一种基于卷积神经网络和VGGNet16模型的图像风格转换方法与流程
本发明属于计算机应用技术领域,具体是一种基于卷积神经网络和vggnet16模型的图像风格转换方法。
背景技术:
深度学习的概念源于人工神经网络的研究,含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。深度学习的概念由hinton等人于2006年提出,基于深度置信网络(dbn)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。此外lecun等人提出的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。深度学习是机器学习中一种基于对数据进行表征学习的方法,观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等,而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。
图像风格转换是最近新兴起的一种基于深度学习的技术,它的出现一方面是卷积神经网络所带来的优势,卷积神经网络所带来的对图像特征的高层特征的抽取使得风格和内容的分离成为了可能。另一方面,内容的表示是卷积神经网络所擅长的技巧,但风格转换却不是,风格的表示是采用相关矩阵来表示,这样生成的图像更生动更有艺术效果;基于卷积神经网络的图像风格转换方法,可以从图像中学习提取高层语义信息,实现对包括纹理识别和艺术风格分离。
正是基于卷积神经网络对图像风格转换有如上的优点,所以设计一种基于卷积神经网络和vggnet16模型的图像风格转换方法。提供一张内容图像和一张风格图像,所要生成图像的内容是来自内容图像的,而生成图像的风格来自风格图像的风格,计算生成图像与内容图像在指定卷积层上输出的差值,即内容损失,计算生成图像与风格图像在指定卷积层上输出的差值,即风格损失,定义损失函数,目标是最小化损失函数,生成内容相似于内容图像,而风格类似于风格图像。
技术实现要素:
针对卷积神经网络对图像的内容和风格得以处理的优点,本发明提出了一种基于卷积神经网络和vggnet16模型的图像风格转换方法。
本发明的技术方案是:一种基于卷积神经网络和vggnet16模型的图像风格转换方法,包括步骤:
图像数据的预处理,首先将内容图像和风格图像用python的image库进行读取,转换成可以进行计算的数值向量,接下来需加载vgg16模型,通过加载该模型,获得模型中的13层卷积层的权重值和偏置值,以及3层全连接层的权重值和偏置值;通过正太分布随机生成一个四维向量的变量,也是彩色图像,图像大小跟内容图像和风格图像的大小一致,通过梯度下降的方法,使该图像的内容更完整;通过myvggnet类和tensorflow库构建13层卷积神经网络,设置每层卷积神经网络的卷积核个数、卷积核大小、激活函数和池化层,各层卷积核的参数来自vgg16模型的对应卷积核参数;进一步通过tensoflow库构建三层全连接层和输出层,同样设置每层全连接层和输出层的神经元个数,各层的参数也来自vgg16模型的对应层参数;最后调用tensorflow库的api构建关于内容的损失和关于风格的损失,通过一定权重计算总损失loss,再使用梯度下降算法减少损失loss,最终得出生成的风格图像,解决以往工作人员通过软件或手工来绘制不同风格图像的问题。
进一步,图像数据的预处理过程中,读取内容图像和风格图像将其转换为四维向量,生成图像的内容来自内容图像,生成图像的风格来自风格图像,再通过均值是127.5、方差是20的正太分布随机生成一个四维向量,代表生成的图像,具体过程为:
对图像数据进行预处理,首先获得图像数据,通过python的image库读取图像数据,即通过函数img=image.open(img_name)来读取图像数据img,参数img_name表示图像的路径,再通过python的numpy库对数据img生成三维的向量(224,224,3),即通过函数np_img=np.array(img)来获得向量数据,其中np是numpy库的别名,array是numpy库的函数,最后通过np_img=np.asarray([np_img],dtype=np.int32)函数对三维向量np_img进行增加一维,变成四维向量(1,224,,224,3),其中asarray是numpy库的函数,dtype=np.int32表示转换后的图像数据都是int32类型,其中各个维度的数字表示如下:1表示该向量表示一张图像,224*224表示该图像的大小,最后的维度3表示该图像的通道数,也就是rgb三个通道,彩色图像都是三个通道,这里的内容图像和风格图像也是彩色图像;本实验的图像大小必须是224*224,采用的vgg16模型是针对224*224的图像,如果是不一样大小的图像,运行该实验的代码会出错;该实验的数据集也就是两张图像,衡量的指标是损失值越小越好,从而生成图像的内容越相似于内容图像的内容,风格越接近风格图像的风格;
