一种基于模糊三向2DFDA的人脸识别分类方法与流程
本发明涉及一种基于模糊三向2dfda的人脸识别分类方法。
背景技术:
在过去的近三十多年时间里,心理学家、神经生理学家以及工程技术人员从各个方面对人脸识别进行了广泛的研究,尤其近年来,关于人脸识别技术的研究非常活跃,各种思想层出不穷,除了人脸拓扑的几何关系和代数特征方法取得了新进展外,其他方法如人工神经网络、小波变换在人脸识别研究中都得到了很广泛的应用,在学术研究领域上存在着重要意义。
国际、国内的众多高校也普遍开展了对人脸识别的研究,发表的有关人脸识别论文的数量不断增多,在人脸识别方面的研究取得了较大的进展,出现了不少人脸识别新方法。比如,华南理工大学硕士学位论文《基于线性特征抽取方法的人脸识别的研究》,作者徐海娟提出了一种利用三向2dfda的方法进行人脸识别,同时从水平、垂直、对角线三个方向对图像协方差进行估计,其优点在于类内协方差矩阵是可逆的,从而不存在小样品问题,且该方法优于当前的线性子空间方法,但其存在分类精度较低、速度较慢的技术问题。
技术实现要素:
针对上述问题,本发明提供一种基于模糊三向2dfda的人脸识别分类方法,用于解决现有基于2dfda学习模型的人脸图像分类中存在的分类精度较低、速度较慢的技术问题。
为实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
一种基于模糊三向2dfda的人脸识别分类方法,包括如下步骤:
步骤a、获取图像并进行人脸检测,当检测到人脸后,对包含有背景的人脸图像进行人脸分割,构建新的待分类标准人脸图像;
步骤b、针对新的待分类标准人脸图像进行下述处理:
b1、计算新的待分类标准人脸图像的模糊隶属度特征矩阵u,u=[uij],且uij必须满足以下的两个条件:
其中,元素uij表示第j个训练样本对于第i类的依赖程度,i=1,2,…c,j=1,2,…n,c表示样本的类别数,n表示训练样本的总数;
b2、进行左乘的2dfda算法对原始图像矩阵进行计算,得到特征矩阵yl:
yl=uijwlta
其中,wl=[w1,w2,......wd],为m×d阶投影矩阵,wi是对应于前d个最大特征徝的m维列向量,i=1,....,d,wlt为wl的转置,a为训练样本,m为样本的行向量,d为最大特征值个数;
b3、进行右乘的2dfda算法对原始图像矩阵进行计算,得到特征矩阵yr:
yr=awruij
其中,wr为d×n阶投影矩阵,n为样本列向量;
b4、对原始图像进行对角线重排,计算出特征矩阵y′r:
y′r=duijw
其中,d记为a重排后的m×n矩阵;w=[w1,w2,......wd],为m×d阶投影矩阵;
b5、将上述矩阵yl、yr和y′r合成一个特征矩阵y=(yl,yr,y′r)t;
步骤c、利用最近邻分类器进行分类,输出人脸图像的分类结果。
优选,步骤a中,具体包括如下步骤:
a1、通过人脸图像的肤色分布统计模型将人脸从背景中分割出来,包括抽取眼睛、眉毛、嘴、头发所在的候选位置:
将人脸图像的r、g、b转换为色度与亮度分开的色彩表达空间:
其中,x、y、z是对r、g、b的一种线性变换,y表示亮度信息,x和y表示色度信息;
a2、从粗到精找到人脸所在区域并进行精确定位:
a21、建立肤色统计模型;
1)、手工将人脸的皮肤区域从每幅图中分割出来;
2)、将皮肤区域中每个像素点的色度值转换成ucs的空间表达(uf,vf)、统计色度为(uf,vf)的像素点数,得到二维色度直方图,其中,uf和vf表示色度;
