一种交通事故影响因素空间效应分析方法及其应用与流程
本发明涉及交通安全技术领域,尤其涉及宏观交通事故预测,特别是涉及一种考虑空间溢出效应的交通事故影响因素空间效应分析方法及其在交通事故影响因素识别中的应用和其在交通事故发生频次预测中的应用。
背景技术:
随着社会经济的飞速发展和机动化水平的不断提高,道路交通事故已经成为最广泛、最严重的社会危害。在世界范围内,交通事故的发生给人们生命和财产安全带来了极大的危害。传统交通事故分析的常见流程是发现事故黑点,分析事故原因,实施安全改善,进行安全评价四个阶段。但方法属于事故发生后的“亡羊补牢”,发生的交通事故已然造成了较大的人员伤亡和财产损失,难以促进长期性的、全局性的交通安全水平提升。因此,主动性的交通安全规划理论被提出并成为当前国际道路交通安全业界和学界的研究热点。
交通安全规划是指在传统的交通规划过程中,从宏观角度出发,将交通安全作为首要的规划目标和评价指标,并且将交通安全规划贯穿于整个交通系统方案的设计、建设、评价以及后期的交通运营管理全过程中,在不同阶段实现主动预防,而非被迫改善,从而实现对交通事故的标本兼治。要制定科学合理的交通安全规划,十分有必要明确影响交通事故发生的关键因素,并对其空间效应进行精确的量化研究,
传统的交通事故预测大多从微观角度出发,基于多元线性回归、神经网络等理论方法进行预测分析。同时,已有研究大多只考虑研究区域内各类宏观和微观因素对交通事故发生的直接影响,忽视邻接区域各类影响因素对研究区域事故发生、研究区域事故发生与邻近区域事故发生之间的交互影响。而在实际中,相邻地理空间对象之间往往存在扩散或溢出等空间相互作用。
以酒驾交通事故为例,交警在某区域开展酒驾专项治理或在重点路段设点盘查,会在一定时期内对本区域驾驶员产生威慑,同时还会产生辐射效应,对邻近区域驾驶员产生威慑,从而导致一定范围内酒驾事故率的降低。更为可能的是,酒驾事故并非一定发生于酒精购买与消费区域本地,驾驶员可能在某区域购买或消费后,驾车行驶一定距离到达其他区域后发生交通事故。因此,十分有必要全面考虑研究区域与相邻区域的综合影响,融入空间效应特征进行探索研究,建立的交通事故影响因素空间效应评价的量化分析模型,推动宏观交通安全规划的理论研究和技术应用。
公开号为cn201810352052.3的中国发明专利申请公开了“基于无偏非齐次灰色模型和马氏模型的交通事故预测方法”、公开号为cn201810320886.6的中国发明专利申请公开了“一种基于pca和bp神经网络的交通事故预测方法”,这些方法主要提出了不考虑交通事故影响因素空间效应的交通事故预测方法,并未涉及到邻接区域内影响因素对目标区域事故发生的定量影响。
公开号为cn201310041718.0的中国发明专利申请公开了“一种基于地理加权回归的县级交通事故预测方法”,该方法重点研究了交通事故的空间异质性,并未涉及交通事故空间自相关性的研究,并未涉及到邻接区域内影响因素对目标区域事故发生的定量影响。
技术实现要素:
本发明的目的是针对现有技术中存在以下问题:传统交通事故影响因素分析对交通事故的空间自相关性研究不足,对事故发生影响因素的空间溢出效应考虑不足,无法定量描述邻接区域内影响因素对目标区域事故发生的影响,而提供一种区域交通事故预测方法,在对交通事故的空间自相关性进行分析基础上,除了可以描述目标区域内各类因素对事故发生的影响外,还可以定量描述邻接区域内影响因素对目标区域事故发生的空间溢出效应以及总的空间效应特征。
为实现本发明的目的所采用的技术方案是:
一种交通事故影响因素空间效应分析方法,包括以下步骤:
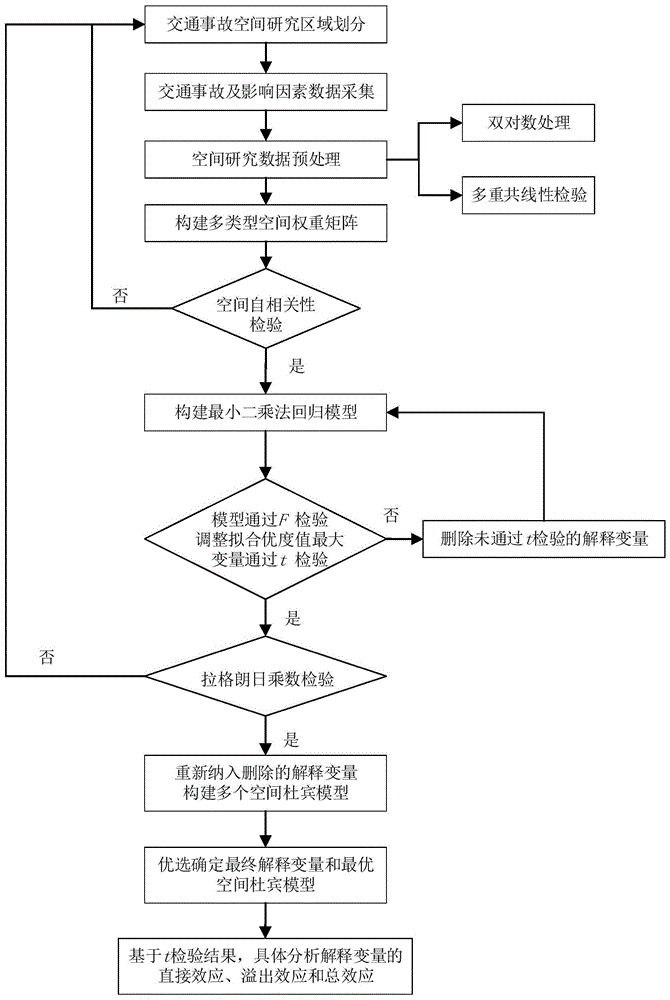
步骤1,划分交通事故的空间研究区域,采集影响交通事故的影响因素数据,获得建模所需解释变量和被解释变量;
步骤2,通过双对数处理和多重共线性检验删除不合理的被解释变量;
