一种人机对话系统的文本分类方法与流程
本发明涉及一种人机对话文本训练方法,具体涉及一种人机对话系统的文本分类方法。
背景技术:
近年来,随着人工智能技术的飞速发展,人机对话系统作为人工智能领域的核心技术之一,在提高人与机器沟通效率的同时,也极大地方便了人们的生活和工作。如何有效的获取用户的说话意图是人机对话的关键技术。
由于自然语言的复杂性和多样性,人机对话系统中往往包含数十甚至上百个领域,利用机器学习方法对如此多的领域进行分类时,分类的准确性和训练分类模型所需的时间都不太理想。
现有的机器学习分类算法,在文本语料不变的情况下,分类的数量与训练分类模型所需的时间是成正相关的,也就是分类数越多,训练分类模型所需要的时间也越长。在人机对话系统中,由于需要用到的领域较多,对大量不同领域的文本语料进行分类时,则需要十几个小时甚至数天时间,对于模型的调试和系统的迭代更新产生了严重的阻碍。
所以,需要对机器学习文本分类方法进行优化,以更好应用于人机对话系统,获得更好的使用效果和更佳的实用性。
技术实现要素:
本发明的目的在于提供一种人机对话系统的文本分类方法,用以解决现有机器学习算法在人机对话领域对文本分类的准确性和实时性不佳的问题。
为实现上述目的,本发明采用如下技术方案:
一种人机对话系统的文本分类方法,所述分类方法包括模型训练和模型预测两部分:
所述模型训练为在包含了数十至数百个不同领域的数据库的人机对话系统中,使用全部数据库训练二分类预测模型ma,把不同领域的数据库平均分成两大类,训练两大类内各个类的预测模型,得到第一大类内各个类的第一类预测模型mb和第二大类内各个类的第二类预测模型mc;
所述模型预测为对用户语音识别后的文本文本使用二分类预测模型ma进行预测,得出预测结果,如果结果属于第一类预测模型mb,则使用第一类预测模型mb进行预测,判断预测结果得分是否大于阈值,若得分大于阈值则使用第一类预测模型mb预测的结果,否则使用第二类预测模型mc进行预测,若结果大于阈值则使用第二类预测模型mc预测的结果,否则取第一类预测模型mb和第二类预测模型mc中得分高的作为预测结果;
所述模型预测为对用户语音识别后的文本文本使用二分类预测模型ma进行预测,得出预测结果,如果结果属于第二类预测模型mc,则使用第二类预测模型mc进行预测,判断预测结果得分是否大于阈值,若得分大于阈值则使用第二类预测模型mc预测的结果,否则使用第一类预测模型mb进行预测,若结果大于阈值则使用第一类预测模型mb预测的结果,否则取第一类预测模型mb和第二类预测模型mc中得分高的作为预测结果。
优选的,上述阈值为经验值,在实际产品中由设计人员以多次试验的办法测试得出。
优选的,上述模型训练中对不同领域的数据库平均分成两大类的过程为:先将数据库依次编号,对编号取中间值,第一个数据库到中间值归为第一类,中间值后至最后一个数据库为第二类。
优选的,上述模型训练中对不同领域的数据库平均分成两大类的过程为:先将数据库依次编号,对编号为偶数的归为第一类,对编号为奇数的归为第二类。
优选的,上述获得二分类预测模型(ma)、第一类预测模型(mb)和第二类预测模型(mc)的训练方法相同。
优选的,上述使用二分类预测模型(ma)、第一类预测模型(mb)和第二类预测模型(mc)的模型预测方法相同
优选的,上述文本分类方法运行于向量机。
一种支持向量机,至少包括存储器、处理器,存储器上存储有计算机程序,处理器在执行所述存储器上的计算机程序时实现上述方法步骤。
本发明具有如下优点:
本发明针对机器学习算法在人机对话领域的文本分类方法进行了优化,实现了对文本高效、准确的分类,有效的提升了人机对话的文本分类的效率和准确性。
附图说明
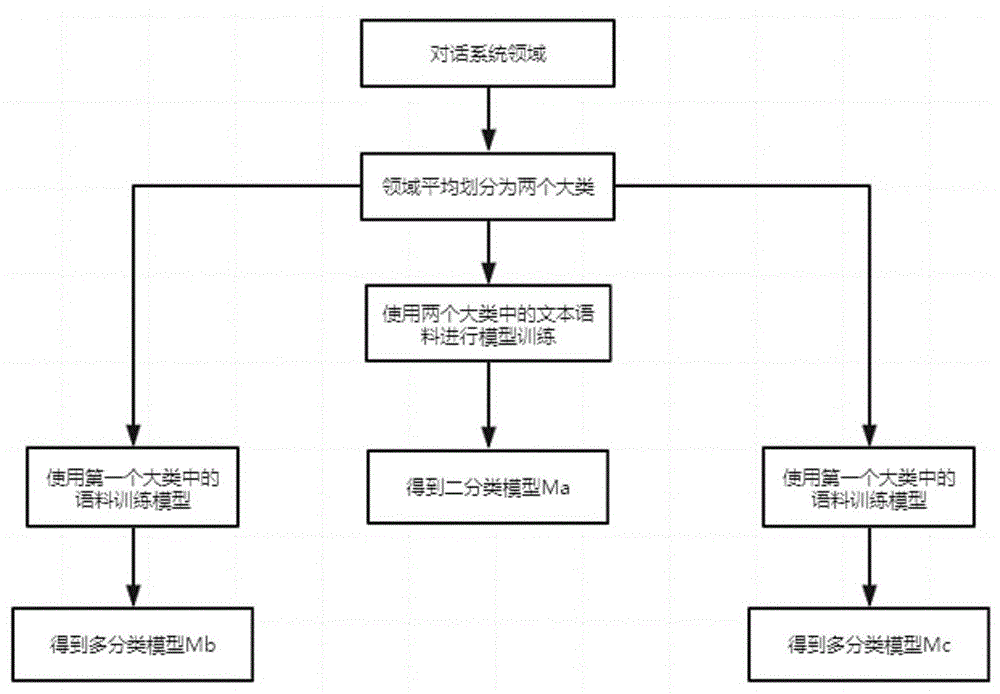
图1为本发明一种人机对话系统的文本分类方法实施例的模型训练的流程图。
图2为本发明一种人机对话系统的文本分类方法实施例的模型预测的流程图。
具体实施方式
以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效。
须知,本说明书所附图式所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容得能涵盖的范围内。同时,本说明书中所引用的如“上”、“下”、“左”、右”、“中间”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