3)、将二维色度直方图除以直方图中的最大值来归一化色度直方图,使色度为(uf,vf)的像素点数取值在0-1之间,将归一化的色度直方图作为肤色统计模型;
a22、建立不同方向的头部模型:选择具有不同旋转角度人脸的图像,手工分割出图像中人的头部区域,将其分成a×b个子块,计算每个子块中肤色面积占子块面积比例ms,发色面积占子块面积比例mh,其中,a和b分别为常数;
a23、根据建立的肤色统计模型和发色统计模型计算得到输入图像中每一像素点p的肤色相似度scs(p)、发色相似度hcs(p),计算方形单元区域的平均肤色相似度as、发色相似度ah,并进行准确定位,其表示形式如下:
其中,n为以像素点为单位的方形单元的尺寸。
优选,步骤b2具体包括如下步骤:
b21、定义类内协方差矩阵sb为:
其中,l为总类别数,li为第i类样品数,
b22、定义类间协方差矩阵sw为:
其中,m×n阶矩阵
b23、求解最优投影向量wl:
其中,λ为对角矩阵,其对角线元素为
b24、进行左乘的2dfda算法对原始图像矩阵进行计算。
优选,步骤b3具体包括如下步骤:
b31、定义类内协方差矩阵sb为:
其中,l为总类别数,li为第i类样品数,
b32、定义类间协方差矩阵sw为:
其中,m×n阶矩阵
b33、求解最优投影向量wr:
其中,λ为对角矩阵,其对角线元素为
b34、进行右乘的2dfda算法对原始图像矩阵进行计算。
优选,步骤b4具体包括如下步骤:
b41、沿着图像矩阵a的列,从左往右把第i列的元素向上移i-1个位,超出矩阵的元素依次补到对应列的下边,构建矩阵d,此时a的对角线元素置为d的第一行,第二对角线元素置为d的第二行,依此类推;
b42、定义类内协方差矩阵s′b为:
其中,
b43、定义类间协方差矩阵s′w为:
其中,m×n阶矩阵
b44、求解最优投影向量w:
其中,λ为对角矩阵,其对角线元素为
b45、计算出特征矩阵y′r。
优选,步骤c具体包括:
c1、定义d(y1,y2)为:
其中,
c2、若总的特征距离为y1,y2,…,yn,每一幅图像都有类标签ci,对应一个新的测试样本y,如果
c3、根据c1和c2的结果,求解所有人脸图像的最终类别,并输出人脸图像的分类结果。
本发明的有益效果是:
(1)本发明利用模糊三向的2dfda方法建立分类模型和设计优化算法抽取人脸识别特征,一方面,三向的2dfda方法用的是二维图像矩阵,因而不需要把图像转换为向量,该方法从三个方向进行特征提取,能够更多的提取人脸图像特征,且该方法类内协方差矩阵是可逆的,从而不存在小样品问题;另一方面,模糊三向的2dfda算法中采用模糊算法能很好的解决人脸图像由于光照、表情、姿态等变化导致的人脸识别率下降的现象,同时能够解决距离比较远的数据样本点之间的联系较弱或者邻域之间的数据样本点交叠不够的时候识别率下降的现象。模糊三向的2dfda算法中采用三向的2dfda算法能够很好的解决不同人脸之间在高维空间存在结构相似的问题,同时直接利用图像矩阵进行二维投影抽取特征,不需要事先将图像矩阵转化为图像向量。模糊算法和三向的2dfda结合起来具有识别率高的优点。
(2)本发明利用人脸图像的肤色统计模型联合人脸的肤色统计模型、发色统计模型以及不同方向的头部模型,用模糊模式匹配的方法进行准确定位,将人脸从背景中分割出来,定位更精确。
(3)本发明利用最近邻分类器进行分类,可有效提高人脸图像分类精度,促进人脸图像的稀疏特点的进一步挖掘。
(4)本发明解决现有基于2dfda学习模型的人脸图像分类中存在的分类精度较低、速度较慢的技术问题,可用于国家公共安全,社会安全、信息安全、金融安全以及人机交互等等领域,具有良好的应用前景。
附图说明