在上述步骤获得内容图像、风格图像和随机生成图像的数据后,需要加载vgg16模型,该模型是从网站下载得到,也就是一个vgg16.npy文件,该模型共有16层网络结构,分别有13层卷积层和3层全连接层,即2个64卷积核、2个128卷积核、3个256卷积核、6个512卷积核的卷积层,以及2个4096神经元和1个1000神经元的全连接层,每一层的权重和偏置都在该模型中,通过函数data_dict=np.load(vgg16_npy_path,encoding="bytes").item()来加载该模型,其中load是numpy库的函数,第一个参数vgg16_npy_path表示模型文件的路径,第二个参数encoding="bytes"表示读取该模型文件以字节bytes编码进行读取,并经过方法tem(),得到一个字典格式数据,字典的长度是16,代表16层网络结构,键key表示每层网络结构的名称,每个key对应一个列表,列表中有两个元素,分别是key对应的网络结构的权重和偏置,每层网络结构的权重和偏置的维度不都是相同的。
进一步,通过myvggnet类和tensorflow库构建13层卷积神经网络,设置每层卷积神经网络的卷积核个数、卷积核大小、激活函数和池化层的具体步骤为:
步骤2.1:在获得了内容图像数据、风格图像数据、生成图像数据以及vggnet16网络模型的参数后,接下来需要通过三个图像数据和模型的各层参数来产生每一层网络的输出结果;首先创建一个myvggnet类对每层网络的输出进行处理;通过class关键字创建myvggnet类,其中的初始化方法__init__将模型参数data_dict代入变成成员属性,方便后面构建神经网络来获得每层的权重和偏置,创建方法get_conv_filter(self,name)来获得卷积层的权重,参数self表示对象本身,参数name表示卷积层的名称,该方法中获取参数值的代码如下:tf.constant(self.data_dict[bytes(name,encoding="utf-8")][0],name='conv'),其中tf是tensorflow库的别名,constant是tensorflow库的函数,bytes(name,encoding="utf-8")表示将name转换成utf-8编码,通过data_dict字典数据来获取该name对应的数据,获得的数据是集合类型,而权重是在集合的第一个索引位置,所以取0索引,name=’conv’表示常量的名称;创建自定义方法get_fc_weight(self,name)来获得全连接层的权重,参数self表示对象本身,参数name表示全连接层的名称,该方法中同样通过上述的tf.constant方法来获取全连接层的权重,其中tf是tensorflow库的别名,constant是tensorflow库的函数;创建自定义方法get_bias(self,name)来获得卷积层和全连接层的偏置,参数self表示对象本身,参数name表示卷积层或全连接层的名称,该方法中同样通过上述的tf.constant方法来获取卷积层或全连接层的偏置,其中tf是tensorflow库的别名,constant是tensorflow库的函数;
步骤2.2:在步骤2.1中创建了获取vggnet16模型的参数的方法后,接下来创建构造卷积层、池化层和全连接层的方法;通过自定义方法conv_layer来获取三张图像的每层卷积层的输出结果:该方法中通过调用方法get_conv_filter来获得对应卷积层的权重conv_w,再通过调用方法get_bias来获取对应全连接层name的偏置conv_b;再通过函数h=tf.nn.conv2d(x,conv_w,[1,1,1,1],padding='same')获得卷积后的输出结果,nn.conv2d是tensorflow库的函数,参数[1,1,1,1]表示移动步长,padding=”