一种基于深度学习的通用隐写方法与流程
本发明属于信息隐藏技术领域,具体涉及一种基于深度学习的通用隐写方法。
背景技术:
信息隐藏作为信息安全传递的重要方式,将机密信息伪装为不引人注意的普通信息而达到隐蔽传输或隐蔽存储的目的,对国家安全与信息安全具有重要意义。信息隐藏这一概念包含多个方面,主要包括隐蔽信道、隐写术、匿名通信和版权表示等方面。早期的信息隐藏方法大多能保证bmp、jpeg、gif等格式载体图像的视觉质量,但对载体数据统计特性考虑不多。随后,学者提出了一些可维持某些统计特征无异常的信息隐藏方法,但安全性仍不令人满意。例如:lsb匹配方法避免了统计不对称性和直方图异常,但检测者可根据直方图fourier域质心位置的变化、最低两层位平面的统计特征变化或解压图像的噪声特征异常来察觉秘密信息;model-based方法可维持原始分布模型,但与理想模型的过分地吻合反而会引起怀疑。检测者还可进一步估计秘密信息嵌入量,且准确性不断提高。可同时检测多种隐藏方法的隐写分析被称为通用分析或盲检测。通用分析不再依据少量敏感统计特性判断载体是否含秘,而是从大量原始样本与含密载体样本中提取特征向量再训练分类器,然后区分原始载体与含密载体。早期用于隐写分析的特征有图像质量测度、dct与马尔科夫特征、高阶统计特征等,分类方法包括神经网络、支持向量机、几何模型等。
理想的信息隐藏应使含密载体在整个载体空间的分布与原始载体分布完全一致。两种分布之间的差异程度可用kl散度(kldivergence)度量,该指标也可用于衡量信息隐藏系统的安全性。然而,载体空间异常巨大,研究者往往在简化数据统计模型后再讨论安全性,如假定载体采样数据服从独立同分布或将载体数据空间投射为统计特征空间。与kldivergence相比,最大均值差异(maximummeandiscrepancy,mmd)更易于计算,且在空间比较稳定,也可作为安全性指标;研究者们还利用fisher信息量给出了安全嵌入容量并对其进行优化。当隐藏者知晓隐写分析方法时,可采取相应措施对抗隐写分析,使隐写分析失效,如文献[3]利用凸集投影法获得失真小且高阶特征无异常的含密图像,对抗文献[2]中的隐写分析方法;文献[4]将图像数据分为两部分:一部分用于隐藏秘密信息,另一部分用于校正隐藏引起的统计特征变化,可抵抗文献[1]中利用274维特征的隐写分析方法。然而,信息隐藏必然引起载体数据变化,如选用其他统计特征进行分析,仍可察觉秘密信息。文献[4]讨论了统计特征完备性对隐写分析的帮助。
综上,目前信息隐藏技术但仍存在一些问题。主要问题如下:(1)、在信息隐藏发展的同时,针对隐蔽信息的检测技术,亦称隐写分析(steganalysis),也得到了迅速发展。该技术根据信息嵌入引起的载体数据统计异常来判断秘密信息是否存在,已对信息隐藏的效果及安全性构成严重威胁;(2)、目前主流信息隐藏方法在修改载体数据时经验性地设定损失指标,再利用“编码方法最小化总损失”的思想,鲜有突破性成果;(3)、相对信息隐藏的广泛应用而言,信息隐藏的理论研究显得滞后,不能为技术的应用发展提供强有力的支撑。
技术实现要素:
为了克服现有技术中存在的不足,本发明提供一种能够极大地提高信息传输的安全性和保密性的基于深度学习的通用隐写方法,其还以对消息进行编码,提高消息提取的准确性和可靠性。
为实现上述目的,本发明采用如下技术方案:
一种基于深度学习的通用隐写方法,其特征在于,包括如下步骤:
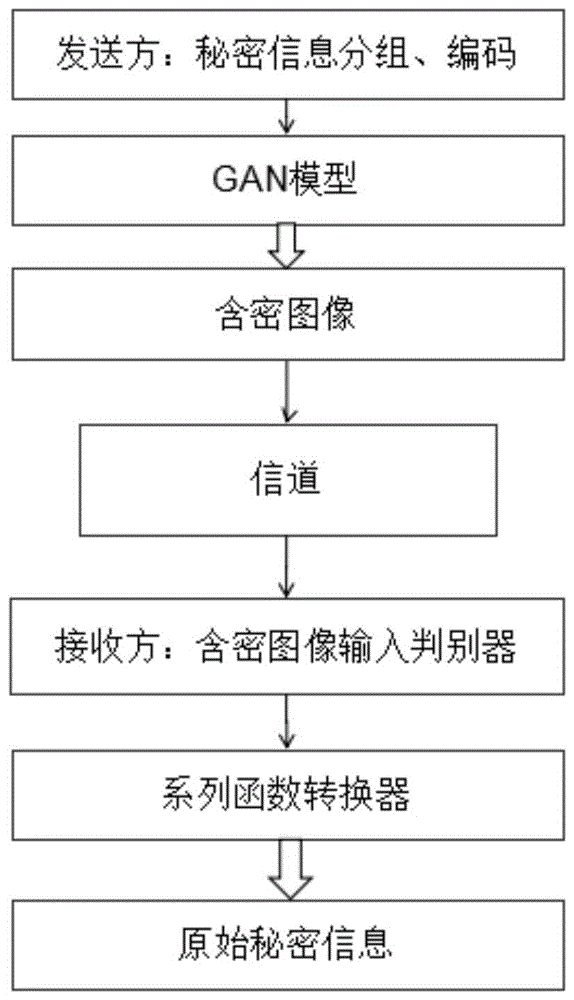
步骤s1、在发送方进行隐藏处理:将待隐藏的秘密信息分成n组信息片段,并对每组信息片段编码得到若干组秘密信息片段,每组秘密信息片段分别对应一个类别标签,采用深度学习模型,以类别标签与随机噪声作为驱动,生成指定类别的伪自然图像,伪自然图像作为隐藏处理后的含密图像输入信道;
步骤s2、在接收方进行提取处理:含密图像由接收方输入到判别器中进行图像真伪鉴别和图像类别判定,然后再将图像类别信息送入函数转换器中进行处理得到秘密信息片段,对秘密信息片段进行译码得到原始秘密信息。
作为优选,所述步骤s1中采用的深度学习模型为gan模型,gan模型对输入数据动态地采样并生成新的样本,gan模型包括生成器和判别器,g(z)表示输入噪声z生成器产生的生成图像。
作为优选,所述步骤s1中需要隐藏处理的秘密信息为文本信息t,隐藏处理包括如下步骤:
步骤s11、对需要隐藏的文本信息t,按照码表字典存在的词或单字进行分词,每m个汉字或词组为一组,在每组文本信息的头部添加一个序号标记,得到n个文本信息片段;
步骤s12、通过查码表字典,将每个文本信息片段编码成4(m+1)个对应的类别标签,构成一组新的秘密信息片段,记为k;
步骤s13、把k输入到事先训练好的gan模型中,调用gan模型中生成器已训练好的权重值,生成器通过k、z的联合输入,生成含密图像g(k,z)。
作为优选,所述步骤s11中每组文本信息头部添加的序号标记的位数相同。
作为优选,所述步骤s2中的提取处理包括如下步骤:
步骤s21、接收方接收到含密图像g(k,z)后,将g(k,z)输入到事先训练好的gan模型的判别器中,判别器输出图像的真伪和图像类别的似然对数l;
步骤s22、使用softmax函数将图像类别的似然对数l转变成图像属于各类别的概率;
步骤s23、使用用argmax函数输出概率最大的类别,提取出类别标签,得到秘密信息k;
步骤s24、提取出接收图像对应的秘密信息片段头部的序号标记;
步骤s25、将秘密信息片段按序号标记排序,通过查码表字典,依次将秘密信息片段译码成对应的文本信息片段,按照顺序连接所有的文本信息片段,得到接收到的含密图像中隐藏的文本信息t。
与现有技术相比,本发明的有益效果如下:
(1)、本发明利用深度学习生成模型直接构造或合成含密载体,充分利用了深度学习的优势,在生成式隐写中,生成的图像可以直接作为含密载体,解决了传统隐写术中的含密图像并不能够完全、准确地提取出消息的技术问题;
(2)、本发明通过深度学习模型可以对消息进行编码,提高消息提取的准确性,本发明基于深度学习的载体合成隐写方法与传统的修改方法相比,能够大大提高实际嵌入容量,嵌入容量是评价隐写系统实用性的一个重要指标,本发明能够达到传统容量的数倍;
(3)、gan框架可以训练任何生成网络,gan生成采样的运行时间更短,gan一次产生一个样本,gan模型没有对潜在变量(生成器的输入值)的大小进行限制;
(4)、本发明将秘密信息和系统变量作为驱动来生成含密图像样本,将其在公共网络等信道上传输,接收方利用判别器和一系列函数转化器从含密图像中提取,得到原始秘密信息,从而实现信息隐藏。
(5)、深度学习与机器学习技术会利用快速高效的计算机运算资源进行高阶特征提取或分析,并且训练结果会越来越好,这对基于嵌入的隐写术提出了重大挑战;