步骤3,构建不同类型的表征研究区域之间关联关系的空间权重矩阵;
步骤4,对步骤3中的不同类型的空间权重矩阵进行空间自相关性检验,若最为显著则进入下一步,否则重新进入步骤1;
步骤5,以步骤2中所选取的解释变量和被解释变量构建ols模型,通过f检验调整拟合优度值最大,删除未通过t检验的解释变量,重构ols模型;
步骤6,基于lm检验对步骤5得到的ols模型残差进行检验,若不存在空间滞后项和空间误差项,则进入步骤7,否则重新进入步骤1;
步骤7,重新纳入步骤5中删除的解释变量,通过替代或组合方式构建多个空间杜宾模型,选取logl值最大的模型为最优空间杜宾模型,作为交通事故影响因素空间效应的分析模型。
一种交通事故影响因素空间效应分析方法,包括以下步骤:
步骤1,划分交通事故的空间研究区域,采集所有空间研究区域内的影响因素数据,基于地理统计分析软件进行数据空间化,并基于所述空间研究区域分别计算交通事故发生频次和所述影响因素的密度,初步获得建模所需解释变量和被解释变量;
步骤2,对解释变量和被解释变量均进行对数变换,即采用对数-对数模型进行分析,同时对解释变量进行多重共线性验证,基于方差膨胀因子值大小,剔除不合理的解释变量;
步骤3,基于所述空间研究区域,构建不同类型的表征研究区域之间关联关系的空间权重矩阵;
步骤4,基于空间自相关性指标,对步骤3中不同类型的空间权重矩阵进行验证,具体的:对空间研究区域内的交通事故发生频次对数进行空间自相关性检验,如果检验通过则确定空间自相关性最为显著的空间权重矩阵,然后进入下一步,否则回到步骤1重新划分空间研究区域;
步骤5,以步骤2中所选取的解释变量和被解释变量,建立最小二乘法回归(ordinaryleastsquare,ols)模型,以调整拟合优度adjustr2最大为建模目标,并确保最终所构建模型通过f检验,所选解释变量通过t检验,对未通过t检验的解释变量先暂时删除后重新构建ols模型,直至满足要求;
步骤6,基于ols模型残差,运用拉格朗日乘数(lagrangemultiplier,lm)检验所述步骤5中的ols模型中是否存在空间滞后项和空间误差项,若不存在则进入下一步,否则回到步骤1重新划分空间研究区域;
步骤7,基于步骤4中空间自相关性最为显著的空间权重矩阵,如式(1)所示构建空间杜宾模型(spatialdurbinmodel,sdm),同时,将步骤5中删除的解释变量通过替代或组合方式重新纳入构建多个sdm模型,基于对数似然函数值(loglikelihood,logl)进行综合比较,选取logl值最大的模型为最优空间杜宾模型;并选取该最优空间杜宾模型作为交通事故影响因素空间效应的分析模型;
y=ρwy+θwx+xβ+αln+ε(1)
其中,y是被解释变量矩阵,x是解释变量矩阵,wy是被解释变量之间存在的内生交互效应,wx是解释变量之间存在的外生交互效应。ρ为空间自回归系数,其大小反映空间扩散或空间溢出的程度,如果ρ显著,表明被解释变量之间存在一定的空间依赖。θ是外生交互效应的系数,θ越显著表明解释变量存在的空间交互作用越强。β表示回归系数,ε是随机误差项常量,通常认为是独立分布的。ln是单位向量,它与被估计的常数项参数α有关。其中wy和wx均使用步骤4中空间自相关性最为显著的空间权重矩阵。ρ,θ,β,α都是最优空间杜宾模型计算得到的系数。
在上述技术方案中,所述步骤1中空间研究区域根据区、县区、街道、交通小区、邮编区域或人口普查区划分,优选为交通小区。
在上述技术方案中,所述步骤1中影响因素包括交通事故地点、人口统计特征、社会经济属性、兴趣点数据(包括兴趣点地址和兴趣点类型等)、交通基础设施和运行管理数据相关影响因素中的一种或多种,其中涉及地理位置的影响因素(比如交通事故地点、兴趣点地址等)的经纬度坐标作为影响因素数据。