same”表示零补充;通过函数h=tf.nn.bias_add(h,conv_b)将卷积后的结果再加上偏置conv_b得到最新的结果h,nn.bias_add为tensorflow库的函数,最后通过激活函数h=tf.nn.relu(h)将最新的h经过激活,得到最后的返回值h,nn.relu是tensorflow库的函数;接下来,通过自定义的方法pooling_layer(self,x,name)来获取三张图像的每层池化层的输出结果,参数self表示对象本身,参数x是卷积层结构的输出结果,参数name是池化层的名称,该方法主要通过以下代码实现:通过函数tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='same',name=name)进行池化操作,其中tf是tensorflow库的别名,nn.max_pool是tensorflow库的函数,ksize=[1,2,2,1]是池化窗口大小2*2,strides=[1,2,2,1]是移动的步长,padding=”same”是否进行零补充,name=name表示此次进行池化的名称;接下来,通过自定义的方法fc_layer来获得全连接层的输出结果:该方法中调用自定义方法get_fc_weight来获得对应全连接层的权重fc_w,再通过自定义方法get_bias来获得对应全连接层的偏置fc_b,通过函数h=tf.matmul(x,fc_w)将输入x与权重fc_w相乘得到结果g,matmul为tensorflow库的函数,再通过函数h=tf.nn.bias_add(h,fc_b)将前面的结果g加上偏置fc_b,再经过激活函数relu,得到最后的输出结果;
步骤2.3:在步骤2.2中创建了构建卷积层、池化层和全连接层的方法后,接下来需创建执行以上方法的成员方法;通过自定义方法build(self,x_rgb)来获得内容图像、风格图像和随机生成图像在vggnet16模型上每层网络结构上的输出,并将每层的输出设置为对象的成员属性,方便后面代码的调用;其中参数self是对象本身,作用是调用自定义方法,参数x_rgb是输入的一张图像,自定义方法build(self,x_rgb)中代码的主要流程如下:调用自定义方法conv_layer(x_bgr,'conv1_1')来获得图像数据在第一层卷积层上的输出conv1_1,参数x_bgr是将参数x_rgb的通道进行调换后的数据,而参数‘conv1_1’是第一层卷积层的名称;再调用自定义方法conv_layer(conv1_1,'conv1_2')来获取在第二层卷积层的输出conv1_2,参数conv1_1是第一层卷积层的输出,参数’conv1_2’表示第二层卷积层的名称;再调用自定义方法pooling_layer(conv1_2,'pool1')将第二层卷积层的输出进行池化得到输出结果pool1,参数conv1_2表示通过第二层卷积层后的数据,参数‘pool1’表示池化层的名称,后面的卷积层和池化同理,不再一一叙述。
进一步,调用tensorflow库的api构建关于内容的损失和关于风格的损失,通过一定权重计算总损失loss,再使用梯度下降算法减少损失loss,最终得出生成的风格图像,主要包含下列步骤:
步骤3.1:在完成myvggnet类的创建后,接下来需要创建对象:通过numpy库的load方法获得了vggnet16模型的各层网络结构的参数值data_dict,分别创建关于内容图像、风格图像和生成图像的三个myvggnet实例,即通过myvggnet(data_dict)类得到三个实例vgg_for_content、vgg_for_style和vgg_for_result,其中参数data_dict是上述获得的模型参数值,再通过三个实例分别执行成员方法build来获得对应图像的每层结构的输出;
