基于Redis高并发延时任务处理的方法与流程
本发明属于大数据技术领域,特别涉及一种基于redis高并发延时任务处理的方法。
背景技术:
延时任务,是指延迟一段时间后才执行的任务。目前大部分应用系统都有执行延时任务的需求,比如,在电商在线业务中,每天会有成百上千万订单产生,用户下单之后如果三十分钟之内没有付款就会自动取消订单,下单成功后系统会在60s之后给用户发送短信通知,7天后自动收货,一定时间后自动评价等等,这些都是属于延时任务。
传统的延时任务处理方法是通过启动一个定时任务,定时轮询某个应用中的所有周期性延时任务,取出延时时间到达的任务记录,然后同步处理。这种处理方式无法做到对延时任务的精确选取,查表轮询效率极低,每次轮询增加了数据库访问压力,影响其他业务操作。如果增大轮询时间间隔,那么任务处理的时效性就会降低;对延时任务处理的性能低下,针对查询出要处理的记录进行同步处理,会导致大量任务堆积,执行时间较长的任务还会影响下个扫描周期的任务执行,无法处理大量的并发任务。
技术实现要素:
本发明所要解决的技术问题是:提出一种基于redis高并发延时任务处理的方法,降低数据查询数量和系统资源消耗,提升数据查询的精确性,以更加高效、高并发的方式处理延时任务。
本发明解决上述技术问题采用的技术方案是:基于redis高并发延时任务处理的方法,包括以下步骤:
a.提取延时任务的关键信息,并通过任务对象的存储结构存入redis的有序集合zset中,所述任务对象的存储结构为:delaytask{"key":"任务类型名称","value":"延时任务数据库主键id","score":"延时任务创建时间数加上延时时间"};
b.定时监听rediszset集合,从中查找出score>=当前时间数的所有任务对象的value值,组成当前需执行的延时任务的数据库主键集合;
c.根据获取的当前需执行的延时任务的数据库主键集合,在数据库中精确查询需要处理的延时任务详细信息;
d.开启线程池,根据查询的延时任务详细信息启用新线程对任务进行异步处理;
e.若某数据库主键对应的延时任务处理成功,则删除rediszset集合中该数据库主键对应的任务对象,若未处理成功,则返回步骤b等待下一次对rediszset集合的监听。
作为进一步优化,步骤a中,在将延时任务的关键信息通过任务对象的存储结构存入redis的有序集合zset时,zset集合按照任务对象中的score从小到大对各个任务对象进行排序。
基于zset集合的天然排序能力,能够更高效地对数据进行筛选。
作为进一步优化,步骤b中,所述从中查找出score>=当前时间数的所有任务对象的value值的方法包括:
通过redis的zrangebyscore命令查出score>=当前时间数,key为delaytask对象key的所有记录的value值。
基于redis的zrangebyscore命令能够快速、准确地查询出符合条件的任务对象。
作为进一步优化,步骤d中,在开启线程池时,基于并发任务的多少设置合理的最大线程数。
设置的最大线程数与并发任务数量相关,从而提升系统的处理性能。
本发明的有益效果是:
引入redis作为数据库存储的补充,将原本需要对数据库进行轮询查询的操作转移到redis中,降低了数据库的访问压力;同时基于redis有序集合天然的排序能力,能够更高效的对数据进行筛选,并且,在对延时任务进行处理时,通过开启线程池,启用多个新线程对延时任务对象并发处理。因此,本发明能够精确筛选延时任务,降低数据库访问压力,提高延时任务并发处理能力。
附图说明
图1为实施例中的基于redis高并发延时任务处理的方法流程图。
具体实施方式
redis是一个高性能的key-value数据库,支持string(字符串)、list(链表)、set(集合)、zset(sortedset有序集合)和hash(哈希类型)等数据类型,并对这些数据类型都支持push/pop、add/remove、排序等操作,而且这些操作都是原子性的。本发明利用redis高性能和有序集合zset自然排序的数据结构特点,提供了一种基于redis高并发延时任务处理的方法,降低数据查询数量和系统资源消耗,提升数据查询的精确性,以更加高效高并发的方式处理延时任务。