在上述技术方案中,所述步骤1中的被解释变量为交通事故发生频次,优选为酒驾交通事故发生频次,解释变量为人口密度、零售店密度,宾馆酒店密度、休闲娱乐密度、餐饮服务密度、公司企业密度、住宅小区密度、交叉口密度和路网密度中的一种或多种。
在上述技术方案中,所述步骤2中采用百分比描述解释变量对被解释变量的影响。
在上述技术方案中,所述步骤2中,对方差膨胀因子(varianceinflationfactor,vif)小于10的解释变量予以保留,对大于10的解释变量予以剔除。
在上述技术方案中,所述步骤3中的空间自相关性指标为莫兰指数。
在上述技术方案中,所述步骤3中的空间权重矩阵为“车式”邻接、“后式”邻接和/或反距离型空间权重矩阵,其中反距离为欧式反距离或曼哈顿反距离。
在上述技术方案中,所述步骤6中的拉格朗日乘数包括lm(lag)、lm(error)和稳健的拉格朗日乘数检验robustlm(lag)和robustlm(error)。
在上述技术方案中,所述步骤6中,如果检验结果均在90%显著性水平上显著,则视为模型中不存在空间滞后项和空间误差项,否则视为模型中存在空间滞后项和空间误差项。
本发明的另一方面,还包括所述交通事故影响因素空间效应分析方法在交通事故关键影响因素识别中的应用,将待预测空间研究区域的影响因素数据作为解释变量输入所述分析方法所得最优空间杜宾模型,计算直接效应、溢出效益和总体效应下的模型系数和t统计值,直接效应中t统计值变量在90%显著性水平上显著的解释变量作为本预测空间区域的关键解释变量即关键影响因素,溢出效应中t统计值变量在90%显著性水平上显著的解释变量作为邻接区域的关键影响因素,总体效应中t统计值变量在90%显著性水平上显著的解释变量作为响交通事故发生总体效应的关键影响因素,由此实现对待预测空间区域交通事故发生的关键影响因素进行识别。
本发明的另一方面,还包括所述交通事故影响因素空间效应分析方法在交通事故发生频次预测中的应用,先通过步骤7得到的最优杜宾模型识别直接效应、溢出效益和总体效应下的关键影响因素,将从待预测区域获取的所述关键影响因素数据代入交通事故发生频次预测模型中进行预测。
在上述技术方案中,所述交通事故发生频次预测模型可为但不限于线性回归模型、神经网络模型或杜宾模型。
与现有技术相比,本发明的有益效果是:
1.本发明提出的区域交通事故预测方法首先划分空间研究区域范围,采集交通事故数据和相关影响因素数据,其次对数据进行双对数处理和多重共线性检验,继而基于构建的多种类型空间权重矩阵进行交通事故空间自相关性检验,然后对ols模型残差进行lm检验,在确定具有空间效应基础上构建多个sdm模型进行综合比选,最后确定了最终解释变量和最优空间杜宾模型。
2.本发明充分考虑了交通事故的空间自相关性特征,克服了以往事故影响因素分析研究忽视邻接区域对研究区域事故发生影响而导致的交通事故预测精度不高问题,从而能够有效明确影响事故发生的解释变量,定量描述影响因素的空间直接效应、溢出效应和总体效应。
3.本发明有助于明确交通事故影响因素的空间影响,极大促进了主动交通安全规划基础理论和技术实践的发展,同时对交通事故管理和预防提供了有力技术支持和决策支持,对促进我国交通事故“零伤亡”愿景的早日实现,实现人民生活的和谐稳定具有重要意义。
附图说明
图1所示为本发明的方法流程图。
具体实施方式
以下结合具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例1
以下结合技术方案和附图,对所示优选实施例作进一步详述。
如图1所示,一种交通事故影响因素空间效应分析方法,包括步骤:
第一步,城市空间研究区域的划分可按照不同划分原则进行,具体有市区、县区、街道、交通小区、邮编区域、人口普查区等多种划分方法。本文优选实施例以交通小区作为研究空间区域划分,提取某市3356起酒驾交通事故作为研究对象,基于该市统计年鉴和全国乡镇第六次人口普查数据提取了人口数据作为人口统计特征,基于高德api接口采集兴趣点数据,提取兴趣点和事故地点经纬度坐标,基于地理统计分析软件arcgis进行数据空间化,同时提取交叉口密度和路网密度作为交通基础设施数据。基于该市国民经济和社会发展统计公报采集社会经济属性数据(类似gdp等数据),基于交通流量检测设备采集运行管理数据,最终提取区域内酒驾交通事故发生频次作为被解释变量,提取人口密度、零售店密度,宾馆酒店密度、休闲娱乐密度、餐饮服务密度、公司企业密度和住宅小区密度、交叉口密度和路网密度作为解释变量。
第二步,为使数据更符合正态分布并消除模型异方差性或偏态性,避免模型对极端值过于敏感,同时缩小变量取值范围,采用百分比描述解释变量对被解释变量的影响,对解释变量和被解释变量进行对数变换,即采用对数-对数模型开展后续的研究分析。
当解释变量之间存在线性关系时,会产生多重共线性问题,导致对被解释变量单独影响力的估计偏差。因此,基于统计分析软件spss对解释变量进行多重共线性验证结果如表1所示,计算发现所有解释变量的vif均小于10,均予以保留。
表1解释变量多重共线性结果表
第三步,空间权重矩阵表达了空间单元间的相互依赖关系,是空间相关性度量和验证的重要基础数据。建立空间单元需恰当的量化空间位置关系与空间属性关系。通常通过定义二元对称矩阵来表达n个空间单元之间的邻接关系,构成n×n阶空间权重矩阵w如下所示:
其中:w——空间权重矩阵;
wij——空间单元i与空间单元j的量化空间关系;
基于交通小区空间区域划分方式,分别构建基于“车式”邻接、“后式”邻接和反距离型的空间权重矩阵。其中,“车式”邻接是指如果两个空间区域之间存在公共的边,就定义wij为“邻接”,否则为“不邻接”;“后式”邻接是指如果两个空间区域存在公共的点或者边,就定义wij为“邻接”,否则为“不邻接”。如式(3)所示,反距离空间权重是指用两个空间单元之间距离的倒数作为衡量区域间相邻关系的方式。
其中,dij是指两个空间区域间质心的距离,可以是欧式距离或曼哈顿距离。
第四步,莫兰指数moran’si是较为常用的全局空间自相关性指标,其定义如式(4)所示。全局莫兰指数值若为正,z值均大于1.96,p值小于0.05,则在95%置信度下具有显著正向空间自相关性。
其中,n是研究区域内地域单元总数,wij是空间权重矩阵的元素值,xi是空间区域单元i的x变量值,xj是空间区域单元j的x变量值。
基于地理统计分析软件arcgis计算莫兰相关指数,结果如表2所示。在交通小区空间区域下,四种不同空间权重下全局莫兰指数值均为正,z值均远大于1.96,p值均为0.001,在95%置信度下具有显著正向空间自相关性。在“车式”邻接空间权重下,莫兰指数值最大,表明空间相关性最为明显的权重矩阵为“车式”空间权重矩阵。
表2空间相关性检验结果
第五步,基于统计分析软件spss建立ols模型,发现回归模型最大调整拟合优度值adjustr2为0.308,p值小于0.05,通过了f检验,表示模型具有统计学意义。如表3所示为回归模型的系数估计结果,解释变量休闲娱乐密度和餐饮服务密度t检验不显著、交叉口密度t检验在90%置信度下显著,其他变量t检验均在95%置信度下显著。因此,暂时去掉休闲娱乐密度和餐饮服务密度进入下一步分析。
表3ols模型系数估计值
第六步,基于空间地理分析软件geoda对ols模型残差进行拉格朗日乘数检验。检验结果如表4所示,lm检验均在95%显著性水平上显著,robustlm(error)在95%显著性水平上显著,robustlm(lag)在90%显著性水平上显著。
表4lm检验结果
第七步,基于空间自相关性最为显著的空间权重矩阵,基于matlab软件构建原始sdm模型。基于sdm模型可以估计解释变量的直接效应和间接效应(又称溢出效应),从而解释空间计量模型的边际效应。直接效应是指目标交通小区影响因素对该小区酒驾事故发生的影响,溢出效应是指相邻小区影响因素对本小区酒驾事故或者本小区的影响因素对相邻小区酒驾事故发生的影响。