步骤3.2:分别创建了内容图像、风格图像和生成图像关于myvggnet的实例之后,接下来需要指定关于内容的卷积层和关于风格的卷积层,其中卷积层的个数可以是多个,最后计算两者的损失和总损失;通过content_features=[vgg_for_content.conv1_2]和result_content_features=[vgg_for_result.conv1_2]来指定内容图像和生成图像在相同卷积层conv1_2上的输出,其中content_features为内容特征,conv1_2为第二层卷积层的输出,result_content_features为结果特征;计算content_features与result_content_features在每一层卷积层上输出的差值的平方,再统计所有卷积层的值,求得内容损失content_loss;通过风格特征style_features=[vgg_for_style.conv4_3]和结果风格特征result_style_features=[vgg_for_result.conv4_3]来指定风格图像和生成图像在相同卷积层conv4_3上的输出,计算关于风格的损失值;与计算内容的损失有所不同,首先需要计算每层卷积层输出到的gram矩阵,通过自定义的方法style_gram求出风格图像和生成图像的每层卷积层的gram矩阵,即将卷积层的输出向量乘以卷积层的输出向量的转置,得出的结果就是gram矩阵,计算风格图像和生成图像对应卷积层的gram矩阵的差值,再统计所有gram矩阵的差值,求得风格损失style_loss;最后通过loss=content_loss*lambda_c+style_loss*lambda_s公式求得最终损失,其中,常量lambda_c和lambda_s分别是内容损失和风格损失的权重,通过tensorflow库的api来执行梯度下降算法adam,逐步减少loss,优化生成图像。
根据上述构思,实现该发明的技术方案主要有以下两点:
(1)myvggnet类的创建:创建myvggnet类实现对vggnet16模型的各层卷积层、池化层和全连接层的参数值进行获取,内容图像、风格图像和生成图像分别创建一个myvggnet实例,方便调用每层网络结构的参数值,实现代码的复用性。
(2)内容损失和风格损失不同计算方法:内容损失是根据内容图像与生成图像在相同层次的卷积层的输出,计算两个输出的差值,而风格损失是根据风格图像和生成图像在相同层次的卷积层的输出,先求得两个输出的gram矩阵,再根据gram矩阵求出风格损失,最终的损失是根据内容损失、风格损失以及对应的权重而得出。
在以上两项内容的配合使用下所产生的主要有益效果是:代码结构简明清晰,易于阅读,能产生不同卷积层或多层卷积层情况下的生成图像,通过比较生成图像的内容和风格,可以确定哪一层卷积层的生成图像的内容更相似,风格更逼真;通过指定一张内容图像和一张风格图像,就可以产生出多张不同程度的内容和风格相似的生成图像。
附图说明
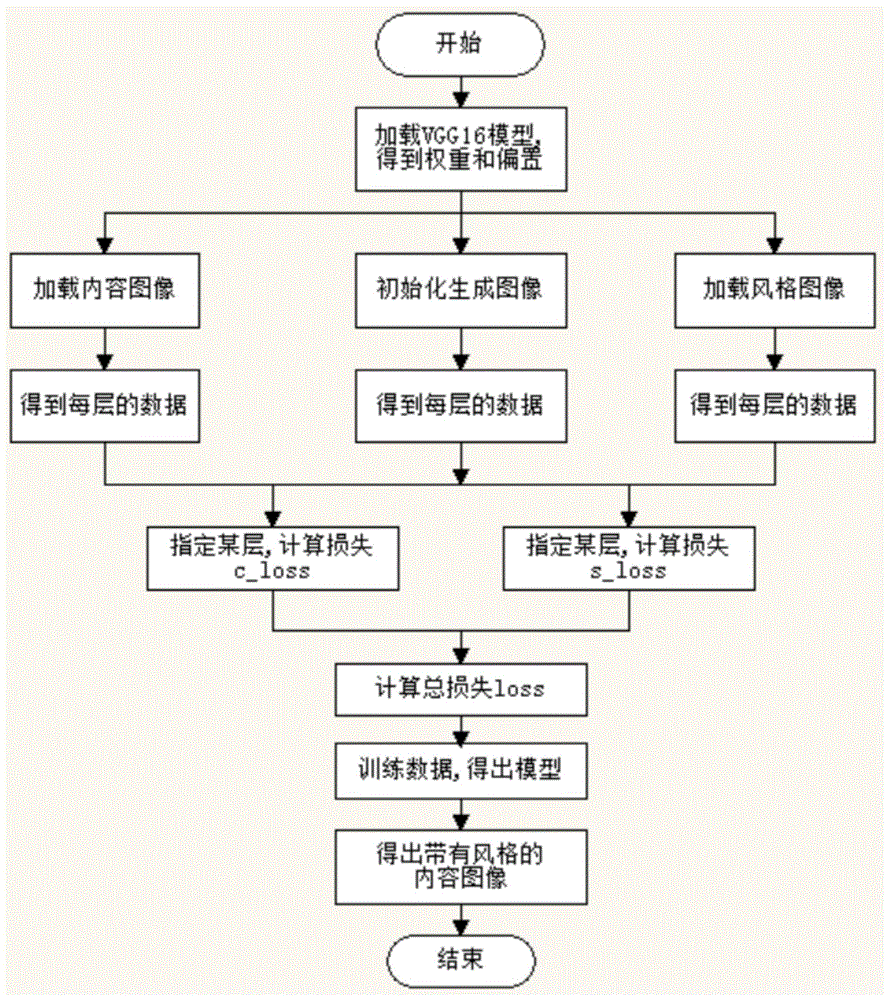
图1是本发明中的一种基于卷积神经网络和vggnet16模型的图像风格转换方法的代码流程图;
图2(a),图2(b)分别是本发明中的内容图像和风格图像;
图3(a),图3(b)分别是不同迭代次数下的生成图像。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好的理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
如图1所示,本发明的一种基于卷积神经网络和vggnet16模型的图像风格转换方法,包括以下步骤:
一种基于卷积神经网络和vggnet16模型的图像风格转换方法,包括下列三大步骤:
步骤1:读取内容图像和风格图像将其转换为四维向量,图2(a)和图2(b)分别是内容图像和风格图像,通过正太分布随机生成一个四维向量,代表生成的图像,经过模型的训练后,而生成图像的内容来自内容图像,生成图像的风格来自风格图像;
步骤2:通过myvggnet类和tensorflow库来获得每一层的数据以及构建卷积神经网络;
步骤3:计算内容图像、风格图像和生成图像在指定层上的输出,分别求出内容图像与生成图像、风格图像与生成图像在指定层上的损失,并计算总的损失,构建损失函数,经过梯度下降算法生成不同迭代次数下的生成图像;
上述步骤1中包含下列步骤:
步骤1.1:图像数据进行预处理,首先获得图像数据,如图2(a)和图2(b)所示,分别表示内容图像和风格图像,通过python的image库读取图像数据,即通过函数img=image.open(img_name)来读取图像数据,参数img_name表示图像的路径,再通过python的numpy库对数据img生成三维的向量(224,224,3),即通过函数np_img=np.array(img)来获得向量数据,最后通过np_img=np.asarray([np_img],dtype=np.int32)函数对三维向量np_img进行增加一维,变成四维向量(1,224,,224,3),其中dtype=np.int32表示转换后的图像数据都是int32类型,其中各个维度的数字表示如下:1表示该向量表示一张图像,224*224表示该图像的大小,最后的维度3表示该图像的通道数,也就是rgb三个通道,彩色图像都是三个通道,这里的内容图像和风格图像也是彩色图像;本实验的图像大小必须是224*224,因为本实验采用的vgg16模型是针对224*224的图像,如果是不一样大小的图像,运行该实验的代码会出错;该实验的数据集也就是两张图像,衡量的指标是损失值越小越好,从而生成图像的内容越相似于内容图像的内容,风格越接近风格图像的风格;
步骤1.2:在步骤1.1中获得内容图像、风格图像和随机生成图像的数据后,需要加载vgg16模型,该模型是从网站下载得到,也就是一个vgg16.npy文件,该模型共有16层网络结构,分别有13层卷积层和3层全连接层,即2个64卷积核、2个128卷积核、3个256卷积核、6个512卷积核的卷积层,以及2个4096神经元和1个1000神经元的全连接层,每一层的权重和偏置都在该模型中,通过函数data_dict=np.load(vgg16_npy_path,encoding="bytes").item()来加载该模型,第一个参数vgg16_npy_path表示模型文件的路径,第二个参数encoding="bytes"表示读取该模型文件以字节编码进行读取,并经过方法tem(),得到一个字典格式数据,字典的长度是16,代表16层网络结构,键key表示每层网络结构的名称,每个key对应一个列表,列表中有两个元素,分别是key对应的网络结构的权重和偏置,每层网络结构的权重和偏置的维度不都是相同的。
上述步骤2中包含下列步骤:
步骤2.1:在获得了内容图像数据、风格图像数据、生成图像数据以及vggnet16网络模型的参数后,接下来需要通过三个图像数据和模型的各层参数来产生每一层网络的输出结果。首先创建一个myvggnet类对每层网络的输出进行处理,这样做的目的是以面向对象思维编程,简化代码量和便于操作,实现复用性特点;通过class关键字创建myvggnet类,其中的初始化方法__init__将模型参数data_dict代入变成成员属性,方便后面构建神经网络来获得每层的权重和偏置,创建get_conv_filter(self,name)方法来获得卷积层的权重,参数self表示对象本身,参数name表示卷积层的名称,其中获取参数值的函数是tf.constant(self.data_dict[bytes(name,encoding="utf-8")][0],name='conv'),bytes(name,encoding="utf-8")表示将name转换成字节编码,通过data_dict字典数据来获取该name对应的数据,获得的数据是集合类型,而权重是在集合的第一个索引位置,所以取0索引,name=’conv’表示常量的名称;通过get_fc_weight(self,name)方法来获得全连接层的权重,参数self表示对象本身,参数name表示全连接层的名称,其中获取参数值的函数是tf.constant(self.data_dict[bytes(name,encoding="utf-8")][0],ame='fc'),同样,bytes(name,encoding="utf-8")表示将name转换成字节编码,通过data_dict字典数据来获取该name对应的数据,获得的数据是集合类型,而权重是在集合的第一个索引位置,所以取0索引,name=’fc’表示常量的名称;通过det_bias(self,name)方法来获得卷积层和全连接层的偏置,参数self表示对象本身,参数name表示卷积层或全连接层的名称,其中获取偏置的函数是tf.constant(self.data_dict[bytes(name,encoding="utf-8")][1],name='bias'),同样,bytes(name,encoding="utf-8")表示将name转换成字节编码,通过data_dict字典数据来获取该name对应的数据,获得的数据是集合类型,而偏置是在集合的第二个索引位置,所以取1索引,name=’bias’表示常量的名称。