(6)、本发明的方法由于没有对图像本身作任何改变,所以能从根本上抵抗各类隐写分析方法的检测、安全性高,能够解决传统信息隐藏技术通过修改信息载体嵌入秘密信息,难以抵御基于统计特征的隐写分析检测的技术难点。
附图说明
图1为本发明的基于深度学习的通用隐写方法的流程图;
图2为本发明采用的gan模型的结构示意图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
本发明的基于深度学习的通用隐写方法,针对传统信息隐藏技术上存在的问题,将深度学习与信息隐藏相结合,通过引入新技术解决传统信息隐藏存在的问题。深度学习也叫无监督特征学习(unsupervisedfeaturelearning),即可以无需人为设计特征提取,特征从数据中学习而来。深度学习实质上是多层表示学习(representationlearning)方法的非线性组合,表示学习是指从数据中学习表示(或特征),以便在分类和预测时提取数据中有用信息。深度学习从原始数据开始将每层表示(或特征)逐层转换为更高层更抽象的表示,从而发现高维数据中错综复杂的结构。利用深度学习模型具有的模拟复杂表示的能力,来达到自动学习有效特征表达的目的。同时利用深度学习的端到端学习过程,把特征构造和分类器训练在一个结构中同步完成。
深度学习还包括卷积神经网络(convolutionalneuralnetworks,cnn)、深度神经网络(deepneuralnetwork,dnn)、循环神经网络(recurrentneuralnetwork,rnn)和生成式对抗网络(generativeadversarialnetworks,gan)。
本发明采用gan模型为深度学习模型,如图1所示gan模型即生成对抗网络,其特点是由噪声驱动来生成图像样本,目前已实现输入噪声后输出随机的伪自然图像,本发明把噪声替换为秘密信息,实现以秘密信息为驱动来生成含密载体的无载体信息隐藏。
目前,gan主要应用在无监督学习上,其对输入数据动态地采样并生成新的样本,gan通过同时训练以下2个神经网络进行学习(设输入分别为真实数据x和随机变量z):
1)、生成模型(g):以噪声z的先验分布pnoise(x)作为输入,生成一个近似于真实数据分布pdata(x)的样本分布pg(z)。
2)、判别模型(d):判别目标是真实数据还是生成样本,如果判别器的输入来自真实数据,标注为1;如果输入样本为g(z),标注为0。
gan的优化过程是一个极小极大博弈问题,在gan的训练过程中解决了以下优化问题:
d(x)代表是真实图像的概率,g(z)是从输入噪声z产生的生成图像。在机器学习中,由于取不同底的对数结果是等比关系,对优化没有影响,所以此处的对数函数不加底,下文同理。
gan模型通过交替训练g与d实现式1)的优化:在每个mini-batch随机梯度优化的迭代过程中,首先对d进行梯度上升,然后对g进行梯度下降。如果用θm表示神经网络m的参数,那么更新规则为:
保持g不变,通过
保持d不变,通过
如图1和图2所示,本发明以隐藏文本信息为例,具体操作步骤如下:
步骤s1:发送方的隐藏处理:
步骤s11、对需要隐藏的文本信息t,根据码表字典存在的词或单字进行分词,每m个汉字或词组为一组,在每组头部添加一个序号标记将文本信息t分成n个文本信息片段,即t={t1,t2,…,tn}。源目录序号标记的目的是使接收方在提取到文本信息片段后能正确地排列组合,更方便还原初始的文本信息t,此外为保证编码的一致性,序号标记可采用相同位数数字编码,如采用4位数字编码;
步骤s12、根据构建好的码表字典,通过查表,将每个文本信息片段编码成4(m+1)个对应的类别标签,构成一个新的秘密信息片段,记为k;
步骤s13、将生成器中的类别标签直接替换成秘密信息k,把k输入到事先训练好的gan模型中,调用生成器己训练好的权重值,生成器通过k、z的联合输入,经过一系列反卷积、正则化等操作生成含密图像g(k,z)进行传递。
步骤s2、接收方的提取处理:
步骤s21、接收方接收到含密图像g(k,z)后,将g(k,z)输入到事先训练好的gan判别器中,经过卷积、正则化等操作,判别器输出图像的真伪和图像类别的似然对数l;
步骤s22、使用softmax函数将图像类别的似然对数l转变成图像属于各类别的概率;
步骤s23、利用argmax函数输出概率最大的类别,提取出类别标签,得到秘密信息k:
步骤s24、由于存在网络延时和其它有意或无意的攻击,接收方接收到的图像顺序可能会与发送方隐藏文本信息片段的图像顺序不同,因此首先提取出接收图像对应的秘密信息k头部的序号标记;
步骤s25、将秘密信息k按序号排序,根据构建好的码表字典,通过查表,依次将秘密信息k译码成对应的文本信息片段,按照顺序连接所有的文本信息片段,得到接收到的含密图像中隐藏的文本信息t,从而实现无载体信息隐藏。
由前述操作步骤可知,本发明以信息隐藏理论、深度神经网络和博弈论等理论作为技术选择、模型建立和性能优化分析的工具,以隐藏效果为验证和性能评估的手段,构建信息隐藏技术的神经网络模型,揭示神经网络超参数与信息隐藏效果的内在规律。
在计算机系统中,图像本质上是以rgb信息保存的,与文本信息相类似,故只需要将图像的rgb信息提取转换为文本信息,即可使用同样方法处理。
[1]sajedih.steganalysisbasedonsteganographypatterndiscovery[j].journalofinformationsecurityandapplications,2016,30:3-14.
[2]chhikararr,singhl.animproveddiscretefireflyandt-testbasedalgorithmforblindimagesteganalysis[c].20156thinternationalconferenceonintelligentsystems,modellingandsimulation.ieee,2015:58-63.
[3]lecuny,bengioy,hintong.deeplearning[j].nature,2015,521(7553):436-444.
[4]bengioy,courvilea,vincentp.acourvilleandpvincent,representationlearning:areviewandnewperspectives[j].ieeetransactionsonpatternanalysisandmachineintelligence,2013,35(8):17981828.
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!