谨慎起见,为避免在回归方程系数检验时,直接剔除未能通过t检验的休闲娱乐密度和餐饮服务密度变量所带来的误差,并且考虑到休闲娱乐密度、餐饮服务密度与零售店密度具有一定相关性,分别用休闲娱乐密度、餐饮服务密度替换前述模型中的零售店密度进行sdm建模,同时基于主成分分析法((principalcomponentanalysis,pca)提取休闲娱乐密度、餐饮服务密度与零售店密度三个变量的主成分进行sdm建模。基于对数似然函数值(loglikelihood,logl)对上述四个sdm模型和ols模型进行比较,结果如表5所示。结果表明,sdm模型拟合效果均优于ols模型,原始sdm模型中logl值最大,从而确定了最优空间杜宾模型。
表5基于logl的不同sdm模型评价结果
实施例2
如实施例1所述的一种交通事故影响因素空间效应分析方法在交通事故关键影响因素识别中的应用,将待预测空间研究区域的影响因素数据输入实施例1所述分析方法所得最优空间杜宾模型,对待预测空间区域交通事故发生的关键影响因素进行识别,从而针对不同城市或同一城市不同地区提出不同的交通事故预测、管理和控制策略。
基于matlab软件计算最优sdm模型中解释变量的直接效应、溢出效应和总效应如表6所示。基于模型t检验结果(即t统计值),影响本区域酒驾事故发生的关键解释变量(直接效应中t统计值变量在90%显著性水平上显著)为表6中除人口密度外的所有解释变量,影响邻接区域酒驾事故发生的关键解释变量(溢出效应中t统计值变量在90%显著性水平上显著)为零售店密度、宾馆酒店密度、交叉口密度和路网密度,影响酒驾事故发生总体效应的最终解释(总体效应中t统计值变量在90%显著性水平上显著)变量为表6中除人口密度外的所有解释变量。以上得到的本区域、邻接区域和总体效应中的最终解释变量即分别对应本区域、邻接区域和总体效应中的关键影响因素。
从解释变量的直接效应分析,除人口密度外所有解释变量的直接效应均显著。零售店密度、交叉口密度和路网密度增加,会导致本区域酒驾事故发生可能性增加,而宾馆酒店密度、公司企业密度和住宅小区密度增多会导致酒驾事故的降低。从溢出效应来看,零售店密度、路网密度变量溢出效应为正,说明这些变量的增加会导致周边区域酒驾事故的增加。宾馆酒店密度和交叉口密度变量溢出效应为负,说明这些变量的增加会导致周边区域酒驾事故的降低。最终,零售店密度和路网密度总体效应显著且为正,宾馆酒店密度、公司企业密度、住宅小区密度、交叉口密度总体效应显著且为负,是影响该市酒驾事故发生的重要空间因素。
表6最优sdm模型的空间效应
注:*表示变量在90%显著性水平上显著;**表示变量在95%显著性水平上显著
实施例3
在基于传统的线性回归模型、神经网络模型等线性和非线性模型进行交通事故发生频次预测时,除了考虑预测目标区域的影响因素外,还应该将邻接区域影响因素对事故发生的影响都纳入预测模型中,从而有效提高模型预测精度。
比如利用线性回归模型或神经网络模型进行酒驾交通事故发生频次预测时,采集某空间区域多个交通小区数据;将实施例2得到的本区域和邻接区域的关键影响因素均作为解释变量进行训练学习建模,确定模型解释变量的系数,将待预测区域的本区域和邻接区域的关键影响因素数据代入模型,得到待预测区域酒驾交通事故发生频次。
或者利用杜宾模型进行预测,将实施例2得到的本区域和邻近区域的关键影响因素均作为解释变量,将实施例2所得直接效应系数和溢出效应系数作为解释变量系数进行建模,将待预测区域的本区域和邻近区域的关键影响因素数据代入模型,得到待预测区域酒驾交通事故发生频次。
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!