步骤2.2:在步骤2.1中创建了获取vggnet16模型的参数的方法后,接下来创建构造卷积层、池化层和全连接层的方法。通过方法defconv_layer(self,x,name)来创建卷积层,获取每一层的输出结果,其中参数self表示对象本身,参数x表示输入的数据,可以是内容图像、风格图像或生产图像的数据,也可以是卷积层或池化层的输出,name是卷积层或池化层的名称,通过函数conv_w=self.get_conv_filter(name)获得name对应的卷积层的权重,其中参数name是卷积层的名称,通过函数conv_b=self.get_bias(name)获得对应的全连接层的偏置,其中参数name是卷积层或全连接层的偏置,再通过函数h=tf.nn.conv2d(x,conv_w,[1,1,1,1],padding='same')获得卷积后的输出结果,参数[1,1,1,1]表示移动步长,padding=”same”表示零补充;通过函数h=tf.nn.bias_add(h,conv_b)将卷积后的结果再加上偏置conv_b得到最新的结果h,最后通过激活函数h=tf.nn.relu(h)将最新的h经过激活,得到最后的返回值h;接下来,通过方法defpooling_layer(self,x,name)来创建池化层,参数self表示对象本身,参数x是卷积层结构的输出结果,参数name是池化层的名称,通过函数returntf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='same',name=name)进行池化操作,ksize=[1,2,2,1]是池化窗口大小2*2,strides=[1,2,2,1]是移动的步长,padding=”same”是否进行零补充,name=name表示此次进行池化的名称;接下来,通过方法deffc_layer(self,x,name,activation=tf.nn.relu)创建全连接层,self表示对象本身,x表示卷积层后的输出结果,name表示全连接层的名称,通过该名称获得全连接层的权重和偏置,参数activation=tf.nn.relu表示激活函数,激活函数默认为relu函数,通过方法fc_w=self.get_fc_weight(name)来获得名称为name的全连接层的权重,通过方法fc_b=self.get_bias(name)来获得名称name的全连接层的偏置,通过函数h=tf.matmul(x,fc_w)将输入x与权重fc_w相乘得到结果g,再通过函数h=tf.nn.bias_add(h,fc_b)将前面的结果g加上偏置fc_b,再经过激活函数relu,得到最后的输出结果。
步骤2.3:在步骤2.2中创建了构建卷积层、池化层和全连接层的方法后,接下来需创建执行以上方法的成员方法。通过方法defbuild(self,x_rgb)来获得内容图像、风格图像和随机生成图像在vggnet16模型上每层网络结构上的输出,并将每层的输出设置为对象的成员属性,方便后面代码的调用。参数self是对象本身,参数x_rgb是输入的一张图像,其中代码的主要流程如下:通过函数self.conv1_1=self.conv_layer(x_bgr,'conv1_1')来获得图像数据在第一层卷积层上的输出,参数x_bgr是将参数x_rgb的通道进行调换后的数据,而参数‘conv1_1’是第一层卷积层的名称,并将conv1_1设置为成员属性;通过函数self.conv1_2=self.conv_layer(self.conv1_1,'conv1_2')将第一层卷积后的结果conv1_1当成第二层的输入,参数’conv1_2’表示第二层卷积层的名称,并将结果conv1_2设置为成员属性;通过函数self.pool1=self.pooling_layer(self.conv1_2,'pool1')将第二层卷积层的输出进行池化,self.conv1_2表示通过第二层卷积层后的数据,参数‘pool1’表示池化层的名称,后面的卷积层和池化同理,不再一一叙述,分别获得卷积层conv2_1、conv2_2、conv3_1、conv3_2、conv3_3、conv4_1、conv4_2、conv4_3、conv5_1、conv5_2和conv5_3的输出,以及池化层pool2、pool3、pool4和pool5的输出。
上述步骤3中包含下列步骤:
步骤3.1:在在完成myvggnet类的创建后,接下来需要创建对象。通过data_dict=np.load(vgg16_npy_path,encoding="bytes").item()方法获得vggnet16模型的各层网络结构的参数值,以下三个函数分别创建关于内容图像、风格图像和生成图像的myvggnet实例,即vgg_for_content=myvggnet(data_dict)、vgg_for_style=myvggnet(data_dict)和vgg_for_result=myvggnet(data_dict),其中参数data_dict是上述获得的模型参数值,再通过以下三个成员方法来获得对应图像的每层结构的输出,即vgg_for_content.build(content)、vgg_for_style.build(style)和vgg_for_result.build(result),参数content、参数style和参数result分别是内容图像、分割图像和生成图像数据;
步骤3.2:分别创建了内容图像、风格图像和生成图像关于myvggnet的实例之后,接下来需要指定关于内容的卷积层和关于风格的卷积层,其中卷积层的个数可以是多个,最后计算两者的损失和总损失。通过content_features=[vgg_for_content.conv1_2]和result_content_features=[vgg_for_result.conv1_2]指定内容图像和生成图像在卷积层conv1_2上的输出,通过一个for循环求得内容损失,即forc,c_inzip(content_features,result_content_features):content_loss+=tf.reduce_mean((c-c_)**2,[1,2,3]),content_loss初始化为0,c和c_分别是集合content_features和result_content_features中的元素,(c-c_)**2表示两个向量相减再平方,[1,2,3]表示在向量的第二维、第三维和第四维上求损失,tf.reduce_mean函数表示求均值,最后content_loss是每层卷积层的损失之和;通过style_features=[vgg_for_style.conv4_3]和result_style_features=[vgg_for_result.conv4_3]指定风格图像和生成图像在卷积层conv4_3上的输出,计算关于风格的损失值,与计算内容的损失有所不同,首先需要计算每层卷积层输出到的gram矩阵,即style_gram=[gram_matrix(feature)forfeatureinstyle_features]和result_style_gram=[gram_matrix(feature)forfeatureinresult_style_features],style_gram是风格图像的每层卷积层的gram矩阵,result_style_gram是生成图像的每层卷积层的gram矩阵,gram_matrix是求gram矩阵的函数,将卷积层的输出向量乘以卷积层的输出向量的转置,得出的结果就是gram矩阵,再通过一个for循环求得风格损失,即fors,s_inzip(style_gram,result_style_gram):style_loss+=tf.reduce_mean((s-s_)**2,[1,2]),s和s_分别是集合style_gram和result_style_gram中的gram矩阵,style_loss初始化为0,将每层卷积层上的损失相加,(c-c_)**2表示两个向量相减再平方,[1,2]表示在向量的第二维和第三维上求损失,tf.reduce_mean函数表示求均值,最后style_loss是每层卷积层的损失之和;最后通过loss=content_loss*lambda_c+style_loss*lambda_s公式求得最终损失,其中,常量lambda_c和lambda_s分别是内容损失和风格损失的权重,通过tensorflow库的api来执行梯度下降算法,tf.train.adamoptimizer(learning_rate).minimize(loss),其中tf是tensorflow库的别名,train.adamoptimizer是tensorflow库的函数,作用是进行梯度下降,learning_rate是学习率,loss就是上述的总损失,每经过一次优化,生成对应的生成图像保存到文件中,生成图像如图3(a)和图3(b)所示,该两张生成图像在不同的迭代次数下生成的。
- 还没有人留言评论。精彩留言会获得点赞!