具体实现上,本发明中的基于redis高并发延时任务处理的方法包括:
1、基于redis有序集合zset的特性,提取延时任务的关键信息,设计任务对象的存储结构,将其存入zset集合中。
zset集合能够存储键值对和得分score,集合中的成员能够根据score进行从小到大的排序。基于此,设计任务对象delaytask{"key":"任务类型名称","value":"延时任务数据库主键id","score":"延时任务创建时间数加上延时时间"},并将其存入redis的zset中。如果有多种延时任务类型,如延时推送消息,延时清洗数据等,可以对delaytask中的key进行分类。由于引入redis作为数据库存储的补充,将原本需要对数据库进行轮询查询的操作转移到redis中,降低了数据库的访问压力;同时基于redis有序集合天然的排序能力,能够更高效的对数据进行筛选。
2、监听redis中任务对象delaytask,取出rediszset集合中score大于等于当前时间数(毫秒)的当前要执行或过期的任务对象:
每分钟定时监听rediszset集合,通过redis的zrangebyscore命令查出score>=当前时间数(毫秒),key为delaytask对象key的所有记录的value值,即延时任务的数据库主键。
3、通过步骤2中返回的延时任务的数据库主键集合,能够在数据库中精确查询需要处理的记录详情。
4、开启线程池,基于步骤3中返回的延时任务详细信息用新线程对任务进行异步处理。通过新线程能够防止某条任务处理耗时较长对后续排队任务的影响,同时提高任务并发处理能力;使用线程池能够极大降低延迟创建和销毁的开销,同时基于并发任务的多寡,设置合理的最大线程数,能够进一步提升系统性能。
5、如果步骤4中的任务处理成功,则删除rediszset集合中延时任务数据库主键对应的任务对象;如果任务处理失败,则该条记录仍然在redis的zset集合中,在下个执行周期中会重复步骤2的过程。
实施例:
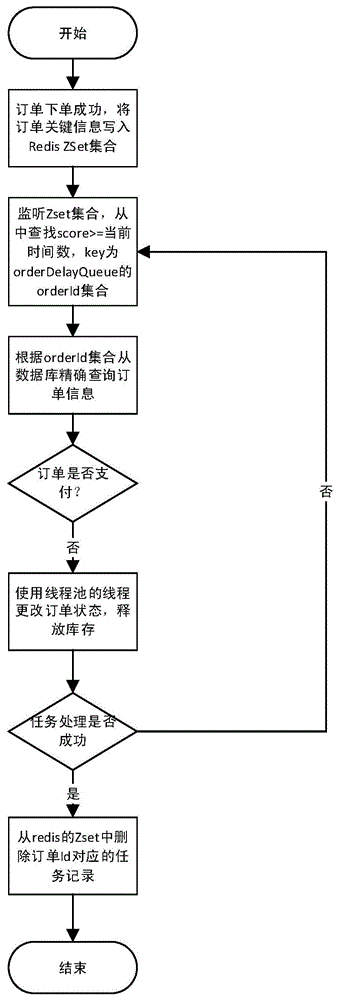
以订单下单支付超时任务处理为例,如图1所示,本实施例的处理流程包括以下步骤:
(1)将延时任务关键信息存储到redis有序集合zset中,利用redis高效kev-value存取特性,降低数据库访问压力。
例如,支付订单下单成功之后,提取支付订单关键信息:订单id、订单下单时间,组成任务对象delaytask{"key":"orderdelayqueue","value":"oderid","score":"下单时间"+30*60*1000}存入redis的zset中。如果有多种延时任务类型,如延时推送消息,延时清洗数据等,可以对delaytask中的key进行分类。
(2)监听redis中任务对象,取出rediszset集合中score大于等于当前时间数(毫秒)的当前要执行或过期的任务对象。每分钟定时监听redis有序集合,通过redis的zrangebyscore命令查出score>=当前时间数(毫秒),key为“orderdelayqueue”所有记录的任务对象中的“oderid”。
(3)通过任务对象中的关键字段到数据库中查询需要处理的记录。通过步骤(2)中返回的所有任务对象的“orderid”到数据库中精确查找对应的订单信息。
(4)开启线程池,基于步骤(3)中返回的任务详细信息用新线程对任务进行异步处理,防止某条任务处理耗时较长对后续排队任务的影响,同时提高任务并发处理能力。例如,如果某条订单的状态为“未支付”,则使用线程池中的线程进行更新该条订单状态为“取消”,释放该条订单对应的库存操作。
(5)如果步骤(4)中的任务处理成功,则删除rediszset集合中任务记录(该条orderid对应的rediszset中的任务记录);如果任务处理失败,则该条记录仍然在redis的zset集合中,在下个执行周期中会重复步骤(2)的过程。
- 还没有人留言评论。精彩留言会获得点赞!