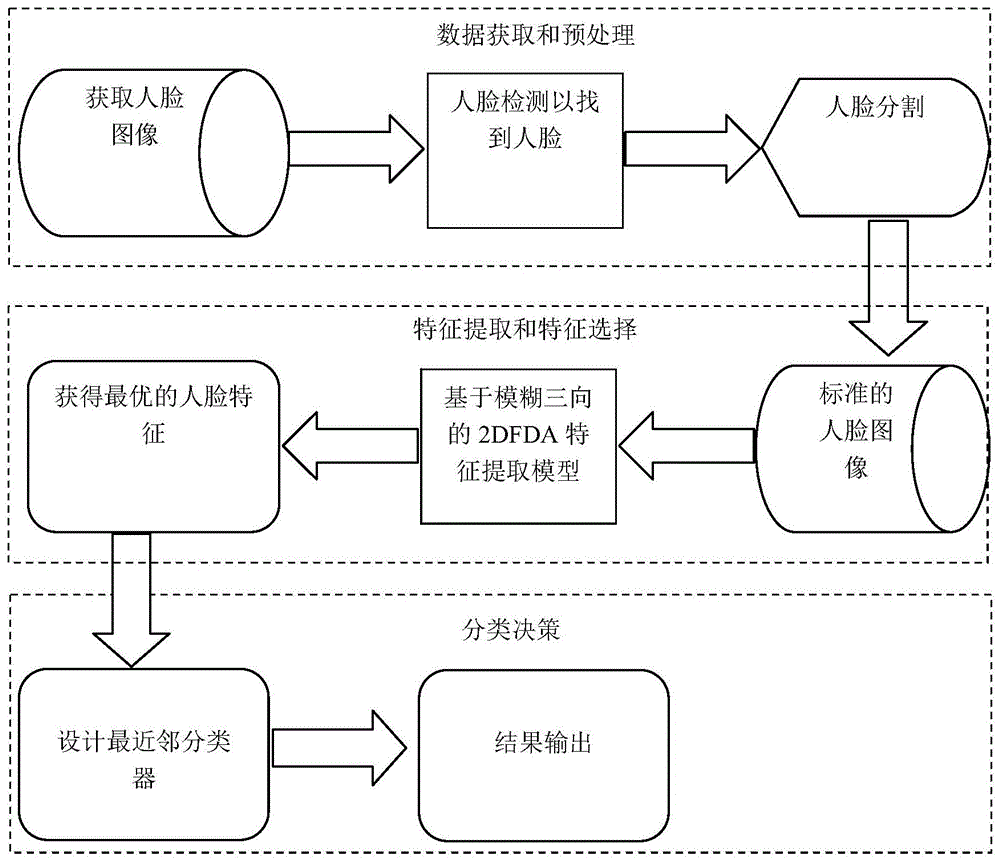
图1是本发明一种基于模糊三向2dfda的人脸识别分类方法示意图;
图2是本发明复杂背景下的人脸实时图像进行分割流程示意图;
图3是本发明基于模糊三向2dfda进行人脸识别方法分类的流程图;
图4是orl人脸库中一个人的十张图;
图5是yale人脸图像库中一个人的11幅图像;
图6是ar人脸图像库中一个子类的20幅图像;
图7是feret人脸库中的部分人脸图像。
具体实施方式
下面结合附图和具体的实施例对本发明技术方案作进一步的详细描述,以使本领域的技术人员可以更好的理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
如图1-3所示,一种基于模糊三向2dfda的人脸识别分类方法,其特征在于,包括如下步骤:
步骤a、获取图像并进行人脸检测,当检测到人脸后,对包含有复杂背景的人脸图像进行人脸分割,构建新的待分类标准人脸图像,具体的:
a1、通过人脸图像的肤色分布统计模型将人脸从背景中分割出来,包括抽取眼睛、眉毛、嘴、头发所在的候选位置,将人脸从背景中分割出来具体为利用肤色在色度空间的聚类性,需要把颜色表达中的色度信息与亮度信息分开,将r、g、b转换为色度与亮度分开的色彩表达空间可达到这个目的。
将人脸图像的r、g、b转换为色度与亮度分开的色彩表达空间:
其中,x、y、z是对r、g、b的一种线性变换,y表示亮度信息,x和y表示色度信息;
a2、从粗到精找到人脸所在区域,在准确定位过程中联合人脸的肤色统计模型、发色统计模型以及不同方向的头部模型,用模糊模式匹配的方法进行准确定位,具体的:
a21、建立肤色统计模型,具体的:
1)、手工将人脸的皮肤区域从每幅图中分割出来;
2)、将皮肤区域中每个像素点的色度值转换成ucs的空间表达(uf,vf)、统计色度为(uf,vf)的像素点数,得到二维色度直方图,其中,uf和vf表示色度;
3)、将得到的二维色度直方图除以直方图中的最大值来归一化色度直方图,使色度为(uf,vf)的像素点数取值在0-1之间。归一化直方图中每个值表达了(uf,vf)色度在多大程度上与肤色相似,即肤色相似度csc(p)。取1时,即为100%肤色。除肤色以外的其它颜色虽在(uf,vf)的二维取值空间内,但其统计值很小,接近0。将归一化的色度直方图作为肤色统计模型。
a22、建立不同方向的头部模型:选择具有不同旋转角度人脸的图像,手工分割出图像中人的头部区域,将其分成a×b(a,b分别为常数)个子块,比如,将其分成10×12个子块,计算每个子块中肤色面积占子块面积比例ms,发色面积占子块面积比例mh。一般可通过5种不同方向的头部模型用来检测不同旋转角度的人脸。
a23、根据建立的肤色统计模型和发色统计模型计算得到输入图像中每一像素点p的肤色相似度scs(p)、发色相似度hcs(p),计算方形单元区域的平均肤色相似度as、发色相似度ah,并进行准确定位,其表示形式如下:
其中,n为以像素点为单位的方形单元的尺寸。
步骤b、针对新的待分类标准人脸图像进行下述处理,利用模糊三向的2dfda方法建立分类模型和设计优化算法抽取人脸识别特征,具体的:
b1、计算新的待分类标准人脸图像的模糊隶属度(fuzzysets)特征矩阵u,u=[uij],且uij必须满足以下的两个条件:
其中,元素uij表示第j个训练样本对于第i类的依赖程度,i=1,2,…c,j=1,2,…n,c表示样本的类别数,n表示训练样本的总数;
优选,uij的计算方法包括如下步骤;