实施例1
一种人机对话系统的文本分类方法,所述分类方法包括模型训练和模型预测两部分:
参见图1,所述模型训练为在包含了数十至数百个不同领域的数据库的人机对话系统中,使用全部数据库训练二分类预测模型ma,把不同领域的数据库平均分成两大类,训练两大类内各个类的预测模型,得到第一大类内各个类的第一类预测模型mb和第二大类内各个类的第二类预测模型mc;假设共有领域s1,s2,...,sn,每个领域中对应的训练文本语料分别为c1,c2,...,cn。使用全部领域s1,s2,...,sn训练领域的二分类模型ma,把领域平均分成两大类,即s1~sn/2和sn/2~sn,使用s1,s2,...,sn/2下对应的文本语料c1,c2,...,cn/2进行n/2分类模型训练,得到第一类预测模型mb。使用sn/2,sn/2+1,...,sn下对应的文本语料cn/2,cn/2+1,...cn进行n/2分类模型训练,得到第二类类模型mc。
参见图2,所述模型预测为对用户语音识别后的文本文本使用二分类预测模型ma进行预测,得出预测结果,如果结果属于第一类预测模型mb,则使用第一类预测模型mb进行预测,判断预测结果得分是否大于阈值,若得分大于阈值则使用第一类预测模型mb预测的结果,否则使用第二类预测模型mc进行预测,若结果大于阈值则使用第二类预测模型mc预测的结果,否则取第一类预测模型mb和第二类预测模型mc中得分高的作为预测结果;
所述模型预测为对用户语音识别后的文本文本使用二分类预测模型ma进行预测,得出预测结果,如果结果属于第二类预测模型mc,则使用第二类预测模型mc进行预测,判断预测结果得分是否大于阈值,若得分大于阈值则使用第二类预测模型mc预测的结果,否则使用第一类预测模型mb进行预测,若结果大于阈值则使用第一类预测模型mb预测的结果,否则取第一类预测模型mb和第二类预测模型mc中得分高的作为预测结果。
优选的,上述阈值为经验值,在实际产品中由设计人员以多次试验的办法测试得出。
优选的,上述模型训练中对不同领域的数据库平均分成两大类的过程为:先将数据库依次编号,对编号取中间值,第一个数据库到中间值归为第一类,中间值后至最后一个数据库为第二类。
优选的,上述模型训练中对不同领域的数据库平均分成两大类的过程为:先将数据库依次编号,对编号为偶数的归为第一类,对编号为奇数的归为第二类。
优选的,上述获得二分类预测模型(ma)、第一类预测模型(mb)和第二类预测模型(mc)的训练方法相同。
优选的,上述使用二分类预测模型(ma)、第一类预测模型(mb)和第二类预测模型(mc)的模型预测方法相同
优选的,上述文本分类方法运行于向量机。
以儿童娱乐教育人机对话文本分类方法为例,全部数据库包括音乐,故事,天气,相声,评书,京剧,万年历,菜谱,新闻,诗词,国学,识字,英文翻译,面积换算,体积换算,同反义词解释,历史,成语解释;把领域平均分成两大类:一类为娱乐类:音乐,故事,天气,相声,评书,京剧,万年历,菜谱,新闻;另一类为教育类:诗词,国学,识字,英文翻译,面积换算,体积换算,同反义词解释,历史,成语解释。
模型训练阶段:
把娱乐类下的所有语料表示为娱乐,教育类下所有语料表示为教育,训练二分类预测模型ma;使用娱乐类预测模型ma下语料训练第一类预测模型mb;使用教育类预测模型ma下语料训练第二类预测模型mc。
模型使用阶段:
对语音识别后的文本,首先使用ma进行二分类预测,预测属于娱乐类还是教育类。如果属于娱乐类并且大于阈值,则使用mb进行预测,返回预测结果;如果属于教育类并且大于阈值,则使用mc进行预测,返回预测结果;如果属于娱乐类并且小于阈值,使用mc进行预测,预测结果大于阈值,返回该预测结果;如果属于教育类并且小于阈值,使用mb进行预测,预测结果大于阈值,返回该预测结果;如果属于娱乐类并且小于阈值,使用mc进行预测,预测结果小于阈值,使用mb进行预测,选取mb和mc中预测阈值较大者,返回该结果;如果属于教育类并且小于阈值,使用mb进行预测,预测结果小于阈值,使用mc进行预测,选取mb和mc中预测阈值较大者,返回该结果。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!