c)”以上的驱动器。
·节点编号n的节点中存在因驱动器的减少设置/检测到故障征兆而重建数据时i/o性能与通常时相比劣化的可能性。”
即,能够通知对于进行了通知条件的判断的节点追加物理容量、以及节点中保存的数据的重建所需的必要最低限度的物理容量。另外,实际追加的物理容量可以是比必要最低限度的物理容量更多的值,例如可以追加1.5倍程度的物理容量。追加比必要最低限度的物理容量多何种程度的物理容量,由管理者适当设定。
图17a中,也对管理者通知在节点编号n中执行的数据的重建对i/o性能的影响。
图17b是表示本实施例的基于通知条件(2)的警报(2)的一例的图。
在属于某一故障集的第一存储节点的已分配物理块的数量超过属于某一故障集、第一存储节点以外的存储节点中的、尚未分配给逻辑块的物理块的数量(空闲物理容量)的合计值的情况下,配对目标故障集的各节点的已分配物理容量超过了其他节点的空闲物理容量的合计值的情况即满足通知条件(2)的情况下,对系统管理者通知如图17b所示的警报(2)。
警报(2)的内容是:
“·请在故障集编号f的故障集中增加设置物理容量的合计值在“a-(c-b)”以上的节点或驱动器。
·或者请在故障集编号f、p以外的故障集编号的故障集中增加设置物理容量的合计值在”d-e”以上的节点或驱动器。
·节点编号n的节点闭塞的情况下,存在节点的数据不能重建的可能性。”
即,能够通知对于进行了通知条件的判断的故障集追加物理容量、和追加节点中保存的数据的重建所需的必要最低限度的物理容量。也通知该物理容量的追加能够通过追加具有必要的物理容量的节点或驱动器而达成。
另外,通知对于与故障集组成配对的故障集以外的故障集追加物理容量和重建所需的物理容量。也通知该物理容量的追加能够通过追加具有必要的物理容量的节点或驱动器而达成。
另外,实际追加的物理容量可以是比必要最低限度的物理容量更多的值,例如可以追加1.5倍程度的物理容量。追加比必要最低限度的物理容量多何种程度的物理容量,由管理者适当设定。
图17b中,也一同通知在节点编号n的节点闭塞的情况下、存在节点的数据的重建不能进行的可能性的警告。
图17c是表示本实施例的基于通知条件(3)的警报(3)的一例的图。
在各节点的已分配物理容量超过了除属于数据的配对目标故障集的节点以外的其他节点的空闲物理容量的合计值的情况即满足通知条件(3)的情况下,对系统管理者通知如图17c所示的警报(3)。
警报(3)的内容是:
“·请在故障集编号f、p以外的故障集编号的故障集中增设物理容量的合计值在“a-b”以上的节点或驱动器。
·故障集编号f的故障集闭塞的情况下,存在故障集的数据不能重建的可能性。”
即,能够通知对于进行了通知条件的判断的故障集、作为配对的故障集以外的故障集追加物理容量、和追加故障集中保存的数据的重建所需的必要最低限度的物理容量。也通知该物理容量的追加能够通过追加具有必要的物理容量的节点或驱动器而达成。
另外,实际追加的物理容量可以是比必要最低限度的物理容量更多的值,例如可以追加1.5倍程度的物理容量。追加比必要最低限度的物理容量多何种程度的物理容量,由管理者适当设定。
如上所述,通过警报(1)至(3),系统的管理者能够得知在用于重建的物理容量不足的情况下、在何处追加多少物理容量即可。
即,通过警报(1)至(3),系统的管理者能够得知是(i)在同一节点中追加物理容量、还是(ii)在属于同一故障集的节点中追加物理容量、或者在同一故障集中追加节点、还是(iii)在属于不保存冗余数据的其他故障集的节点中追加物理容量、或者追加节点这样应当追加物理容量的场所。
另外,能够得知应当在上述应当追加物理容量的场所中追加多少物理容量。
图18是表示本实施例的节点内优先分配处理的流程图。
在步骤s1801中,接受驱动器d的数据的重建请求。
在步骤s1802中,从物理块管理表403取得从驱动器编号d中分割出的物理块编号p。步骤s1803至步骤s1810是用于与对应的物理块编号相应地反复处理的循环。
在步骤s1803中,从物理块管理表403取得物理块编号p的状态s。
在步骤s1804中,步骤s1803中取得的物理块编号的状态是分配(allocated)的情况下,前进至步骤s1805,是闭塞(blockade)的情况下前进至步骤s1812。
在步骤s1805中,从驱动器管理表402取得与驱动器编号d同一节点编号的节点上连接的、并且物理块数(空闲)在1以上的驱动器编号e。
在步骤s1805中驱动器编号e的取得成功时,前进至步骤s1806,取得失败时前进至步骤s1811。
在步骤s1806中,从物理块管理表403取得从驱动器编号e的驱动器分割出的、并且状态是“未分配(non_allocated)”的物理块编号q。
在步骤s1807中,将物理块编号p的物理块作为重建源数据指示节点内的数据的重建。
在步骤s1805中驱动器编号e的取得失败的情况下,在步骤s1811中,将物理块编号p的物理块作为重建源数据指示节点间的数据的重建。
在步骤s1804中判断为闭塞(blockade),前进至步骤s1812时,从逻辑块管理表取得与物理块编号p组成配对的物理块编号q。
接着,在步骤s1813中,将物理块编号q的物理块作为重建源数据指示节点间的数据的重建。
在步骤s1808中,接受数据的重建的完成通知时,为了反映数据重建后的内容而将各种表信息更新(步骤s1810)。
通过图18的处理,因为优先地进行将驱动器d中保存的数据的重建数据保存在同一节点的驱动器中,所以能够防止节点之间发生的用于数据重建的数据传输,达成数据重建的高速化和系统的io性能劣化。
以上,根据本实施方式,在多存储节点系统中,即使在驱动器或节点故障、驱动器或节点减少设置时,也能够按驱动器、节点、故障集单位管理为了确保数据冗余性而进行数据重建用的容量管理。
另外,系统管理者能够得知重建后的数据的保存位置的物理容量的不足,简单地得知在何处追加多少物理容量即可。
附图标记说明
101:存储节点(sn)
101a:集群主(首要)(主节点)
101b:集群主(次要)
101c:集群工作节点
102:故障集(fs)
103:存储集群(sc)
104:存储节点间网络
105:计算网络
106:管理网络
107:计算节点(cn)
108:管理节点(mn)
110:sodb
111:集群控制程序
112:节点控制程序
113:io控制活动程序
114:io控制待机程序
115:dp卷
116:dp池
117:逻辑块
118:物理块
119:驱动器
301:cpu
302:存储器。
- 还没有人留言评论。精彩留言会获得点赞!