b11、计算训练数据样本集中任意两个数据样本点之间的欧氏距离,构建一个n×n的距离矩阵;
b12、将得到的n×n距离矩阵的对角线上的元素置为无穷大,并将距离矩阵的每一列或者每一行按照距离值从小到大排列,找到每一列或者每一行k个最近邻数据样本点,以及和这k个最近邻数据样本点的类别信息;
b13、计算第j个训练样本对于第i类的依赖程度uij:
其中,nij表示第j个样本的k个最近邻数据样本点中属于第i类的数据样本个数,k表示最近邻数据样本数。
b2、进行左乘的2dfda算法对原始图像矩阵进行计算,得到特征矩阵yl:
其中,wl=[w1,w2,......wd],为m×d阶投影矩阵,wi是对应于前d个最大特征徝的m维列向量,i=1,....,d,wlt为wl的转置,a为训练样本,m为样本的行向量,d为最大特征值个数;
b3、进行右乘的2dfda算法对原始图像矩阵进行计算,得到特征矩阵yr:
yr=awruij
其中,wr为d×n阶投影矩阵,n为样本列向量;
优选,步骤b2具体包括如下步骤:
b21、定义类内协方差矩阵sb为:
其中,l为总类别数,li为第i类样品数,m为所有训练样品均值,mi为第i类样品均值;
b22、定义类间协方差矩阵sw为:
其中,m×n阶矩阵
b23、求解最优投影向量wl:
其中,λ为对角矩阵,其对角线元素为
b24、进行左乘的2dfda算法对原始图像矩阵进行计算。
对应的,步骤b3具体包括如下步骤:
b31、定义类内协方差矩阵sb为:
其中,l为总类别数,li为第i类样品数,
b32、定义类间协方差矩阵sw为:
其中,m×n阶矩阵
b33、求解最优投影向量wr:
其中,λ为对角矩阵,其对角线元素为
b34、进行右乘的2dfda算法对原始图像矩阵进行计算。
b4、对原始图像进行对角线重排,计算出特征矩阵y′r:
y′r=duijw
其中,d记为a重排后的m×n矩阵;w=[w1,w2,......wd],为m×d阶投影矩阵。
优选,步骤b4具体包括如下步骤:
b41、沿着图像矩阵a的列,从左往右把第i列的元素向上移i-1个位,超出矩阵的元素依次补到对应列的下边,构建矩阵d,此时a的对角线元素置为d的第一行,第二对角线元素置为d的第二行,依此类推;
b42、定义类内协方差矩阵s′b为:
其中,
b43、定义类间协方差矩阵s′w为:
其中,m×n阶矩阵
b44、求解最优投影向量w:
其中,λ为对角矩阵,其对角线元素为
b45、计算出特征矩阵y′r。
b5、将上述矩阵yl、yr和y′r合成一个特征矩阵y=(yl,yr,y′r)t;
步骤c、经过模糊三向的2dfda方法训练后,利用最近邻分类器进行分类可以提高分类精度,输出人脸图像的分类结果,具体的:
c1、考虑两幅图像x1,x2经模糊三向的2dfda算法降维后的特征矩阵
其中,
c2、若总的特征距离为y1,y2,…,yn,每一幅图像都有类标签ci,对应一个新的测试样本y,如果
c3、根据c1和c2的结果,求解所有人脸图像的最终类别,并输出人脸图像的分类结果。
实验分析:
下面结合常用的人脸数据库进行实验分析并与现有技术进行比较,为了验证模糊三向的2dfda算法在人脸识别中的有效性,分别在orl,yale,ar和feret人脸图像数据库上进行了识别的实验,比较了该算法与2d-pca、2d-fda、b2d-fda、dia2d-lda和t2d-fda算法的分类识别性能,其中所有的算法均采用欧氏距离和最近邻分类器。实验环境:dellpc,cpu:interathlon(tm)64processor,内存:1024m,matlab7.01。
1.在orl人脸数据库上的实验
orl标准人脸库(http://www.uk.research.att.com/facedatabase.html)由40人构成,其中每人由10幅112×92大小的灰度图像组成,在这些图像中有些是拍摄于不同时期的;人的脸部表情、脸部细节、人脸姿态以及人脸的尺度有着不同程度的变化,比如,笑或不笑,眼睛或睁或闭,戴或不戴眼镜;深度旋转和平面旋转可达20°;尺度也有多达10%的变化。在这个实验中,图像被处理成56×46大小的灰度的形式。图4是orl人脸库中一个人的10幅图像。
实验中随即选取每个人的l(l=2,3,4,5)张图像进行训练,剩余10-l图像进行测试,测试结果如表1所示:
表1.在orl人脸库上不同算法的最大识别率结果
2.在yale人脸数据库上的实验
yale标准人脸图像库(http://www.cvc.yale.edu/projects/
yalefaces/yalefaces.html)中包括了15个人的165幅灰度人脸图像。每个人由11幅照片构成,这些照片在不同的表情和光照等条件下拍摄。在这个实验中,图像被处理成50×40维的形式,图5显示yale人脸图像库中一个人的11幅图像。
同时,此实验中也是随机选取l(l=2,3,4,5)幅图像训练,剩余11-l图像进行测试,测试结果如表2所示:
表2.yale在人脸库上不同算法的最大识别率结果
3.在ar人脸数据库上的实验
ar人脸图像库(http://cobweb.ecn.purdue.edu/~aleix/aleix_face_db.html)包含126个人(70位男性,56位女性)的4000多张彩色人脸图像,这些图像由不同光照、不同表情和不同的遮挡情况下的正面人脸图像组成。大部分人的图像是在相隔2周的时间下拍摄的2个像集。每个像集包含13张彩色图像和120个人(65位男性,55位女性)。我们在实验中采用了这120个人的图像中(没戴围巾的)的人脸图像,每人20幅,共计2400幅人脸图像。我们手动裁剪下了这些图像,并归一到50×40维的灰度图像。人脸图像在1)自然表情;2)微笑;3)生气;4)尖叫;5)左边亮;6)右边亮;7)整体亮;8)戴着墨镜;9)戴墨镜且左边亮;10)戴墨镜且右边亮。如图6所示是ar人脸图像库中一个子类的20幅图像,其中,ar人脸图像库中一个子类的20幅图像,前一行和后一行的图像是不同的时期拍摄(相差两个星期)。实验中随机选取l(l=2,3,4,5,6)幅图像训练,剩余20-l图像测试示,测试结果如表3所示:
表3在ar人脸库上不同算法的最大识别率结果
4.在feret人脸数据库上的实验
本次试验采用feret(http://www.frvt.org/feret/default.htm)其中部分的人脸图像,共200人,每人由7幅图像构成,一共1400幅人脸,并且对原始feret库的人脸图像做预处理,只保留相应图像中的人脸部分。处理后的人脸图像归一化为40×40的形式,图7显示了该人脸库中的部分人脸图像,其为feret人脸库一个人的11张图。
在这个实验中,前l(l从2到4)幅图像训练,剩余7-l图像测试。特征抽取后,用最近邻分类器用来分类,测试结果如表4所示:
表4.在feret人脸库上不同算法的最大识别率结果
通过上述实验分析,本发明可有效提高人脸图像分类精度,具有识别率高的优点。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或者等效流程变换,或者直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!